Notebooks organiseren en code modulariseren in notebooks
Meer informatie over het organiseren van notebooks en het modulariseren van code in notebooks. Bekijk voorbeelden en begrijp wanneer u alternatieve methoden gebruikt voor indeling van notitieblokken.
Indelings- en code modularisatiemethoden
In de volgende tabel worden de methoden vergeleken die beschikbaar zijn voor het organiseren van notebooks en het modulariseren van code in notebooks.
| Methode | Gebruiksscenario | Notities |
|---|---|---|
| Databricks Banen | Orchestratie van notitieblokken (aanbevolen) | Aanbevolen methode voor het organiseren van notitieblokken. Ondersteunt complexe werkstromen met taakafhankelijkheden, planning en triggers. Biedt een robuuste en schaalbare benadering voor productieworkloads, maar vereist installatie en configuratie. |
| dbutils.notebook.run() | Orchestratie van notitieblokken | Gebruik dbutils.notebook.run() wanneer Jobs uw 'use case' niet kunnen ondersteunen, zoals bij het herhaald uitvoeren van notitieblokken met een dynamische set parameters.Start een nieuwe tijdelijke taak voor elke aanroep, waardoor de overhead kan toenemen en geavanceerde planningsfuncties ontbreken. |
| werkruimtebestanden | Code modularisatie (aanbevolen) | Aanbevolen methode voor het modulariseren van code. Code modulariseren in herbruikbare codebestanden die zijn opgeslagen in de werkruimte. Ondersteunt versiebeheer met opslagplaatsen en integratie met IDE's voor betere foutopsporing en eenheidstests. Vereist aanvullende instellingen voor het beheren van bestandspaden en afhankelijkheden. |
| %run | Code modularisering | Gebruik %run als u geen toegang hebt tot werkruimtebestanden.Importeer eenvoudig functies of variabelen uit andere notebooks door ze inline uit te voeren. Handig voor het maken van prototypen, maar kan leiden tot nauw gekoppelde code die moeilijker te onderhouden is. Biedt geen ondersteuning voor het doorgeven van parameters of versiebeheer. |
%run versus dbutils.notebook.run()
Met de %run opdracht kunt u een ander notitieblok opnemen in een notitieblok. U kunt %run gebruiken om uw code te modulariseren door ondersteunende functies in een afzonderlijk notebook te plaatsen. U kunt deze ook gebruiken om notebooks samen te voegen die de stappen in een analyse implementeren. Wanneer u het notitieblok gebruikt %run, wordt het aangeroepen notebook onmiddellijk uitgevoerd en worden de functies en variabelen die erin zijn gedefinieerd, beschikbaar in het aanroepende notebook.
De dbutils.notebook-API vormt een aanvulling op %run omdat u hiermee parameters kunt doorgeven aan en waarden kunt retourneren uit een notebook. Hiermee kunt u complexe werkstromen en pijplijnen bouwen met afhankelijkheden. U kunt bijvoorbeeld een lijst met bestanden in een map ophalen en de namen doorgeven aan een ander notitieblok, wat onmogelijk is met %run. U kunt ook if-then-else-werkstromen maken op basis van retourwaarden.
In tegenstelling tot %run, wordt met de dbutils.notebook.run() methode een nieuwe taak gestart om het notebook uit te voeren.
Net als alle dbutils API's zijn deze methoden alleen beschikbaar in Python en Scala. U kunt echter ook dbutils.notebook.run() een R-notebook aanroepen.
Gebruiken %run om een notebook te importeren
In dit voorbeeld definieert het eerste notebook een functie, reversedie beschikbaar is in het tweede notebook nadat u de %run magie hebt gebruikt om uit te voeren shared-code-notebook.
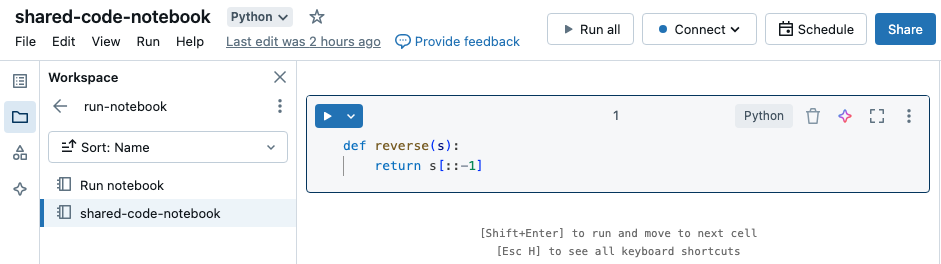
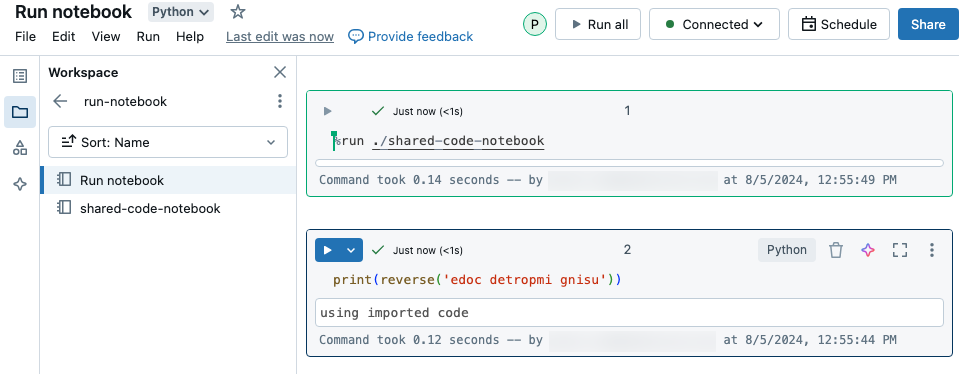
Omdat beide notebooks zich in dezelfde map in de werkruimte bevinden, gebruikt u het voorvoegsel ./ in ./shared-code-notebook om aan te geven dat het pad moet worden bepaald ten opzichte van het momenteel actieve notebook. U kunt notitieblokken ordenen in mappen, zoals %run ./dir/notebook, of een absoluut pad gebruiken, zoals %run /Users/username@organization.com/directory/notebook.
Notitie
-
%runmoet op zichzelf in een cel staan, omdat het hele notebook inline wordt uitgevoerd. - U uitvoeren
%runin een notebook. Als u wilt importeren uit een Python-bestand, raadpleegt u Uw code modulariseren met behulp van bestanden. U kunt het bestand ook inpakken in een Python-bibliotheek, een Azure Databricks-bibliotheek maken vanuit die Python-bibliotheek en de bibliotheek installeren in het cluster dat u gebruikt om uw notebook uit te voeren. - Wanneer u
%rungebruikt om een notebook met widgets uit te voeren, wordt het specifieke notebook standaard uitgevoerd met de standaardwaarden van de widgets. U kunt ook waarden doorgeven aan widgets; zie Databricks-widgets gebruiken met %run.
Gebruik dbutils.notebook.run om een nieuwe taak te starten
Voer een notebook uit en retourneer de afsluitwaarde. De methode start een tijdelijke taak die onmiddellijk wordt uitgevoerd.
De methoden die beschikbaar zijn in de dbutils.notebook API zijn run en exit. Zowel parameters als retourwaarden moeten tekenreeksen zijn.
run(path: String, timeout_seconds: int, arguments: Map): String
De timeout_seconds parameter bepaalt de time-out van de uitvoering (0 betekent geen time-out). De aanroep naar run genereert een uitzondering als deze niet binnen de opgegeven tijd wordt voltooid. Als Azure Databricks langer dan 10 minuten uitvalt, mislukt de uitvoering van timeout_secondshet notebook, ongeacht.
Met de parameter arguments worden widgetwaarden van het doelnotitieblok ingesteld. Als het notebook dat u uitvoert een widget heeft met de naam Aen u een sleutel-waardepaar ("A": "B") doorgeeft als onderdeel van de parameter argumenten aan de run() aanroep, wordt het ophalen van de waarde van de widget A geretourneerd "B". U vindt de instructies voor het maken en werken met widgets in het artikel databricks-widgets .
Notitie
- De parameter
argumentsaccepteert alleen Latijnse tekens (ASCII-tekenset). Als u niet-ASCII-tekens gebruikt, wordt een fout geretourneerd. - Taken die zijn gemaakt met behulp van de
dbutils.notebookAPI, moeten binnen 30 dagen of minder worden voltooid.
run Gebruik
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
Scala
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
Gestructureerde gegevens doorgeven tussen notebooks
In deze sectie ziet u hoe u gestructureerde gegevens tussen notebooks doorgeeft.
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
Scala
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
Afhandeling van fouten
In deze sectie ziet u hoe u fouten kunt afhandelen.
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
Scala
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here, we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
Gelijktijdig meerdere notebooks uitvoeren
U kunt meerdere notebooks tegelijk uitvoeren met behulp van standaard-Scala- en Python-constructies zoals Threads (Scala, Python) en Futures (Scala, Python). In de voorbeeldnotebooks wordt gedemonstreerd hoe u deze constructies gebruikt.
- Download de volgende vier notebooks. De notebooks worden geschreven in Scala.
- Importeer de notebooks in één map in de werkruimte.
- Voer het notebook Gelijktijdig uitvoeren uit.