Spark-taakdefinitie migreren van Azure Synapse naar Fabric
Als u Spark-taakdefinities (SJD) wilt verplaatsen van Azure Synapse naar Fabric, hebt u twee verschillende opties:
- Optie 1: Spark-taakdefinitie handmatig maken in Fabric.
- Optie 2: u kunt een script gebruiken om Spark-taakdefinities uit Azure Synapse te exporteren en te importeren in Fabric met behulp van de API.
Raadpleeg voor overwegingen met betrekking tot spark-taakdefinities verschillen tussen Azure Synapse Spark en Fabric.
Vereisten
Als u er nog geen hebt, maakt u een Fabric-werkruimte in uw tenant.
Optie 1: Spark-taakdefinitie handmatig maken
Een Spark-taakdefinitie exporteren vanuit Azure Synapse:
- Open Synapse Studio: meld u aan bij Azure. Navigeer naar uw Azure Synapse-werkruimte en open Synapse Studio.
- Zoek de Python/Scala/R Spark-taak: zoek en identificeer de Python/Scala/R Spark-taakdefinitie die u wilt migreren.
-
De taakdefinitieconfiguratie exporteren:
- Open in Synapse Studio de Spark-taakdefinitie.
- Exporteer of noteer de configuratie-instellingen, waaronder de locatie van het scriptbestand, afhankelijkheden, parameters en eventuele andere relevante details.
Een nieuwe Spark-taakdefinitie (SJD) maken op basis van de geëxporteerde SJD-informatie in Fabric:
- Access Fabric-werkruimte: meld u aan bij Fabric en open uw werkruimte.
-
Maak een nieuwe Spark-taakdefinitie in Fabric:
- Ga in Fabric naar Data-engineer startpagina.
- Selecteer Spark-taakdefinitie.
- Configureer de taak met behulp van de gegevens die u hebt geëxporteerd uit Synapse, inclusief scriptlocatie, afhankelijkheden, parameters en clusterinstellingen.
- Aanpassen en testen: Breng alle benodigde aanpassingen aan het script of de configuratie aan voor de Fabric-omgeving. Test de taak in Fabric om ervoor te zorgen dat deze correct wordt uitgevoerd.
Zodra de Spark-taakdefinitie is gemaakt, valideert u afhankelijkheden:
- Zorg ervoor dat u dezelfde Spark-versie gebruikt.
- Valideer het bestaan van het hoofddefinitiebestand.
- Valideer het bestaan van de bestanden, afhankelijkheden en resources waarnaar wordt verwezen.
- Gekoppelde services, gegevensbronverbindingen en koppelpunten.
Meer informatie over het maken van een Apache Spark-taakdefinitie in Fabric.
Optie 2: De Fabric-API gebruiken
Volg deze belangrijke stappen voor migratie:
- Vereisten.
- Stap 1: Spark-taakdefinitie exporteren van Azure Synapse naar OneLake (.json).
- Stap 2: Spark-taakdefinitie automatisch importeren in Fabric met behulp van de Fabric-API.
Vereisten
De vereisten omvatten acties die u moet overwegen voordat u de migratie van spark-taakdefinities naar Fabric start.
- Een Infrastructuurwerkruimte.
- Als u er nog geen hebt, maakt u een Fabric Lakehouse in uw werkruimte.
Stap 1: Spark-taakdefinitie exporteren vanuit Azure Synapse-werkruimte
De focus van stap 1 ligt op het exporteren van spark-taakdefinities vanuit de Azure Synapse-werkruimte naar OneLake in json-indeling. Dit proces is als volgt:
- 1.1) Import SJD migration notebook to Fabric workspace. Met dit notebook worden alle Spark-taakdefinities vanuit een bepaalde Azure Synapse-werkruimte geëxporteerd naar een tussenliggende map in OneLake. Synapse-API wordt gebruikt om SJD te exporteren.
- 1.2) Configureer de parameters in de eerste opdracht om spark-taakdefinitie te exporteren naar een tussenliggende opslag (OneLake). Hiermee wordt alleen het JSON-metagegevensbestand geëxporteerd. Het volgende codefragment wordt gebruikt om de bron- en doelparameters te configureren. Zorg ervoor dat u ze vervangt door uw eigen waarden.
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
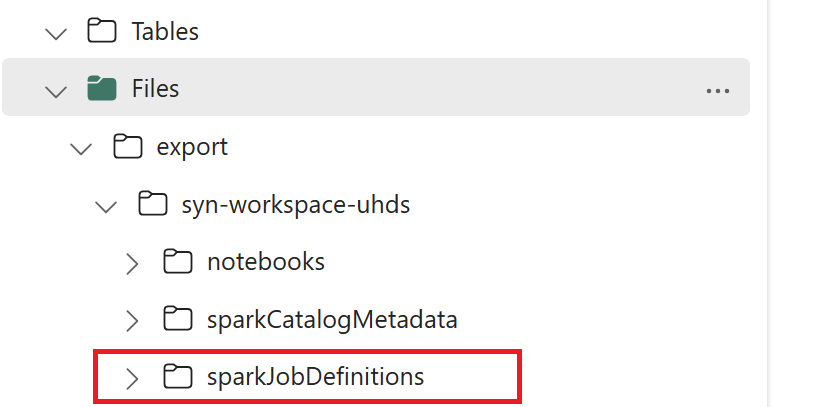
- 1.3) Voer de eerste twee cellen van het export-/importnotebook uit om metagegevens van spark-taakdefinities te exporteren naar OneLake. Zodra de cellen zijn voltooid, wordt deze mapstructuur onder de tussenliggende uitvoermap gemaakt.
Stap 2: Spark-taakdefinitie importeren in Fabric
Stap 2 is wanneer Spark-taakdefinities worden geïmporteerd uit tussenliggende opslag in de infrastructuurwerkruimte. Dit proces is als volgt:
- 2.1) Valideer de configuraties in 1.2 om ervoor te zorgen dat de juiste werkruimte en het juiste voorvoegsel worden aangegeven om de Spark-taakdefinities te importeren.
- 2.2) Voer de derde cel van het export-/importnotebook uit om alle Spark-taakdefinities te importeren vanaf een tussenliggende locatie.
Notitie
Met de exportoptie wordt een JSON-metagegevensbestand uitgevoerd. Zorg ervoor dat uitvoerbare bestanden, referentiebestanden en argumenten van spark-taakdefinities toegankelijk zijn vanuit Fabric.