Problemen met de connectiviteit van XMLA-eindpunten oplossen
XMLA-eindpunten in Power BI zijn afhankelijk van het systeemeigen Analysis Services-communicatieprotocol voor toegang tot semantische Power BI-modellen. Daarom is het oplossen van problemen met XMLA-eindpunten veel hetzelfde als het oplossen van problemen met een typische Analysis Services-verbinding. Er zijn echter enkele verschillen met betrekking tot power BI-specifieke afhankelijkheden van toepassing.
Voordat u begint
Voordat u problemen met een XMLA-eindpuntscenario gaat oplossen, moet u de basisbeginselen bekijken die worden behandeld in Semantische modelconnectiviteit met het XMLA-eindpunt. De meest voorkomende use cases voor XMLA-eindpunten worden daar behandeld. Andere handleidingen voor het oplossen van problemen met Power BI, zoals problemen met gateways oplossen- Power BI en Het analyseren van problemen in Excel kunnen ook nuttig zijn.
Het XMLA-eindpunt inschakelen
Het XMLA-eindpunt kan worden ingeschakeld voor zowel Power BI Premium-, Premium-per-gebruiker- als Power BI Embedded-capaciteiten. Bij kleinere capaciteiten, zoals een A1-capaciteit met slechts 2,5 GB geheugen, kan er een fout optreden in capaciteitsinstellingen bij het instellen van het XMLA-eindpunt op Lezen/schrijven en vervolgens Toepassen selecteren. De fout geeft aan dat er een probleem is met uw workloadinstellingen. Probeer het over een tijdje opnieuw.".
Hier volgen enkele dingen die u kunt proberen:
- Beperk het geheugenverbruik van andere services op de capaciteit, zoals gegevensstromen, tot 40% of minder, of schakel een onnodige service volledig uit.
- Upgrade de capaciteit naar een grotere SKU. Als u bijvoorbeeld een upgrade uitvoert van een A1 naar een A3-capaciteit, wordt dit configuratieprobleem opgelost zonder dat u gegevensstromen hoeft uit te schakelen.
Houd er rekening mee dat u ook de Exportgegevens op tenantniveau instelling moet inschakelen in de Power BI-beheerportal. Deze instelling is ook vereist voor de functie Analyseren in Excel.
Een clientverbinding tot stand brengen
Nadat het XMLA-eindpunt is ingeschakeld, is het een goed idee om de connectiviteit met een werkruimte op de capaciteit te testen. Zie Verbinding maken met een Premium-werkruimte voor meer informatie. Lees ook de sectie Verbindingsvereisten voor nuttige tips en informatie over de huidige BEPERKINGEN voor XMLA-connectiviteit.
Verbinding maken met een service-principal
Als u tenantinstellingen hebt ingeschakeld om service-principals toe te staan API van Power BI s te gebruiken, zoals beschreven in Service-principals inschakelen, kunt u verbinding maken met een XMLA-eindpunt met behulp van een service-principal. Houd er rekening mee dat voor de service-principal hetzelfde toegangsniveau is vereist op werkruimte- of semantisch modelniveau als gewone gebruikers.
Als u een service-principal wilt gebruiken, moet u de toepassingsidentiteit opgeven in de connectiestring als:
Gebruikers-id - app:appid@tenantid
Wachtwoord
certificaat:vingerafdruk (aanbevolen voor beveiliging)
Data Source=powerbi://api.powerbi.com/v1.0/myorg/Contoso;Initial Catalog=PowerBI_Dataset;User ID=app:<appid>;Password=cert:<thumbprint>;applicatiegeheim
Data Source=powerbi://api.powerbi.com/v1.0/myorg/Contoso;Initial Catalog=PowerBI_Dataset;User ID=app:<appid>;Password=<secret>;
Als u de volgende fout krijgt:
"We kunnen geen verbinding maken met het semantische model vanwege onvolledige accountgegevens. Voor service-principals moet u ervoor zorgen dat u de tenant-id samen met de app-id opgeeft in het formaat app:<appId>@<tenantId>, en probeer het dan opnieuw.
Zorg ervoor dat u de tenant-ID samen met de app-ID in het juiste formaat opgeeft.
Het is ook geldig om de app-id op te geven zonder de tenant-id. In dit geval moet u echter de myorg alias in de gegevensbron-URL vervangen door de werkelijke tenant-id. Power BI kan vervolgens de service-principal vinden in de juiste tenant. Maar als best practice gebruikt u de myorg alias en geeft u de tenant-id op samen met de app-id in de parameter Gebruikers-id.
Verbinding maken met Microsoft Entra B2B
Met ondersteuning voor Microsoft Entra business-to-business (B2B) in Power BI kunt u externe gastgebruikers toegang bieden tot semantische modellen via het XMLA-eindpunt. Zorg ervoor dat de instelling Inhoud delen met externe gebruikers is ingeschakeld in de Power BI-beheerportal. Zie Power BI-inhoud distribueren naar externe gastgebruikers met Microsoft Entra B2B voor meer informatie.
Een semantisch model implementeren
U kunt een tabellair modelproject in Visual Studio (SSDT) implementeren naar een werkruimte die is toegewezen aan een Premium-capaciteit, veel hetzelfde als voor een serverresource in Azure Analysis Services. Bij het implementeren zijn er echter enkele aanvullende overwegingen. Zorg ervoor dat je de sectie Modelprojecten implementeren vanuit Visual Studio (SSDT) doorneemt in het artikel over semantische modelconnectiviteit met het XMLA-eindpunt.
Een nieuw model implementeren
In de standaardconfiguratie probeert Visual Studio het model te verwerken als onderdeel van de implementatiebewerking om gegevens te laden in het semantische model uit de gegevensbronnen. Zoals beschreven in Modelprojecten implementeren vanuit Visual Studio (SSDT), kan deze bewerking mislukken omdat de referenties van de gegevensbron niet kunnen worden opgegeven als onderdeel van de implementatiebewerking. Als referenties voor uw gegevensbron niet al zijn gedefinieerd voor een van uw bestaande semantische modellen, moet u de referenties voor de gegevensbron opgeven in de semantische modelinstellingen met behulp van de Power BI-gebruikersinterface (Semantische modellen>Instellingen>Referenties bewerken). Nadat u de referenties voor de gegevensbron hebt gedefinieerd, kan Power BI de referenties automatisch toepassen op deze gegevensbron voor elk nieuw semantisch model, nadat de implementatie van metagegevens is geslaagd en het semantische model is gemaakt.
Als power BI uw nieuwe semantische model niet kan binden aan de referenties van de gegevensbron, krijgt u de foutmelding 'Kan database niet verwerken. Reden: Kan wijzigingen niet opslaan op de server.' met de foutcode 'DMTS_DatasourceHasNoCredentialError', zoals hieronder wordt weergegeven:
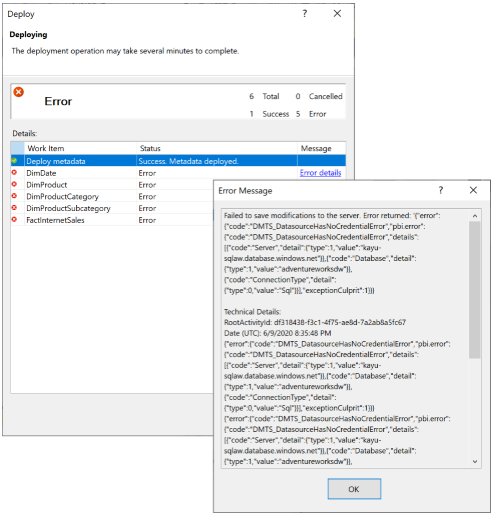
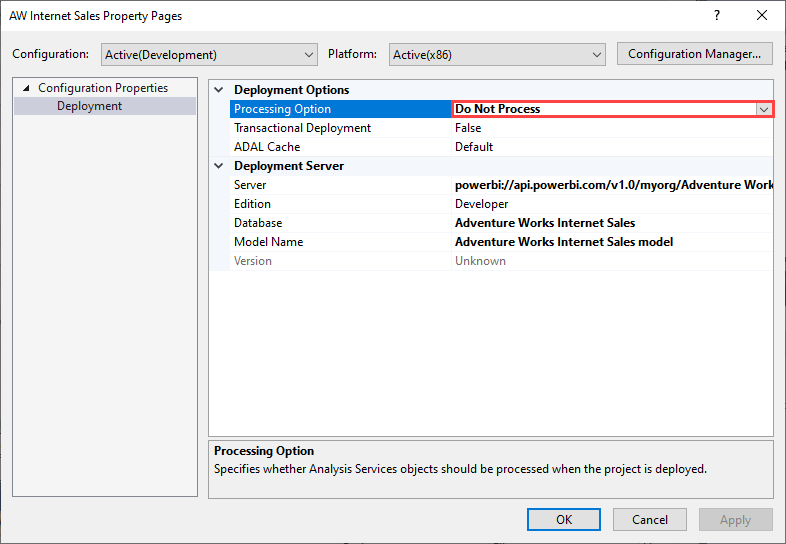
Als u de verwerkingsfout wilt voorkomen, stelt u de verwerkingsopties voor implementatieopties> in op Niet verwerken, zoals wordt weergegeven in de volgende afbeelding. Visual Studio implementeert vervolgens alleen metagegevens. Vervolgens kunt u de referenties voor de gegevensbron configureren en nu op Vernieuwen klikken voor het semantische model in de Power BI-gebruikersinterface.
Nieuw project van een bestaand semantisch model
Het maken van een nieuw tabellair project in Visual Studio door de metagegevens uit een bestaand semantisch model te importeren, wordt niet ondersteund. U kunt echter verbinding maken met het semantische model met behulp van SQL Server Management Studio, de metagegevens scripten en opnieuw gebruiken in andere tabellaire projecten.
Een semantisch model migreren naar Power BI
Het is raadzaam om het compatibiliteitsniveau 1500 (of hoger) voor tabellaire modellen op te geven. Dit compatibiliteitsniveau ondersteunt de meeste mogelijkheden en gegevensbrontypen. Latere compatibiliteitsniveaus zijn achterwaarts compatibel met eerdere niveaus.
Ondersteunde gegevensproviders
Op het compatibiliteitsniveau 1500 ondersteunt Power BI de volgende gegevensbrontypen:
- Gegevensbronnen van de provider (verouderd met een verbindingsreeks in de metadata van het model).
- Gestructureerde gegevensbronnen (geïntroduceerd met het compatibiliteitsniveau 1400).
- Inline M-declaraties van gegevensbronnen (zoals Power BI Desktop deze declareert).
Het is raadzaam om gestructureerde gegevensbronnen te gebruiken, die Visual Studio standaard maakt bij het doorlopen van de gegevensstroom Importeren. Als u echter van plan bent om een bestaand model te migreren naar Power BI dat gebruikmaakt van een providergegevensbron, moet u ervoor zorgen dat de gegevensbron van de provider afhankelijk is van een ondersteunde gegevensprovider. Het Microsoft OLE DB-stuurprogramma voor SQL Server en eventuele ODBC-stuurprogramma's van derden. Voor OLE DB-stuurprogramma voor SQL Server moet u de definitie van de gegevensbron overschakelen naar de .NET Framework-gegevensprovider voor SQL Server. Voor ODBC-stuurprogramma's van derden die mogelijk niet beschikbaar zijn in de Power BI-service, moet u in plaats daarvan overschakelen naar een definitie van een gestructureerde gegevensbron.
Het wordt ook aanbevolen om het verouderde Microsoft OLE DB-stuurprogramma voor SQL Server (SQLNCLI11) in uw SQL Server-gegevensbrondefinities te vervangen door de .NET Framework-gegevensprovider voor SQL Server.
De volgende tabel bevat een voorbeeld van een .NET Framework-gegevensprovider voor een SQL Server-verbindingsreeks die ter vervanging is van een overeenkomende verbindingsreeks voor OLE DB-stuurprogramma voor SQL Server.
| OLE DB-stuurprogramma voor SQL Server | .NET Framework-gegevensprovider voor SQL Server |
|---|---|
Provider=SQLNCLI11;Data Source=sqldb.database.windows.net;Initial Catalog=AdventureWorksDW;Trusted_Connection=yes; |
Data Source=sqldb.database.windows.net;Initial Catalog=AdventureWorksDW2016;Integrated Security=SSPI;Encrypt=true;TrustServerCertificate=false |
Kruisverwijzen van partitiebronnen
Net zoals er meerdere gegevensbrontypen zijn, zijn er ook meerdere partitiebrontypen die een tabellair model kan bevatten om gegevens in een tabel te importeren. Specifiek kan een partitie een querypartitiebron of een M-partitiebron gebruiken. Deze partitiebrontypen kunnen op hun beurt verwijzen naar providergegevensbronnen of gestructureerde gegevensbronnen. Hoewel tabellaire modellen in Azure Analysis Services ondersteuning bieden voor kruisverwijzingen naar deze verschillende gegevensbron- en partitietypen, dwingt Power BI een striktere relatie af. Querypartitiebronnen moeten verwijzen naar providergegevensbronnen en M-partitiebronnen moeten verwijzen naar gestructureerde gegevensbronnen. Andere combinaties worden niet ondersteund in Power BI. Als u een semantisch model met kruisverwijzingen wilt migreren, worden in de volgende tabel ondersteunde configuraties beschreven:
| Gegevensbron | Partitiebron | Opmerkingen | Ondersteund met XMLA-eindpunt |
|---|---|---|---|
| gegevensbron van de aanbieder | Querypartitiebron | De AS-engine maakt gebruik van de op cartridge gebaseerde connectiviteitsstack voor toegang tot de gegevensbron. | Ja |
| Gegevensbron van de provider | M-partitiebron | De AS-engine vertaalt de providergegevensbron in een algemene gestructureerde gegevensbron en gebruikt vervolgens de Mashup-engine om de gegevens te importeren. | Nee |
| Gestructureerde gegevensbron | Querypartitiebron | De AS-engine verpakt de systeemeigen query op de partitiebron in een M-expressie en gebruikt vervolgens de Mashup-engine om de gegevens te importeren. | Nee |
| Gestructureerde gegevensbron | M-partitiebron | De AS-engine gebruikt de Mashup-engine om de gegevens te importeren. | Ja |
Gegevensbronnen en imitatie
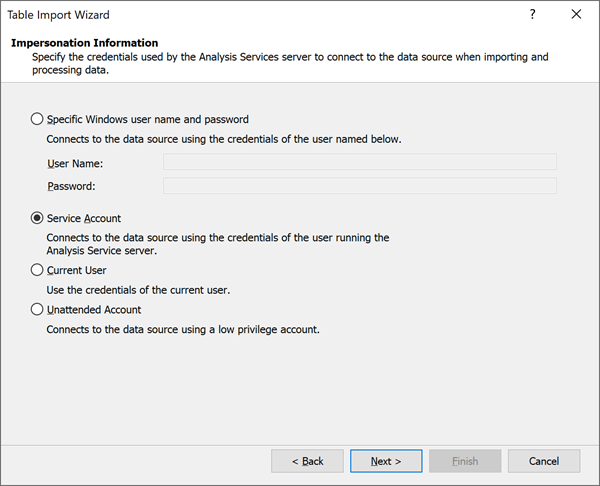
Imitatie-instellingen die u kunt definiëren voor providergegevensbronnen zijn niet relevant voor Power BI. Power BI maakt gebruik van een ander mechanisme op basis van semantische modelinstellingen voor het beheren van referenties voor gegevensbronnen. Zorg er daarom voor dat u serviceaccount selecteert als u een providergegevensbron maakt.
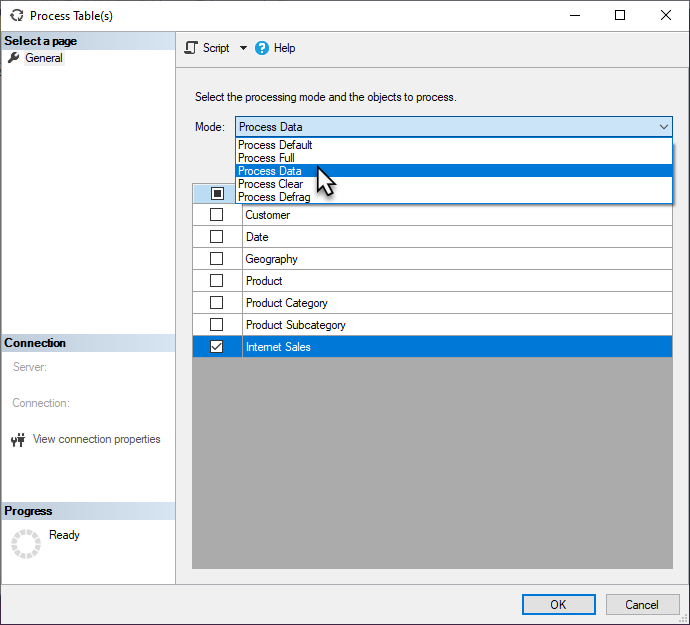
Fijnmazige verwerking
Wanneer een geplande vernieuwing of on-demand vernieuwing in Power BI wordt geactiveerd, wordt het hele semantische model doorgaans vernieuwd in Power BI. In veel gevallen is het efficiënter om selectiever vernieuwingen uit te voeren. U kunt gedetailleerde verwerkingstaken uitvoeren in SQL Server Management Studio (SSMS), zoals hieronder wordt weergegeven, of met behulp van hulpprogramma's of scripts van derden.
Overschrijvingen in de TMSL-opdracht vernieuwen
Met onderdrukkingen in de opdracht Vernieuwen (TMSL) kunnen gebruikers een andere definitie van een partitiequery of gegevensbron kiezen voor de vernieuwingsbewerking.
E-mailabonnementen
Semantische modellen die worden vernieuwd met een XMLA-eindpunt activeren geen e-mailabonnement.
Fouten met Premium-capaciteit
Verbinding maken met serverfout in SSMS
Wanneer u verbinding maakt met een Power BI-werkruimte met SQL Server Management Studio (SSMS), wordt mogelijk de volgende fout weergegeven:
TITLE: Connect to Server
------------------------------
Cannot connect to powerbi://api.powerbi.com/v1.0/[tenant name]/[workspace name].
------------------------------
ADDITIONAL INFORMATION:
The remote server returned an error: (400) Bad Request.
Technical Details:
RootActivityId:
Date (UTC): 10/6/2021 1:03:25 AM (Microsoft.AnalysisServices.AdomdClient)
------------------------------
The remote server returned an error: (400) Bad Request. (System)
Wanneer u verbinding maakt met een Power BI-werkruimte met SSMS, moet u het volgende controleren:
- De instelling voor het XMLA-eindpunt is ingeschakeld voor de capaciteit van uw tenant. Zie XMLA lezen en schrijven inschakelen voor meer informatie.
- De instelling XMLA-eindpunten toestaan en analyseren in Excel met on-premises semantische modellen is ingeschakeld in tenantinstellingen.
- U gebruikt de nieuwste versie van SSMS. Download de nieuwste versie.
Query uitvoeren in SSMS
Wanneer u verbinding hebt met een werkruimte in een Power BI Premium of Power BI Embedded-capaciteit, kan SQL Server Management Studio de volgende fout weergeven:
Executing the query ...
Error -1052311437: We had to move the session with ID '<Session ID>' to another Power BI Premium node. Moving the session temporarily interrupted this trace - tracing will resume automatically as soon as the session has been fully moved to the new node.
Dit is een informatief bericht dat kan worden genegeerd in SSMS 18.8 en hoger, omdat de clientbibliotheken automatisch opnieuw verbinding maken. Houd er rekening mee dat clientbibliotheken die zijn geïnstalleerd met SSMS v18.7.1 of lager geen ondersteuning bieden voor sessietracering. Download de nieuwste SSMS.
Een grote opdracht uitvoeren met behulp van het XMLA-eindpunt
Bij het uitvoeren van een grote opdracht met behulp van het XMLA-eindpunt kan de volgende fout optreden:
Executing the query ...
Error -1052311437:
The remote server returned an error: (400) Bad Request.
Technical Details:
RootActivityId: 3716c0f7-3d01-4595-8061-e6b2bd9f3428
Date (UTC): 11/13/2020 7:57:16 PM
Run complete
Wanneer u SSMS v18.7.1 of lager gebruikt om een langdurige vernieuwingsbewerking (>1 min) uit te voeren op een semantisch model in een Power BI Premium- of Power BI Embedded-capaciteit , kan SSMS deze fout weergeven, zelfs als de vernieuwingsbewerking slaagt. Dit wordt veroorzaakt door een bekend probleem in de clientbibliotheken waarbij de status van de vernieuwingsaanvraag onjuist wordt bijgehouden. Dit is opgelost in SSMS 18.8 en hoger. Download de nieuwste SSMS.
Deze fout kan ook optreden wanneer een zeer grote aanvraag moet worden omgeleid naar een ander knooppunt in het Premium-cluster. Het wordt vaak gezien wanneer u probeert een semantisch model te maken of te wijzigen met behulp van een groot TMSL-script. In dergelijke gevallen kan de fout meestal worden vermeden door de Initial Catalog op de naam van de database op te geven voordat u de opdracht uitvoert.
Wanneer u een nieuwe database maakt, kunt u een leeg semantisch model maken, bijvoorbeeld:
{
"create": {
"database": {
"name": "DatabaseName"
}
}
}
Nadat u het nieuwe semantische model hebt gemaakt, geeft u de eerste catalogus op en wijzigt u het semantische model.
Andere clienttoepassingen en hulpprogramma's
Clienttoepassingen en hulpprogramma's zoals Excel, Power BI Desktop, SSMS of externe hulpprogramma's die verbinding maken met en werken met semantische modellen in Power BI Premium-capaciteiten, kunnen de volgende fout veroorzaken: de externe server heeft een fout geretourneerd: (400) Ongeldige aanvraag.. De fout kan worden veroorzaakt, met name als een onderliggende DAX-query of XMLA-opdracht lang wordt uitgevoerd. Als u potentiële fouten wilt beperken, moet u de meest recente toepassingen en hulpprogramma's gebruiken die recente versies van de Analysis Services-clientbibliotheken installeren met regelmatige updates. Ongeacht de toepassing of het hulpprogramma zijn de minimaal vereiste clientbibliotheekversies om verbinding te maken met en te werken met semantische modellen in een Premium-capaciteit via het XMLA-eindpunt:
| Clientbibliotheek | Versie |
|---|---|
| MSOLAP | 15.1.65.22 |
| AMO | 19.12.7.0 |
| ADOMD | 19.12.7.0 |
Rol lidmaatschappen bewerken in SSMS
Wanneer u SSMS (SQL Server Management Studio) v18.8 gebruikt om een rollidmaatschap in een semantisch model te bewerken, kan SSMS de volgende fout weergeven:
Failed to save modifications to the server.
Error returned: ‘Metadata change of current operation cannot be resolved, please check the command or try again later.’
Dit komt door een bekend probleem in de REST API van app-services. Dit wordt opgelost in een toekomstige release. Als u deze fout ondertussen wilt omzeilen, klikt u in Roleigenschappen op Script en voert u de volgende TMSL-opdracht in en voert u deze uit:
{
"createOrReplace": {
"object": {
"database": "AdventureWorks",
"role": "Role"
},
"role": {
"name": "Role",
"modelPermission": "read",
"members": [
{
"memberName": "xxxx",
"identityProvider": "AzureAD"
},
{
"memberName": “xxxx”
"identityProvider": "AzureAD"
}
]
}
}
}
Publicatiefout - Live verbonden semantisch model
Wanneer u een live verbonden semantisch model opnieuw publiceert met behulp van de Analysis Services-connector, wordt de volgende fout weergegeven: 'Er is een bestaand rapport/semantisch model met dezelfde naam. Verwijder of wijzig de naam van het bestaande semantische model en probeer het opnieuw.' kan worden weergegeven.
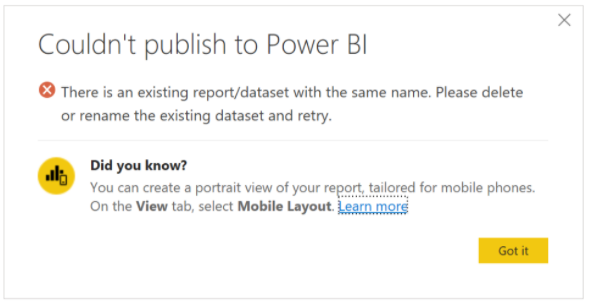
Dit komt doordat het semantische model wordt gepubliceerd met een andere verbindingsreeks, maar dezelfde naam heeft als het bestaande semantische model. U kunt dit probleem oplossen door het bestaande semantische model te verwijderen of de naam ervan te wijzigen. Zorg er ook voor dat u alle apps die afhankelijk zijn van het rapport opnieuw publiceert. Indien nodig moeten downstreamgebruikers worden geïnformeerd over het bijwerken van bladwijzers met het nieuwe rapportadres om ervoor te zorgen dat ze toegang hebben tot het meest recente rapport.
Direct verbonden semantisch model kan niet worden geladen
Gebruikers die een nieuw live verbonden model willen maken of een bestaand live verbonden model willen openen met behulp van de versies van maart 2024 of nieuwere versies van Power BI Desktop, kunnen een fout tegenkomen die vergelijkbaar is met het volgende: 'Er kan geen verbinding worden gemaakt met uw model in de Power BI-service. De gegevensset is mogelijk verwijderd, hernoemd, verplaatst of mogelijk bent u niet gemachtigd om deze te openen.'
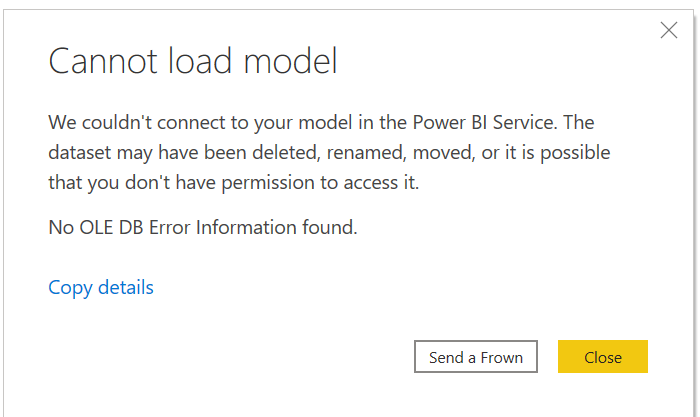
De fout kan optreden wanneer een proxy is geconfigureerd in de omgeving van de gebruiker en de proxy de toegang tot de Power BI-service verhindert. Vanaf de versie van maart 2024 van Power BI Desktop moet de omgeving van de gebruiker verbindingen met het Power BI-service op eindpunt *.pbidedicated.windows.net of de bijbehorende Power BI-service-eindpunten voor onafhankelijke clouds toestaan.
Als u wilt controleren of het probleem het gevolg is van proxy-instellingen, probeert u de SQL Server Analysis Services-connector in Power BI Desktop of een extern hulpprogramma van derden, zoals SQL Server Management Studio, om verbinding te maken met een Premium-werkruimte.
Raadpleeg de sectie voor het tot stand brengen van een clientverbinding in dit artikel voor meer informatie over het testen van algemene XML/A-connectiviteit.
Excel-werkmap kan niet worden geopend
Excel-werkmap kan niet worden geopend met de fout 'Initialisatie van de gegevensbron is mislukt. Controleer de databaseserver of neem contact op met de databasebeheerder.' Als de werkmap een verbinding met een semantisch Power BI-model bevat, controleert u of de verbindingsreeks de eigenschap Catalog Rebound=True bevat. Als de eigenschap is gevonden, verwijdert u deze, slaat u de werkmap op en probeert u deze opnieuw te openen.
De eigenschap Catalog Rebound=True wordt automatisch toegevoegd door de Analysis Services OLE DB Provider (MSOLAP) in nieuwere versies van Excel wanneer de verbinding met het semantische Power BI-model wordt geoptimaliseerd door de provider. Omdat de eigenschap blijft behouden in de werkmap, kan excel de werkmap niet openen wanneer dezelfde werkmap wordt geopend in Excel die een oudere versie van de provider gebruikt die de optimalisatie niet ondersteunt.
"Catalog Rebound" is enkel bedoeld voor intern gebruik.
Werkruimte/server-alias
In tegenstelling tot Azure Analysis Services worden servernaamaliassen niet ondersteund voor Premium-werkruimten.
DISCOVER_M_EXPRESSIONS
De DMV-DISCOVER_M_EXPRESSIONS gegevensbeheerweergave (DMV) wordt momenteel niet ondersteund in Power BI met behulp van het XMLA-eindpunt. Toepassingen kunnen het tabellaire objectmodel (TOM) gebruiken om M-expressies te verkrijgen die door het gegevensmodel worden gebruikt.
Hulpmiddel voor het beheren van opdrachtgeheugenlimiet in Premium
Premium-capaciteiten gebruiken resourcebeheer om ervoor te zorgen dat geen enkele bewerking van een semantisch model de beschikbare geheugenresources voor de capaciteit kan overschrijden, zoals bepaald door de SKU. Een P1-abonnement heeft bijvoorbeeld een effectieve geheugenlimiet per item van 25 GB, voor een P2-abonnement is de limiet 50 GB en voor een P3-abonnement is de limiet 100 GB. Naast de semantische modelgrootte (database) is de effectieve geheugenlimiet ook van toepassing op onderliggende semantische modelopdrachtbewerkingen zoals Maken, Wijzigen en Vernieuwen.
De effectieve geheugenlimiet voor een opdracht is gebaseerd op de lagere geheugenlimiet van de capaciteit (bepaald door SKU) of de waarde van de eigenschap DbpropMsmdRequestMemoryLimit XMLA.
Bijvoorbeeld voor een P1-capaciteit, als:
DbpropMsmdRequestMemoryLimit = 0 (of niet opgegeven), de effectieve geheugenlimiet voor de opdracht is 25 GB.
DbpropMsmdRequestMemoryLimit = 5 GB, de effectieve geheugenlimiet voor de opdracht is 5 GB.
DbpropMsmdRequestMemoryLimit = 50 GB, de effectieve geheugenlimiet voor de opdracht is 25 GB.
Normaal gesproken wordt de effectieve geheugenlimiet voor een opdracht berekend op het geheugen dat is toegestaan voor het semantische model door de capaciteit (25 GB, 50 GB, 100 GB) en hoeveel geheugen het semantische model al verbruikt wanneer de opdracht wordt uitgevoerd. Een semantisch model met 12 GB op een P1-capaciteit maakt bijvoorbeeld een effectieve geheugenlimiet mogelijk voor een nieuwe opdracht van 13 GB. De effectieve geheugenlimiet kan echter verder worden beperkt door de eigenschap DbPropMsmdRequestMemoryLimit XMLA wanneer deze optioneel is opgegeven door een toepassing. Als in het vorige voorbeeld 10 GB is opgegeven in de eigenschap DbPropMsmdRequestMemoryLimit, wordt de effectieve limiet van de opdracht verder verlaagd tot 10 GB.
Als de opdrachtbewerking probeert meer geheugen te verbruiken dan is toegestaan door de limiet, kan de bewerking mislukken en wordt er een fout geretourneerd. De volgende fout beschrijft bijvoorbeeld een effectieve geheugenlimiet van 25 GB (P1-capaciteit) is overschreden omdat het semantische model al 12 GB (12288 MB) heeft verbruikt toen de opdracht werd uitgevoerd en een effectieve limiet van 13 GB (13312 MB) is toegepast voor de opdrachtbewerking:
Beheer van middelen: deze bewerking is geannuleerd omdat er niet genoeg geheugen beschikbaar was om de uitvoering ervan te voltooien. Verhoog het geheugen van de Premium-capaciteit waar dit semantische model wordt gehost of verminder de geheugenvoetafdruk van uw semantische model door bijvoorbeeld de hoeveelheid geïmporteerde gegevens te beperken. Meer informatie: verbruikt geheugen 13312 MB, geheugenlimiet 13312 MB, databasegrootte vóór opdrachtuitvoering 12288 MB. Meer informatie: https://go.microsoft.com/fwlink/?linkid=2159753"
In sommige gevallen is 'verbruikt geheugen' 0, zoals in de volgende fout wordt weergegeven, maar de hoeveelheid die wordt weergegeven voor databasegrootte voordat de opdracht wordt uitgevoerd, is al groter dan de effectieve geheugenlimiet. Dit betekent dat de bewerking niet kan worden uitgevoerd omdat de hoeveelheid geheugen die al door het semantische model wordt gebruikt, groter is dan de geheugenlimiet voor de SKU.
Beheer van resources: Deze bewerking is geannuleerd omdat er niet genoeg geheugen was om deze te voltooien. Verhoog het geheugen van de Premium-capaciteit waar dit semantische model wordt gehost of verminder de geheugenvoetafdruk van uw semantische model door bijvoorbeeld de hoeveelheid geïmporteerde gegevens te beperken. Meer informatie: verbruikt geheugen 0 MB, geheugenlimiet 25600 MB, databasegrootte voor uitvoering van opdracht 26000 MB. Meer informatie: https://go.microsoft.com/fwlink/?linkid=2159753"
Om te voorkomen dat de effectieve geheugenlimiet wordt overschreden:
- Voer een upgrade uit naar een grotere Premium-capaciteit (SKU) voor het semantische model.
- Verminder de geheugenvoetafdruk van uw semantische model door de hoeveelheid gegevens te beperken die bij elke vernieuwing wordt geladen.
- Voor vernieuwingsbewerkingen via het XMLA-eindpunt vermindert u het aantal partities dat parallel wordt verwerkt. Te veel partities die parallel met één opdracht worden verwerkt, kunnen de effectieve geheugenlimiet overschrijden.
Gerelateerde inhoud
- Semantische modelconnectiviteit met het XMLA-eindpunt
- Automatiseer Premium-werkruimte en semantische modeltaken met service-principals
- Problemen met Analyse in Excel oplossen
- Tabular model solution deployment (Implementatie van oplossingen met tabellaire modellen)