Gegevens transformeren met Apache Spark en query's uitvoeren met SQL
In deze handleiding gaat u het volgende doen:
Gegevens uploaden naar OneLake met de Verkenner van OneLake.
Gebruik een Fabric-notebook om gegevens in OneLake te lezen en terug te schrijven als een Delta-tabel.
Gegevens analyseren en transformeren met Spark met behulp van een Fabric-notebook.
Voer een query uit op één exemplaar van gegevens in OneLake met SQL.
Vereisten
Voordat u begint, moet u het volgende doen:
Download en installeer OneLake-verkenner.
Maak een werkruimte met een Lakehouse-item.
Download de WideWorldImportersDW-gegevensset. U kunt Azure Storage Explorer gebruiken om verbinding te maken met
https://fabrictutorialdata.blob.core.windows.net/sampledata/WideWorldImportersDW/csv/full/dimension_cityde set CSV-bestanden en deze te downloaden. U kunt ook uw eigen CSV-gegevens gebruiken en de details indien nodig bijwerken.
Notitie
Maak, laad of maak altijd een snelkoppeling naar Delta-Parquet-gegevens rechtstreeks onder de sectie Tabellen van het lakehouse. Nest uw tabellen niet in submappen onder de sectie Tabellen , omdat het lakehouse deze niet herkent als een tabel en deze labelt als Niet-geïdentificeerd.
Gegevens uploaden, lezen, analyseren en er query's op uitvoeren
Navigeer in De Verkenner van OneLake naar uw lakehouse en maak onder de map een submap met de
/Filesnaamdimension_city.
Kopieer uw csv-voorbeeldbestanden naar de OneLake-map
/Files/dimension_citymet behulp van OneLake-verkenner.
Navigeer naar uw lakehouse in de Power BI-service en bekijk uw bestanden.
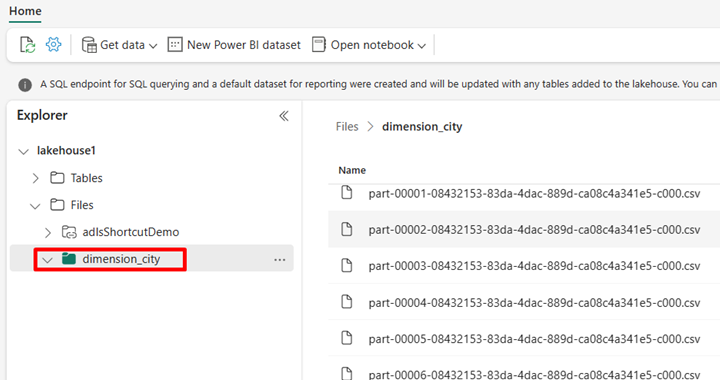
Selecteer Notitieblok openen en vervolgens Nieuw notitieblok om een notitieblok te maken.
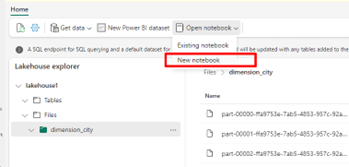
Converteer de CSV-bestanden met behulp van het Fabric-notebook naar de Delta-indeling. Met het volgende codefragment worden gegevens uit de door de gebruiker gemaakte map
/Files/dimension_citygelezen en geconverteerd naar een Delta-tabeldim_city.import os from pyspark.sql.types import * for filename in os.listdir("/lakehouse/default/Files/<replace with your folder path>"): df=spark.read.format('csv').options(header="true",inferSchema="true").load("abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Files/<folder name>/"+filename,on_bad_lines="skip") df.write.mode("overwrite").format("delta").save("Tables/<name of delta table>")Als u de nieuwe tabel wilt zien, vernieuwt u de weergave van de
/Tablesmap.
Voer een query uit op uw tabel met SparkSQL in hetzelfde Fabric-notebook.
%%sql SELECT * from <replace with item name>.dim_city LIMIT 10;Wijzig de Delta-tabel door een nieuwe kolom met de naam newColumn toe te voegen met een geheel getal van het gegevenstype. Stel de waarde van 9 in voor alle records voor deze zojuist toegevoegde kolom.
%%sql ALTER TABLE <replace with item name>.dim_city ADD COLUMN newColumn int; UPDATE <replace with item name>.dim_city SET newColumn = 9; SELECT City,newColumn FROM <replace with item name>.dim_city LIMIT 10;U kunt ook elke Delta-tabel in OneLake openen via een SQL-analyse-eindpunt. Een SQL-analyse-eindpunt verwijst naar dezelfde fysieke kopie van de Delta-tabel in OneLake en biedt de T-SQL-ervaring. Selecteer het SQL Analytics-eindpunt voor Lakehouse1 en selecteer vervolgens Nieuwe SQL-query om een query uit te voeren op de tabel met behulp van T-SQL.
SELECT TOP (100) * FROM [<replace with item name>].[dbo].[dim_city];
