Richtlijnen voor DirectQuery-modellen in Power BI Desktop
Dit artikel is gericht op gegevensmodelleerders die Power BI DirectQuery-modellen ontwikkelen, ontwikkeld met behulp van Power BI Desktop of de Power BI-service. Hierin worden gebruiksvoorbeelden, beperkingen en richtlijnen van DirectQuery beschreven. De richtlijnen zijn ontworpen om u te helpen bepalen of DirectQuery de juiste modus voor uw model is en om de prestaties van uw rapporten te verbeteren op basis van DirectQuery-modellen. Dit artikel is van toepassing op DirectQuery-modellen die worden gehost in de Power BI-service of Power BI Report Server.
Dit artikel is niet bedoeld om een volledige discussie te bieden over het ontwerp van directQuery-modellen. Raadpleeg het artikel DirectQuery-modellen in Power BI Desktop voor een inleiding. Raadpleeg het technisch document over DirectQuery in SQL Server 2016 Analysis Services voor meer informatie. Houd er rekening mee dat in het technisch document wordt beschreven hoe u DirectQuery gebruikt in SQL Server Analysis Services. Veel van de inhoud is echter nog steeds van toepassing op Power BI DirectQuery-modellen.
Notitie
Zie de richtlijnen voor Power BI-modellering voor Power Platform voor overwegingen bij het gebruik van de DirectQuery-opslagmodus voor Dataverse.
In dit artikel worden samengestelde modellen niet rechtstreeks behandeld. Een samengesteld model bestaat uit ten minste één DirectQuery-bron en mogelijk meer. De richtlijnen die in dit artikel worden beschreven, zijn nog steeds van belang voor het ontwerp van samengestelde modellen, althans gedeeltelijk. De gevolgen van het combineren van importtabellen met DirectQuery-tabellen vallen echter niet binnen het bereik van dit artikel. Zie Samengestelde modellen gebruiken in Power BI Desktop voor meer informatie.
Het is belangrijk om te begrijpen dat DirectQuery-modellen een andere workload opleggen aan de Power BI-omgeving (Power BI-service of Power BI Report Server) en ook aan de onderliggende gegevensbronnen. Als u bepaalt dat DirectQuery de juiste ontwerpbenadering is, raden we u aan om de juiste personen in het project te betrekken. We zien vaak dat een succesvolle DirectQuery-modelimplementatie het resultaat is van een team van IT-professionals die nauw samenwerken. Het team bestaat meestal uit modelontwikkelaars en de brondatabasebeheerders. Het kan ook betrekking hebben op gegevensarchitecten en datawarehouse- en ETL-ontwikkelaars. Optimalisaties moeten vaak rechtstreeks op de gegevensbron worden toegepast om goede prestatieresultaten te bereiken.
Prestaties van gegevensbronnen optimaliseren
De relationele databasebron kan op verschillende manieren worden geoptimaliseerd, zoals beschreven in de volgende lijst met opsommingstekens.
Notitie
We begrijpen dat niet alle modelleerders over de machtigingen of vaardigheden beschikken om een relationele database te optimaliseren. Hoewel het de voorkeurslaag is om de gegevens voor te bereiden op een DirectQuery-model, kunnen sommige optimalisaties ook worden bereikt in het modelontwerp, zonder de brondatabase te wijzigen. De beste optimalisatieresultaten worden echter vaak bereikt door optimalisaties toe te passen op de brondatabase.
Ervoor zorgen dat de gegevensintegriteit is voltooid: het is met name belangrijk dat dimensietabellen een kolom met unieke waarden (dimensiesleutel) bevatten die is toegewezen aan de feitentabel(s). Het is ook belangrijk dat feitentabeldimensiekolommen geldige dimensiewaarden bevatten. Hiermee kunnen efficiëntere modelrelaties worden geconfigureerd die overeenkomende waarden aan beide zijden van relaties verwachten. Wanneer de brongegevens geen integriteit hebben, wordt aanbevolen dat er een 'onbekende' dimensierecord wordt toegevoegd om de gegevens effectief te herstellen. U kunt bijvoorbeeld een rij toevoegen aan de
Producttabel om een onbekend product weer te geven en deze vervolgens een buitenbereiksleutel toe te wijzen, zoals -1. Als rijen in de tabelSaleseen ontbrekende productcodewaarde bevatten, vervangt u deze door -1. Het zorgt ervoor dat elkeSalestabelproductcodewaarde een bijbehorende rij in deProducttabel heeft.Indexen toevoegen: Definieer de juiste indexen (in tabellen of weergaven) om het efficiënt ophalen van gegevens voor het verwachte filteren en groeperen van rapportvisuals te ondersteunen. Voor SQL Server-, Azure SQL Database- of Azure Synapse Analytics-bronnen (voorheen SQL Data Warehouse) raadpleegt u de architectuur en ontwerphandleiding voor SQL Server-indexen voor nuttige informatie over het ontwerpen van indexen. Zie Aan de slag met Columnstore voor realtime operationele analyses voor vluchtige SQL Server- of Azure SQL Database-bronnen.
Gedistribueerde tabellen ontwerpen: Voor Azure Synapse Analytics-bronnen (voorheen SQL Data Warehouse) die gebruikmaken van MPP-architectuur (Massively Parallel Processing), kunt u overwegen om grote feitentabellen te configureren als hash gedistribueerd en dimensietabellen om te repliceren over alle rekenknooppunten. Zie Richtlijnen voor het ontwerpen van gedistribueerde tabellen in Azure Synapse Analytics (voorheen SQL Data Warehouse) voor meer informatie.
Ervoor zorgen dat de vereiste gegevenstransformaties worden gerealiseerd: Voor relationele SQL Server-databasebronnen (en andere relationele databasebronnen) kunnen berekende kolommen worden toegevoegd aan tabellen. Deze kolommen zijn gebaseerd op een expressie, zoals Hoeveelheid vermenigvuldigd met Prijs per eenheid. Berekende kolommen kunnen worden behouden (gerealiseerd) en, zoals gewone kolommen, soms kunnen ze worden geïndexeerd. Zie Indexen voor berekende kolommen voor meer informatie.
Overweeg ook geïndexeerde weergaven die vooraf feitentabelgegevens kunnen aggregeren op een hoger niveau. Als de
Salestabel bijvoorbeeld gegevens op orderregelniveau opslaat, kunt u een weergave maken om deze gegevens samen te vatten. De weergave kan zijn gebaseerd op eenSELECT-instructie waarmee deSalestabelgegevens worden gegroepeerd op datum (op maandniveau), klant, product en metingen worden samengevat, zoals verkoop, hoeveelheid, enzovoort. De weergave kan vervolgens worden geïndexeerd. Zie Geïndexeerde weergaven maken voor SQL Server- of Azure SQL Database-bronnen.Materialiseer een datumtabel: een algemene modelleringsvereiste omvat het toevoegen van een datumtabel ter ondersteuning van filteren op basis van tijd. Als u de bekende op tijd gebaseerde filters in uw organisatie wilt ondersteunen, maakt u een tabel in de brondatabase en zorgt u ervoor dat deze wordt geladen met een reeks datums die de feitentabeldatums omvatten. Zorg er ook voor dat deze kolommen bevat voor nuttige perioden, zoals jaar, kwartaal, maand, week, enzovoort.
Modelontwerp optimaliseren
Een DirectQuery-model kan op veel manieren worden geoptimaliseerd, zoals beschreven in de volgende lijst met opsommingstekens.
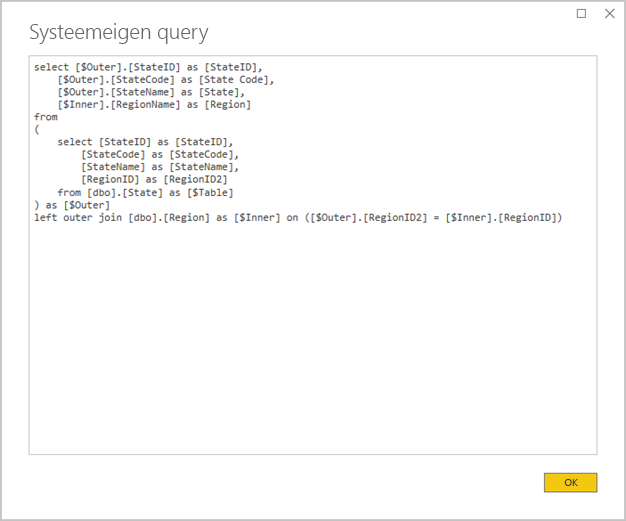
Vermijd complexe Power Query-query's: een efficiënt modelontwerp kan worden bereikt door de noodzaak te verwijderen voor de Power Query-query's om transformaties toe te passen. Dit betekent dat elke query wordt toegewezen aan één relationele databasebrontabel of -weergave. U kunt een voorbeeld bekijken van een weergave van de werkelijke SQL-query-instructie voor een toegepaste Power Query-stap door de optie Systeemeigen query weergeven te selecteren.
Bekijk het gebruik van berekende kolommen en wijzigingen in het gegevenstype: DirectQuery-modellen ondersteunen het toevoegen van berekeningen en Power Query-stappen om gegevenstypen te converteren. Betere prestaties worden echter vaak bereikt door transformatieresultaten te materialiseren in de relationele databasebron, indien mogelijk.
Gebruik geen relatieve datumfiltering van Power Query: het is mogelijk om relatieve datumfiltering in een Power Query-query te definiëren. Als u bijvoorbeeld wilt ophalen naar de verkooporders die in het afgelopen jaar zijn gemaakt (ten opzichte van de datum van vandaag). Dit type filter wordt als volgt omgezet in een inefficiënte systeemeigen query:
… from [dbo].[Sales] as [_] where [_].[OrderDate] >= convert(datetime2, '2018-01-01 00:00:00') and [_].[OrderDate] < convert(datetime2, '2019-01-01 00:00:00'))Een betere ontwerpmethode is het opnemen van kolommen met relatieve tijd in de datumtabel. In deze kolommen worden offsetwaarden opgeslagen ten opzichte van de huidige datum. In een kolom
RelativeYearvertegenwoordigt de waarde nul bijvoorbeeld het huidige jaar, -1 het vorige jaar, enzovoort. Bij voorkeur wordt de kolomRelativeYeargerealiseerd in de datumtabel. Hoewel het minder efficiënt is, kan het ook worden toegevoegd als een berekende modelkolom, op basis van de expressie met behulp van de DAX-functies TODAY en DATE .Metingen eenvoudighouden: in eerste instantie is het raadzaam om metingen te beperken tot eenvoudige aggregaties. De statistische functies omvatten SOM, AANTAL, MIN, MAX en GEMIDDELDE. Als de metingen dan voldoende responsief zijn, kunt u experimenteren met complexere metingen, maar aandacht besteden aan de prestaties voor elke meting. Hoewel de DAX-functie CALCULATE kan worden gebruikt om geavanceerde meetexpressies te produceren waarmee filtercontext wordt bewerkt, kunnen ze dure systeemeigen query's genereren die niet goed presteren.
Relaties voor berekende kolommen vermijden: modelrelaties kunnen slechts één kolom in één tabel koppelen aan één kolom in een andere tabel. Soms is het echter nodig om tabellen te relateren met behulp van meerdere kolommen. De tabellen
SalesenGeographyzijn bijvoorbeeld gerelateerd aan twee kolommen:CountryRegionenCity. Als u een relatie tussen de tabellen wilt maken, is één kolom vereist en moet de kolom in deGeographytabel unieke waarden bevatten. Als u het land/de regio en de plaats samenvoegt met een scheidingsteken voor afbreekstreepjes, kan dit resultaat worden bereikt.De gecombineerde kolom kan worden gemaakt met een aangepaste Power Query-kolom of in het model als een berekende kolom. Het moet echter worden vermeden omdat de berekeningsexpressie wordt ingesloten in de bronquery's. Het is niet alleen inefficiënt, maar voorkomt vaak het gebruik van indexen. Voeg in plaats daarvan gerealiseerde kolommen toe aan de relationele databasebron en overweeg deze te indexeren. U kunt ook overwegen surrogaatsleutelkolommen toe te voegen aan dimensietabellen. Dit is een veelvoorkomende procedure in relationele datawarehouse-ontwerpen.
Er is één uitzondering op deze richtlijnen en dit betreft het gebruik van de DAX-functie COMBINEVALUES . Het doel van deze functie is het ondersteunen van modelrelaties met meerdere kolommen. In plaats van een expressie te genereren die door de relatie wordt gebruikt, wordt er een SQL-joinpredicaat met meerdere kolommen gegenereerd.
Vermijd relaties in kolommen met unieke id's: Power BI biedt geen systeemeigen ondersteuning voor het gegevenstype Unieke id (GUID). Wanneer u een relatie definieert tussen kolommen van dit type, genereert Power BI een bronquery met een join met betrekking tot een cast. Deze querytijdgegevensconversie leidt vaak tot slechte prestaties. Totdat dit geval is geoptimaliseerd, is de enige tijdelijke oplossing het materialiseren van kolommen van een alternatief gegevenstype in de onderliggende database.
De enkelzijdige kolom van relaties verbergen: De enkelzijdige kolom van een relatie moet verborgen worden. (Dit is meestal de primaire sleutelkolom van dimensietabellen.) Wanneer deze verborgen is, is deze niet beschikbaar in het deelvenster Gegevens en kan deze dus niet worden gebruikt om een visual te configureren. De kolom aan de veelzijde kan zichtbaar blijven als het handig is om rapporten te groeperen of te filteren op de kolomwaarden. Denk bijvoorbeeld aan een model waarin een relatie bestaat tussen
SalesenProducttabellen. De relatiekolommen bevatten product-SKU-waarden (Stock-Keeping Unit). Als de product-SKU moet worden toegevoegd aan visuals, moet deze alleen zichtbaar zijn in de tabelSales. Wanneer deze kolom wordt gebruikt om te filteren of groeperen in een visual, genereert Power BI een query die niet hoeft te worden gekoppeld aan deSalesenProducttabellen.Relaties instellen om integriteit af te dwingen: de eigenschap referentiële integriteit aannemen eigenschap van DirectQuery-relaties bepaalt of Power BI bronquery's genereert met behulp van een
INNER JOINin plaats van eenOUTER JOIN. De queryprestaties worden over het algemeen verbeterd, hoewel deze afhankelijk is van de specifieke kenmerken van de relationele databasebron. Zie Referentiële integriteitsinstellingen aannemen in Power BI Desktop voor meer informatie.Vermijd het gebruik van bidirectionele relatiefilters: Het gebruik van bidirectionele relatiefiltering kan leiden tot queryverklaringen die ondermaats presteren. Gebruik deze relatiefunctie alleen wanneer dat nodig is en dit is meestal het geval bij het implementeren van een veel-op-veel-relatie in een overbruggingstabel. Zie Relaties met een veel-op-veel-kardinaliteit in Power BI Desktop voor meer informatie.
Parallelle query's beperken: u kunt het maximum aantal verbindingen instellen dat DirectQuery wordt geopend voor elke onderliggende gegevensbron. Het bepaalt het aantal query's dat gelijktijdig naar de gegevensbron wordt verzonden.
- De instelling is alleen ingeschakeld wanneer er ten minste één DirectQuery-bron in het model is. De waarde is van toepassing op alle DirectQuery-bronnen en op nieuwe DirectQuery-bronnen die aan het model worden toegevoegd.
- Als u de waarde maximumverbindingen per gegevensbron verhoogt, zorgt u ervoor dat er meer query's (maximaal het opgegeven maximum aantal) kunnen worden verzonden naar de onderliggende gegevensbron. Dit is handig wanneer meerdere visuals zich op één pagina bevinden of dat veel gebruikers tegelijkertijd toegang hebben tot een rapport. Zodra het maximum aantal verbindingen is bereikt, worden verdere query's in de wachtrij geplaatst totdat er een verbinding beschikbaar is. Het verhogen van deze limiet leidt tot meer belasting van de onderliggende gegevensbron, dus de instelling is niet gegarandeerd om de algehele prestaties te verbeteren.
- Wanneer het model wordt gepubliceerd naar Power BI, is het maximum aantal gelijktijdige query's dat naar de onderliggende gegevensbron wordt verzonden, ook afhankelijk van de omgeving. Verschillende omgevingen (zoals Power BI, Power BI Premium of Power BI Report Server) kunnen verschillende doorvoerbeperkingen opleggen. Zie Microsoft Fabric-capaciteitslicenties en capaciteiten configureren en beheren in Power BI Premium voor meer informatie over beperkingen van capaciteitsresources.
Belangrijk
Soms verwijst dit artikel naar Power BI Premium of de capaciteitsabonnementen (P-SKU's). Houd er rekening mee dat Microsoft momenteel aankoopopties consolideert en de Power BI Premium-SKU's per capaciteit buiten gebruik stelt. Nieuwe en bestaande klanten moeten overwegen om in plaats daarvan F-SKU's (Fabric-capaciteitsabonnementen) aan te schaffen.
Zie Belangrijke update voor Power BI Premium-licenties en veelgestelde vragen over Power BI Premium voor meer informatie.
Rapportontwerpen optimaliseren
Rapporten op basis van een semantisch DirectQuery-model kunnen op veel manieren worden geoptimaliseerd, zoals beschreven in de volgende lijst met opsommingstekens.
- Technieken voor het verminderen van query's inschakelen: Power BI Desktop Opties en instellingen bevat een pagina met queryreductie. Deze pagina heeft drie handige opties. Het is mogelijk om kruislings markeren en kruislings filteren standaard uit te schakelen, hoewel het kan worden overschreven door interacties te bewerken. Het is ook mogelijk om een knop Toepassen weer te geven op slicers en filters. De slicer- of filteropties worden pas toegepast wanneer de rapportgebruiker op de knop klikt. Als u deze opties inschakelt, raden we u aan dit te doen wanneer u het rapport voor het eerst maakt.
-
Pas eerst filters toe: bij het ontwerpen van rapporten raden we u aan alle toepasselijke filters toe te passen, op rapport-, pagina- of visualniveau, voordat u velden toe te wijzen aan de visuele velden. In plaats van bijvoorbeeld de metingen
CountryRegionenSaleste slepen en vervolgens op een bepaald jaar te filteren, past u eerst het filter toe op hetYearveld. Dit komt doordat elke stap van het bouwen van een visual een query verzendt en hoewel het mogelijk is om vervolgens nog een wijziging aan te brengen voordat de eerste query is voltooid, wordt de onderliggende gegevensbron nog steeds onnodig belast. Door filters vroeg toe te passen, worden deze tussenliggende query's doorgaans goedkoper en sneller. Bovendien kan het niet vroeg toepassen van filters leiden tot een overschrijden van de limiet van 1 miljoen rijen, zoals beschreven in over DirectQuery. - Het aantal visuals op een pagina beperken: wanneer een rapportpagina wordt geopend (en wanneer paginafilters worden toegepast) worden alle visuals op een pagina vernieuwd. Er is echter een limiet voor het aantal query's dat parallel kan worden verzonden, opgelegd door de Power BI-omgeving en de instelling Maximumverbindingen per gegevensbronmodel , zoals hierboven beschreven. Naarmate het aantal paginavisuals toeneemt, is er dus een hogere kans dat ze op een seriële manier worden vernieuwd. Het verhoogt de tijd die nodig is om de hele pagina te vernieuwen en verhoogt ook de kans dat visuals inconsistente resultaten kunnen weergeven (voor vluchtige gegevensbronnen). Om deze redenen is het raadzaam om het aantal visuals op elke pagina te beperken en in plaats daarvan eenvoudigere pagina's te hebben. Als u meerdere kaartvisuals vervangt door één kaartvisual met meerdere rijen, kunt u een vergelijkbare pagina-indeling bereiken.
- Interactie tussen visuals uitschakelen: voor kruislings markeren en kruislings filteren moeten query's worden verzonden naar de onderliggende bron. Tenzij deze interacties nodig zijn, is het raadzaam ze uit te schakelen als de tijd die nodig is om te reageren op selecties van gebruikers onredelijk lang zou zijn. Deze interacties kunnen worden uitgeschakeld, ofwel voor het hele rapport (zoals hierboven beschreven voor opties voor het verminderen van query's) of per geval. Zie Hoe visuals elkaar kruislings filteren in een Power BI-rapport voor meer informatie.
Naast de bovenstaande lijst met optimalisatietechnieken kan elk van de volgende rapportagemogelijkheden bijdragen aan prestatieproblemen:
Filters voor metingen: Visualisaties met metingen (of kolomaggregaties) kunnen filters hebben die op die metingen worden toegepast. In de onderstaande visual ziet u bijvoorbeeld Verkoop per categorie, maar alleen voor categorieën met meer dan $ 15 miljoen verkoop.
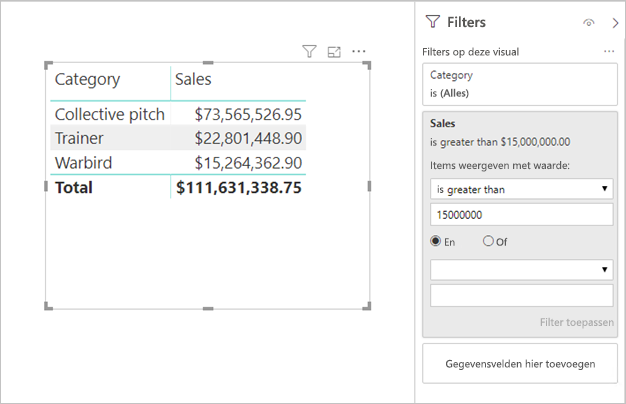
Dit kan ertoe leiden dat er twee query's naar de onderliggende bron worden verzonden:
- Met de eerste query worden de categorieën opgehaald die voldoen aan de voorwaarde (Omzet > $ 15 miljoen)
- De tweede query haalt vervolgens de benodigde gegevens voor de visual op en voegt de categorieën die aan de voorwaarde voldoen toe aan de
WHERE-clausule.
Het werkt over het algemeen prima als er honderden of duizenden categorieën zijn, zoals in dit voorbeeld. De prestaties kunnen echter afnemen als het aantal categorieën veel groter is (en de query mislukt zelfs als er meer dan 1 miljoen categorieën aan de voorwaarde voldoen, vanwege de hierboven besproken limiet van 1 miljoen rijen).
TopN-filters: Geavanceerde filters kunnen worden gedefinieerd om alleen te filteren op de hoogste (of onderste) N-waarden die zijn gerangschikt op basis van een meting. Als u bijvoorbeeld alleen de bovenste vijf categorieën in de bovenstaande visual wilt weergeven. Net als bij de metingfilters leidt dit er ook toe dat er twee query's naar de onderliggende gegevensbron worden verzonden. De eerste query retourneert echter alle categorieën uit de onderliggende bron en vervolgens wordt de bovenste N bepaald op basis van de geretourneerde resultaten. Afhankelijk van de kardinaliteit van de betrokken kolom kan dit leiden tot prestatieproblemen (of queryfouten vanwege de limiet van 1 miljoen rijen).
Mediaan: Over het algemeen wordt elke aggregatie (zoals Som, Unieke Aantal, enzovoort) naar de onderliggende bron doorgegeven. Dit geldt echter niet voor Mediaan, omdat deze statistische functie niet wordt ondersteund door de onderliggende bron. In dergelijke gevallen worden detailgegevens opgehaald uit de onderliggende bron en evalueert Power BI de mediaan uit de geretourneerde resultaten. Het is prima wanneer de mediaan moet worden berekend over een relatief klein aantal resultaten, maar prestatieproblemen (of queryfouten vanwege de limiet van 1 miljoen rijen) optreden als de kardinaliteit groot is. De gemiddelde bevolking van het land/de regio kan bijvoorbeeld redelijk zijn, maar de mediaanverkoopprijs is mogelijk niet.
slicers met meerdere selecties: Het toestaan van meervoudige selectie in slicers en filters kan prestatieproblemen veroorzaken. De reden hiervoor is dat wanneer de gebruiker extra sliceritems selecteert (bijvoorbeeld tot de 10 producten waarin ze geïnteresseerd zijn), elke nieuwe selectie resulteert in een nieuwe query die naar de onderliggende bron wordt verzonden. Hoewel de gebruiker het volgende item kan selecteren voordat de query wordt voltooid, leidt dit tot extra belasting van de onderliggende bron. Deze situatie kan worden vermeden door de knop Toepassen weer te geven, zoals hierboven beschreven in de technieken voor het verminderen van query's.
Totals in tabellen en matrices: Tabellen en matrices tonen standaard totalen en subtotalen. In veel gevallen moeten extra query's naar de onderliggende bron worden verzonden om de waarden voor de totalen te verkrijgen. Deze is van toepassing wanneer u count distinct of mediaanaggregaties gebruikt en in alle gevallen wanneer u DirectQuery gebruikt via SAP HANA of SAP Business Warehouse. Dergelijke totalen moeten worden uitgeschakeld (met behulp van het deelvenster Opmaak) als dat niet nodig is.
Converteren naar een samengesteld model
De voordelen van Import- en DirectQuery-modellen kunnen worden gecombineerd tot één model door de opslagmodus van de modeltabellen te configureren. De tabelopslagmodus kan Import of DirectQuery zijn, of beide, ook wel Dual genoemd. Wanneer een model tabellen met verschillende opslagmodi bevat, wordt dit een samengesteld model genoemd. Zie Samengestelde modellen gebruiken in Power BI Desktop voor meer informatie.
Er zijn veel functionele en prestatieverbeteringen die kunnen worden bereikt door een DirectQuery-model te converteren naar een samengesteld model. Een samengesteld model kan meer dan één DirectQuery-bron integreren en kan ook aggregaties bevatten. Aggregatietabellen kunnen worden toegevoegd aan DirectQuery-tabellen om een samengevatte weergave van de tabel te importeren. Ze kunnen aanzienlijke prestatieverbeteringen bereiken wanneer visuals statistische gegevens op een hoger niveau opvragen. Zie Aggregaties in Power BI Desktop voor meer informatie.
Gebruikers informeren
Het is belangrijk om uw gebruikers te informeren over het efficiënt werken met rapporten op basis van semantische DirectQuery-modellen. Uw rapportauteurs moeten worden geïnformeerd over de inhoud die wordt beschreven in de sectie Rapportontwerpen optimaliseren.
U wordt aangeraden uw rapportgebruikers te informeren over uw rapporten die zijn gebaseerd op semantische DirectQuery-modellen. Het kan handig zijn voor hen om inzicht te hebben in de algemene gegevensarchitectuur, inclusief eventuele relevante beperkingen die in dit artikel worden beschreven. Laat ze weten dat vernieuwingsreacties en interactieve filters soms traag kunnen zijn. Wanneer rapportgebruikers begrijpen waarom prestatievermindering plaatsvindt, verliezen ze minder waarschijnlijk vertrouwen in de rapporten en gegevens.
Wanneer u rapporten over vluchtige gegevensbronnen levert, moet u rapportgebruikers informeren over het gebruik van de knop Vernieuwen. Laat ze ook weten dat het mogelijk is om inconsistente resultaten te zien en dat een vernieuwing van het rapport inconsistenties op de rapportpagina kan oplossen.
Gerelateerde inhoud
Raadpleeg de volgende bronnen voor meer informatie over DirectQuery: