Gegevens opnemen in OneLake en analyseren met Azure Databricks
In deze handleiding gaat u het volgende doen:
Maak een pijplijn in een werkruimte en opname van gegevens in uw OneLake in Delta-indeling.
Een Delta-tabel lezen en wijzigen in OneLake met Azure Databricks.
Vereisten
Voordat u begint, moet u het volgende hebben:
Een werkruimte met een Lakehouse-item.
Een premium Azure Databricks-werkruimte. Alleen premium Azure Databricks-werkruimten ondersteunen Passthrough voor Microsoft Entra-referenties. Wanneer u uw cluster maakt, schakelt u azure Data Lake Storage-referentiepassthrough in in de geavanceerde opties.
Een voorbeeldgegevensset.
Gegevens opnemen en de Delta-tabel wijzigen
Navigeer naar uw Lakehouse in de Power BI-service en selecteer Gegevens ophalen en selecteer vervolgens Nieuwe gegevenspijplijn.
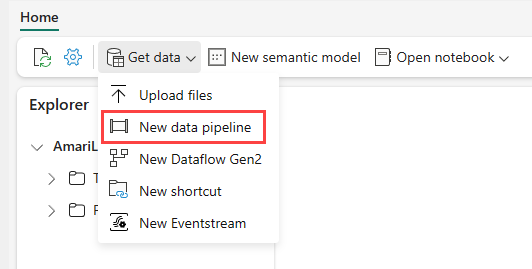
Voer in de prompt Nieuwe pijplijn een naam in voor de nieuwe pijplijn en selecteer Vervolgens Maken.
Voor deze oefening selecteert u de NYC Taxi - Groene voorbeeldgegevens als de gegevensbron en selecteert u vervolgens Volgende.
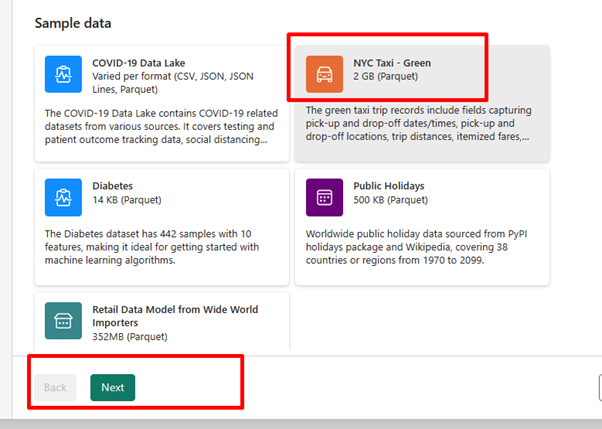
Selecteer Volgende in het voorbeeldscherm.
Selecteer voor gegevensbestemming de naam van het lakehouse dat u wilt gebruiken om de OneLake Delta-tabelgegevens op te slaan. U kunt een bestaand lakehouse kiezen of een nieuwe maken.
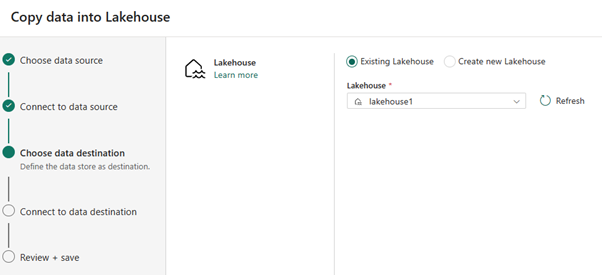
Selecteer waar u de uitvoer wilt opslaan. Kies Tabellen als de hoofdmap en voer 'nycsample' in als tabelnaam.
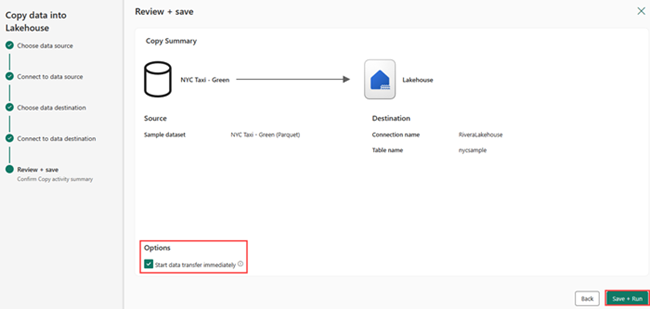
Selecteer in het scherm Controleren en opslaan de optie Gegevensoverdracht direct starten en selecteer vervolgens Opslaan en uitvoeren.
Wanneer de taak is voltooid, gaat u naar uw lakehouse en bekijkt u de deltatabel die wordt vermeld onder de map /Tables.
Klik met de rechtermuisknop op de naam van de gemaakte tabel, selecteer Eigenschappen en kopieer het ABFS-pad (Azure Blob FileSystem).
Open uw Azure Databricks-notebook. Lees de Delta-tabel in OneLake.
olsPath = "abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample" df=spark.read.format('delta').option("inferSchema","true").load(olsPath) df.show(5)Werk de Delta-tabelgegevens bij door een veldwaarde te wijzigen.
%sql update delta.`abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample` set vendorID = 99999 where vendorID = 1;