Hoe Azure SQL Managed Instance configureren in Kopieeractiviteit
In dit artikel wordt beschreven hoe u de kopieeractiviteit in de gegevenspijplijn gebruikt om gegevens van en naar Azure SQL Managed Instance te kopiëren.
Ondersteunde configuratie
Voor de configuratie van elk tabblad onder kopieeractiviteit gaat u respectievelijk naar de volgende secties.
Algemeen
Raadpleeg de Algemene-instellingen richtlijnen voor het configureren van het tabblad Algemeen instellingen.
Bron
De volgende eigenschappen worden ondersteund voor Azure SQL Managed Instance op het tabblad Bron van een kopieeractiviteit.
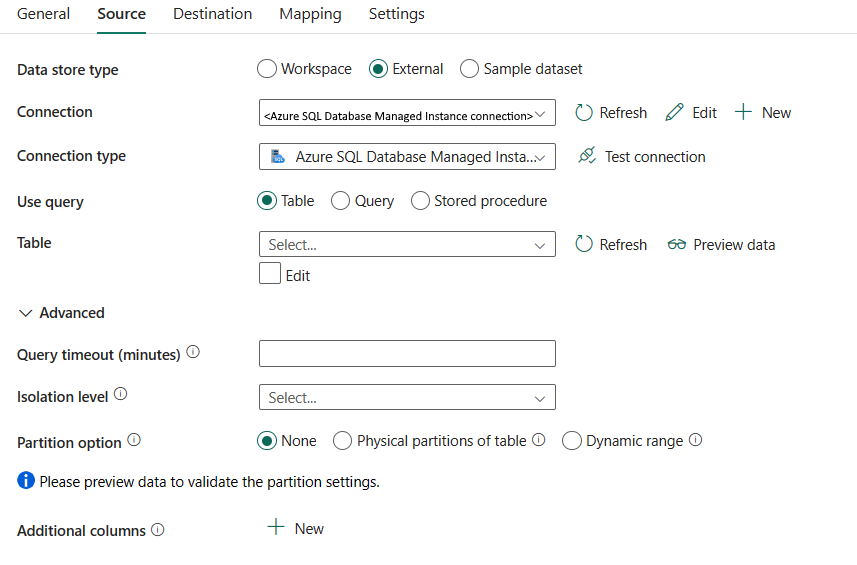
De volgende eigenschappen zijn vereist:
gegevensarchieftype: selecteer Externe.
Connection: Selecteer een Azure SQL Managed Instance-verbinding in de lijst met verbindingen. Als de verbinding niet bestaat, maakt u een nieuwe Azure SQL Managed Instance-verbinding door Nieuwete selecteren.
verbindingstype: selecteer Azure SQL Managed Instance.
Querygebruiken: geef de manier op waarop u gegevens wilt lezen. U kunt tabel, queryof opgeslagen procedurekiezen. In de volgende lijst wordt de configuratie van elke instelling beschreven:
Tabel: Gegevens uit de opgegeven tabel lezen. Selecteer de brontabel in de vervolgkeuzelijst of selecteer Bewerken om deze handmatig in te voeren.
Query: geef de aangepaste SQL-query op om gegevens te lezen. Een voorbeeld is
select * from MyTable. Of selecteer het potloodpictogram dat u wilt bewerken in de code-editor.
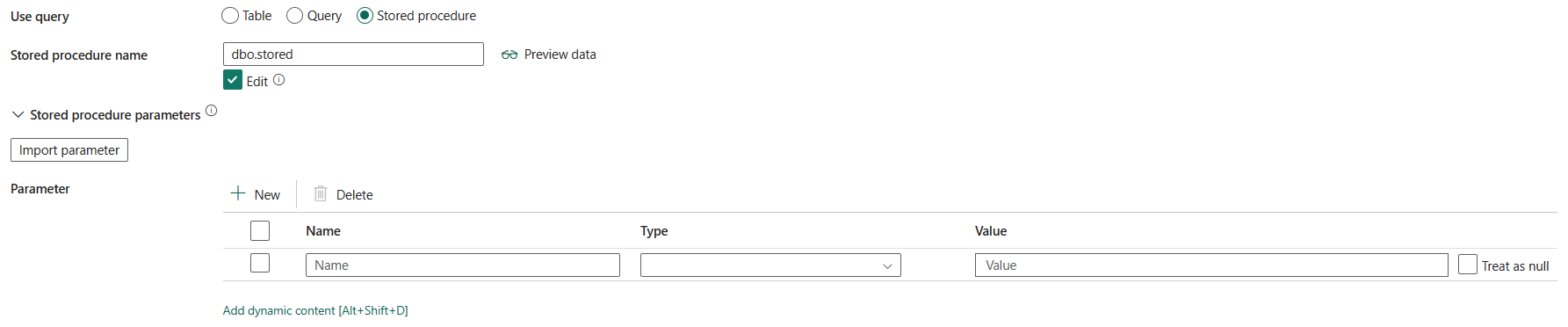
opgeslagen procedure: gebruik de opgeslagen procedure waarmee gegevens uit de brontabel worden gelezen. De laatste SQL-instructie moet een SELECT-instructie zijn in de opgeslagen procedure.
naam van opgeslagen procedure: selecteer de opgeslagen procedure of geef de naam van de opgeslagen procedure handmatig op wanneer u de Bewerken selecteert om gegevens uit de brontabel te lezen.
opgeslagen procedureparameters: Specificeer waarden voor opgeslagen procedureparameters. Toegestane waarden zijn naam- of waardeparen. De namen en het hoofdlettergebruik van parameters moeten overeenkomen met de namen en het hoofdlettergebruik van de parameters van de opgeslagen procedure. U kunt importparameters selecteren om de opgeslagen procedureparameters op te halen.
Onder Geavanceerdekunt u de volgende velden opgeven:
time-out voor query's (minuten): geef de time-out op voor het uitvoeren van de queryopdracht. De standaardwaarde is 120 minuten. Als een parameter voor deze eigenschap is ingesteld, zijn toegestane waarden tijdspanne, zoals '02:00:00' (120 minuten).
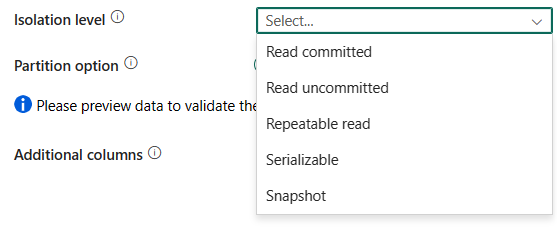
isolatieniveau: hiermee geeft u het gedrag voor transactievergrendeling voor de SQL-bron op. De toegestane waarden zijn: gecommitteerde lezing, niet-gecommitteerde lezing, herhaalbare lezing, seriële lezing, momentopname. Als dit niet is opgegeven, wordt het standaardisolatieniveau van de database gebruikt. Raadpleeg IsolationLevel Enum voor meer informatie.
partitieoptie: geef de opties voor gegevenspartitionering op die worden gebruikt om gegevens uit Azure SQL Managed Instance te laden. Toegestane waarden zijn: Geen (standaard), Fysieke partities van tabelen dynamisch bereik. Wanneer een partitieoptie is ingeschakeld (dus niet Geen), wordt de graad van parallelisme om gegevens tegelijkertijd van Azure SQL Managed Instance te kopiëren, beheerst door Graad van kopieparallelisme in het instellingen-tabblad voor kopieeractiviteit.
Geen: kies deze instelling om geen partitie te gebruiken.
fysieke partities van tabel: wanneer u een fysieke partitie gebruikt, worden de partitiekolom en het mechanisme automatisch bepaald op basis van de definitie van uw fysieke tabel.
dynamisch bereik: wanneer u query's gebruikt waarvoor parallel is ingeschakeld, is de bereikpartitieparameter (
?DfDynamicRangePartitionCondition) nodig. Voorbeeldquery:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.kolomnaam partitie: geef de naam op van de bronkolom in geheel getal of datum/datum/tijd type (
int,smallint,bigint,date,smalldatetime,datetime,datetime2ofdatetimeoffset) die wordt gebruikt door bereikpartitionering voor parallelle kopie. Als deze niet is opgegeven, wordt de index of de primaire sleutel van de tabel automatisch gedetecteerd en gebruikt als partitiekolom.Als u een query gebruikt om de brongegevens op te halen, koppelt u
?DfDynamicRangePartitionConditionin de WHERE-component. Zie de sectie Parallel kopiëren van Azure SQL Managed Instance voor een voorbeeld.Partitie bovengrens: Geef de maximumwaarde van de partitiekolom op voor het splitsen van partitiebereiken. Deze waarde wordt gebruikt om de partition stapgrootte te bepalen, niet voor het filteren van de rijen in de tabel. Alle rijen in de tabel of het queryresultaat worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarde. Zie de sectie Parallel kopiëren van Azure SQL Managed Instance voor een voorbeeld.
Partitie ondergrens: geef de minimumwaarde van de partitiekolom op voor het splitsen van partitiebereiken. Deze waarde wordt gebruikt om de partitie-stride te bepalen, niet voor het filteren van de rijen in de tabel. Alle rijen in de tabel of het queryresultaat worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarde. Zie de sectie Parallel kopiëren van Azure SQL Managed Instance voor een voorbeeld.
Aanvullende kolommen: voeg extra gegevenskolommen toe om het relatieve pad of de statische waarde van de bronbestanden op te slaan. Expressie wordt ondersteund voor de laatste.
Let op de volgende punten:
- Als Query is opgegeven voor de bron, voert de kopieeractiviteit deze query uit op de azure SQL Managed Instance-bron om de gegevens op te halen. U kunt ook een opgeslagen procedure opgeven door opgeslagen procedurenaam en opgeslagen procedureparameters op te geven als de opgeslagen procedure parameters gebruikt.
- Wanneer u opgeslagen procedures in de bron gebruikt om gegevens op te halen, moet u er rekening mee houden dat uw opgeslagen procedure is ontworpen voor het retourneren van een ander schema wanneer er een andere parameterwaarde wordt doorgegeven. U kunt mogelijk een fout tegenkomen of een onverwacht resultaat zien bij het importeren van het schema uit de gebruikersinterface of bij het kopiëren van gegevens naar de SQL-database met automatische tabelaanmaak.
Bestemming
De volgende eigenschappen worden ondersteund voor Azure SQL Managed Instance op het tabblad Bestemming van een kopieeractiviteit.
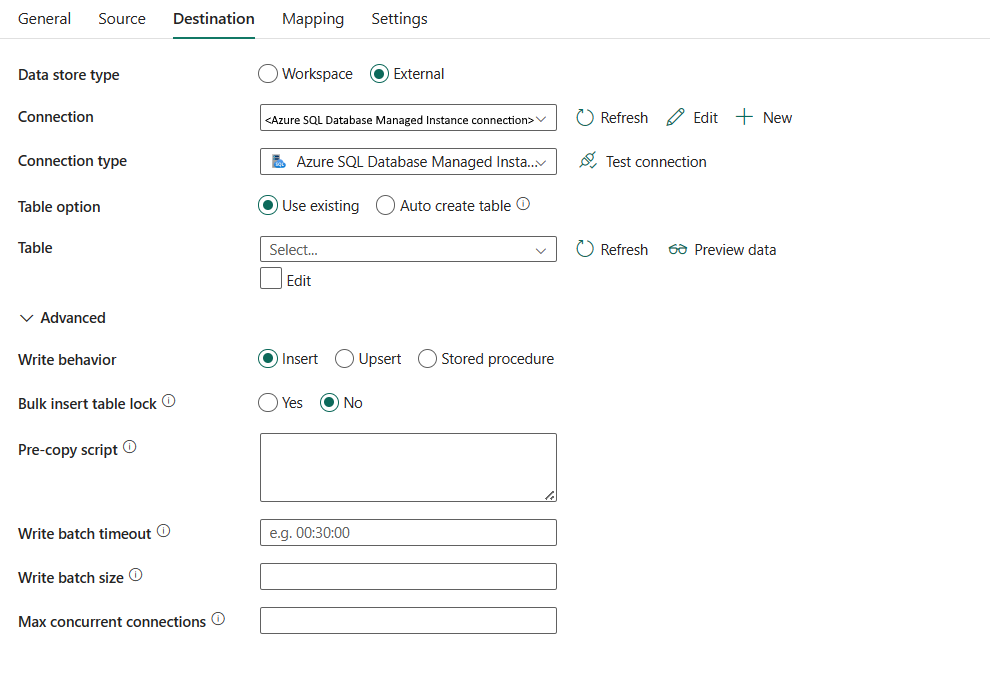
De volgende eigenschappen zijn vereist:
gegevensarchieftype: selecteer Externe.
Connection: Selecteer een Azure SQL Managed Instance-verbinding in de lijst met verbindingen. Als de verbinding niet bestaat, maakt u een nieuwe Azure SQL Managed Instance-verbinding door Nieuwete selecteren.
verbindingstype: selecteer Azure SQL Managed Instance.
tabeloptie: u kunt kiezen Bestaande gebruiken om de opgegeven tabel te gebruiken. Of kies tabel automatisch maken om automatisch een doeltabel te maken als de tabel niet in het bronschema bestaat en houd er rekening mee dat deze selectie niet wordt ondersteund wanneer opgeslagen procedure wordt gebruikt als schrijfgedrag.
Als u Bestaandegebruiken selecteert:
- Tabel: Selecteer de tabel in de doeldatabase in de vervolgkeuzelijst. Of controleer Bewerken om de tabelnaam handmatig in te voeren.
Als u selecteert: automatisch een tabel maken:
- Tabel: geef de naam op voor de automatisch gemaakte doeltabel.
Onder Geavanceerdekunt u de volgende velden opgeven:
schrijfgedrag: definieert het schrijfgedrag wanneer de bron bestanden zijn uit een op bestanden gebaseerd gegevensarchief. U kunt kiezen Invoegen, **Upsert, of opgeslagen procedure.
Invoegen: Kies deze optie om het invoegschrijfgedrag te gebruiken voor het laden van gegevens in Azure SQL Managed Instance.
Upsert-: kies deze optie om het schrijfgedrag van upsert te gebruiken om gegevens in Azure SQL Managed Instance te laden.
TempDB-gebruiken: geef aan of u een globale tijdelijke tabel of fysieke tabel wilt gebruiken als tussentijdse tabel voor upsert. De service maakt standaard gebruik van een globale tijdelijke tabel als de tussentijdse tabel en deze eigenschap is geselecteerd.
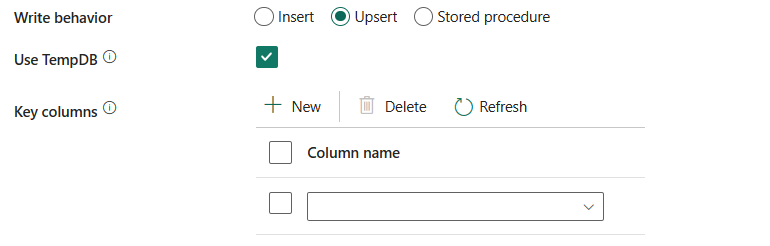
Database-schema van gebruiker selecteren: wanneer de TempDB- niet is geselecteerd, geeft u het tussentijdse schema op voor het maken van een tussentijdse tabel als er een fysieke tabel wordt gebruikt.
Notitie
U moet over de machtiging beschikken voor het maken en verwijderen van tabellen. Een tussentijdse tabel deelt standaard hetzelfde schema als een doeltabel.
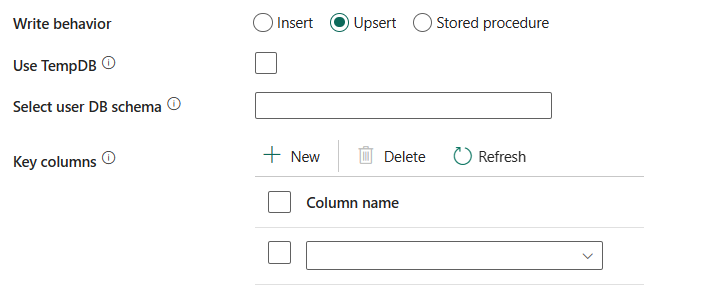
sleutelkolommen: geef de kolomnamen op voor unieke rijidentificatie. U kunt één sleutel of een reeks sleutels gebruiken. Als deze niet is opgegeven, wordt de primaire sleutel gebruikt.
opgeslagen procedure: gebruik de opgeslagen procedure waarmee wordt gedefinieerd hoe brongegevens in een doeltabel moeten worden toegepast. Deze opgeslagen procedure wordt aangeroepen per batch. Gebruik de eigenschap Pre-copy-script voor bewerkingen die slechts eenmaal worden uitgevoerd en niets te maken hebben met brongegevens, bijvoorbeeld verwijderen of trunceren.
Naam van de opgeslagen procedure: selecteer de opgeslagen procedure of geef deze handmatig op bij het controleren van de Bewerken om gegevens uit de brontabel te lezen.
parameters voor opgeslagen procedures:
- tabeltype: geef de naam van het tabeltype op dat moet worden gebruikt in de opgeslagen procedure. De kopieeractiviteit maakt de gegevens beschikbaar in een tijdelijke tabel met dit tabeltype. Opgeslagen procedurecode kan vervolgens de gegevens samenvoegen die worden gekopieerd met bestaande gegevens.
- parameternaam tabeltype: geef de parameternaam op van het tabeltype dat is opgegeven in de opgeslagen procedure.
- Parameters: Geef waarden op voor opgeslagen procedureparameters. Toegestane waarden zijn naam- of waardeparen. De namen en het lettergebruik van parameters moeten overeenkomen met de namen en het lettergebruik van de parameters van de opgeslagen procedure. U kunt importparameters selecteren om de opgeslagen procedureparameters op te halen.
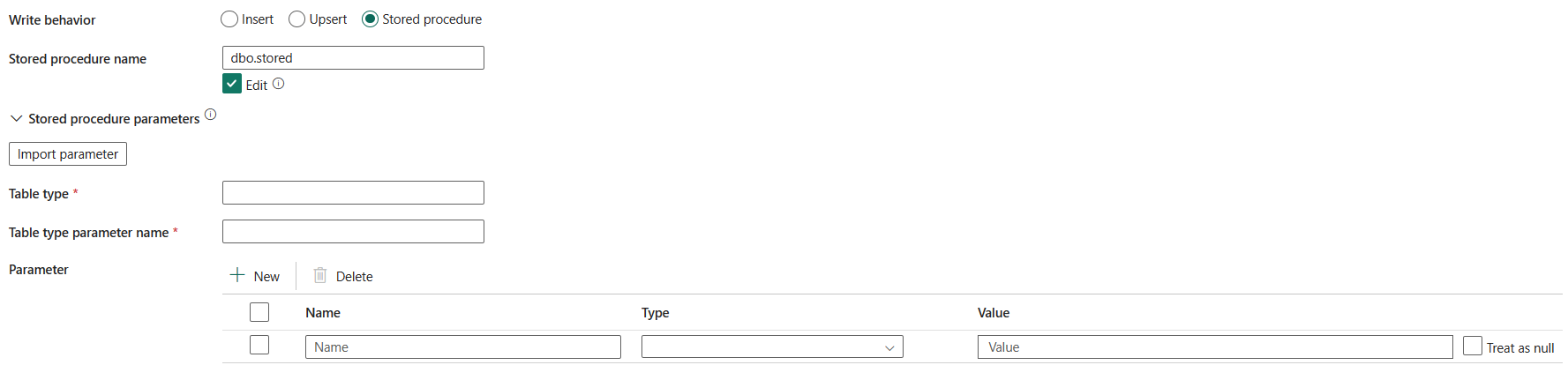
tabelvergrendeling bulksgewijs invoegen: kies Ja of Geen (standaard). Gebruik deze instelling om de kopieerprestaties te verbeteren tijdens een bulksgewijze invoegbewerking op een tabel zonder index van meerdere clients. U kunt deze eigenschap opgeven wanneer u Insert of Upsert als schrijfgedrag selecteert. Ga voor meer informatie naar BULK INSERT (Transact-SQL)
script vooraf kopiëren: geef een script op dat moet worden uitgevoerd voor kopieeractiviteit voordat u in elke uitvoering gegevens naar een doeltabel schrijft. U kunt deze eigenschap gebruiken om de vooraf geladen gegevens op te schonen.
Timeout voor schrijfbatch: Geef de wachttijd op waarvan de batchinvoegbewerking moet zijn voltooid voordat er een time-out optreedt. De toegestane waarde is een tijdsduur. Als er geen waarde is opgegeven, wordt de time-out standaard ingesteld op '02:00:00'.
Batchgrootte schrijven: geef het aantal rijen op dat in de SQL-tabel per batch moet worden ingevoegd. De toegestane waarde is een geheel getal (aantal rijen). Standaard bepaalt de service dynamisch de juiste batchgrootte op basis van de rijgrootte.
Maximum aantal gelijktijdige verbindingen: de bovengrens van gelijktijdige verbindingen die tijdens de uitvoering van de activiteit tot stand zijn gebracht met het gegevensarchief. Geef alleen een waarde op wanneer u gelijktijdige verbindingen wilt beperken.
Kartering
Als u geen gebruik maakt van Azure SQL Managed Instance met automatisch aanmaken van tabellen als uw bestemming, gaat u voor de Mapping tabbladconfiguratie naar Mapping.
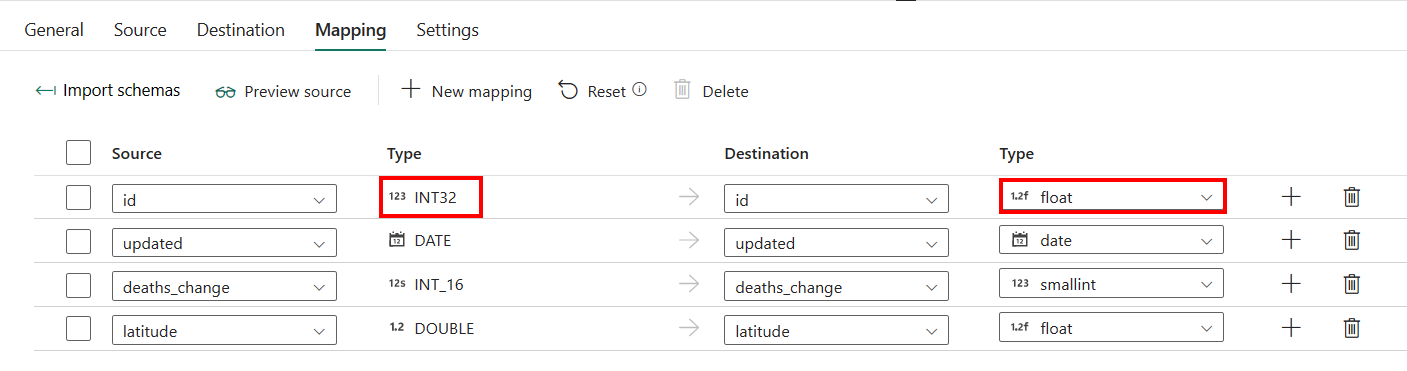
Als u Azure SQL Managed Instance met automatische tabelcreatie als bestemming gebruikt, met uitzondering van de configuratie in toewijzing, kunt u het type voor de doelkolommen bewerken. Nadat u Schema's importerenhebt geselecteerd, kunt u het kolomtype opgeven in uw bestemming.
Het type voor ID-kolom in de bron is bijvoorbeeld int, en u kunt dit wijzigen in float type bij het toewijzen aan de doelkolom.
Instellingen
Ga voor instellingen tabbladconfiguratie naar Andere instellingen configureren op het tabblad Instellingen.
Parallelle kopie van Azure SQL Managed Instance
De Azure SQL Managed Instance-connector in de kopieeractiviteit biedt ingebouwde gegevenspartitionering om gegevens parallel te kunnen kopiëren. U vindt opties voor gegevenspartitionering op het tabblad Bron van de kopieeractiviteit.
Wanneer u gepartitioneerde kopie inschakelt, voert de kopieeractiviteit parallelle query's uit op uw Azure SQL Managed Instance-bron om gegevens te laden op partities. De parallelle graad wordt bepaald door de mate van kopieerparallelisme op het tabblad Instellingen voor kopieeractiviteit. Als u bijvoorbeeld mate van parallelle kopieerbewerking instelt op vier, genereert en voert de service gelijktijdig vier query's uit op basis van de opgegeven partitieoptie en -instellingen en haalt elke query een deel van de gegevens op uit uw Azure SQL Managed Instance.
U wordt aangeraden parallelle kopie met gegevenspartitionering in te schakelen, met name wanneer u grote hoeveelheden gegevens laadt vanuit uw met Azure SQL beheerde exemplaar. Hier volgen voorgestelde configuraties voor verschillende scenario's. Wanneer u gegevens kopieert naar een bestandsgegevensarchief, is het raadzaam om naar een map te schrijven als meerdere bestanden (alleen mapnaam opgeven), in welk geval de prestaties beter zijn dan schrijven naar één bestand.
| Scenario | Voorgestelde instellingen |
|---|---|
| Volledige lading van grote tabel, met fysieke partities. |
partitieoptie: fysieke partities van de tabel. Tijdens de uitvoering detecteert de service automatisch de fysieke partities en kopieert de gegevens per partitie. Als u wilt controleren of uw tabel een fysieke partitie heeft of niet, kunt u verwijzen naar deze query. |
| Volledige uitvoer van een grote tabel, zonder fysieke partities, maar met een geheel getal of datum-/tijdkolom voor gegevenspartitionering. |
Partitieopties: dynamisch bereik partitie. Kolom partitioneren (optioneel): Geef de kolom op die wordt gebruikt om gegevens te partitioneren. Als deze niet is opgegeven, wordt de index- of primaire sleutelkolom gebruikt. Partitie bovengrens en partitie ondergrens (optioneel): Geef op of u de partitiestride wilt bepalen. Dit is niet voor het filteren van de rijen in de tabel. Alle rijen in de tabel worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarden. Als de partitiekolom 'ID' bijvoorbeeld waarden heeft tussen 1 en 100 en u de ondergrens instelt op 20 en de bovengrens als 80, met parallelle kopie als 4, haalt de service gegevens op met 4 partities - id's in het bereik <=20, [21, 50], [51, 80] en >=81. |
| Laad een grote hoeveelheid gegevens met behulp van een aangepaste query, zonder fysieke partities, terwijl u een geheel getal of een datum/datum/tijd-kolom gebruikt voor gegevenspartitionering. |
Partitieopties: dynamisch bereikpartitie. Query: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.partitie kolom: Geef de kolom op die wordt gebruikt om gegevens te partitioneren. Partitie bovengrens en partitie ondergrens (optioneel): Geef op of u de partitiestride wilt bepalen. Dit is niet voor het filteren van de rijen in de tabel. Alle rijen in het queryresultaat worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarde. Als de partitiekolom 'ID' bijvoorbeeld waarden heeft tussen 1 en 100, en u de ondergrens instelt op 20 en de bovengrens als 80, met parallelle kopie als 4, haalt de service gegevens op met 4 partities- id's in het bereik <=20, [21, 50], [51, 80] en >=81. Hier volgen meer voorbeeldquery's voor verschillende scenario's: • Voer een query uit op de hele tabel: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Een query uitvoeren vanuit een tabel met kolomselectie en aanvullende where-clause-filters: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Query's uitvoeren met subquery's: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Query uitvoeren met partitie in subquery: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Aanbevolen procedures voor het laden van gegevens met partitieoptie:
- Kies een onderscheidende kolom als partitiekolom (zoals primaire sleutel of unieke sleutel) om scheeftrekken van gegevens te voorkomen.
- Als de tabel een ingebouwde partitie heeft, gebruikt u de partitieoptie fysieke partities van tabel om betere prestaties te krijgen.
Voorbeeldquery om een fysieke partitie te controleren
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Als de tabel een fysieke partitie heeft, ziet u HasPartition als ja, zoals hieronder.

Tabelsamenvatting
Zie de volgende tabel voor de samenvatting en meer informatie over de kopieeractiviteit van Azure SQL Managed Instance.
Broninformatie
| Naam | Beschrijving | Waarde | Vereist | JSON-scripteigenschap |
|---|---|---|---|---|
| gegevensarchieftype | Het gegevensarchieftype. | Externe | Ja | / |
| verbinding | Uw verbinding met het brongegevensarchief. | < uw verbinding > | Ja | verbinding |
| verbindingstype | Uw verbindingstype. Selecteer Azure SQL Managed Instance. | Azure SQL Managed Instance | Ja | / |
| Query gebruiken | De aangepaste SQL-query voor het lezen van gegevens. | • Tafel •Vraag • Opgeslagen procedure |
Ja | / |
| Tabel | De brongegevenstabel. | < naam van de tabel> | Nee | schema tafel |
| Query | De aangepaste SQL-query voor het lezen van gegevens. | < uw zoekopdracht > | Nee | sqlReaderQuery |
| naam van opgeslagen procedure | Deze eigenschap is de naam van de opgeslagen procedure waarmee gegevens uit de brontabel worden gelezen. De laatste SQL-instructie moet een SELECT-instructie zijn in de opgeslagen procedure. | < opgeslagen procedure-naam > | Nee | Naam van de opgeslagen procedure voor SQL-lezer sqlReaderStoredProcedureName |
| opgeslagen procedureparameter | Deze parameters zijn voor de opgeslagen procedure. Toegestane waarden zijn naam- of waardeparen. De namen en hoofdletters van parameters moeten overeenkomen met de namen en hoofdletters van de opgeslagen procedureparameters. | < naam- of waardeparen > | Nee | storedProcedureParameters |
| Timeout van queries | De time-out voor het uitvoeren van queryopdrachten. | tijdspanne (de standaardwaarde is 120 minuten) |
Nee | queryTimeout |
| isolatieniveau | Hiermee geeft u het gedrag voor transactievergrendeling voor de SQL-bron op. | • Lees vastgelegd • Niet-verzonden lezen • Herhaalbare leesbewerking •Serializable •Momentopname |
Nee | isolatieniveau • ReadCommitted • ReadUncommitted (if this is the correct and common term used in Dutch IT or database contexts, no changes needed) • Herhaalbaar gelezen • Serieel verwerkbaar Momentopname |
| partitieoptie | De opties voor gegevenspartitionering die worden gebruikt voor het laden van gegevens uit Azure SQL Managed Instance. | • Geen (standaard) • Fysieke partities van tabel • Dynamisch bereik |
Nee | partitieOptie: • Geen (standaard) • FysiekePartitiesVanTabel • DynamicRange |
| partitie kolomnaam | De naam van de bronkolom in geheel getal of datum/datum/tijd type (int, smallint, bigint, date, smalldatetime, datetime, datetime2of datetimeoffset) die wordt gebruikt door bereikpartitionering voor parallelle kopie. Als deze niet is opgegeven, wordt de index of de primaire sleutel van de tabel automatisch gedetecteerd en gebruikt als partitiekolom. Als u een query gebruikt om de brongegevens op te halen, koppelt u ?DfDynamicRangePartitionCondition in de WHERE-component. |
< jouw partitiekolomnamen > | Nee | partitionColumnName |
| Bovengrens van de partitie | De maximale waarde van de partitiekolom voor het splitsen van een partitiebereik. Deze waarde wordt gebruikt om de partitielengte te bepalen, en niet voor het filteren van de rijen in de tabel. Alle rijen in de tabel of het queryresultaat worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarde. | < de bovengrens van de partitie > | Nee | partitionUpperBound |
| Partitie ondergrens | De minimale waarde van de partitiekolom voor het splitsen van een partitiebereik. Deze waarde wordt gebruikt om de partitie-stap te bepalen, niet voor het filteren van de rijen in de tabel. Alle rijen in de tabel of het queryresultaat worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarde. | < de ondergrens van de partitie > | Nee | partitionLowerBound |
| Aanvullende kolommen | Voeg extra gegevenskolommen toe om het relatieve pad of de statische waarde van bronbestanden op te slaan. Expressie wordt ondersteund voor de laatste. | •Naam •Waarde |
Nee | extraKolommen: •naam • waarde |
Doelgegevens
| Naam | Beschrijving | Waarde | Vereist | JSON-scripteigenschap |
|---|---|---|---|---|
| gegevensarchieftype | Het gegevensarchieftype. | Externe | Ja | / |
| verbinding | Uw verbinding met de bestemmingsgegevensopslag. | < uw verbinding > | Ja | verbinding |
| verbindingstype | Uw verbindingstype. Selecteer Azure SQL Managed Instance. | Azure SQL Managed Instance | Ja | / |
| optie voor tabel | Hiermee geeft u op of de doeltabel automatisch moet worden gemaakt als deze niet bestaat op basis van het bronschema. | • Bestaande gebruiken • Tabel automatisch maken |
Ja | tableOption: • automatisch aanmaken |
| Tabel | Uw doelgegevenstabel. | <naam van de tabel> | Ja | schema tafel |
| Schrijfgedrag | Het schrijfgedrag voor kopieeractiviteit voor het laden van gegevens in de Azure SQL Managed Instance-database. | •Invoegen • Bijwerken of invoegen • Opgeslagen procedure |
Nee | schrijfGedrag: •invoegen • upsert (invoegen of bijwerken) sqlWriterStoredProcedureName, sqlWriterTableType, storedProcedureTableTypeParameterName, storedProcedureParameters |
| TempDB- gebruiken | Of u de globale tijdelijke tabel of fysieke tabel wilt gebruiken als de tussentijdse tabel voor upsert. | geselecteerd (standaard) of niet geselecteerd | Nee | useTempDB: waar (standaard) of onwaar |
| db-schema van gebruiker selecteren | Het tussentijdse schema voor het maken van een tussentijdse tabel als fysieke tabel wordt gebruikt. Opmerking: de gebruiker moet over de machtiging beschikken voor het maken en verwijderen van een tabel. De tussentijdse tabel deelt standaard hetzelfde schema als de doeltabel. Toepassen wanneer u TempDB-niet selecteert. | geselecteerd (standaard) of niet geselecteerd | Nee | interimSchemaName |
| sleutelkolommen | De kolomnamen die worden gebruikt voor unieke rijidentificatie. U kunt één sleutel of een reeks sleutels gebruiken. Als deze niet is opgegeven, wordt de primaire sleutel gebruikt. | < de sleutelkolom> | Nee | Sleutels |
| naam van opgeslagen procedure | De naam van de opgeslagen procedure waarmee wordt gedefinieerd hoe brongegevens in een doeltabel moeten worden toegepast. Deze opgeslagen procedure wordt aangeroepen per batch. Voor bewerkingen die slechts eenmaal worden uitgevoerd en die niets te maken hebben met brongegevens, bijvoorbeeld verwijderen of afkappen, gebruikt u de eigenschap Script vooraf kopiëren. | < de naam van de opgeslagen procedure > | Nee | sqlWriterStoredProcedureName |
| tabeltype | De naam van het tabeltype dat moet worden gebruikt in de opgeslagen procedure. De kopieeractiviteit maakt de gegevens beschikbaar in een tijdelijke tabel met dit tabeltype. Opgeslagen procedurecode kan vervolgens de gegevens samenvoegen die worden gekopieerd met bestaande gegevens. | < de naam van het tabeltype > | Nee | sqlWriterTableType |
| tabeltypeparameternaam van | De parameternaam van het tabeltype dat is opgegeven in de opgeslagen procedure. | < de parameternaam van het tabeltype > | Nee | opgeslagenProcedureTabelTypeParameterNaam |
| Parameters | Parameters voor de opgeslagen procedure. Toegestane waarden zijn naam- en waardeparen. Namen en hoofdlettergebruik van parameters moeten overeenkomen met de namen en het hoofdlettergebruik van de opgeslagen procedureparameters. | < naam- en waardeparen > | Nee | opgeslagenProcedureParameters |
| tabelvergrendeling bulksgewijs invoegen | Gebruik deze instelling om de kopieerprestaties te verbeteren tijdens een bulksgewijze invoegbewerking op een tabel zonder index van meerdere clients. | Ja of Nee (standaard) | Nee | sqlWriterUseTableLock: waar of onwaar (standaard) |
| script vooraf kopiëren | Een script voor kopieerbewerkingen dat moet worden uitgevoerd voordat gegevens bij elke uitvoering in een bestemmingstabel worden geschreven. U kunt deze eigenschap gebruiken om de vooraf geladen gegevens op te schonen. |
< script vooraf kopiëren > (tekenreeks) |
Nee | preCopyScript |
| time-out voor schrijfbatch | De wachttijd voordat de batchinvoegbewerking is voltooid voordat er een time-out optreedt. | tijdspanne (de standaardwaarde is '02:00:00') |
Nee | writeBatchTimeout |
| Batchgrootte instellen | Het aantal rijen dat moet worden ingevoegd in de SQL-tabel per batch. Standaard bepaalt de service dynamisch de juiste batchgrootte op basis van de rijgrootte. |
< aantal rijen > (geheel getal) |
Nee | writeBatchSize |
| Maximum aantal gelijktijdige verbindingen | De bovengrens van gelijktijdige verbindingen die tijdens de uitvoering van de activiteit tot stand zijn gebracht met het gegevensarchief. Geef alleen een waarde op wanneer u gelijktijdige verbindingen wilt beperken. |
< bovengrens van gelijktijdige verbindingen > (geheel getal) |
Nee | maximaal gelijktijdige verbindingen |
Verwante inhoud
- Inleiding van Azure SQL Managed Instance