Uw migratie plannen vanuit Azure Data Factory
Microsoft Fabric is het SaaS-product voor gegevensanalyse van Microsoft dat alle toonaangevende analyseproducten van Microsoft samenbrengt in één gebruikerservaring. Fabric Data Factory biedt werkstroomindeling, gegevensverplaatsing, gegevensreplicatie en gegevenstransformatie op schaal met vergelijkbare mogelijkheden die zijn gevonden in Azure Data Factory (ADF). Als u bestaande ADF-investeringen hebt die u wilt moderniseren naar Fabric Data Factory, is dit document handig om inzicht te krijgen in migratieoverwegingen, strategieën en benaderingen.
Migreren vanuit de Azure PaaS ETL/DI-services ADF & Synapse-pijplijnen en -gegevensstromen kan verschillende belangrijke voordelen bieden:
- Nieuwe geïntegreerde pijplijnfuncties, waaronder e-mail- en Teams-activiteiten, maken eenvoudige routering van berichten mogelijk tijdens de uitvoering van de pijplijn.
- Ingebouwde FUNCTIES voor continue integratie en levering (CI/CD) (implementatiepijplijnen) vereisen geen externe integratie met Git-opslagplaatsen.
- Integratie van werkruimten met uw OneLake-datalake maakt eenvoudig en overzichtelijk analysebeheer vanuit één geïntegreerde interface mogelijk.
- Het vernieuwen van uw semantische gegevensmodellen is eenvoudig in Fabric met een volledig geïntegreerde pijplijnactiviteit.
Microsoft Fabric is een geïntegreerd platform voor zowel selfservice- als it-beheerde bedrijfsgegevens. Met exponentiële groei in gegevensvolumes en complexiteit eisen Fabric-klanten bedrijfsoplossingen die schalen, veilig, gemakkelijk te beheren en toegankelijk zijn voor alle gebruikers in de grootste organisaties.
In de afgelopen jaren investeerde Microsoft aanzienlijk in het leveren van schaalbare cloudmogelijkheden aan Premium. Daartoe biedt Data Factory in Fabric direct een groot ecosysteem van ontwikkelaars van gegevensintegratie en oplossingen voor gegevensintegratie die in meer dan tientallen jaren zijn opgebouwd om de volledige set functies en mogelijkheden toe te passen die veel verder gaan dan vergelijkbare functionaliteit die beschikbaar is in vorige generaties.
Natuurlijk vragen klanten of er een mogelijkheid is om te consolideren door hun oplossingen voor gegevensintegratie in Fabric te hosten. Veelvoorkomende vragen zijn:
- Werkt alle functionaliteit waar we van afhankelijk zijn in Fabric-pijplijnen?
- Welke mogelijkheden zijn alleen beschikbaar in Fabric-pijplijnen?
- Hoe migreren we bestaande pijplijnen naar Fabric-pijplijnen?
- Wat is de roadmap van Microsoft voor het opnemen van zakelijke gegevens?
Platformverschillen
Wanneer u een volledig ADF-exemplaar migreert, zijn er veel belangrijke verschillen om rekening mee te houden tussen ADF en Data Factory in Fabric, wat belangrijk wordt wanneer u migreert naar Fabric. We verkennen een aantal van deze belangrijke verschillen in deze sectie.
Raadpleeg Vergelijk Data Factory in Fabric en Azure Data Factoryvoor een beter begrip van de functionele verschillen tussen Azure Data Factory en Fabric Data Factory.
Integratietijdomgevingen
In ADF zijn integratieruntimes (IR's) configuratieobjecten die rekenkracht vertegenwoordigen die door ADF worden gebruikt om uw gegevensverwerking te voltooien. Deze configuratie-eigenschappen omvatten de Azure-regio voor cloud compute en gegevensstroom-Spark-rekengroottes. Andere IR-typen zijn zelf-hostende IR's (SHIR's) voor on-premises gegevensconnectiviteit, SSIS IRs voor het uitvoeren van SQL Server Integration Services-pakketten en cloud-IR's met Vnet-functionaliteit.
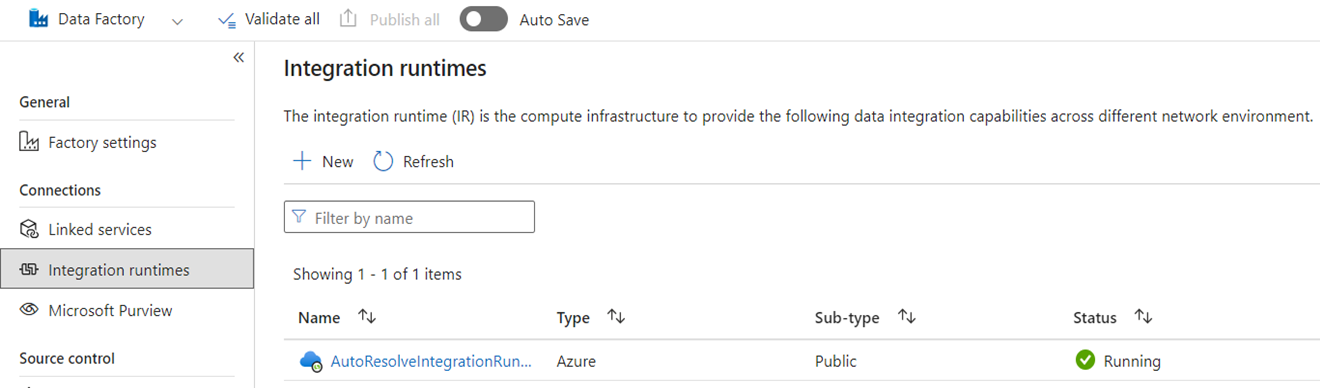
Microsoft Fabric is een SaaS-product (Software as a Service), terwijl ADF een PaaS-product (Platform as a Service) is. Wat dit onderscheid in termen van runtimes voor integraties betekent, is dat je niets hoeft te configureren om pijplijnen of gegevensstromen in Fabric te gebruiken. De standaardinstelling is namelijk om cloudgebaseerde berekeningen te gebruiken in de regio waar je Fabric-capaciteiten zich bevinden. SSIS IRs bestaan niet in Fabric en voor on-premises gegevensconnectiviteit gebruikt u een infrastructuurspecifiek onderdeel dat bekend staat als de on-premises Data Gateway (OPDG). En voor connectiviteit op basis van een virtueel netwerk met beveiligde netwerken gebruikt u de Virtual Network Data Gateway in Fabric.
Wanneer u migreert van ADF naar Fabric, hoeft u geen publieke netwerk Azure (cloud) IRs te migreren. U moet uw SHIR's opnieuw maken als OPDG's en Azure IR's die virtuele netwerken hebben ingeschakeld als Virtual Network Data Gateways.
Pijpleidingen
Pijplijnen zijn het fundamentele onderdeel van ADF, dat wordt gebruikt voor de primaire werkstroom en indeling van uw ADF-processen voor gegevensverplaatsing, gegevenstransformatie en procesindeling. Pijplijnen in Fabric Data Factory zijn bijna identiek aan ADF, maar met extra onderdelen die passen bij het SaaS-model op basis van Power BI. Deze overeenkomst omvat systeemeigen activiteiten voor e-mails, Teams en het vernieuwen van het semantisch model.
De JSON-definitie van pijplijnen in Fabric Data Factory verschilt enigszins van ADF vanwege verschillen in het toepassingsmodel tussen de twee producten. Vanwege dit verschil is het niet mogelijk om pijplijn-JSON te kopiëren/plakken, pijplijnen te importeren/exporteren of naar een ADF Git-opslagplaats te verwijzen.
Wanneer u uw ADF-pijplijnen herbouwt als Fabric-pijplijnen, gebruikt u praktisch dezelfde werkstroommodellen en vaardigheden die u in ADF heeft gebruikt. De belangrijkste overweging heeft te maken met gekoppelde services en gegevenssets die concepten zijn in ADF die niet bestaan in Fabric.
Gekoppelde services
In ADF definiëren gekoppelde services de connectiviteitseigenschappen die nodig zijn om verbinding te maken met uw gegevensarchieven voor gegevensverplaatsing, gegevenstransformatie en gegevensverwerkingsactiviteiten. In Fabric moet u deze definities opnieuw maken als verbindingen die eigenschappen zijn voor uw activiteiten, zoals Kopiëren en Gegevensstromen.
Datasets
Gegevenssets definiëren de vorm, locatie en inhoud van uw gegevens in ADF, maar bestaan niet als entiteiten in Fabric. Als u gegevenseigenschappen wilt definiëren, zoals gegevenstypen, kolommen, mappen, tabellen, enzovoort in Fabric Data Factory-pijplijnen, definieert u deze kenmerken inline binnen pijplijnactiviteiten en binnen het verbindingsobject waarnaar eerder in de sectie Gekoppelde service wordt verwezen.
Gegevensstromen
In Data Factory for Fabric verwijst de term gegevensstromen verwijst naar de activiteiten voor gegevenstransformatie zonder code, terwijl in ADF dezelfde functie wordt aangeduid als gegevensstromen. Fabric Data Factory-gegevensstromen hebben een gebruikersinterface die is gebouwd op Power Query, die wordt gebruikt in de ADF Power Query-activiteit. De berekening die wordt gebruikt voor het uitvoeren van gegevensstromen in Fabric is een systeemeigen uitvoeringsengine die kan worden uitgebreid voor grootschalige gegevenstransformatie met behulp van de nieuwe datawarehouse-rekenengine voor fabric.
In ADF worden gegevensstromen gebouwd op de Synapse Spark-infrastructuur, en ze worden gedefinieerd met behulp van een gebruikersinterface voor constructie die een onderliggende domeinspecifieke taal (DSL) gebruikt, bekend als gegevensstroomscript. Deze definitietaal verschilt aanzienlijk van de op Power Query gebaseerde gegevensstromen in Fabric die een definitietaal gebruiken die bekend staat als M om hun gedrag te definiëren. Vanwege deze verschillen in gebruikersinterfaces, talen en uitvoerprogramma's zijn Fabric gegevensstromen en ADF gegevensstromen niet compatibel en moet u uw ADF--gegevensstromen opnieuw maken als Fabric--gegevensstromen bij het upgraden van uw oplossingen naar Fabric.
Triggers
Triggers signaleren ADF om een pijplijn uit te voeren op basis van een wandklokschema, tumblingvenstertijdsegmenten, bestandsgebeurtenissen of aangepaste gebeurtenissen. Deze functies zijn vergelijkbaar in Fabric, hoewel de onderliggende implementatie anders is.
In Fabric bestaan triggers alleen als een concept in de pijplijn. Het grotere framework dat pijplijntriggers in Fabric gebruiken, wordt Data Activatorgenoemd. Dit is een gebeurtenis- en waarschuwingssubsysteem van de realtime intelligence-functies in Fabric.
Fabric Data Activator heeft waarschuwingen die kunnen worden gebruikt voor het maken van bestandsgebeurtenissen en aangepaste gebeurtenistriggers. Schema-triggers zijn een afzonderlijke entiteit in Fabric die bekend staan als -schema's. Deze schema's bevinden zich op platformniveau in Fabric en zijn niet specifiek voor pijplijnen. Ze worden ook niet triggers genoemd in Fabric.
Als u uw triggers van ADF naar Fabric wilt migreren, overweeg dan om uw planningstriggers opnieuw te bouwen als schema's die eigenschappen zijn van uw Fabric-pijplijnen. En voor alle andere triggertypen gebruikt u de knop Triggers in de Fabric-pijplijn of gebruikt u Data Activator rechtstreeks in Fabric.
Foutopsporing
Foutopsporing van pijplijnen is eenvoudiger in Fabric dan in ADF. Deze eenvoud is omdat Fabric Data Factory-pijplijnen geen afzonderlijk concept van foutopsporingsmodus hebben die u in ADF-pijplijnen en gegevensstromen vindt. Wanneer u uw pijplijn bouwt, bevindt u zich altijd in de interactieve modus. Als u uw pijplijnen wilt testen en fouten wilt opsporen, hoeft u alleen de afspeelknop te selecteren op de werkbalk van de pijplijneditor wanneer u klaar bent in uw ontwikkelingscyclus. Pijplijnen in Fabric bevatten de foutopsporing niet totdat er een stapsgewijs debugpatroon interactief wordt uitgevoerd. In plaats daarvan gebruikt u in Fabric de activiteitsstatus en stelt u alleen de activiteiten in die u als actief wilt testen terwijl u alle andere activiteiten instelt op inactief om dezelfde test- en foutopsporingspatronen te bereiken. Raadpleeg de volgende video waarin wordt uitgelegd hoe u deze foutopsporingservaring in Fabric kunt uitvoeren.
Wijzigingen in gegevens vastleggen
Change Data Capture (CDC) in ADF is een preview-functie waarmee u gegevens eenvoudig op een incrementele manier kunt verplaatsen door CDC-functies aan de bronzijde van uw gegevensarchieven toe te passen. Als u uw CDC-artefacten naar Fabric Data Factory wilt migreren, recreëert u deze artefacten als Kopieeropdracht-items in uw Fabric-werkruimte. Deze functie biedt vergelijkbare mogelijkheden voor incrementele gegevensverplaatsing met een gebruiksvriendelijke gebruikersinterface zonder dat hiervoor een pijplijn is vereist, net als in ADF CDC. Zie voor meer informatie de kopieeropdracht voor Data Factory in Fabric.
Azure Synapse Link
Hoewel ze niet beschikbaar zijn in ADF, maken synapse-pijplijngebruikers vaak gebruik van Azure Synapse Link om gegevens van SQL-databases te repliceren naar hun data lake in kant-en-klare benadering. In Fabric maakt u de Azure Synapse Link-artefacten opnieuw als spiegelingsitems in uw werkruimte. Zie voor meer informatie over Fabric databasespiegeling.
SQL Server Integration Services (SSIS)
SSIS is het on-premises hulpprogramma voor gegevensintegratie en ETL dat Microsoft met SQL Server verzendt. In ADF kunt u uw SSIS-pakketten lift-and-shiften naar de cloud met behulp van de ADF SSIS IR. In Fabric hebben we niet het concept van IR's, dus deze functionaliteit is momenteel niet mogelijk. We werken echter aan het inschakelen van de uitvoering van SSIS-pakketten vanuit Fabric, die we binnenkort naar het product willen brengen. Ondertussen kunt u SSIS-pakketten het beste uitvoeren in de cloud met Fabric Data Factory door een SSIS IR in uw ADF-factory te starten en vervolgens een ADF-pijplijn aan te roepen om uw SSIS-pakketten aan te roepen. U kunt een ADF-pijplijn op afstand aanroepen vanuit uw Fabric-pijplijnen met behulp van de aangeroepen pijplijnactiviteit die in de volgende sectie wordt beschreven.
Pijplijnactiviteit aanroepen
Een veelvoorkomende activiteit die wordt gebruikt in ADF-pijplijnen, is de Pijplijnactiviteit uitvoeren waarmee u een andere pijplijn in uw factory kunt aanroepen. In Fabric hebben we deze activiteit verbeterd als de activiteit voor het aanroepen van de pijplijn. Raadpleeg de documentatie Pijplijnactiviteit aanroepen.
Deze activiteit is handig voor migratiescenario's waarbij u veel ADF-pijplijnen hebt die gebruikmaken van ADF-specifieke functies, zoals Mapping Data Flows of SSIS. U kunt deze pijplijnen onderhouden as-is in ADF- of zelfs Synapse-pijplijnen en die pijplijn vervolgens inline aanroepen vanuit uw nieuwe Infrastructuurgegevensfactory-pijplijn met behulp van de activiteit Pijplijn aanroepen en verwijzen naar de externe factory-pijplijn.
Voorbeeldmigratiescenario's
De volgende scenario's zijn veelvoorkomende migratiescenario's die u kunt tegenkomen bij het migreren van ADF naar Fabric Data Factory.
Scenario 1: ADF-pijplijnen en gegevensstromen
De primaire gebruikssituaties voor de migraties van fabrieken zijn gebaseerd op het moderniseren van uw ETL-omgeving van het ADF-fabriek PaaS-model naar het nieuwe Fabric SaaS-model. De primaire factory-items die moeten worden gemigreerd, zijn pijplijnen en gegevensstromen. Er zijn verschillende fundamentele factory-elementen die u moet plannen voor migratie buiten deze twee items op het hoogste niveau: gekoppelde services, integratieruntimes, gegevenssets en triggers.
- Gekoppelde services moeten in Fabric opnieuw worden aangemaakt als verbindingen in de activiteiten van uw pijplijn.
- Datasets bestaan niet in de Factory. De eigenschappen van uw gegevenssets worden weergegeven als eigenschappen binnen pijplijnactiviteiten zoals Kopiëren of Opzoeken, terwijl verbindingen andere gegevensseteigenschappen bevatten.
- Integratieruntimes bestaan niet in Fabric. Uw zelfgehoste IR's kunnen echter opnieuw worden gemaakt met behulp van on-premises gegevensgateways (OPDG's) in Fabric en Azure virtuele netwerk-IR's als beheerde virtuele netwerkgateways in Fabric.
- Deze ADF-pijplijnactiviteiten zijn niet opgenomen in Fabric Data Factory:
- Data Lake Analytics (U-SQL): deze functie is een afgeschafte Azure-service.
- Validatieactiviteit: de validatieactiviteit in ADF is een helperactiviteit die u eenvoudig kunt herbouwen in uw Fabric-pijplijnen met behulp van een activiteit Metagegevens ophalen, een pijplijnlus en een If-activiteit.
- Power Query - In Fabric worden alle gegevensstromen gebouwd met behulp van de Power Query-gebruikersinterface, zodat u uw M-code kunt kopiëren en plakken vanuit uw ADF Power Query-activiteiten en deze kunt bouwen als gegevensstromen in Fabric.
- Als u een van de ADF-pijplijnmogelijkheden gebruikt die niet zijn gevonden in Fabric Data Factory, gebruikt u de activiteit Pijplijn aanroepen in Fabric om uw bestaande pijplijnen in ADF aan te roepen.
- De volgende ADF-pijplijnactiviteiten worden gecombineerd tot een activiteit met één doel:
- Azure Databricks-activiteiten (Notebook, Jar, Python)
- Azure HDInsight (Hive, Pig, MapReduce, Spark, Streaming)
In de volgende afbeelding ziet u de configuratiepagina van de ADF-gegevensset, met de bestandspad- en compressie-instellingen:
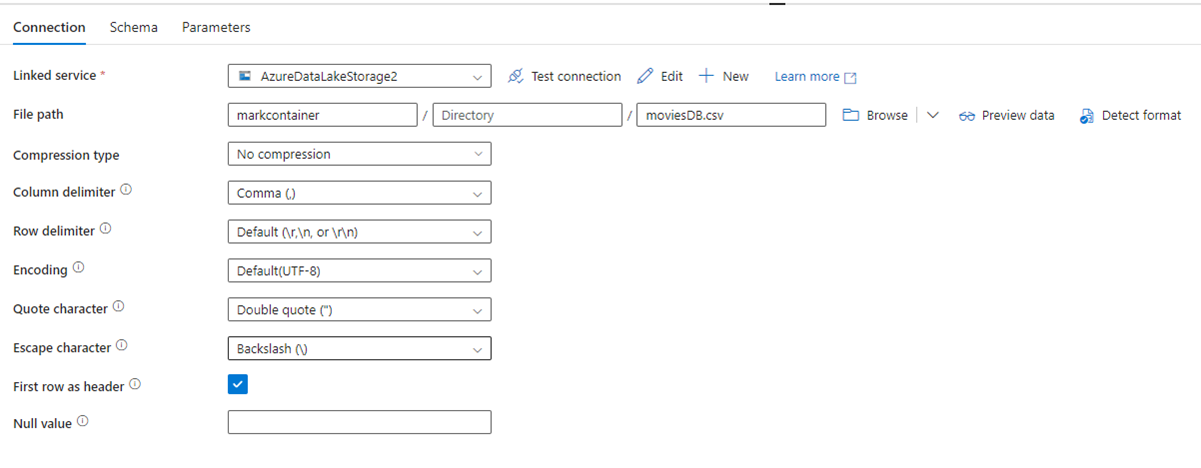
In de volgende afbeelding ziet u de configuratie van de kopieeractiviteit voor Data Factory in Fabric, waarbij compressie en bestandspad inline zijn in de activiteit:
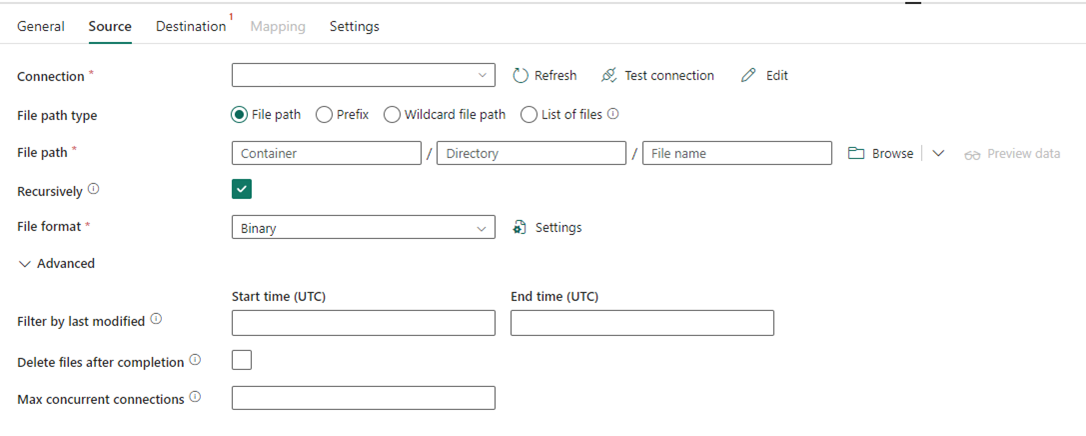
Scenario 2: ADF met CDC, SSIS en Airflow
CDC & Airflow in ADF zijn preview-functies, terwijl SSIS in ADF een algemeen beschikbare functie is voor vele jaren. Elk van deze functies heeft verschillende behoeften voor gegevensintegratie, maar vereist speciale aandacht bij het migreren van ADF naar Fabric. Change Data Capture (CDC) is een ADF-concept op het hoogste niveau, maar in Fabric ziet u deze mogelijkheid als de kopieertaak.
Airflow is de door de cloud beheerde Apache Airflow-functie van ADF en is ook beschikbaar in Fabric Data Factory. Je zou hetzelfde Airflow-repo moeten kunnen gebruiken of je DAG's nemen en de code kopiëren en plakken in de Fabric Airflow-dienst, waarbij weinig tot geen wijzigingen nodig zijn.
Scenario 3: Migratie van Data Factory met Git naar Fabric
Hoewel het niet verplicht is, is het gebruikelijk dat uw ADF- of Synapse-factory's en werkruimten zijn verbonden met uw eigen externe Git-provider in ADO of GitHub. In dit scenario moet u uw factory- en werkruimte-items migreren naar een Fabric-werkruimte en vervolgens Git-integratie instellen in uw Fabric-werkruimte.
Fabric biedt twee primaire manieren om CI/CD in te schakelen, zowel op werkruimteniveau: Git-integratie, waarbij u uw eigen Git-opslagplaats in ADO gebruikt en er verbinding mee maakt vanuit Fabric en ingebouwde implementatiepijplijnen, waar u code naar hogere omgevingen kunt promoveren zonder dat u uw eigen Git hoeft mee te nemen.
In beide gevallen werkt uw bestaande Git-opslagplaats van ADF niet met Fabric. In plaats daarvan moet u verwijzen naar een nieuwe opslagplaats of een nieuwe implementatiepijplijn starten in Fabric en uw pijplijnartefacten opnieuw bouwen in Fabric.
Uw bestaande ADF-exemplaren rechtstreeks koppelen aan een Fabric-werkruimte
Eerder hebben we gesproken over het gebruik van de Fabric Data Factory-activiteit "Pijplijn Aanroepen" als een mechanisme om bestaande ADF-pijplijninvesteringen te onderhouden en ze direct aan te roepen vanuit Fabric. Binnen Fabric kunt u dat vergelijkbare concept nog een stap verder doen en de hele fabriek in uw Fabric-werkruimte koppelen als een systeemeigen Fabric-item.
Voor meer informatie over toenemende gebruiksscenario's, zie Samenwerkings- en leveringsscenario's voor inhoud.
Het koppelen van uw Azure Data Factory in uw Fabric-werkruimte biedt veel voordelen. Als u niet eerder met Fabric werkt en uw fabrieken naast elkaar wilt houden binnen hetzelfde deelvenster, kunt u deze koppelen aan Fabric, zodat u beide binnen Fabric kunt beheren. De volledige ADF-gebruikersinterface is nu beschikbaar vanuit uw gekoppelde factory, waar u uw ADF-factory-items volledig vanuit de werkruimte Fabric kunt bewaken, beheren en bewerken. Deze functie maakt het veel eenvoudiger om deze items te migreren naar Fabric als systeemeigen Fabric-artefacten. Deze functie is voornamelijk bedoeld voor gebruiksgemak en maakt het gemakkelijk om uw ADF-factory's in uw Fabric-werkruimte te zien. De werkelijke uitvoering van de pijplijnen, activiteiten, integratieruntimes, enzovoort, vindt echter nog steeds plaats in uw Azure-resources.
Verwante inhoud
Overwegingen voor migratie van ADF naar Data Factory in Fabric