Richtlijnen voor samengestelde modellen in Power BI Desktop
Dit artikel is bedoeld voor gegevensmodelleerders die samengestelde Power BI-modellen ontwikkelen. Hierin worden gebruiksvoorbeelden voor samengestelde modellen beschreven en vindt u ontwerprichtlijnen. Met name de richtlijnen kunnen u helpen bepalen of een samengesteld model geschikt is voor uw oplossing. Als dat zo is, helpt dit artikel u ook bij het ontwerpen van optimale samengestelde modellen en rapporten.
Notitie
In dit artikel wordt geen inleiding tot samengestelde modellen behandeld. Als u niet volledig bekend bent met samengestelde modellen, raden we u aan eerst het artikel Samengestelde modellen gebruiken in Power BI Desktop te lezen.
Omdat samengestelde modellen bestaan uit ten minste één DirectQuery-bron, is het ook belangrijk dat u een grondig begrip hebt van modelrelaties, DirectQuery-modellen en Richtlijnen voor het ontwerpen van DirectQuery-modellen.
Use cases voor samengesteld model
Een samengesteld model combineert per definitie meerdere brongroepen. Een brongroep kan geïmporteerde gegevens of een verbinding met een DirectQuery-bron vertegenwoordigen. Een DirectQuery-bron kan een relationele database of een ander tabellair model zijn. Dit kan een semantisch Power BI-model of een tabellair Analysis Services-model zijn. Wanneer een tabellair model verbinding maakt met een ander tabellair model, wordt dit ook wel ketening genoemd. Zie Samengestelde modellen gebruiken in Power BI Desktopvoor meer informatie.
Notitie
Wanneer een model verbinding maakt met een tabellair model, maar dit niet uitbreidt met aanvullende gegevens, is het geen samengesteld model. In dit geval is het een DirectQuery-model dat verbinding maakt met een extern model, dus het bestaat uit slechts de ene brongroep. U kunt dit type model maken om eigenschappen van bronmodelobjecten te wijzigen, zoals een tabelnaam, sorteervolgorde voor kolommen, opmaaktekenreeksen of andere.
Verbinding maken met tabellaire modellen is met name relevant bij het uitbreiden van een semantisch bedrijfsmodel (als het een semantisch Power BI-model of Analysis Services-model is). Een semantisch bedrijfsmodel is essentieel voor de ontwikkeling en werking van een datawarehouse. Het biedt een abstractielaag over de gegevens in het datawarehouse om bedrijfsdefinities en terminologie te presenteren. Het wordt vaak gebruikt als een koppeling tussen fysieke gegevensmodellen en rapportagehulpprogramma's, zoals Power BI. In de meeste organisaties wordt het beheerd door een centraal team en daarom wordt het beschreven als onderneming. Zie het enterprise BI-gebruiksscenario voor meer informatie.
U kunt overwegen om een samengesteld model te ontwikkelen in de volgende situaties:
- Uw model kan een DirectQuery-model zijn en u wilt de prestaties verbeteren. In een samengesteld model kunt u de prestaties verbeteren door de juiste opslag in te stellen voor elke tabel. U kunt ook door de gebruiker gedefinieerde aggregaties toevoegen. Beide optimalisaties worden verderop in dit artikel beschreven.
- U wilt een DirectQuery-model combineren met meer gegevens, die moeten worden geïmporteerd in het model. U kunt geïmporteerde gegevens laden uit een andere gegevensbron of uit berekende tabellen.
- U wilt twee of meer DirectQuery-gegevensbronnen combineren in één model. Deze bronnen kunnen relationele databases of andere tabellaire modellen zijn.
Notitie
Samengestelde modellen kunnen geen verbindingen met bepaalde externe analytische databases bevatten. Deze databases omvatten SAP Business Warehouse en SAP HANA bij het behandelen van SAP HANA als multidimensionale bron.
Andere ontwerpopties voor modellen evalueren
Hoewel samengestelde Power BI-modellen bepaalde ontwerpuitdagingen kunnen oplossen, kunnen ze bijdragen aan trage prestaties. In sommige gevallen kunnen er ook onverwachte berekeningsresultaten optreden (verderop in dit artikel beschreven). Om deze redenen evalueert u andere ontwerpopties voor modellen wanneer deze bestaan.
Waar mogelijk kunt u het beste een model ontwikkelen in de importmodus. Deze modus biedt de grootste flexibiliteit van het ontwerp en de beste prestaties. Uitdagingen met betrekking tot grote gegevensvolumes of rapportage over bijna realtime gegevens kunnen echter niet altijd worden opgelost door importmodellen. In beide gevallen kunt u een DirectQuery-model overwegen, mits uw gegevens worden opgeslagen in één gegevensbron die wordt ondersteund door de DirectQuery-modus. Zie DirectQuery-modellen in Power BI Desktop voor meer informatie.
Tip
Als u alleen een bestaand tabellair model wilt uitbreiden met meer gegevens, indien mogelijk, voegt u die gegevens toe aan de bestaande gegevensbron.
Tabelopslagmodus
In een samengesteld model kunt u de opslagmodus voor elke tabel instellen (met uitzondering van berekende tabellen).
- DirectQuery-: u wordt aangeraden deze modus in te stellen voor tabellen die grote gegevensvolumes vertegenwoordigen of die bijna realtime resultaten moeten leveren. Gegevens worden nooit geïmporteerd in deze tabellen. Deze tabellen zijn meestal feitentabellen, dat zijn tabellen die worden samengevat.
- Importeren: u wordt aangeraden deze modus in te stellen voor tabellen die niet worden gebruikt voor het filteren en groeperen van feitentabellen in de DirectQuery- of hybride modus. Het is ook de enige optie voor tabellen die zijn gebaseerd op bronnen die niet worden ondersteund door de DirectQuery-modus. Berekende tabellen zijn altijd tabellen importeren.
- Dual: u wordt aangeraden deze modus in te stellen voor dimensietabellen, wanneer er een mogelijkheid is dat ze samen met DirectQuery-feitentabellen uit dezelfde bron worden opgevraagd.
- Hybride: u wordt aangeraden deze modus in te stellen door importpartities en één DirectQuery-partitie toe te voegen aan een feitentabel wanneer u de meest recente gegevenswijzigingen in realtime wilt opnemen, of wanneer u snelle toegang wilt bieden tot de meest gebruikte gegevens via importpartities, terwijl u het merendeel van meer onregelmatig gebruikte gegevens in het datawarehouse overlaat.
Er zijn verschillende scenario's waarin Power BI een samengesteld model opvraagt.
- Alleen query's die worden geïmporteerd of dubbele tabel(len): Power BI haalt alle gegevens op uit de modelcache. Het levert de snelst mogelijke prestaties. Dit scenario is gebruikelijk voor dimensietabellen die worden opgevraagd door filters of slicer-visualisaties.
- Uitvoeren van query's op duale tabellen of DirectQuery-tabellen uit dezelfde bron: Power BI haalt alle gegevens op door een of meer systeemeigen query's naar de DirectQuery-bron te verzenden. Het levert goede prestaties, met name wanneer de juiste indexen aanwezig zijn in de brontabellen. Dit scenario is gebruikelijk voor query's die tabellen met dubbele dimensies en DirectQuery-feitentabellen relateren. Deze query's zijn binnen de brongroep en daarom worden alle een-op-een- of een-op-veel-relaties geëvalueerd als reguliere relaties.
- Query's uitvoeren op twee tabellen of hybride tabellen uit dezelfde bron: dit scenario is een combinatie van de vorige twee scenario's. Power BI haalt gegevens op uit de modelcache wanneer deze beschikbaar is in importpartities, anders worden er een of meer systeemeigen query's naar de DirectQuery-bron verzonden. Dit levert de snelst mogelijke prestaties omdat alleen een segment van de gegevens wordt opgevraagd in het datawarehouse, met name wanneer de juiste indexen aanwezig zijn in de brontabellen. Wat betreft de tabellen met dubbele dimensies en DirectQuery-feitentabellen, zijn deze query's binnen dezelfde brongroep, en dus worden alle een-op-een- of een-op-veel-relaties geëvalueerd als reguliere relaties.
- Alle andere query's: deze query's hebben betrekking op relaties tussen meerdere brongroepen. Dit komt doordat een importtabel betrekking heeft op een DirectQuery-tabel of een dubbele tabel betrekking heeft op een DirectQuery-tabel uit een andere bron. In dat geval gedraagt deze zich als een importtabel. Alle relaties worden geëvalueerd als beperkte relaties. Het betekent ook dat groeperingen die zijn toegepast op niet-DirectQuery-tabellen, moeten worden verzonden naar de DirectQuery-bron als gerealiseerde subquery's (virtuele tabellen). In dit geval kan de systeemeigen query inefficiënt zijn, met name voor grote groeperingssets.
Kortom, we raden u aan het volgende te doen:
- Houd er zorgvuldig rekening mee dat een samengesteld model de juiste oplossing is, terwijl het integratie op modelniveau van verschillende gegevensbronnen toestaat, worden ook ontwerpcomplexiteiten met mogelijke gevolgen geïntroduceerd (verderop in dit artikel beschreven).
- Stel de opslagmodus in op DirectQuery- wanneer een tabel een feitentabel is die grote gegevensvolumes opslaat of wanneer deze bijna realtime resultaten moet leveren.
- Overweeg om hybride modus te gebruiken door een beleid voor incrementeel vernieuwen en realtime gegevens te definiëren, of door de feitentabel te partitioneren met behulp van TOM, TMSL of een hulpprogramma van derden. Zie Incrementeel vernieuwen en realtime gegevens voor semantische modellen en het gebruiksscenario voor geavanceerd gegevensmodelbeheer voor meer informatie.
- Stel de opslagmodus in op Dual- wanneer een tabel een dimensietabel is en deze wordt samen met DirectQuery of hybride feitentabellen in dezelfde brongroep opgevraagd.
- Stel de juiste vernieuwingsfrequenties in om de modelcache voor dubbele en hybride tabellen (en eventuele afhankelijke berekende tabellen) gesynchroniseerd te houden met de brondatabase(s).
- Zorg ervoor dat gegevensintegriteit tussen brongroepen (inclusief de modelcache) wordt gegarandeerd, omdat met beperkte relaties rijen in queryresultaten worden geëlimineerd wanneer gerelateerde kolomwaarden niet overeenkomen.
- Optimaliseer waar mogelijk DirectQuery-gegevensbronnen met de juiste indexen voor efficiënte joins, filteren en groeperen.
Door de gebruiker gedefinieerde aggregaties
U kunt door de gebruiker gedefinieerde aggregaties toevoegen aan DirectQuery-tabellen. Hun doel is om de prestaties voor hogere query's te verbeteren.
Wanneer aggregaties in de cache van het model worden opgeslagen, gedragen ze zich als importtabellen (hoewel ze niet kunnen worden gebruikt als een modeltabel). Het toevoegen van importaggregaties aan een DirectQuery-model resulteert in een samengesteld model.
Notitie
Hybride tabellen bieden geen ondersteuning voor aggregaties omdat sommige partities worden uitgevoerd in de importmodus. Het is niet mogelijk om aggregaties toe te voegen op het niveau van een afzonderlijke DirectQuery-partitie.
U wordt aangeraden een aggregatie te volgen volgens een basisregel: het aantal rijen moet ten minste een factor 10 kleiner zijn dan de onderliggende tabel. Als de onderliggende tabel bijvoorbeeld 1 miljard rijen opslaat, mag de aggregatietabel niet groter zijn dan 100 miljoen rijen. Deze regel zorgt ervoor dat er voldoende prestatiewinst is ten opzichte van de kosten voor het maken en onderhouden van de aggregatie.
Relaties tussen brongroepen
Wanneer een modelrelatie brongroepen omvat, wordt dit een relatie tussen meerdere brongroepen genoemd. Relaties tussen meerdere brongroepen zijn ook beperkte relaties omdat er geen gegarandeerde 'één'-zijde is. Zie Relatie-evaluatie voor meer informatie.
Notitie
In sommige situaties kunt u voorkomen dat er een relatie tussen meerdere bronnen wordt gemaakt. Zie het onderwerp Slicers voor synchronisatie gebruiken verderop in dit artikel.
Houd bij het definiëren van relaties tussen meerdere brongroepen rekening met de volgende aanbevelingen.
- Kolommen met een lage kardinaliteitsrelatie gebruiken: Voor de beste prestaties raden we u aan dat de relatiekolommen een lage kardinaliteit hebben, wat betekent dat ze minder dan 50.000 unieke waarden moeten opslaan. Deze aanbeveling geldt met name bij het combineren van tabellaire modellen en voor niet-tekstkolommen.
- Vermijd het gebruik van kolommen met grote tekstrelaties: als u tekstkolommen in een relatie moet gebruiken, berekent u de verwachte tekstlengte voor het filter door de kardinaliteit te vermenigvuldigen met de gemiddelde lengte van de tekstkolom. De mogelijke tekstlengte mag niet langer zijn dan 1.000.000 tekens.
- de granulariteit van de relatie verhogen: indien mogelijk maakt u relaties op een hoger granulariteitsniveau. Gebruik bijvoorbeeld de maandsleutel in plaats van een datumtabel te relateeren aan de datumsleutel. Voor deze ontwerpbenadering is vereist dat de gerelateerde tabel een kolom met maandsleutels bevat en rapporten geen dagelijkse feiten kunnen weergeven.
- Streven naar een eenvoudig relatieontwerp: maak alleen een relatie tussen meerdere bronnen wanneer deze nodig is en probeer het aantal tabellen in het relatiepad te beperken. Deze ontwerpbenadering helpt de prestaties te verbeteren en dubbelzinnige relatiepaden te voorkomen.
Waarschuwing
Omdat Power BI Desktop relaties tussen meerdere brongroepen niet grondig valideert, is het mogelijk om dubbelzinnige relaties te maken.
Relatiescenario voor verschillende brongroepen 1
Overweeg een scenario van een complex relatieontwerp en hoe het verschillende, maar geldige resultaten kan produceren.
In dit scenario heeft de Region tabel in de brongroep A een relatie met de Date tabel en Sales tabel in de brongroep B. De relatie tussen de Region tabel en de Date tabel is actief, terwijl de relatie tussen de Region tabel en de Sales tabel inactief is. Er is ook een actieve relatie tussen de Region tabel en de Sales tabel, die beide zich in de brongroep bevinden B. De tabel Sales bevat een meting met de naam TotalSalesen de tabel Region bevat twee metingen met de naam RegionalSales en RegionalSalesDirect.
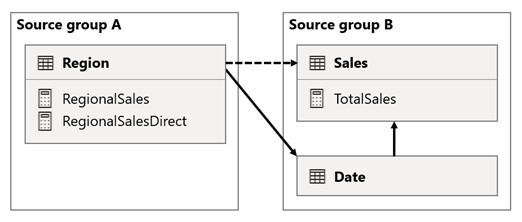
Hier volgen de metingdefinities.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
U ziet hoe de RegionalSales meting verwijst naar de TotalSales meting, terwijl de RegionalSalesDirect dat niet doet. In plaats daarvan gebruikt de maat RegionalSalesDirect de expressie SUM(Sales[Sales]), wat de expressie van de maat TotalSales is.
Het verschil in het resultaat is subtiel. Wanneer Power BI de meting RegionalSales evalueert, wordt het filter van de Region tabel toegepast op zowel de Sales-tabel als de Date tabel. Daarom wordt het filter ook vanuit de Date tabel doorgegeven aan de Sales tabel. Daarentegen, wanneer Power BI de meting RegionalSalesDirect evalueert, wordt het filter alleen vanuit de Region-tabel doorgegeven aan de Sales-tabel. De resultaten die worden geretourneerd door RegionalSales meting en de RegionalSalesDirect meting kunnen verschillen, ook al zijn de expressies semantisch gelijkwaardig.
Belangrijk
Wanneer u de CALCULATE functie gebruikt met een expressie die een meting in een externe brongroep is, test u de berekeningsresultaten grondig.
Relatiescenario voor verschillende brongroepen 2
Overweeg een scenario wanneer een relatie tussen meerdere bronnen kolommen met een relatie met een hoge kardinaliteit heeft.
In dit scenario is de Date tabel gerelateerd aan de Sales tabel in de DateKey kolommen. Het gegevenstype van de DateKey kolommen is geheel getal, waarbij gehele getallen worden opgeslagen die gebruikmaken van de jjjjmmdd notatie. De tabellen behoren tot verschillende brongroepen. Verder is het een relatie met hoge kardinaliteit, omdat de vroegste datum in de tabel Date 1 januari 1900 is en de laatste datum 31 december 2100 is, dus er is een totaal van 73.414 rijen in de tabel (één rij voor elke datum in de periode 1900-2100).
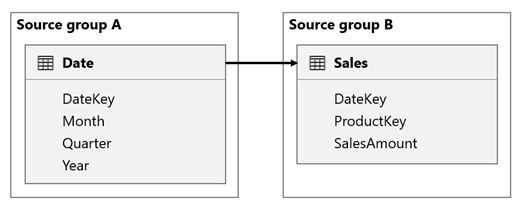
Er zijn twee zaken waar het om gaat.
Eerst, wanneer u de Date tabelkolommen als filters gebruikt, zal de doorstroomfilter de DateKey kolom van de Sales tabel filteren om metingen te evalueren. Bij het filteren op één jaar, zoals 2022, bevat de DAX-query een filterexpressie zoals Sales[DateKey] IN { 20220101, 20220102, …20221231 }. De tekengrootte van de query kan zeer groot worden wanneer het aantal waarden in de filterexpressie groot is of wanneer de filterwaarden lange tekenreeksen zijn. Het is duur voor Power BI om de lange query te genereren en de gegevensbron om de query uit te voeren.
Ten tweede, wanneer u Date tabelkolommen, zoals Year, Quarterof Month, gebruikt als groeperingskolommen, resulteert dit in filters die alle unieke combinaties van jaar-, kwartaal- of maand-, en de DateKey kolomwaarden bevatten. De tekenreeksgrootte van de query, die filters bevat voor de groeperingskolommen en de relatiekolom, kan extreem groot worden. Dat geldt vooral wanneer het aantal groeperingskolommen en/of de kardinaliteit van de joinkolom (de DateKey kolom) groot is.
U kunt het volgende doen om prestatieproblemen op te lossen:
- Voeg de
Datetabel toe aan de gegevensbron, wat resulteert in één brongroepmodel (wat betekent dat het geen samengesteld model meer is). - Verhoog de granulariteit van de relatie. U kunt bijvoorbeeld een
MonthKeykolom toevoegen aan beide tabellen en de relatie voor deze kolommen maken. Als u echter de granulariteit van de relatie verhoogt, verliest u de mogelijkheid om te rapporteren over dagelijkse verkoopactiviteiten (tenzij u de kolomDateKeyuit deSalestabel gebruikt).
Relatiescenario voor verschillende brongroepen 3
Overweeg een scenario wanneer er geen overeenkomende waarden zijn tussen tabellen in een relatie tussen verschillende brongroepen.
In dit scenario heeft de Date tabel in de brongroep B een relatie met de Sales tabel in die brongroep en ook met de Target tabel in de brongroep A. Alle relaties zijn een-op-veel uit de Date tabel met betrekking tot de Year kolommen. De tabel Sales bevat een SalesAmount kolom waarin verkoopbedragen worden opgeslagen, terwijl de Target tabel een TargetAmount kolom bevat waarin doelbedragen worden opgeslagen.
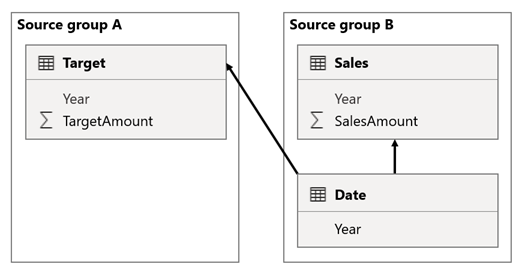
De Date tabel slaat de jaren 2021 en 2022 op. In de Sales tabel worden verkoopbedragen opgeslagen voor jaren 2021 (100) en 2022 (200), terwijl de Target tabel doelbedragen opslaat voor 2021 (100), 2022 (200), en 2023 (300)— een toekomstig jaar.
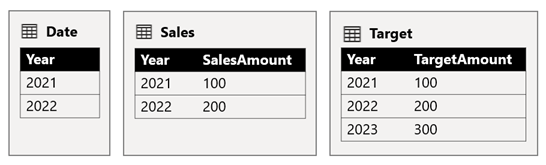
Wanneer een Power BI-tabelvisual het samengestelde model opvraagt door te groeperen op de Year-kolom van de Date-tabel en de kolommen SalesAmount en TargetAmount optelt, zal er voor 2023 geen doelbedrag worden weergegeven. Dat komt doordat de relatie tussen meerdere brongroepen een beperkte relatie is en dus semantiek gebruikt INNER JOIN , waardoor rijen worden geëlimineerd waar aan beide zijden geen overeenkomende waarde is. Er wordt echter een juist doelbedrag totaal (600) gegenereerd, omdat een Date tabelfilter niet van toepassing is op de evaluatie.
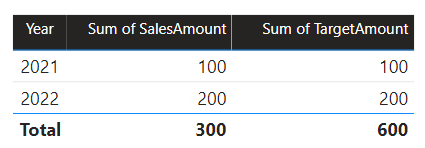
Als de relatie tussen de Date tabel en de Target tabel een relatie binnen de brongroep is (ervan uitgaande dat de Target tabel behoort tot de brongroep B), bevat de visual een (Leeg) jaar om het doelbedrag voor 2023 (en andere niet-overeenkomende jaren) weer te geven.
Belangrijk
Om onjuiste rapportage te voorkomen, moet u ervoor zorgen dat er overeenkomende waarden in de relatiekolommen zijn wanneer dimensie- en feitentabellen zich in verschillende brongroepen bevinden.
Zie De evaluatie van relaties voor meer informatie over beperkte relaties.
Berekeningen
Houd rekening met specifieke beperkingen bij het toevoegen van berekende kolommen en berekeningsgroepen aan een samengesteld model.
Berekende kolommen
Berekende kolommen die zijn toegevoegd aan een DirectQuery-tabel die hun gegevens uit een relationele database, zoals Microsoft SQL Server, ophalen, zijn beperkt tot expressies die op één rij tegelijk werken. Deze expressies kunnen geen DAX-iteratorfuncties gebruikenCALCULATE
Notitie
Het is niet mogelijk om berekende kolommen of berekende tabellen toe te voegen die afhankelijk zijn van gekoppelde tabellaire modellen.
Een berekende kolomexpressie in een externe DirectQuery-tabel is beperkt tot alleen evaluatie binnen rij. U kunt echter een dergelijke expressie maken, maar dit resulteert in een fout wanneer deze wordt gebruikt in een visual. Als u bijvoorbeeld een berekende kolom toevoegt aan een externe DirectQuery-tabel met de naam DimProduct met behulp van de expressie [Product Sales] / SUM (DimProduct[ProductSales]), kunt u de expressie in het model opslaan. Dit resulteert echter in een fout wanneer deze wordt gebruikt in een visual, omdat deze de evaluatiebeperking binnen rij schendt.
Berekende kolommen daarentegen die zijn toegevoegd aan een externe DirectQuery-tabel die een tabellair model is, dat een semantisch Power BI-model of Analysis Services-model is, zijn flexibeler. In dit geval zijn alle DAX-functies toegestaan omdat de expressie wordt geëvalueerd in het tabellaire bronmodel.
Voor veel expressies moet Power BI de berekende kolom materialiseren voordat deze als groep of filter wordt gebruikt of samengevoegd. Wanneer een berekende kolom wordt gerealiseerd via een grote tabel, kan het kostbaar zijn in termen van CPU en geheugen, afhankelijk van de kardinaliteit van de kolommen waarvan de berekende kolom afhankelijk is. In dit geval raden we u aan deze berekende kolommen toe te voegen aan het bronmodel.
Notitie
Wanneer u berekende kolommen toevoegt aan een samengesteld model, moet u alle modelberekeningen testen. Upstream-berekeningen werken mogelijk niet correct omdat ze hun invloed op de filtercontext niet hebben overwogen.
Berekeningsgroepen
Als er berekeningsgroepen bestaan in een brongroep die verbinding maakt met een semantisch Power BI-model of een Analysis Services-model, kan Power BI onverwachte resultaten opleveren. Zie Berekeningsgroepen, query' en metingsevaluatie voor meer informatie.
Modelontwerp
U moet altijd een Power BI-model optimaliseren door een stervormig schemaontwerp te gebruiken.
Tip
Zie Meer informatie over stervormige schema's en het belang van Power BI.
Zorg ervoor dat u dimensietabellen maakt die gescheiden zijn van feitentabellen, zodat Power BI joins correct kan interpreteren en efficiënte queryplannen kan produceren. Hoewel deze richtlijnen waar zijn voor elk Power BI-model, is dit met name waar voor modellen die u herkent, een brongroep van een samengesteld model wordt. Het biedt een eenvoudigere en efficiëntere integratie van andere tabellen in downstreammodellen.
Vermijd waar mogelijk dimensietabellen in één brongroep die betrekking hebben op een feitentabel in een andere brongroep. Dat komt doordat het beter is om intra-brongroeprelaties te hebben dan relaties tussen meerdere brongroepen, met name voor kolommen met een relatie met hoge kardinaliteit. Zoals eerder beschreven, zijn relaties tussen meerdere brongroepen afhankelijk van overeenkomende waarden in de relatiekolommen, anders kunnen onverwachte resultaten worden weergegeven in rapportvisuals.
Beveiliging op rijniveau
Als uw model door de gebruiker gedefinieerde aggregaties, berekende kolommen voor importtabellen of berekende tabellen bevat, moet u ervoor zorgen dat beveiliging op rijniveau (RLS) correct is ingesteld en getest.
Als het samengestelde model verbinding maakt met andere tabellaire modellen, worden RLS-regels alleen toegepast op de brongroep (lokaal model) waar ze zijn gedefinieerd. Ze worden niet toegepast op andere brongroepen (externe modellen). U kunt ook geen RLS-regels definiëren voor een tabel uit een andere brongroep en u kunt ook geen RLS-regels definiëren voor een lokale tabel die een relatie heeft met een andere brongroep.
Rapportontwerp
In sommige situaties kunt u de prestaties van een samengesteld model verbeteren door een geoptimaliseerde rapportindeling te ontwerpen.
Visuals van één brongroep
Maak waar mogelijk visuals die gebruikmaken van velden uit één brongroep. Dat komt doordat query's die door visuals worden gegenereerd, beter presteren wanneer het resultaat wordt opgehaald uit één brongroep. Overweeg om twee visuals naast elkaar te maken die gegevens ophalen uit twee verschillende brongroepen.
Slicers synchroniseren gebruiken
In sommige situaties kunt u synchronisatieslicers instellen om te voorkomen dat er een relatie tussen meerdere bronnen in uw model wordt gemaakt. Hiermee kunt u brongroepen visueel combineren die beter kunnen presteren.
Overweeg een scenario wanneer uw model twee brongroepen heeft. Elke brongroep heeft een tabel met productdimensie die wordt gebruikt om reseller- en internetverkopen te filteren.
In dit scenario bevat de brongroep A de Product tabel die is gerelateerd aan de ResellerSales tabel. De brongroep B bevat de Product2 tabel die is gerelateerd aan de InternetSales tabel. Er zijn geen relaties tussen brongroepen.
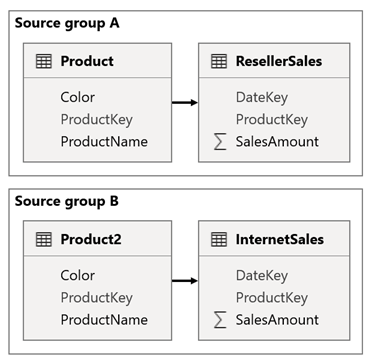
In het rapport voegt u een slicer toe waarmee de pagina wordt gefilterd met behulp van de kolom Color van de Product tabel. De slicer filtert standaard de ResellerSales tabel, maar niet de InternetSales tabel. Vervolgens voegt u een verborgen slicer toe met behulp van de kolom Color van de Product2 tabel. Door een identieke groepsnaam (in de geavanceerde opties voor synchronisatieslicers) in te stellen, worden filters die zijn toegepast op de zichtbare slicer automatisch doorgegeven aan de verborgen slicer.
Notitie
Hoewel het gebruik van synchronisatieslicers de noodzaak om een relatie tussen meerdere brongroepen te maken, kan de complexiteit van het modelontwerp toenemen. Zorg ervoor dat u andere gebruikers informeert over waarom u het model hebt ontworpen met dubbele dimensietabellen. Vermijd verwarring door dimensietabellen te verbergen die u niet wilt gebruiken door andere gebruikers. U kunt ook beschrijvingstekst toevoegen aan de verborgen tabellen om hun doel te documenteren.
Zie Afzonderlijke slicers synchroniseren voor meer informatie.
Andere richtlijnen
Hier volgen enkele andere richtlijnen voor het ontwerpen en onderhouden van samengestelde modellen.
- Prestatie en schaal: Als uw rapporten eerder live verbonden waren met een semantisch Power BI-model of Analysis Services-model, kan de Power BI-service visual caches hergebruiken in rapporten. Nadat u de liveverbinding hebt geconverteerd om een lokaal DirectQuery-model te maken, profiteren rapporten niet meer van deze caches. Als gevolg hiervan kunnen er tragere prestaties optreden of zelfs vernieuwingsfouten optreden. Bovendien neemt de workload voor de Power BI-service toe, waardoor u mogelijk uw capaciteit omhoog moet schalen of de workload over andere capaciteiten moet verdelen. Zie Gegevens vernieuwen in Power BI voor meer informatie over het vernieuwen en opslaan van gegevens in cache.
- Naam wijzigen: We raden af om semantische modellen die door samengestelde modellen worden gebruikt een andere naam te geven of om hun werkruimten te hernoemen. Dat komt doordat samengestelde modellen verbinding maken met semantische Power BI-modellen met behulp van de werkruimte- en semantische modelnamen (en niet hun interne unieke id's). Als u de naam van een semantisch model of werkruimte wijzigt, kunnen de verbindingen die door uw samengestelde model worden gebruikt, worden verbroken.
- Governance: het is niet raadzaam dat uw enkele versie van de waarheid model een samengesteld model is. Dat komt doordat het afhankelijk is van andere gegevensbronnen of modellen, die, indien bijgewerkt, kunnen leiden tot het verbreken van het samengestelde model. In plaats daarvan raden we u aan om een semantisch ondernemingsmodel te publiceren als de enige versie van waarheid. Beschouw dit model als een betrouwbare basis. Andere gegevensmodelleerders kunnen vervolgens samengestelde modellen maken die het basismodel uitbreiden om gespecialiseerde modellen te maken.
- Gegevensherkomst: Gebruik de functies voor gegevensherkomst en invloedanalyse van het semantische model voordat u wijzigingen in een samengesteld model publiceert. Deze functies zijn beschikbaar in de Power BI-service en kunnen u helpen begrijpen hoe semantische modellen zijn gerelateerd en gebruikt. Het is belangrijk om te begrijpen dat u geen impactanalyse kunt uitvoeren op externe semantische modellen die worden weergegeven in de herkomstweergave, maar zich in feite in een andere werkruimte bevinden. Als u impactanalyses wilt uitvoeren op een extern semantisch model, moet u naar de bronwerkruimte navigeren.
- schema-updates: vernieuw het samengestelde model in Power BI Desktop wanneer schemawijzigingen worden aangebracht in upstream-gegevensbronnen. Vervolgens moet u het model opnieuw publiceren naar de Power BI-service. Zorg ervoor dat u berekeningen en afhankelijke rapporten grondig test.
Gerelateerde inhoud
Raadpleeg de volgende bronnen voor meer informatie over dit artikel.
- Samengestelde modellen gebruiken in Power BI Desktop
- Modelrelaties in Power BI Desktop
- DirectQuery-modellen in Power BI Desktop
- DirectQuery gebruiken in Power BI Desktop
- Opslagmodus in Power BI Desktop
- Door de gebruiker gedefinieerde aggregaties
- Vragen? Vraag het de Fabric Community.
- Suggesties? Ideeën bijdragen om Fabric- te verbeteren