Zelfstudie: R gebruiken om vluchtvertraging te voorspellen
In deze handleiding wordt een end-to-end-voorbeeld van een Synapse Data Science-werkstroom in Microsoft Fabric gepresenteerd. Het maakt gebruik van de nycflights13 gegevens, en R, om te voorspellen of een vliegtuig meer dan 30 minuten te laat aankomt. Vervolgens worden de voorspellingsresultaten gebruikt om een interactief Power BI-dashboard te bouwen.
In deze zelfstudie leert u het volgende:
- Gebruik tidymodels pakketten (recepten, parsnip, rsample, werkstromen) om gegevens te verwerken en een machine learning-model te trainen
- De uitvoergegevens naar een lakehouse schrijven als een deltatabel
- Een Power BI-visualrapport maken om rechtstreeks toegang te krijgen tot gegevens in dat lakehouse
Voorwaarden
Een Microsoft Fabric-abonnementophalen. Of meld u aan voor een gratis microsoft Fabric-proefversie.
Meld u aan bij Microsoft Fabric-.
Gebruik de ervaringswisselaar aan de linkerkant van de startpagina om over te schakelen naar Fabric.

Open of maak een notitieblok. Zie Hoe u Microsoft Fabric-notebooks gebruiktom te leren hoe.
Stel de taaloptie in op SparkR- om de primaire taal te wijzigen.
Koppel uw notitieblok aan een lakehouse. Selecteer aan de linkerkant Voeg toe om een bestaand lakehouse toe te voegen of om een lakehouse te maken.
Pakketten installeren
Installeer het nycflights13-pakket om de code in deze zelfstudie te gebruiken.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
De gegevens verkennen
De nycflights13 gegevens bevatten informatie over 325.819 vluchten die in 2013 in de buurt van New York City zijn aangekomen. Bekijk eerst de distributie van vluchtvertragingen. Deze grafiek laat zien dat de verdeling van de aankomstvertragingen rechts-scheef is. Het heeft een lange staart in de hoge waarden.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
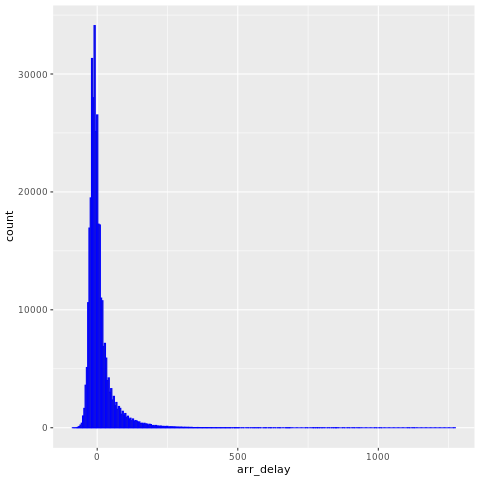
Laad de gegevens en breng enkele wijzigingen aan in de variabelen:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Voordat we het model bouwen, moet u rekening houden met enkele specifieke variabelen die belangrijk zijn voor zowel voorverwerking als modellering.
Variabele arr_delay is een factorvariabele. Voor de training van logistieke regressiemodellen is het belangrijk dat de resultaatvariabele een factorvariabele is.
glimpse(flight_data)
Ongeveer 16% van de vluchten in deze gegevensset kwamen meer dan 30 minuten te laat aan.
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
De dest-functie heeft 104 vluchtbestemmingen.
unique(flight_data$dest)
Er zijn 16 verschillende vervoerders.
unique(flight_data$carrier)
De gegevens splitsen
Verdeel de enkele gegevensset in twee sets: een trainingsgegevensset en een testset. Behoud de meeste rijen in de oorspronkelijke gegevensset (als een willekeurig gekozen subset) in de trainingsgegevensset. Gebruik de trainingsgegevensset om het model aan te passen en gebruik de testgegevensset om de modelprestaties te meten.
Gebruik het rsample-pakket om een object te maken dat informatie bevat over het splitsen van de gegevens. Gebruik vervolgens nog twee rsample functies om DataFrames te maken voor de trainings- en testsets:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Een recept en rollen maken
Maak een recept voor een eenvoudig logistiek regressiemodel. Voordat u het model traint, gebruikt u een recept om nieuwe voorspellers te maken en voert u de voorverwerking uit die het model nodig heeft.
Gebruik de functie update_role() zodat de recepten weten dat flight en time_hour variabelen zijn, met een aangepaste rol genaamd ID. Een rol kan een willekeurige tekenwaarde hebben. De formule bevat alle variabelen in de trainingsset, behalve arr_delay, als voorspellingsfactoren. Het recept bewaart deze twee id-variabelen, maar gebruikt ze niet als resultaten of voorspellers.
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Als u de huidige set variabelen en rollen wilt weergeven, gebruikt u de functie summary():
summary(flights_rec)
Functies maken
Voer een aantal functie-engineering uit om uw model te verbeteren. De vluchtdatum kan een redelijk effect hebben op de kans op late aankomst.
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Het kan helpen om modeltermen toe te voegen die zijn afgeleid van de datum die mogelijk van belang zijn voor het model. Leid de volgende zinvolle kenmerken af uit de enkele datumvariabele.
- Dag van de week
- Maand
- Of de datum al dan niet overeenkomt met een feestdag
Voeg de drie stappen toe aan uw recept:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Een model aanpassen met een recept
Gebruik logistieke regressie om de vluchtgegevens te modelleren. Bouw eerst een modelspecificatie met het parsnip-pakket:
lr_mod <-
logistic_reg() %>%
set_engine("glm")
Gebruik het workflows pakket om uw parsnip model (lr_mod) te bundelen met uw recept (flights_rec):
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Het model trainen
Met deze functie kunt u het recept voorbereiden en het model trainen op basis van de resulterende voorspellingsfactoren:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
Gebruik de helperfuncties xtract_fit_parsnip() en extract_recipe() om het model- of receptobject uit de werkstroom te extraheren. In dit voorbeeld haalt u het aangepaste modelobject op en gebruikt u vervolgens de functie broom::tidy() om een nette tibble van modelcoëfficiënten te verkrijgen.
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Resultaten voorspellen
Eén aanroep van predict() maakt gebruik van de getrainde werkstroom (flights_fit) om voorspellingen te doen met de onbekende testgegevens. De methode predict() past het recept toe op de nieuwe gegevens en geeft vervolgens de resultaten door aan het aangepaste model.
predict(flights_fit, test_data)
Haal de uitvoer van predict() op om de voorspelde klasse te retourneren: late versus on_time. Voor de voorspelde klassekansen voor elke vlucht gebruikt u echter augment() met het model, gecombineerd met testgegevens, om ze samen op te slaan:
flights_aug <-
augment(flights_fit, test_data)
Controleer de gegevens:
glimpse(flights_aug)
Het model evalueren
We hebben nu een tibble met de voorspelde klassekansen. In de eerste paar rijen heeft het model vijf on-time vluchten correct voorspeld (waarden van .pred_on_time zijn p > 0.50). We hebben echter 81.455 rijen totaal om te voorspellen.
We hebben een metrische waarde nodig die aangeeft hoe goed het model late aankomsten voorspelde, vergeleken met de werkelijke status van uw resultaatvariabele, arr_delay.
Gebruik het gebied onder de werkingskenmerken van de curveontvanger (AUC-ROC) als meetwaarde. Bereken het met roc_curve() en roc_auc(), vanuit het yardstick-pakket:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Een Power BI-rapport maken
Het modelresultaat ziet er goed uit. Gebruik de voorspellingsresultaten voor vluchtvertraging om een interactief Power BI-dashboard te bouwen. Het dashboard toont het aantal vluchten per vervoerder en het aantal vluchten per bestemming. Het dashboard kan filteren op de resultaten van de vertragingsvoorspelling.
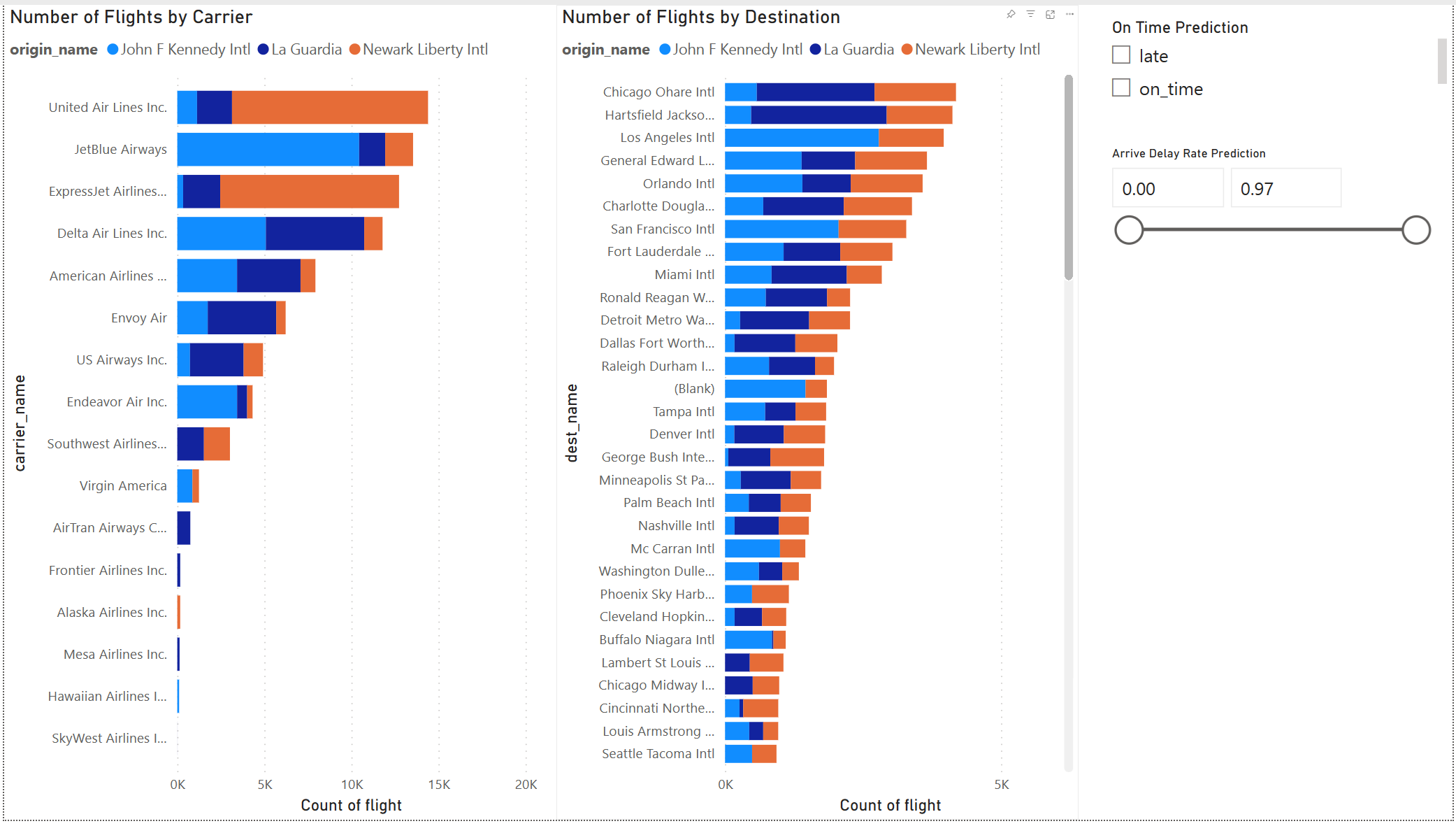
Neem de naam van de provider en de naam van de luchthaven op in de gegevensset met voorspellingsresultaten:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Controleer de gegevens:
glimpse(flights_clean)
Converteer de gegevens naar een Spark DataFrame:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Schrijf de gegevens in een deltatabel in uw lakehouse.
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
Gebruik de deltatabel om een semantisch model te maken.
Selecteer aan de linkerkant OneLake
Selecteer het lakehouse dat u aan uw notitieblok hebt gekoppeld
Selecteer openen
Selecteer nieuw semantisch model
Selecteer nycflight13- voor uw nieuwe semantische model en selecteer vervolgens Bevestigen
Uw semantische model wordt gemaakt. Selecteer nieuw rapport
Selecteer of sleep de velden van de Gegevens en Visualisaties deelvensters naar het rapportcanvas om uw rapport te maken.

Als u het rapport wilt maken dat aan het begin van deze sectie wordt weergegeven, gebruikt u deze visualisaties en gegevens:
-
 gestapeld staafdiagram met:
gestapeld staafdiagram met: - Y-as: carrier_name
- X-as: vlucht. Selecteer Count voor de aggregatie
- Legenda: origin_name
-
gestapeld staafdiagram met:
- Y-as: dest_name
- X-as: vlucht. Selecteer Count voor de aggregatie
- Legenda: origin_name
-
 Slicer met:
Slicer met: - Veld: _pred_class
-
slicer met:
- Veld: _pred_late