Workloads in een Premiumcapaciteit configureren
In dit artikel worden de werkbelastingen voor Power BI Premium vermeld en worden hun capaciteiten beschreven.
Notitie
Workloads kunnen worden ingeschakeld en toegewezen aan een capaciteit met behulp van de REST API's voor capaciteiten .
Ondersteunde workloads
Queryworkloads worden geoptimaliseerd voor en beperkt door de resources zoals bepaald door uw Premium-capaciteitsspecificatie (SKU). Premium-capaciteiten ondersteunen ook extra werklasten die gebruik kunnen maken van de resources van uw capaciteit.
In de onderstaande lijst met workloads wordt beschreven welke Premium-SKU's elke workload ondersteunen:
AI: alle SKU's worden ondersteund, afgezien van de EM1/A1-SKU's
Semantische modellen : alle SKU's worden ondersteund
Gegevensstromen : alle SKU's worden ondersteund
Gepagineerde rapporten - Alle SKU's worden ondersteund
Workloads configureren
U kunt het gedrag van de workloads afstemmen door workloadinstellingen voor uw capaciteit te configureren.
Belangrijk
Alle workloads zijn altijd ingeschakeld en kunnen niet worden uitgeschakeld. Uw capaciteitsbronnen worden beheerd door Power BI op basis van uw capaciteitsgebruik.
Workloads configureren in de Power BI-beheerportal
Meld u aan bij Power BI met uw beheerdersaccountreferenties.
Selecteer in de paginakoptekst ...>Beheerportal voor instellingen>.
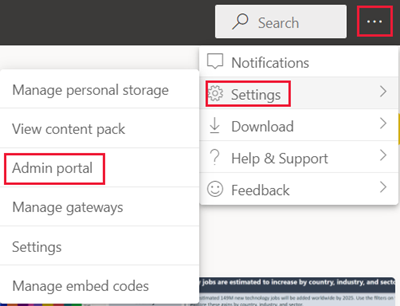
Ga naar Capaciteitsinstellingen en selecteer een capaciteit op het tabblad Power BI Premium .
Klap Workloads uit.
Stel de waarden voor elke workload in op basis van uw specificaties.
Kies Toepassen.
Werkbelastingen bewaken
Gebruik de microsoft Fabric Capacity Metrics-app om de activiteit van uw capaciteit te bewaken.
Belangrijk
Als uw Power BI Premium-capaciteit een hoog resourcegebruik ondervindt, wat resulteert in prestatie- of betrouwbaarheidsproblemen, kunt u e-mailberichten met meldingen ontvangen om het probleem te identificeren en op te lossen. Dit kan een gestroomlijnde manier zijn om problemen met overbelaste capaciteiten op te lossen. Zie Meldingen voor meer informatie.
AI (Preview)
Met de AI-workload kunt u cognitieve services en geautomatiseerde machine learning gebruiken in Power BI. Gebruik de volgende instellingen om het gedrag van de werkbelasting te beheren.
| Instellingsnaam | Beschrijving |
|---|---|
| Maximaal geheugen (%)1 | Het maximumpercentage van het beschikbare geheugen dat AI-processen in een capaciteit kunnen gebruiken. |
| Gebruik vanuit Power BI Desktop toestaan | Deze instelling is gereserveerd voor toekomstig gebruik en wordt niet weergegeven in alle gebruikers. |
| Machine Learning-modellen bouwen toestaan | Hiermee geeft u op of bedrijfsanalisten machine learning-modellen rechtstreeks in Power BI kunnen trainen, valideren en aanroepen. Zie Geautomatiseerde machine learning in Power BI (preview) voor meer informatie. |
| Parallellisme inschakelen voor AI-aanvragen | Hiermee geeft u op of AI-aanvragen parallel kunnen worden uitgevoerd. |
Voor 1Premium hoeven geen geheugeninstellingen te worden gewijzigd. Geheugen in Premium wordt automatisch beheerd door het onderliggende systeem.
Semantische modellen
In deze sectie worden de volgende workloadinstellingen voor semantische modellen beschreven:
Power BI-instellingen
Gebruik de instellingen in de onderstaande tabel om het gedrag van de werkbelasting te beheren. Instellingen met een koppeling bevatten aanvullende informatie die u in aangewezen secties onder de tabel kunt bekijken.
| Instellingsnaam | Beschrijving |
|---|---|
| Maximaal geheugen (%)1 | Het maximumpercentage van het beschikbare geheugen dat semantische modellen in een capaciteit kunnen gebruiken. |
| XMLA-eindpunt | Hiermee specificeert u dat verbindingen van cliëntapplicaties het lidmaatschap van de beveiligingsgroep volgen, zoals ingesteld op het werkruimte- en applicatieniveau. Zie Verbinding maken met semantische modellen met clienttoepassingen en hulpprogramma's voor meer informatie. |
| Maximaal aantal tussenliggende rijenset | Het maximum aantal tussenliggende rijen dat door DirectQuery wordt geretourneerd. De standaardwaarde is 10000000 en het toegestane bereik ligt tussen 100000 en 2147483646. De bovengrens moet mogelijk verder worden beperkt op basis van wat de gegevensbron ondersteunt. |
| Maximale grootte van offline semantisch model (GB) | De maximale grootte van het offline semantische model in het geheugen. Dit is de gecomprimeerde grootte op schijf. De standaardwaarde is 0. Dit is de hoogste limiet die is gedefinieerd door de SKU. Het toegestane bereik ligt tussen 0 en de maximale capaciteitsgrootte. |
| Maximumaantal resultaatrijen | Het maximum aantal rijen dat wordt geretourneerd in een DAX-query. De standaardwaarde is 2147483647 en het toegestane bereik ligt tussen 10000 en 2147483647. |
| Geheugenlimiet voor query's (%) | Het maximumpercentage van het beschikbare geheugen in de workload dat kan worden gebruikt voor het uitvoeren van een MDX- of DAX-query. De standaardwaarde is 0, wat resulteert in een SKU-specifieke automatische geheugenlimiet voor query's. |
| Query-time-out (seconden) | De maximale hoeveelheid tijd voordat er een time-out optreedt voor een query. De standaardwaarde is 3600 seconden (1 uur). Een waarde van 0 geeft aan dat er geen time-out optreedt voor query's. |
| Pagina automatisch vernieuwen | In-/uitschakelen zodat Premium-werkruimten rapporten met automatische paginavernieuwing kunnen hebben op basis van vaste intervallen. |
| Minimaal vernieuwingsinterval | Als het automatisch vernieuwen van pagina's is ingeschakeld, is het minimale interval dat is toegestaan voor het vernieuwingsinterval van de pagina. De standaardwaarde is vijf minuten en de minimaal toegestane waarde is één seconde. |
| Meting voor veranderingdetectie | In-/uitschakelen zodat Premium-werkruimten rapporten kunnen hebben met automatisch vernieuwen van pagina's op basis van wijzigingsdetectie. |
| Minimale uitvoeringsinterval | Als de meting voor wijzigingsdetectie is ingeschakeld, is het minimale toegestane uitvoeringsinterval om te peilen naar gegevenswijzigingen. De standaardwaarde is vijf seconden en de minimaal toegestane waarde is één seconde. |
Voor 1Premium hoeven geen geheugeninstellingen te worden gewijzigd. Geheugen in Premium wordt automatisch beheerd door het onderliggende systeem.
Maximum aantal tussenliggende rijen set
Gebruik deze instelling om de impact van resource-intensieve of slecht ontworpen rapporten te beheren. Wanneer een query naar een semantisch DirectQuery-model resulteert in een zeer groot resultaat van de brondatabase, kan dit leiden tot een piek in het geheugengebruik en de verwerkingsoverhead. Deze situatie kan ertoe leiden dat andere gebruikers en rapporten weinig resources hebben. Met deze instelling kan de capaciteitsbeheerder aanpassen hoeveel rijen een afzonderlijke query kan ophalen uit de gegevensbron.
Als de capaciteit meer dan de standaardwaarde van één miljoen rijen kan ondersteunen en u een groot semantisch model hebt, verhoogt u deze instelling om meer rijen op te halen.
Deze instelling beïnvloedt alleen DirectQuery-query's, terwijl Max Result Row Set Count DAX-query's beïnvloedt.
Maximale grootte van offline semantisch model
Gebruik deze instelling om te voorkomen dat makers van rapporten een groot semantisch model publiceren dat een negatieve invloed kan hebben op de capaciteit. Power BI kan de werkelijke grootte van het geheugen pas bepalen als het semantische model in het geheugen is geladen. Het is mogelijk dat een semantisch model met een kleinere offlinegrootte een grotere geheugenvoetafdruk kan hebben dan een semantisch model met een grotere offlinegrootte.
Als u een bestaand semantisch model hebt dat groter is dan de grootte die u voor deze instelling opgeeft, kan het semantische model niet worden geladen wanneer een gebruiker er toegang toe probeert te krijgen. Het semantische model kan ook niet worden geladen als het groter is dan het maximale geheugen dat is geconfigureerd voor de workload van semantische modellen.
Deze instelling is van toepassing op modellen in zowel een kleine semantische modelopslagindeling (ABF-indeling) als een grote semantische modelopslagindeling (PremiumFiles), hoewel de offlinegrootte van hetzelfde model kan verschillen wanneer het model is opgeslagen in de ene indeling versus de andere. Zie Grote modellen in Power BI Premium voor meer informatie.
Om de prestaties van het systeem te beschermen, wordt een extra SKU-specifiek hard plafond toegepast voor maximale offline semantische modelgrootte, ongeacht de geconfigureerde waarde. Het extra SKU-specifieke harde plafond in de onderstaande tabel is niet van toepassing op semantische Power BI-modellen die zijn opgeslagen in een grote semantische modelopslagindeling.
| SKU | Limiet1 |
|---|---|
| F2 | 1 GB |
| F4 | 2 GB |
| F8/EM1/A1 | 3 GB |
| F16/EM2/A2 | 5 GB |
| F32/EM3/A3 | 6 GB |
| F64/P1/A4 | 10 GB |
| F128/P2/A5 | 10 GB |
| F256/P3/A6 | 10 GB |
| F512/P4/A7 | 10 GB |
| F1024/P5/A8 | 10 GB |
| F2048 | 10 GB |
1Hard plafond voor maximale semantische modelgrootte offline (kleine opslagindeling).
Maximumaantal resultatenrijen
Gebruik deze instelling om de impact van resource-intensieve of slecht ontworpen rapporten te beheren. Als deze limiet is bereikt in een DAX-query, ziet een rapportgebruiker de volgende fout. Ze moeten de foutgegevens kopiëren en contact opnemen met een beheerder.
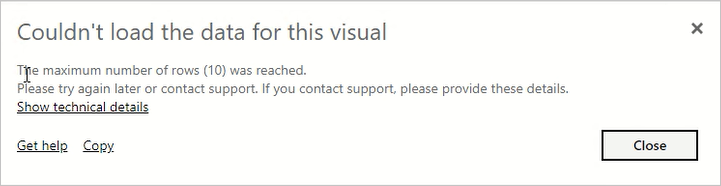
Deze instelling is alleen van invloed op DAX-query's, terwijl het maximumaantal tussenliggende rijensets directQuery-query's beïnvloedt.
Geheugenlimiet voor query's
Gebruik deze instelling om de impact van resource-intensieve of slecht ontworpen rapporten te beheren. Sommige query's en berekeningen kunnen leiden tot tussenliggende resultaten die veel geheugen op de capaciteit gebruiken. Deze situatie kan ertoe leiden dat andere query's zeer langzaam worden uitgevoerd, leiden tot verwijdering van andere semantische modellen uit de capaciteit en leiden tot geheugenfouten voor andere gebruikers van de capaciteit.
Deze instelling is van toepassing op alle DAX- en MDX-query's die worden uitgevoerd door Power BI-rapporten, Analyseren in Excel-rapporten en andere hulpprogramma's die verbinding kunnen maken via het XMLA-eindpunt.
Bewerkingen voor het vernieuwen van gegevens kunnen ook DAX-query's uitvoeren als onderdeel van het vernieuwen van de dashboardtegels en visualcaches nadat de gegevens in het semantische model zijn vernieuwd. Dergelijke query's kunnen mogelijk ook mislukken vanwege deze instelling. Dit kan ertoe leiden dat de bewerking voor het vernieuwen van gegevens in een mislukte status wordt weergegeven, ook al zijn de gegevens in het semantische model bijgewerkt.
De standaardinstelling is 0, wat resulteert in de volgende SKU-specifieke automatische geheugenlimiet voor query's.
| artikelnummer | Geheugenlimiet voor automatische query's |
|---|---|
| F2 | 1 GB |
| F4 | 1 GB |
| F8/EM1/A1 | 1 GB |
| F16/EM2/A2 | 2 GB |
| F32/EM3/A3 | 5 GB |
| F64/P1/A4 | 10 GB |
| F128/P2/A5 | 10 GB |
| F256/P3/A6 | 10 GB |
| F512/P4/A7 | 20 GB |
| F1024/P5/A8 | 40 GB |
| F2048 | 40 GB |
De querylimiet voor een werkruimte die niet is toegewezen aan een Premium-capaciteit is 1 GB.
Query-time-out
Gebruik deze instelling om betere controle te houden over langlopende query's, waardoor rapporten langzaam worden geladen voor gebruikers.
Deze instelling is van toepassing op alle DAX- en MDX-query's die worden uitgevoerd door Power BI-rapporten, Analyseren in Excel-rapporten en andere hulpprogramma's die verbinding kunnen maken via het XMLA-eindpunt.
Bewerkingen voor het vernieuwen van gegevens kunnen ook DAX-query's uitvoeren als onderdeel van het vernieuwen van de dashboardtegels en visualcaches nadat de gegevens in het semantische model zijn vernieuwd. Dergelijke query's kunnen mogelijk ook mislukken vanwege deze instelling. Dit kan ertoe leiden dat de bewerking voor het vernieuwen van gegevens in een mislukte status wordt weergegeven, ook al zijn de gegevens in het semantische model bijgewerkt.
Deze instelling is van toepassing op één query en niet op de tijd die nodig is om alle query's uit te voeren die zijn gekoppeld aan het bijwerken van een semantisch model of rapport. Kijk een naar het volgende voorbeeld:
- De Time-outinstelling voor query's is 1200 (20 minuten).
- Er zijn vijf query's die moeten worden uitgevoerd en elke query wordt 15 minuten uitgevoerd.
De gecombineerde tijd voor alle query's is 75 minuten, maar de instellingslimiet is niet bereikt omdat alle afzonderlijke query's minder dan 20 minuten worden uitgevoerd.
Houd er rekening mee dat Power BI-rapporten deze standaardinstelling overschrijven met een veel kleinere time-out voor elke query naar de capaciteit. De time-out voor elke query duurt doorgaans ongeveer drie minuten.
Pagina automatisch vernieuwen
Wanneer automatische paginavernieuwing is ingeschakeld, kunnen gebruikers in uw Premium-capaciteit pagina's in hun rapport vernieuwen met een gedefinieerd interval, voor DirectQuery-bronnen. Als capaciteitsbeheerder kunt u het volgende doen:
- Pagina automatisch vernieuwen in- en uitschakelen
- Een minimaal vernieuwingsinterval definiëren
Ga als volgende te werk om de instelling voor het automatisch vernieuwen van pagina's te vinden:
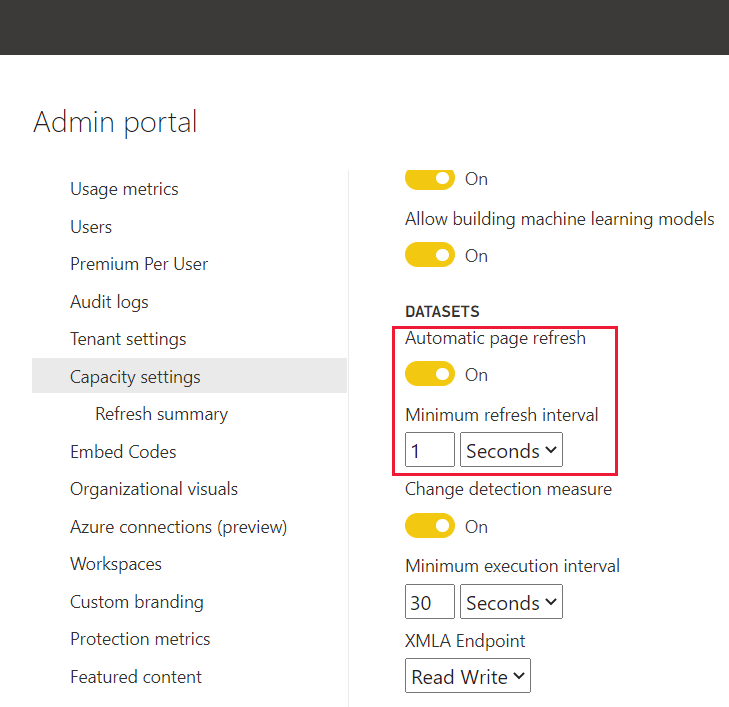
Selecteer Capaciteitsinstellingen in de Power BI-beheerportal.
Selecteer uw capaciteit en schuif omlaag en vouw het menu Workloads uit.
Schuif omlaag naar de sectie Semantische modellen .
Query's die zijn gemaakt door het automatisch vernieuwen van pagina's, gaan rechtstreeks naar de gegevensbron, dus het is belangrijk dat u rekening houdt met betrouwbaarheid en belasting van deze bronnen wanneer u automatische paginavernieuwing in uw organisatie toestaat.
Eigenschappen van Analysis Services-server
Power BI Premium ondersteunt aanvullende Analysis Services-servereigenschappen. Als u deze eigenschappen wilt bekijken, raadpleegt u Server-eigenschappen in Analysis Services.
Overschakeling voor beheerportaal
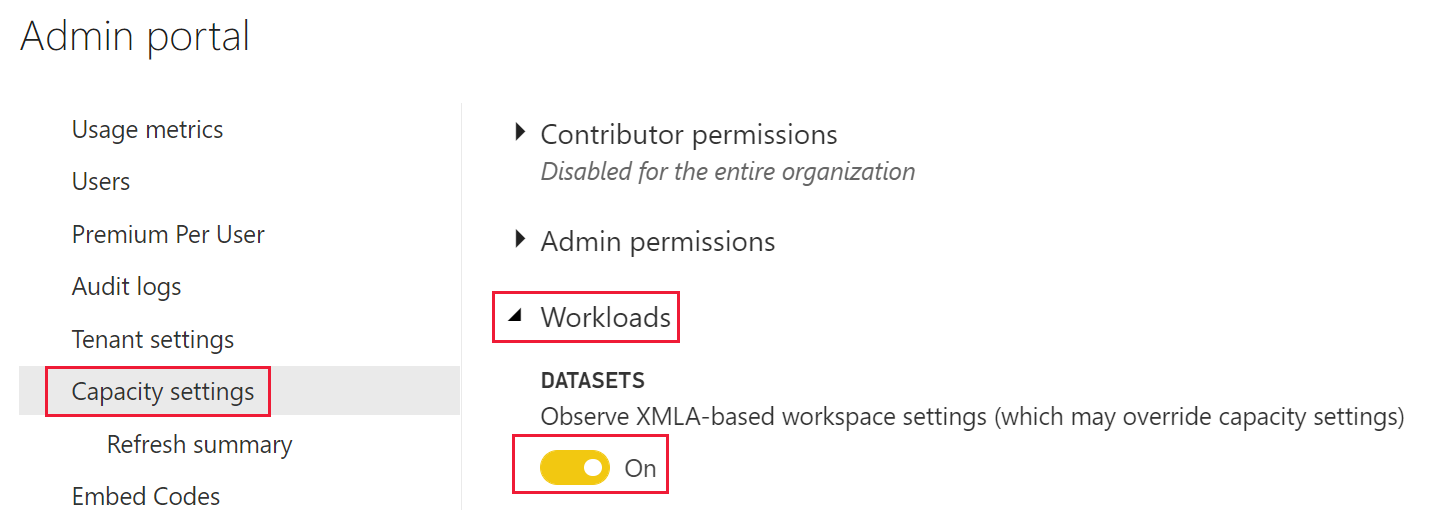
De instelling voor op XMLA gebaseerde servereigenschappen van Analysis Services is standaard ingeschakeld. Wanneer deze functie is ingeschakeld, kunnen werkruimtebeheerders gedrag voor een afzonderlijke werkruimte wijzigen. Gewijzigde eigenschappen zijn alleen van toepassing op die werkruimte. Volg de onderstaande stappen om de instelling voor de eigenschappen van de Analysis Services-server in te schakelen.
Ga naar uw capaciteitsinstellingen.
Selecteer de capaciteit waarin u de eigenschappen van de Analysis Services-server wilt uitschakelen.
Klap Werkbelastingen uit.
Selecteer onder semantische modellen de gewenste instelling voor de schakeloptie Op XMLA gebaseerde werkruimte-instellingen observeren (waardoor capaciteitsinstellingen mogelijk worden overschreven).
Gegevensstromen
Met de gegevensstromenwerkload kunt u self-servicegegevensvoorbereiding gebruiken om gegevens op te nemen, te transformeren, te integreren en te verrijken. Gebruik de volgende instellingen om het gedrag van workloads in Premium te beheren. Voor Power BI Premium hoeven geen geheugeninstellingen te worden gewijzigd. Geheugen in Premium wordt automatisch beheerd door het onderliggende systeem.
Verbeterde berekeningsengine voor gegevensstromen
Als u wilt profiteren van de nieuwe berekeningsengine, splitst u de opname van gegevens in afzonderlijke gegevensstromen en plaatst u transformatielogica in berekende entiteiten in verschillende gegevensstromen. Deze methode wordt aanbevolen omdat de berekeningsengine werkt op gegevensstromen die verwijzen naar een bestaande gegevensstroom. Het werkt niet bij opnamegegevensstromen. Door deze richtlijnen te volgen, zorgt u ervoor dat de nieuwe berekeningsengine transformatiestappen, zoals joins en samenvoegingen, verwerkt voor optimale prestaties.
Gepagineerde rapporten
Met de workload voor gepagineerde rapporten kunt u gepagineerde rapporten uitvoeren op basis van de standaard SQL Server Reporting Services-indeling in de Power BI-service.
Gepagineerde rapporten bieden dezelfde mogelijkheden als SQL Server Reporting Services-rapporten (SSRS) vandaag, waaronder de mogelijkheid voor rapportauteurs om aangepaste code toe te voegen. Hierdoor kunnen auteurs rapporten dynamisch wijzigen, zoals het wijzigen van tekstkleuren op basis van code-expressies.
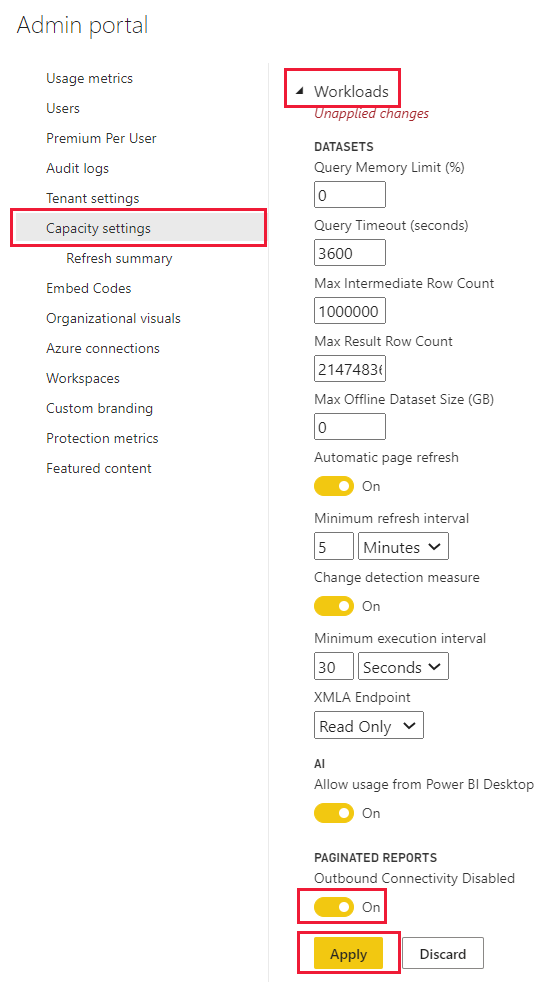
Uitgaande connectiviteit
Uitgaande connectiviteit is standaard ingeschakeld. Hiermee kunnen gepagineerde rapporten aanvragen indienen voor het ophalen van externe resources, zoals afbeeldingen, en het aanroepen van externe API's en Azure-functies die zijn gedefinieerd met behulp van aangepaste code in gepagineerde rapporten. Een Fabric-beheerder kan deze instelling uitschakelen in de Power BI-beheerportal.
Voer de volgende stappen uit om toegang te krijgen tot de uitgaande connectiviteitsinstellingen:
Navigeer in Power BI-service naar de beheerportal.
Selecteer op het tabblad Power BI Premium de capaciteit waarvoor u uitgaande aanvragen voor gepagineerde rapporten wilt uitschakelen.
Klap workloads uit.
De uitgaande connectiviteitsswitch bevindt zich in de sectie van Gepagineerde Rapporten.
Wanneer uitgaande connectiviteit uitschakelen is uitgeschakeld, is uitgaande connectiviteit ingeschakeld.
Wanneer uitgaande connectiviteit uitschakelen is ingeschakeld, wordt uitgaande connectiviteit uitgeschakeld.
Nadat u een wijziging hebt aangebracht, selecteert u Toepassen.
De functie voor gepagineerde rapporten wordt automatisch ingeschakeld en staat altijd ingeschakeld.