Gegevens ophalen uit OneLake
In dit artikel leert u hoe u gegevens uit OneLake kunt ophalen in een nieuwe of bestaande tabel.
Voorwaarden
- Een werkruimte met een capaciteit met Microsoft Fabric
- Een Lakehouse-
- Een KQL-database met bewerkingsmachtigingen
Bestandspad kopiëren vanuit Lakehouse
Selecteer in uw werkruimte de Lakehouse-omgeving met de gegevensbron die u wilt gebruiken.
Plaats de cursor op het gewenste bestand en selecteer het menu Meer (...) en selecteer vervolgens Eigenschappen.
Belangrijk
- Mappaden worden niet ondersteund.
- Jokertekens (*) worden niet ondersteund.
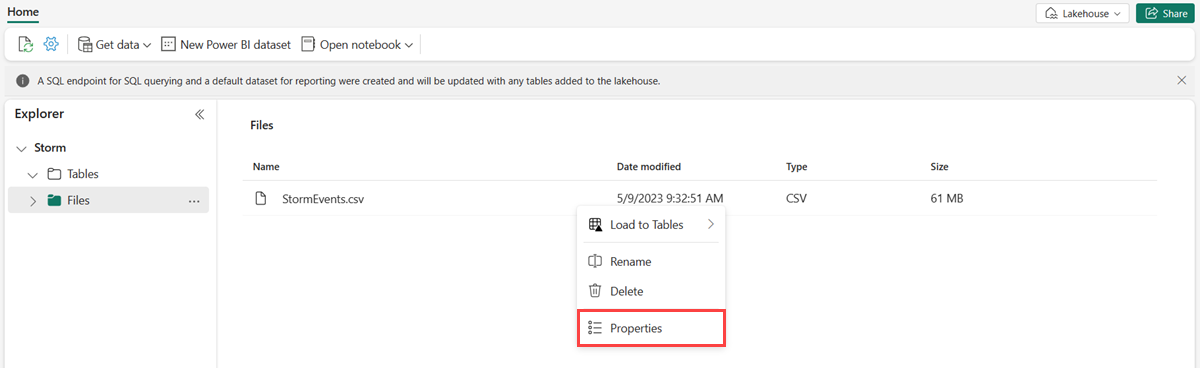
Selecteer onder URLhet pictogram Kopiëren naar klembord en sla deze ergens op om op te halen in een latere stap.

Ga terug naar uw werkruimte en selecteer een KQL-database.


Bron
Selecteer op het onderste lint van uw KQL-database Gegevens ophalen.
In het venster Gegevens ophalen is het tabblad Bron geselecteerd.
Selecteer de gegevensbron in de beschikbare lijst. In dit voorbeeld neemt u gegevens op uit OneLake-.
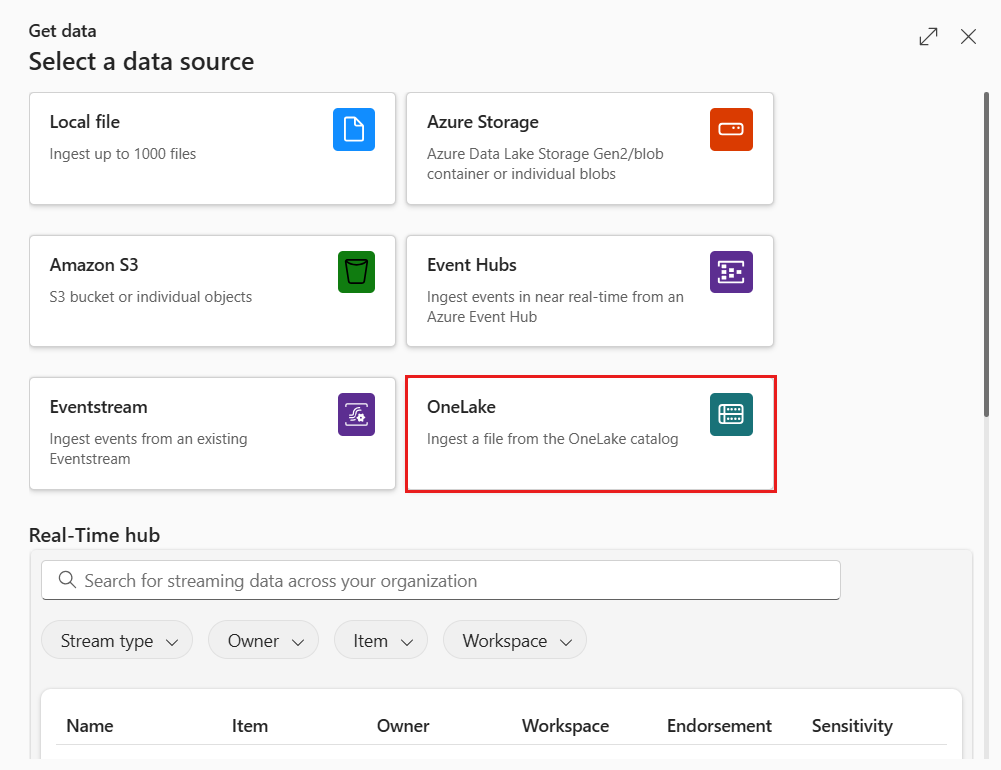

Configureren
Selecteer een doeltabel. Als u gegevens wilt opnemen in een nieuwe tabel, selecteert u +Nieuwe tabel en voert u een tabelnaam in.
Notitie
Tabelnamen kunnen maximaal 1024 tekens zijn, waaronder spaties, alfanumerieke, afbreekstreepjes en onderstrepingstekens. Speciale tekens worden niet ondersteund.
Plak in OneLake-bestandhet bestandspad van het Lakehouse dat u hebt gekopieerd in Bestandspad kopiëren van Lakehouse.
Notitie
U kunt maximaal 10 items van maximaal 1 GB ongecomprimeerd formaat toevoegen.
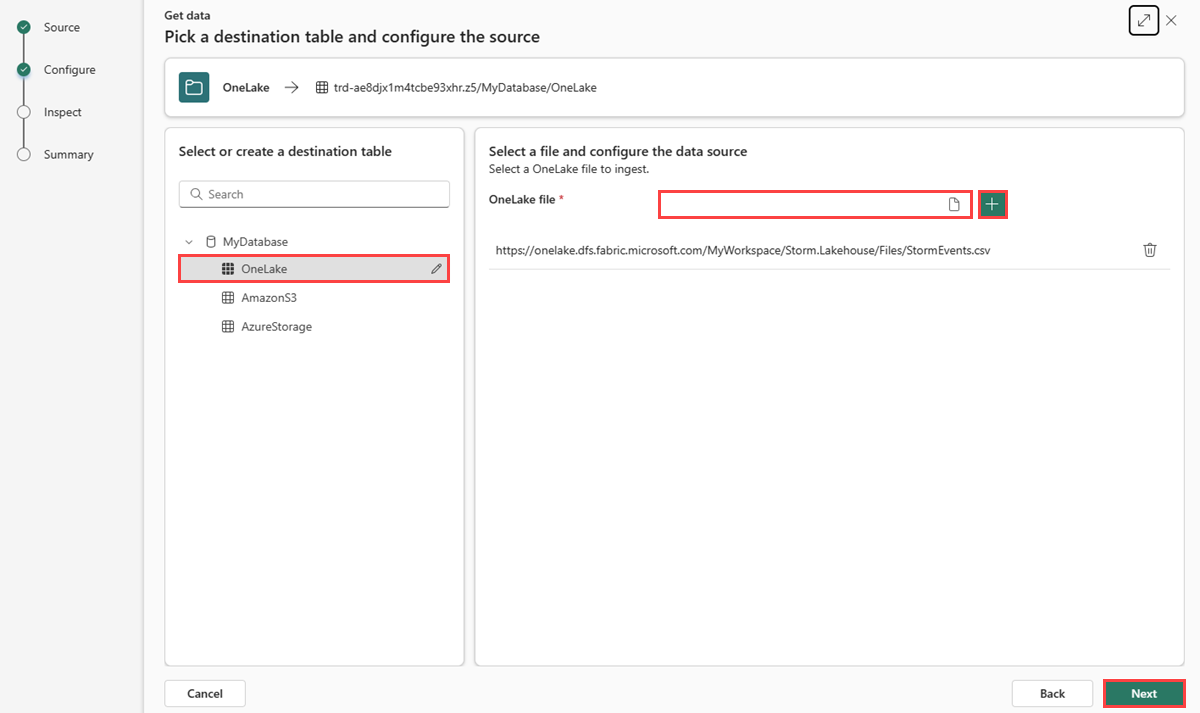
Selecteer Volgende.

Inspecteren
Het tabblad Controleren wordt geopend met een voorbeeld van de gegevens.
Om het opnameproces te voltooien, selecteert u Voltooien.

Optioneel:
- Selecteer opdrachtviewer om de automatische opdrachten weer te geven en te kopiëren die zijn gegenereerd op basis van uw invoer.
- Gebruik het schemadefinitiebestand vervolgkeuzelijst om het bestand te wijzigen waaruit het schema is afgeleid.
- Wijzig de automatisch uitgestelde gegevensindeling door de gewenste indeling in de vervolgkeuzelijst te selecteren. Zie Gegevensindelingen die worden ondersteund door Real-Time Intelligencevoor meer informatie.
- Bewerk kolommen.
- Verken geavanceerde opties op basis van gegevenstype.
Kolommen bewerken
Notitie
- Voor tabelindelingen (CSV, TSV, PSV) kunt u een kolom niet twee keer toewijzen. Om toe te wijzen aan een bestaande kolom, verwijder eerst de nieuwe kolom.
- U kunt een bestaand kolomtype niet wijzigen. Als u probeert toe te wijzen aan een kolom met een ander formaat, kunt u uiteindelijk eindigen met lege kolommen.
De wijzigingen die u in een tabel kunt aanbrengen, zijn afhankelijk van de volgende parameters:
- tabeltype is nieuw of bestaand
- Het toewijzingstype is nieuw of bestaand
| Tabeltype | Toewijzingstype | Beschikbare aanpassingen |
|---|---|---|
| Nieuwe tabel | Nieuwe kaart | Naam van kolom wijzigen, gegevenstype wijzigen, gegevensbron wijzigen, toewijzingstransformatie, kolom toevoegen, kolom verwijderen |
| Bestaande tabel | Nieuwe kaart | Kolom toevoegen (waarop u vervolgens het gegevenstype, de naam kunt wijzigen en bijwerken) |
| Bestaande tabel | Bestaande koppeling | geen |

Toewijzingstransformaties
Sommige toewijzingen van gegevensindelingen (Parquet, JSON en Avro) ondersteunen eenvoudige transformaties tijdens het inladen van gegevens. Als u toewijzingstransformaties wilt toepassen, maakt u een kolom aan of werkt u deze bij in het venster Kolommen bewerken.
Koppelingstransformaties kunnen worden uitgevoerd op een kolom van het type tekenreeks of datum/tijd, waarbij de bron gegevenstype int of long heeft. Ondersteunde toewijzingstransformaties zijn:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconden
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Geavanceerde opties op basis van gegevenstype
Tabellaire(CSV, TSV, PSV):
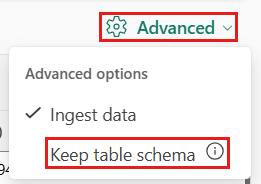
Als u tabelformaten importeert in een bestaande tabel, kunt u Geavanceerd>Tabelschema behoudenselecteren. Tabelgegevens bevatten niet noodzakelijkerwijs de kolomnamen die worden gebruikt om brongegevens toe te wijzen aan de bestaande kolommen. Wanneer deze optie is aangevinkt, wordt de toewijzing op volgorde uitgevoerd en blijft het tabelschema hetzelfde. Als deze optie is uitgeschakeld, worden nieuwe kolommen gemaakt voor binnenkomende gegevens, ongeacht de gegevensstructuur.
Als u de eerste rij als kolomnamen wilt gebruiken, selecteert u Advanced>Eerste rij is kolomkop.
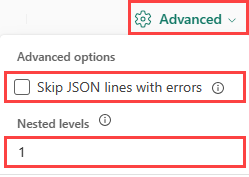
JSON
Als u de kolomverdeling van JSON-gegevens wilt bepalen, selecteert u Advanced>Geneste niveaus, van 1 tot en met 100.
Als u Geavanceerde>JSON-regels met fouten overslaanselecteert, worden de gegevens in JSON-indeling opgenomen. Als u dit selectievakje uitgeschakeld laat, worden de gegevens opgenomen in multijson-indeling.
Samenvatting
In het venster Gegevensvoorbereiding worden alle drie de stappen gemarkeerd met groene vinkjes wanneer de gegevensopname is voltooid. U kunt een kaart selecteren om een query uit te voeren, de opgenomen gegevens te verwijderen of een dashboard van uw opnameoverzicht te bekijken.
