OneLake integreren met Azure HDInsight
Azure HDInsight is een beheerde cloudservice voor big data-analyses waarmee organisaties grote hoeveelheden gegevens kunnen verwerken. Deze zelfstudie laat zien hoe u vanuit een Azure HDInsight-cluster verbinding maakt met OneLake met een Jupyter-notebook.
Azure HDInsight gebruiken
Verbinding maken met OneLake met een Jupyter-notebook vanuit een HDInsight-cluster:
Maak een HDInsight-cluster (HDI) voor Apache Spark. Volg deze instructies: clusters instellen in HDInsight.
Onthoud tijdens het opgeven van clustergegevens uw gebruikersnaam en wachtwoord voor clusteraanmelding, omdat u ze later nodig hebt om toegang te krijgen tot het cluster.
Maak een door de gebruiker toegewezen beheerde identiteit (UAMI): Maak voor Azure HDInsight - UAMI en kies deze als de identiteit in het opslagscherm .
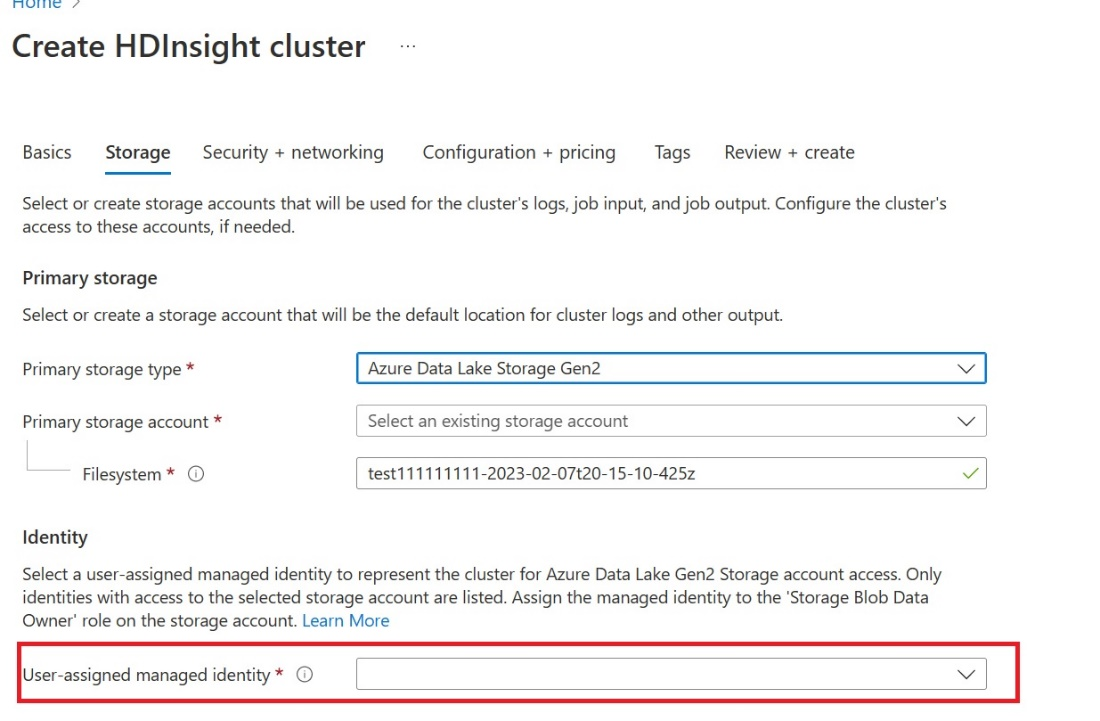
Geef deze UAMI toegang tot de Fabric-werkruimte die uw items bevat. Zie Werkruimterollen voor hulp bij het bepalen welke rol het beste is.
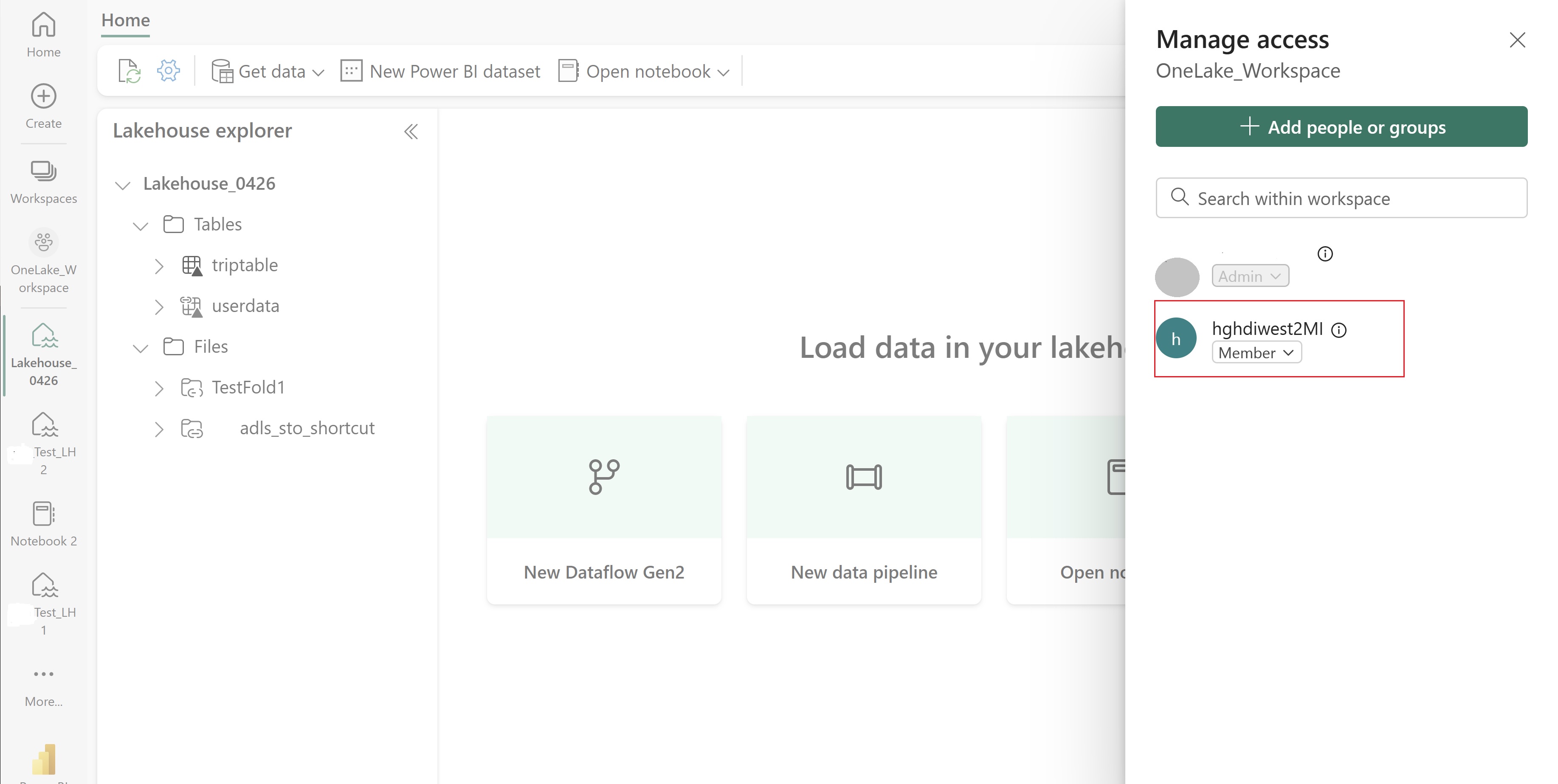
Navigeer naar uw lakehouse en zoek de naam voor uw werkruimte en lakehouse. U vindt deze in de URL van uw lakehouse of in het deelvenster Eigenschappen voor een bestand.
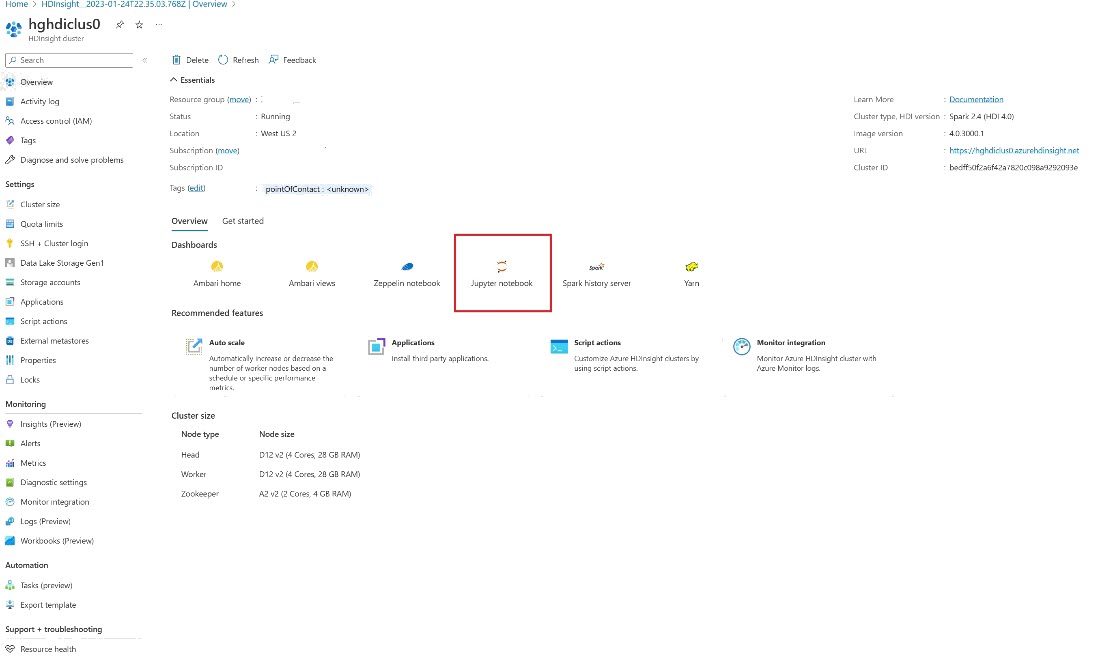
Zoek in Azure Portal naar uw cluster en selecteer het notebook.
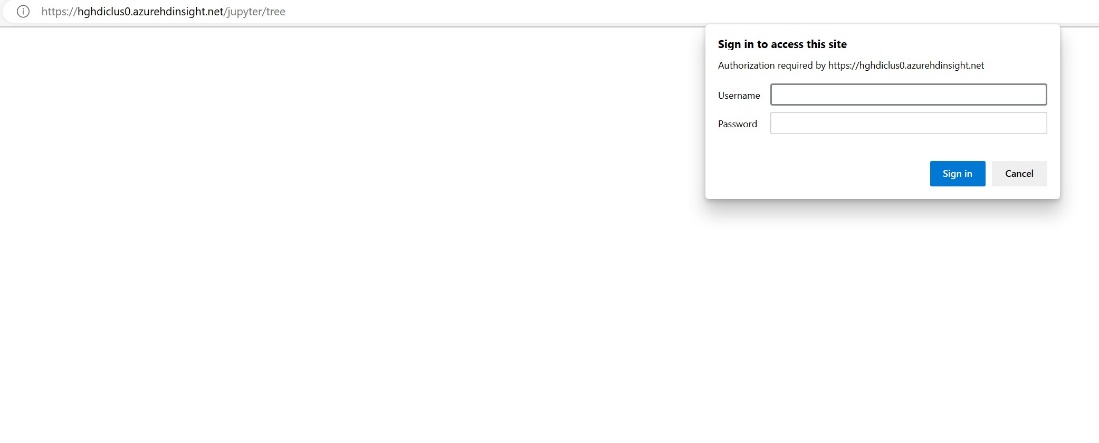
Voer de referentiegegevens in die u hebt opgegeven tijdens het maken van het cluster.
Maak een nieuw Apache Spark-notebook.
Kopieer de namen van de werkruimte en lakehouse naar uw notebook en bouw de OneLake-URL voor uw lakehouse. U kunt nu elk bestand lezen vanuit dit bestandspad.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()Probeer wat gegevens naar het lakehouse te schrijven.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Test of uw gegevens zijn geschreven door uw lakehouse te controleren of door het zojuist geladen bestand te lezen.




U kunt nu gegevens lezen en schrijven in OneLake met behulp van uw Jupyter-notebook in een HDI Spark-cluster.