OneLake integreren met Azure Databricks
In dit scenario ziet u hoe u via Azure Databricks verbinding maakt met OneLake. Nadat u deze zelfstudie hebt voltooid, kunt u vanuit uw Azure Databricks-werkruimte lezen en schrijven naar een Microsoft Fabric Lakehouse.
Vereisten
Voordat u verbinding maakt, moet u het volgende hebben:
- Een Infrastructuurwerkruimte en Lakehouse.
- Een premium Azure Databricks-werkruimte. Alleen premium Azure Databricks-werkruimten ondersteunen Passthrough voor Microsoft Entra-referentie, die u nodig hebt voor dit scenario.
Uw Databricks-werkruimte instellen
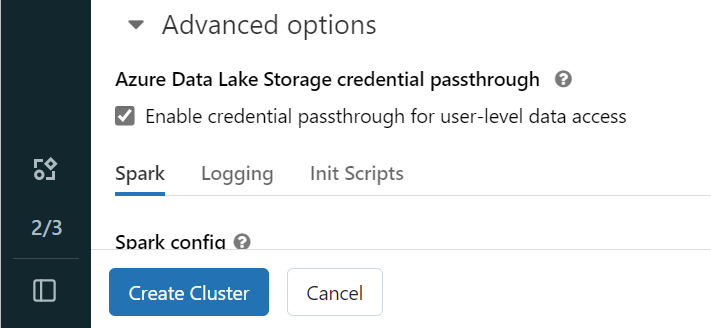
Open uw Azure Databricks-werkruimte en selecteer Cluster maken>.
Als u zich wilt verifiëren bij OneLake met uw Microsoft Entra-identiteit, moet u passthrough voor Azure Data Lake Storage-referenties (ADLS) inschakelen op uw cluster in de geavanceerde opties.
Notitie
U kunt Databricks ook verbinden met OneLake met behulp van een service-principal. Zie Service-principals beheren voor meer informatie over het verifiëren van Azure Databricks met behulp van een service-principal.
Maak het cluster met de gewenste parameters. Zie Clusters configureren - Azure Databricks voor meer informatie over het maken van een Databricks-cluster.
Open een notebook en verbind het met uw zojuist gemaakte cluster.
Uw notitieblok ontwerpen
Navigeer naar uw Fabric Lakehouse en kopieer het ABFS-pad (Azure Blob FileSystem) naar uw lakehouse. U vindt deze in het deelvenster Eigenschappen .
Notitie
Azure Databricks ondersteunt alleen het ABFS-stuurprogramma (Azure Blob FileSystem) bij het lezen en schrijven naar ADLS Gen2 en OneLake:
abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/.Sla het pad op naar uw lakehouse in uw Databricks-notebook. In dit lakehouse schrijft u uw verwerkte gegevens later:
oneLakePath = 'abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/myLakehouse.lakehouse/Files/'Laad gegevens uit een openbare Databricks-gegevensset in een dataframe. U kunt ook een bestand van elders in Fabric lezen of een bestand kiezen uit een ander ADLS Gen2-account dat u al hebt.
yellowTaxiDF = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-12.csv.gz")Uw gegevens filteren, transformeren of voorbereiden. Voor dit scenario kunt u uw gegevensset verkleinen voor sneller laden, samenvoegen met andere gegevenssets of filteren op specifieke resultaten.
filteredTaxiDF = yellowTaxiDF.where(yellowTaxiDF.fare_amount<4).where(yellowTaxiDF.passenger_count==4) display(filteredTaxiDF)Schrijf uw gefilterde dataframe naar uw Fabric Lakehouse met behulp van uw OneLake-pad.
filteredTaxiDF.write.format("csv").option("header", "true").mode("overwrite").csv(oneLakePath)Test of uw gegevens zijn geschreven door het zojuist geladen bestand te lezen.
lakehouseRead = spark.read.format('csv').option("header", "true").load(oneLakePath) display(lakehouseRead.limit(10))
Gefeliciteerd. U kunt nu gegevens lezen en schrijven in Fabric met behulp van Azure Databricks.