Oplossingen ontwikkelen met gegevensstromen
Power BI-gegevensstromen zijn een op bedrijven gerichte oplossing voor gegevensvoorbereiding die een ecosysteem van gegevens beschikbaar maakt voor gebruik, hergebruik en integratie. Dit artikel bevat enkele veelvoorkomende scenario's, koppelingen naar artikelen en andere informatie om u te helpen bij het begrijpen en gebruiken van gegevensstromen voor hun volledige potentieel.
Toegang krijgen tot Premium-functies van gegevensstromen
Power BI-gegevensstromen in Premium-capaciteiten bieden veel belangrijke functies waarmee u grotere schaal en prestaties voor uw gegevensstromen kunt bereiken, zoals:
- Geavanceerde berekening, die de ETL-prestaties versnelt en DirectQuery-mogelijkheden biedt.
- Incrementeel vernieuwen, waarmee u gegevens kunt laden die zijn gewijzigd van een bron.
- Gekoppelde entiteiten, die u kunt gebruiken om te verwijzen naar andere gegevensstromen.
- Berekende entiteiten, die u kunt gebruiken om composeerbare bouwstenen van gegevensstromen te bouwen die meer bedrijfslogica bevatten.
Daarom raden we u aan om waar mogelijk gegevensstromen in een Premium-capaciteit te gebruiken. Gegevensstromen die in een Power BI Pro-licentie worden gebruikt, kunnen worden gebruikt voor eenvoudige, kleinschalige gebruiksvoorbeelden.
Oplossing
Het verkrijgen van toegang tot deze Premium-functies van gegevensstromen is op twee manieren mogelijk:
- Wijs hier een Premium-capaciteit aan voor een bepaalde werkruimte en neem uw eigen Pro-licentie mee om gegevensstromen te maken.
- Breng je eigen Premium per gebruiker (PPU)-licentie mee, wat vereist dat andere leden van de werkruimte ook een PPU-licentie hebben.
U kunt geen PPU-gegevensstromen (of andere inhoud) buiten de PPU-omgeving (zoals in Premium of andere SKU's of licenties) gebruiken.
Voor Premium-capaciteiten hebben uw gebruikers van gegevensstromen in Power BI Desktop geen expliciete licenties nodig om power BI te gebruiken en te publiceren. Maar als u wilt publiceren naar een werkruimte of een resulterend semantisch model wilt delen, hebt u ten minste een Pro-licentie nodig.
Voor PPU moet iedereen die PPU-inhoud maakt of gebruikt een PPU-licentie hebben. Deze vereiste verschilt van de rest van Power BI, omdat u iedereen met PPU expliciet een licentie moet geven. U kunt geen gratis, pro- of zelfs Premium-capaciteiten combineren met PPU-inhoud, tenzij u de werkruimte migreert naar een Premium-capaciteit.
Het kiezen van een model is doorgaans afhankelijk van de grootte en doelstellingen van uw organisatie, maar de volgende richtlijnen zijn van toepassing.
| Team type | Premium per capaciteit | Premium per gebruiker |
|---|---|---|
| >5000 gebruikers | ✔ | |
| <5000 gebruikers | ✔ |
Voor kleine teams kan PPU de kloof tussen Gratis, Pro en Premium per capaciteit overbruggen. Als u grotere behoeften hebt, is het gebruik van een Premium-capaciteit met gebruikers met Pro-licenties de beste aanpak.
Gebruikersgegevensstromen maken waarop beveiliging is toegepast
Stel dat u gegevensstromen moet maken voor verbruik, maar wel beveiligingsvereisten hebt:
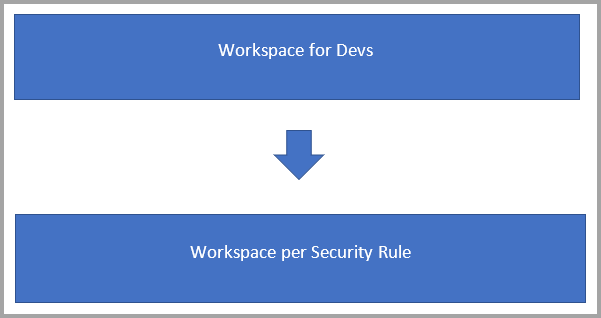
In dit scenario hebt u waarschijnlijk twee typen werkruimten:
Back-endwerkruimten waarin u gegevensstromen ontwikkelt en de bedrijfslogica uitbouwt.
Gebruikerswerkruimten waarin u bepaalde gegevensstromen of tabellen beschikbaar wilt maken voor een bepaalde groep gebruikers voor gebruik:
- De gebruikerswerkruimte bevat gekoppelde tabellen die verwijzen naar de gegevensstromen in de back-endwerkruimte.
- Gebruikers hebben viewertoegang tot de werkruimte van de consument en geen toegang tot de back-endwerkruimte.
- Wanneer een gebruiker Power BI Desktop gebruikt om toegang te krijgen tot een gegevensstroom in de gebruikerswerkruimte, kan deze de gegevensstroom zien. Maar omdat de gegevensstroom leeg wordt weergegeven in de Navigator, worden de gekoppelde tabellen niet weergegeven.
Gekoppelde tabellen begrijpen
Gekoppelde tabellen zijn gewoon een aanwijzer naar de oorspronkelijke gegevensstroomtabellen en nemen de machtiging van de bron over. Als Power BI de gekoppelde tabel toestaat om de doelmachtiging te gebruiken, kan elke gebruiker de bronmachtiging omzeilen door een gekoppelde tabel te maken in de bestemming die naar de bron verwijst.
Oplossing: Berekende tabellen gebruiken
Als u toegang hebt tot Power BI Premium, kunt u een berekende tabel maken in de bestemming die verwijst naar de gekoppelde tabel, met een kopie van de gegevens uit de gekoppelde tabel. U kunt kolommen verwijderen via projecties en rijen verwijderen via filters. De gebruiker met machtigingen voor de doelwerkruimte heeft toegang tot gegevens via deze tabel.
Herkomst voor bevoegde personen toont ook de werkruimte waarnaar wordt verwezen en stelt gebruikers in staat om een koppeling te maken om de bovenliggende gegevensstroom volledig te begrijpen. Voor gebruikers die geen bevoegdheden hebben, wordt de privacy nog steeds gerespecteerd. Alleen de naam van de werkruimte wordt weergegeven.
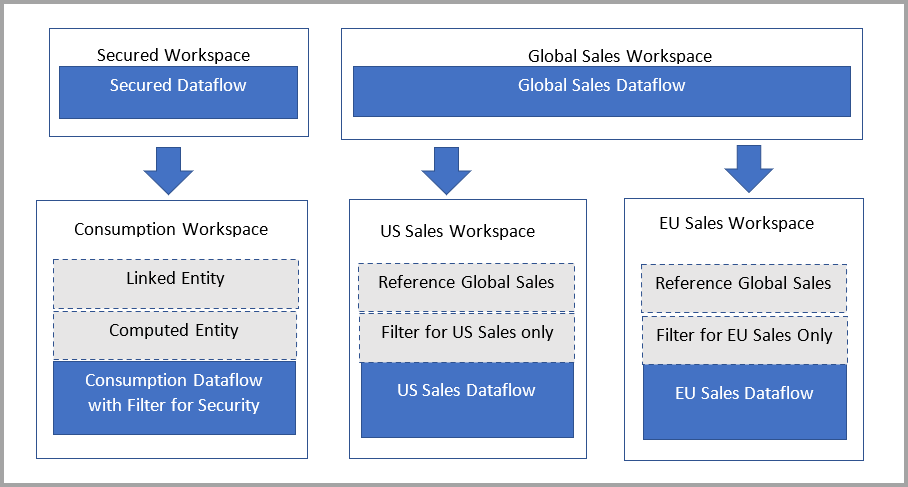
In het volgende diagram ziet u deze installatie. Aan de linkerkant ziet u het architectuurpatroon. Aan de rechterkant ziet u een voorbeeld waarin verkoopgegevens zijn gesplitst en beveiligd per regio.
Vernieuwingstijden voor gegevensstromen verminderen
Stel dat u een grote gegevensstroom hebt, maar u wilt semantische modellen van die gegevensstroom maken en de tijd die nodig is om deze te vernieuwen verkorten. Het duurt meestal lang voordat vernieuwingen zijn voltooid van de gegevensbron naar gegevensstromen naar het semantische model. Langdurige vernieuwingen zijn moeilijk te beheren of te onderhouden.
Oplossing: Gebruik tabellen met expliciet geconfigureerd inschakelen van laden voor de verwijzende tabellen en schakel laden niet uit.
Power BI ondersteunt eenvoudige indeling voor gegevensstromen, zoals gedefinieerd in het begrijpen en optimaliseren van gegevensstromen vernieuwen. Als u gebruik wilt maken van orkestratie, moet u expliciet downstreamgegevensstromen hebben geconfigureerd om Laden in te schakelen.
Het uitschakelen van de belasting is doorgaans alleen geschikt wanneer de overhead van het laden van meer query's het voordeel annuleert van de entiteit waarmee u ontwikkelt.
Hoewel het uitschakelen van de belasting betekent dat Power BI die query niet evalueert, wanneer deze wordt gebruikt als ingrediënten, dat wil zeggen, waarnaar wordt verwezen in andere gegevensstromen, betekent dit ook dat Power BI deze niet behandelt als een bestaande tabel waar we een aanwijzer kunnen bieden en vouwen en queryoptimalisaties kunnen uitvoeren. In dit opzicht is het uitvoeren van transformaties zoals een koppeling of samenvoeging eenvoudigweg een koppeling of samenvoeging van twee gegevensbronquery's. Dergelijke bewerkingen kunnen een negatief effect hebben op de prestaties, omdat Power BI al berekende logica volledig opnieuw moet laden en vervolgens andere logica moet toepassen.
Om de queryverwerking van uw gegevensstroom te vereenvoudigen en ervoor te zorgen dat er engineoptimalisaties plaatsvinden, schakelt u de belasting in en zorgt u ervoor dat de berekeningsengine in Power BI Premium-gegevensstromen is ingesteld op de standaardinstelling, die is geoptimaliseerd.
Als u laden inschakelt, kunt u ook de volledige weergave van herkomst behouden, omdat Power BI een niet-ingeschakelde laadgegevensstroom beschouwt als een nieuw item. Als de herkomst voor u belangrijk is, schakelt u het laden niet uit voor entiteiten of gegevensstromen die zijn verbonden met andere gegevensstromen.
Vernieuwingstijden voor semantische modellen verminderen
Stel dat u een gegevensstroom hebt die groot is, maar dat u er semantische modellen van wilt maken en de indeling wilt verkleinen. Het duurt lang voordat vernieuwingen van de gegevensbron naar gegevensstromen naar semantische modellen zijn voltooid, waardoor de latentie toeneemt.
Oplossing: DirectQuery-gegevensstromen gebruiken
DirectQuery kan worden gebruikt wanneer de ece-instelling (Enhanced Compute Engine) van een werkruimte expliciet is geconfigureerd op Aan. Deze instelling is handig wanneer u gegevens hebt die niet rechtstreeks in een Power BI-model hoeven te worden geladen. Als u de ECE voor het eerst configureert om aan te staan, worden de wijzigingen die DirectQuery toestaan, doorgevoerd tijdens de volgende vernieuwing. U moet deze vernieuwen wanneer u deze inschakelt om wijzigingen onmiddellijk te laten plaatsvinden. Vernieuwingen bij de initiële gegevensstroombelasting kunnen langzamer zijn, omdat Power BI gegevens schrijft naar zowel opslag als een beheerde SQL-engine.
Om samen te vatten, maakt het gebruik van DirectQuery met gegevensstromen de volgende verbeteringen mogelijk voor uw Power BI- en gegevensstromen:
- Vermijd afzonderlijke vernieuwingsschema's: DirectQuery maakt rechtstreeks verbinding met een gegevensstroom, waardoor u geen geïmporteerd semantisch model hoeft te maken. Als zodanig betekent het gebruik van DirectQuery met uw gegevensstromen dat u geen afzonderlijke vernieuwingsschema's meer nodig hebt voor de gegevensstroom en het semantische model om ervoor te zorgen dat uw gegevens worden gesynchroniseerd.
- Gegevens filteren: DirectQuery is handig voor het werken aan een gefilterde weergave van gegevens in een gegevensstroom. Als u gegevens wilt filteren en op deze manier wilt werken met een kleinere subset van de gegevens in uw gegevensstroom, kunt u DirectQuery (en de ECE) gebruiken om gegevensstroomgegevens te filteren en te werken met de gefilterde subset die u nodig hebt.
In het algemeen zorgt DirectQuery voor het ophalen van actuele gegevens in uw semantische model, maar met tragere rapportprestaties in vergelijking met de importmodus. Houd deze aanpak alleen in overweging wanneer:
- Voor uw use-case zijn lage latentiegegevens vereist die afkomstig zijn van uw gegevensstroom.
- De gegevensstroom is omvangrijk.
- Een import zou te tijdrovend zijn.
- U bent bereid om de prestaties in de cache te ruilen voor actuele gegevens.
Oplossing: Gebruik de connector voor gegevensstromen om query folding en incrementele vernieuwing voor het importeren mogelijk te maken.
De unified Dataflows-connector kan de evaluatietijd aanzienlijk verminderen voor stappen die worden uitgevoerd via berekende entiteiten, zoals het uitvoeren van joins, distinct, filters en group by-bewerkingen. Er zijn twee specifieke voordelen:
- Downstreamgebruikers die verbinding maken met de connector voor gegevensstromen in Power BI Desktop, kunnen profiteren van betere prestaties in ontwerpscenario's, omdat de nieuwe connector ondersteuning biedt voor het vouwen van query's.
- Semantische bewerkingen voor het vernieuwen van modellen kunnen ook worden gevouwen naar de verbeterde berekeningsengine, wat betekent dat zelfs incrementeel vernieuwen van een semantisch model kan worden gevouwen naar een gegevensstroom. Deze mogelijkheid verbetert de vernieuwingsprestaties en vermindert mogelijk de latentie tussen vernieuwingscycli.
Als u deze functie wilt inschakelen voor elke Premium-gegevensstroom, moet u ervoor zorgen dat de berekeningsengine expliciet is ingesteld op Aan. Gebruik vervolgens de gegevensstromenconnector in Power BI Desktop. U moet de versie van augustus 2021 van Power BI Desktop of hoger gebruiken om te profiteren van deze functie.
Als u deze functie wilt gebruiken voor bestaande oplossingen, moet u een Premium- of Premium-abonnement per gebruiker hebben. Mogelijk moet u ook enkele wijzigingen aanbrengen in uw gegevensstroom, zoals beschreven in Het gebruik van de verbeterde berekeningsengine. U moet eventuele bestaande Power Query-query's bijwerken om de nieuwe connector te kunnen gebruiken door in de PowerBI.Dataflows te vervangen door PowerPlatform.Dataflows.
Complexe creatie van gegevensstromen in Power Query
Stel dat u een gegevensstroom hebt die miljoenen rijen met gegevens bevat, maar u wilt hiermee complexe bedrijfslogica en -transformaties bouwen. U wilt de aanbevolen procedures volgen voor het werken met grote gegevensstromen. U hebt ook de voorbeeldweergaven van de gegevensstroom nodig om snel uit te voeren. Maar u hebt tientallen kolommen en miljoenen rijen met gegevens.
Oplossing: Schemaweergave gebruiken
U kunt de schemaweergave gebruiken, die is ontworpen om uw stroom te optimaliseren wanneer u aan bewerkingen op schemaniveau werkt door de kolominformatie voor en het midden van uw query te plaatsen. De schemaweergave biedt contextuele interacties om uw gegevensstructuur vorm te geven. Schemaweergave biedt ook bewerkingen met een lagere latentie omdat alleen de metagegevens van de kolom moeten worden berekend en niet de volledige gegevensresultaten.
Werken met grotere gegevensbronnen
Stel dat u een query uitvoert op het bronsysteem, maar u geen directe toegang tot het systeem wilt bieden of de toegang wilt democratiseren. U wilt deze in een gegevensstroom plaatsen.
Oplossing 1: Een weergave gebruiken voor de query of de query optimaliseren
Door een geoptimaliseerde gegevensbron en query te gebruiken, is dat uw beste optie. Vaak werkt de gegevensbron het beste met query's die hiervoor zijn bedoeld. Power Query verbetert de mogelijkheden voor het vouwen van query's om deze workloads te delegeren. Power BI biedt ook stapsgewijze indicatoren in Power Query Online. Lees meer over typen indicatoren in de documentatie voor stapsgewijze indicatoren.
Oplossing 2: Systeemeigen query gebruiken
U kunt ook de functie Value.NativeQuery() M gebruiken. U stelt EnableFolding=true in de derde parameter in. Native Query wordt gedocumenteerd op deze website voor de Postgres-connector. Het werkt ook voor de SQL Server-connector.
Oplossing 3: De gegevensstroom opsplitsen in opname- en verbruiksgegevensstromen om te profiteren van de ECE- en gekoppelde entiteiten
Door een gegevensstroom in afzonderlijke opname- en verbruiksgegevensstromen te verbreken, kunt u profiteren van de ECE- en gekoppelde entiteiten. Meer informatie over dit patroon en andere vindt u in de documentatie over aanbevolen procedures.
Zorg ervoor dat klanten waar mogelijk gegevensstromen gebruiken
Stel dat u veel gegevensstromen hebt die algemene doeleinden dienen, zoals conforme dimensies zoals klanten, gegevenstabellen, producten en geografische gebieden. Gegevensstromen zijn al beschikbaar op het lint voor Power BI. In het ideale voorbeeld wilt u dat klanten voornamelijk gebruikmaken van de gegevensstromen die u hebt gemaakt.
Oplossing: Goedkeuring gebruiken om gegevensstromen te certificeren en te promoten
Zie Goedkeuring: Power BI-inhoud promoten en certificeren voor meer informatie over hoe goedkeuring werkt.
Programmeerbaarheid en automatisering in Power BI-gegevensstromen
Stel dat u zakelijke vereisten hebt voor het automatiseren van import-, export- of vernieuwingen, en meer indeling en acties buiten Power BI. U hebt een aantal opties om dit in te schakelen, zoals beschreven in de volgende tabel.
| Type | Mechanisme |
|---|---|
| Gebruik de Power Automate-sjablonen. | Geen code |
| Automatiseringsscripts gebruiken in PowerShell. | Automatiseringsscripts |
| Bouw uw eigen bedrijfslogica met behulp van de API's. | Rest API |
Voor meer informatie over het vernieuwen, zie Gegevensstromen vernieuwen en optimaliseren.
Zorg ervoor dat u gegevens verder in het proces beveiligt
U kunt vertrouwelijkheidslabels gebruiken om een gegevensclassificatie toe te passen en regels die u hebt geconfigureerd voor downstreamitems die verbinding maken met uw gegevensstromen. Zie vertrouwelijkheidslabels in Power BI voor meer informatie over vertrouwelijkheidslabels. Zie Downstream-overerving van vertrouwelijkheidslabels in Power BI om de overerving van vertrouwelijkheidslabels te bekijken.
Ondersteuning voor meerdere geografische gebieden
Veel klanten hebben tegenwoordig behoefte aan gegevenssoevereine en verblijfsvereisten. U kunt een handmatige configuratie voor uw werkruimte voor gegevensstromen voltooien om meerdere geografische gebieden te hebben.
Gegevensstromen bieden ondersteuning voor meerdere geografische gebieden wanneer ze de functie Bring Your Own Storage-account gebruiken. Deze functie wordt beschreven in Het configureren van gegevensstroomopslag voor het gebruik van Azure Data Lake Gen 2. De werkruimte moet leeg zijn voordat u deze mogelijkheid koppelt. Met deze specifieke configuratie kunt u gegevensstroomgegevens opslaan in specifieke geografische regio's van uw keuze.
Zorg ervoor dat u gegevensassets achter een virtueel netwerk beveiligt
Veel klanten hebben tegenwoordig behoefte aan het beveiligen van uw gegevensassets achter een privé-eindpunt. Hiervoor gebruikt u virtuele netwerken en een gateway om compatibel te blijven. In de volgende tabel wordt de huidige ondersteuning voor virtuele netwerken beschreven en wordt uitgelegd hoe u gegevensstromen gebruikt om compatibel te blijven en uw gegevensassets te beveiligen.
| Scenario | Status |
|---|---|
| Gegevensbronnen van virtuele netwerken lezen via een on-premises gateway. | Ondersteund via een on-premises gateway |
| Schrijf gegevens naar een vertrouwelijkheidslabelaccount achter een virtueel netwerk met behulp van een on-premises gateway. | Op het moment niet ondersteund |
Gerelateerde inhoud
De volgende artikelen bevatten meer informatie over gegevensstromen en Power BI: