Gegevens transformeren door een Azure Databricks-activiteit uit te voeren
Met de Azure Databricks-activiteit in Data Factory voor Microsoft Fabric kunt u de volgende Azure Databricks-taken organiseren:
- Notebook
- Jar
- Python
Dit artikel bevat een stapsgewijze handleiding waarin wordt beschreven hoe u een Azure Databricks-activiteit maakt met behulp van de Data Factory-interface.
Vereisten
Om aan de slag te gaan, moet u aan de volgende vereisten voldoen:
- Een tenantaccount met een actief abonnement. Gratis een account maken
- Er wordt een werkruimte gemaakt.
Een Azure Databricks-activiteit configureren
Voer de volgende stappen uit om een Azure Databricks-activiteit in een pijplijn te gebruiken:
Verbinding configureren
Maak een nieuwe pijplijn in uw werkruimte.
Klik op Een pijplijnactiviteit toevoegen en zoeken naar Azure Databricks.
U kunt ook zoeken naar Azure Databricks in het deelvenster Pijplijnactiviteiten en deze selecteren om deze toe te voegen aan het pijplijncanvas.
Selecteer de nieuwe Azure Databricks-activiteit op het canvas als deze nog niet is geselecteerd.
Raadpleeg de richtlijnen voor algemene instellingen voor het configureren van het tabblad Algemene instellingen.
Clusters configureren
Selecteer het tabblad Cluster . Vervolgens kunt u een bestaande of een nieuwe Azure Databricks-verbinding maken en vervolgens een nieuw taakcluster, een bestaand interactief cluster of een bestaande exemplaargroep kiezen.
Afhankelijk van wat u voor het cluster kiest, vult u de bijbehorende velden in zoals weergegeven.
- Onder het nieuwe taakcluster en de bestaande exemplaargroep hebt u ook de mogelijkheid om het aantal werkrollen te configureren en spot-exemplaren in te schakelen.
U kunt ook aanvullende clusterinstellingen opgeven, zoals clusterbeleid, Spark-configuratie, Spark-omgevingsvariabelen en aangepaste tags, zoals vereist voor het cluster waarmee u verbinding maakt. Databricks init-scripts en het doelpad van het clusterlogboek kunnen ook worden toegevoegd onder de aanvullende clusterinstellingen.
Notitie
Alle geavanceerde clustereigenschappen en dynamische expressies die worden ondersteund in de gekoppelde Azure Databricks-service van Azure Databricks, worden nu ook ondersteund in de Azure Databricks-activiteit in Microsoft Fabric onder de sectie Aanvullende clusterconfiguratie in de gebruikersinterface. Omdat deze eigenschappen nu zijn opgenomen in de gebruikersinterface van de activiteit; ze kunnen eenvoudig worden gebruikt met een expressie (dynamische inhoud) zonder de geavanceerde JSON-specificatie in de gekoppelde Azure Databricks-service van Azure Databricks.
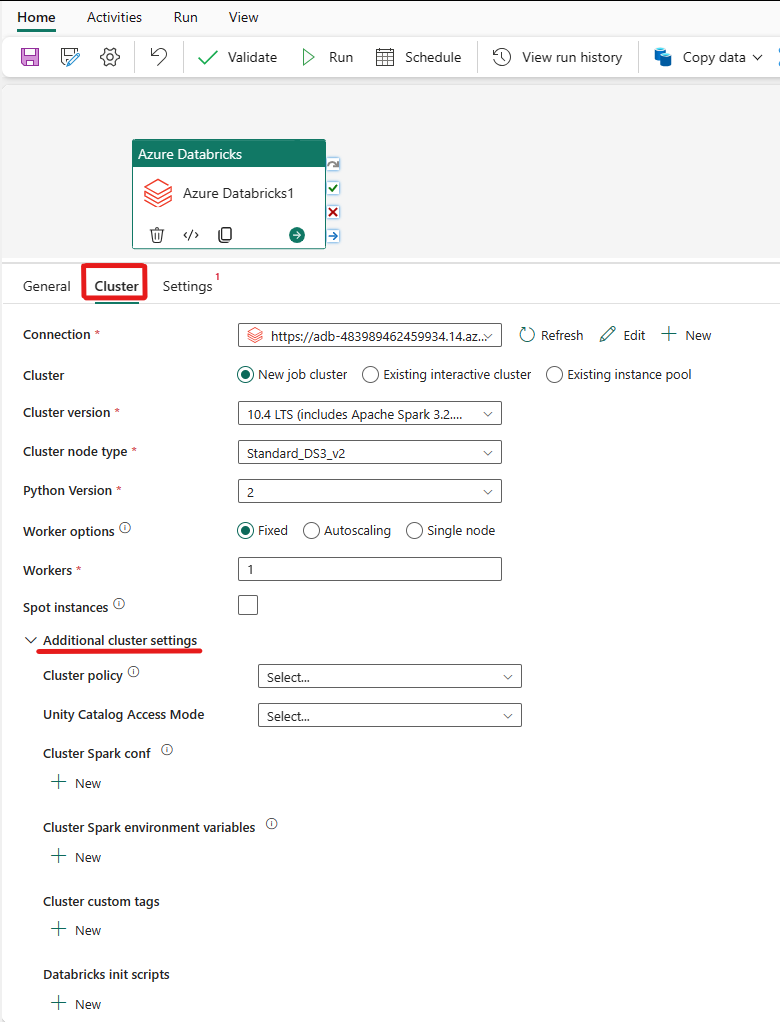
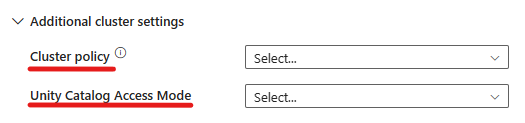
De Azure Databricks-activiteit ondersteunt nu ook ondersteuning voor clusterbeleid en Unity Catalog.
- Onder geavanceerde instellingen kunt u het clusterbeleid kiezen, zodat u kunt opgeven welke clusterconfiguraties zijn toegestaan.
- Onder geavanceerde instellingen hebt u ook de mogelijkheid om de Unity Catalog-toegangsmodus te configureren voor extra beveiliging. De beschikbare typen toegangsmodus zijn:
- Modus voor toegang tot één gebruiker Deze modus is ontworpen voor scenario's waarin elk cluster wordt gebruikt door één gebruiker. Het zorgt ervoor dat de gegevenstoegang binnen het cluster alleen voor die gebruiker is beperkt. Deze modus is handig voor taken die isolatie en afzonderlijke gegevensverwerking vereisen.
- In deze modus voor gedeelde toegang hebben meerdere gebruikers toegang tot hetzelfde cluster. Het combineert gegevensbeheer van Unity Catalog met de verouderde toegangsbeheerlijsten (ACL's) voor tabellen. Met deze modus kunt u gezamenlijke gegevenstoegang krijgen met behoud van governance- en beveiligingsprotocollen. Het heeft echter bepaalde beperkingen, zoals het niet ondersteunen van Databricks Runtime ML, Spark-submit-taken en specifieke Spark-API's en UDF's.
- Geen toegangsmodus Deze modus schakelt interactie met de Unity-catalogus uit, wat betekent dat clusters geen toegang hebben tot gegevens die worden beheerd door Unity Catalog. Deze modus is handig voor workloads waarvoor de governancefuncties van Unity Catalog niet nodig zijn.
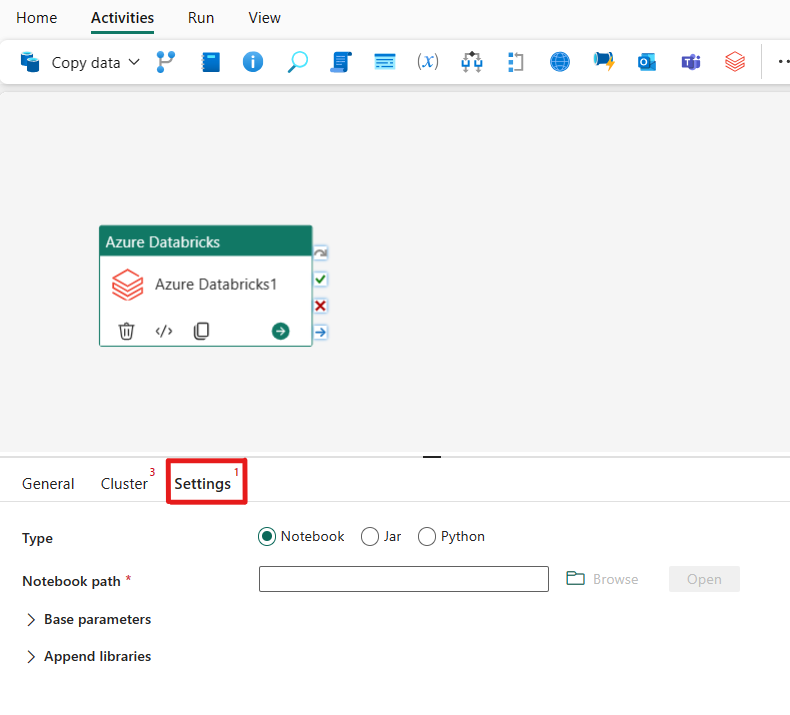
Instellingen configureren
Als u het tabblad Instellingen selecteert, kunt u kiezen uit drie opties die u wilt organiseren in Azure Databricks .
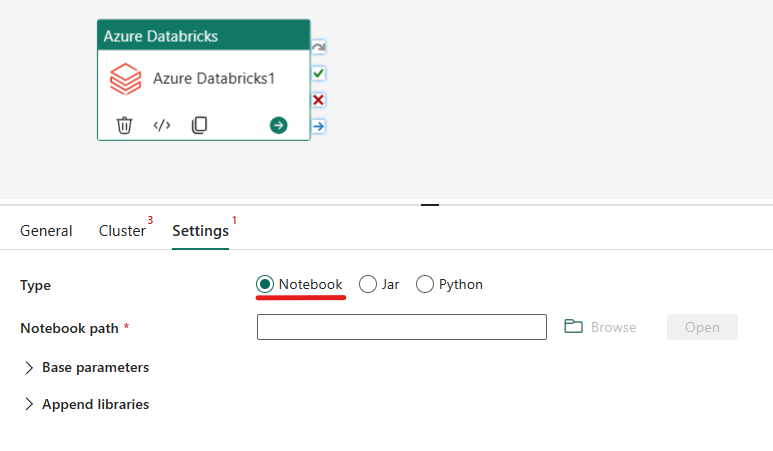
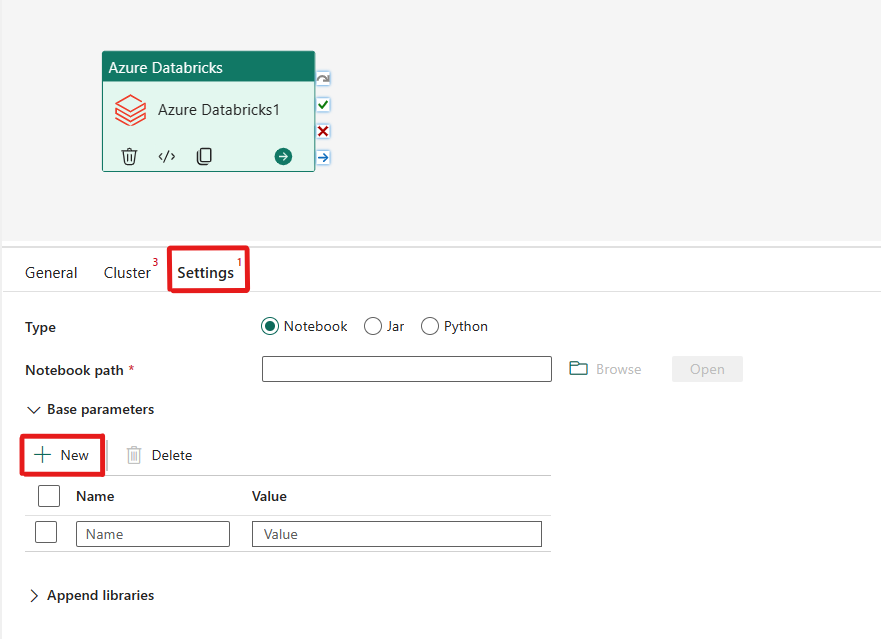
Het notebooktype in azure Databricks-activiteit indelen:
Op het tabblad Instellingen kunt u het keuzerondje Notitieblok kiezen om een notitieblok uit te voeren. U moet het notebookpad opgeven dat moet worden uitgevoerd op Azure Databricks, optionele basisparameters die moeten worden doorgegeven aan het notebook en eventuele extra bibliotheken die op het cluster moeten worden geïnstalleerd om de taak uit te voeren.
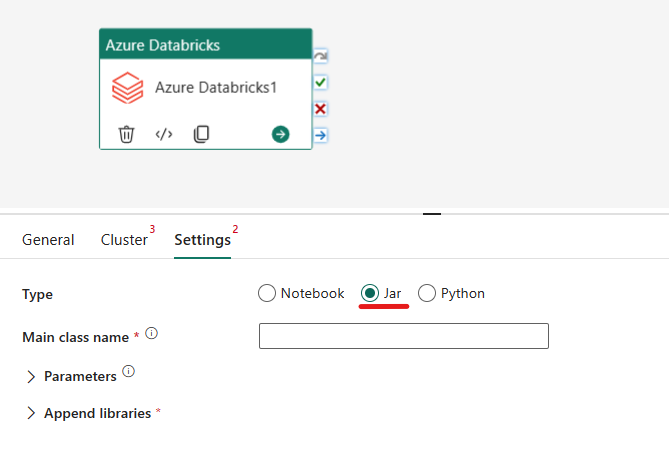
Het Jar-type indelen in Azure Databricks-activiteit:
Op het tabblad Instellingen kunt u het keuzerondje Jar kiezen om een Jar-bestand uit te voeren. U moet de klassenaam opgeven die moet worden uitgevoerd in Azure Databricks, optionele basisparameters die moeten worden doorgegeven aan het Jar-bestand en eventuele extra bibliotheken die op het cluster moeten worden geïnstalleerd om de taak uit te voeren.
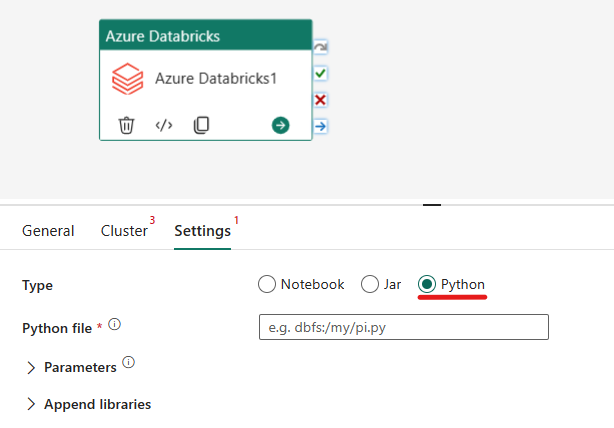
Het Python-type in Azure Databricks-activiteit indelen:
Op het tabblad Instellingen kunt u het keuzerondje Python kiezen om een Python-bestand uit te voeren. U moet het pad in Azure Databricks opgeven naar een Python-bestand dat moet worden uitgevoerd, optionele basisparameters die moeten worden doorgegeven en eventuele extra bibliotheken die moeten worden geïnstalleerd op het cluster om de taak uit te voeren.
Ondersteunde bibliotheken voor de Azure Databricks-activiteit
In de bovenstaande Databricks-activiteitsdefinitie kunt u deze bibliotheektypen opgeven: jar, ei, whl, maven, pypi, cran.
Zie de Databricks-documentatie voor bibliotheektypen voor meer informatie.
Parameters doorgeven tussen Azure Databricks-activiteit en pijplijnen
U kunt parameters doorgeven aan notebooks met behulp van de eigenschap BaseParameters in databricks-activiteit.
In bepaalde gevallen moet u mogelijk bepaalde waarden van notebook terugsturen naar de service, die kan worden gebruikt voor controlestroom (voorwaardelijke controles) in de service of worden gebruikt door downstreamactiviteiten (groottelimiet is 2 MB).
In uw notebook kunt u bijvoorbeeld dbutils.notebook.exit("returnValue") aanroepen en de bijbehorende returnValue worden geretourneerd naar de service.
U kunt de uitvoer in de service gebruiken met behulp van expressies zoals
@{activity('databricks activity name').output.runOutput}.
De pijplijn opslaan en uitvoeren of plannen
Nadat u andere activiteiten hebt geconfigureerd die vereist zijn voor uw pijplijn, gaat u naar het tabblad Start boven aan de pijplijneditor en selecteert u de knop Opslaan om uw pijplijn op te slaan. Selecteer Uitvoeren om het rechtstreeks uit te voeren of Plan om deze te plannen. U kunt hier ook de uitvoeringsgeschiedenis bekijken of andere instellingen configureren.
