Hive Metastore-metagegevens migreren van Azure Synapse Analytics naar Fabric
De eerste stap in de Migratie van Hive Metastore (HMS) omvat het bepalen van de databases, tabellen en partities die u wilt overdragen. Het is niet nodig om alles te migreren; u kunt specifieke databases selecteren. Controleer bij het identificeren van databases voor migratie of er beheerde of externe Spark-tabellen zijn.
Raadpleeg voor HMS-overwegingen de verschillen tussen Azure Synapse Spark en Fabric.
Notitie
Als uw ADLS Gen2 Delta-tabellen bevat, kunt u ook een OneLake-snelkoppeling maken naar een Delta-tabel in ADLS Gen2.
Vereisten
- Als u er nog geen hebt, maakt u een Fabric-werkruimte in uw tenant.
- Als u er nog geen hebt, maakt u een Fabric Lakehouse in uw werkruimte.
Optie 1: HMS exporteren en importeren in lakehouse-metastore
Volg deze belangrijke stappen voor migratie:
- Stap 1: Metagegevens exporteren uit HMS-bron
- Stap 2: Metagegevens importeren in Fabric Lakehouse
- Stappen na de migratie: Inhoud valideren
Notitie
Scripts kopiëren alleen Spark-catalogusobjecten naar Fabric Lakehouse. Veronderstelling is dat de gegevens al zijn gekopieerd (bijvoorbeeld van magazijnlocatie naar ADLS Gen2) of beschikbaar zijn voor beheerde en externe tabellen (bijvoorbeeld via snelkoppelingen, voorkeur) in fabric lakehouse.
Stap 1: Metagegevens exporteren uit HMS-bron
De focus van stap 1 ligt op het exporteren van de metagegevens van bron HMS naar de sectie Bestanden van uw Fabric Lakehouse. Dit proces is als volgt:
1.1) Importeer HMS Metadata Export Notebook in uw Azure Synapse-werkruimte. Dit notebook voert query's uit en exporteert HMS-metagegevens van databases, tabellen en partities naar een tussenliggende map in OneLake (functies die nog niet zijn opgenomen). Interne Spark-catalogus-API wordt in dit script gebruikt om catalogusobjecten te lezen.
1.2) Configureer de parameters in de eerste opdracht om metagegevensgegevens te exporteren naar een tussenliggende opslag (OneLake). Het volgende codefragment wordt gebruikt om de bron- en doelparameters te configureren. Zorg ervoor dat u ze vervangt door uw eigen waarden.
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) Voer alle notebookopdrachten uit om catalogusobjecten te exporteren naar OneLake. Zodra de cellen zijn voltooid, wordt deze mapstructuur onder de tussenliggende uitvoermap gemaakt.
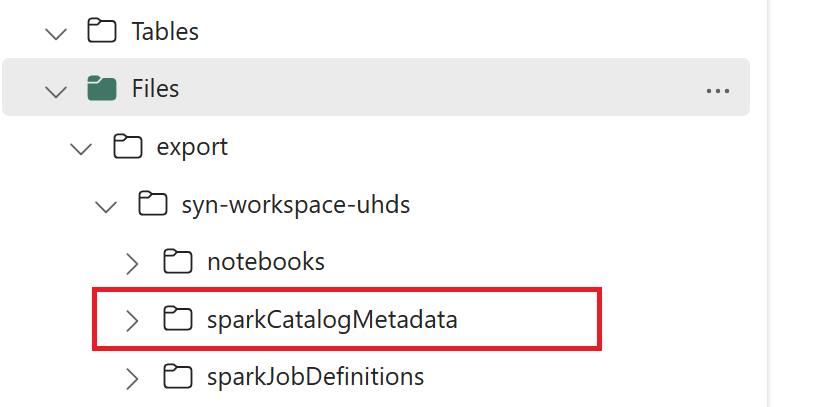
Stap 2: Metagegevens importeren in Fabric Lakehouse
Stap 2 is wanneer de werkelijke metagegevens worden geïmporteerd uit tussenliggende opslag in fabric lakehouse. De uitvoer van deze stap is om alle HMS-metagegevens (databases, tabellen en partities) te migreren. Dit proces is als volgt:
2.1) Maak een snelkoppeling in de sectie 'Bestanden' van het lakehouse. Deze snelkoppeling moet verwijzen naar de bronmap van het Spark-magazijn en wordt later gebruikt om de vervanging voor beheerde Spark-tabellen uit te voeren. Zie snelkoppelingsvoorbeelden die verwijzen naar sparkwarehouse-map:
- Snelkoppelingspad naar Azure Synapse Spark-magazijnmap:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - Snelkoppelingspad naar Azure Databricks-magazijnmap:
dbfs:/mnt/<warehouse_dir> - Snelkoppelingspad naar HDInsight Spark-warehousemap:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- Snelkoppelingspad naar Azure Synapse Spark-magazijnmap:
2.2) Import HMS metadata import notebook into your Fabric workspace. Importeer dit notebook om database-, tabel- en partitieobjecten te importeren uit tussenliggende opslag. Interne Spark-catalogus-API wordt in dit script gebruikt om catalogusobjecten te maken in Fabric.
2.3) Configureer de parameters in de eerste opdracht. Wanneer u in Apache Spark een beheerde tabel maakt, worden de gegevens voor die tabel opgeslagen op een locatie die wordt beheerd door Spark zelf, meestal in de warehousemap van Spark. De exacte locatie wordt bepaald door Spark. Dit contrasteert met externe tabellen, waarbij u de locatie opgeeft en de onderliggende gegevens beheert. Wanneer u de metagegevens van een beheerde tabel migreert (zonder de werkelijke gegevens te verplaatsen), bevatten de metagegevens nog steeds de oorspronkelijke locatiegegevens die verwijzen naar de oude Spark-magazijnmap. Daarom wordt voor beheerde tabellen
WarehouseMappingsgebruikt om de vervanging uit te voeren met behulp van de snelkoppeling die is gemaakt in stap 2.1. Alle beheerde brontabellen worden geconverteerd als externe tabellen met behulp van dit script.LakehouseIdverwijst naar het lakehouse dat is gemaakt in stap 2.1 met snelkoppelingen.// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) Voer alle notebookopdrachten uit om catalogusobjecten uit het tussenliggende pad te importeren.
Notitie
Wanneer u meerdere databases importeert, kunt u (i) één lakehouse per database maken (de methode die hier wordt gebruikt), of (ii) alle tabellen van verschillende databases verplaatsen naar één lakehouse. Voor deze laatste kunnen alle gemigreerde tabellen zijn <lakehouse>.<db_name>_<table_name>en moet u het importnotebook dienovereenkomstig aanpassen.
Stap 3: Inhoud valideren
In stap 3 valideert u of de metagegevens zijn gemigreerd. Bekijk verschillende voorbeelden.
U kunt de geïmporteerde databases zien door het volgende uit te voeren:
%%sql
SHOW DATABASES
U kunt alle tabellen in een lakehouse (database) controleren door het volgende uit te voeren:
%%sql
SHOW TABLES IN <lakehouse_name>
U kunt de details van een bepaalde tabel bekijken door het volgende uit te voeren:
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
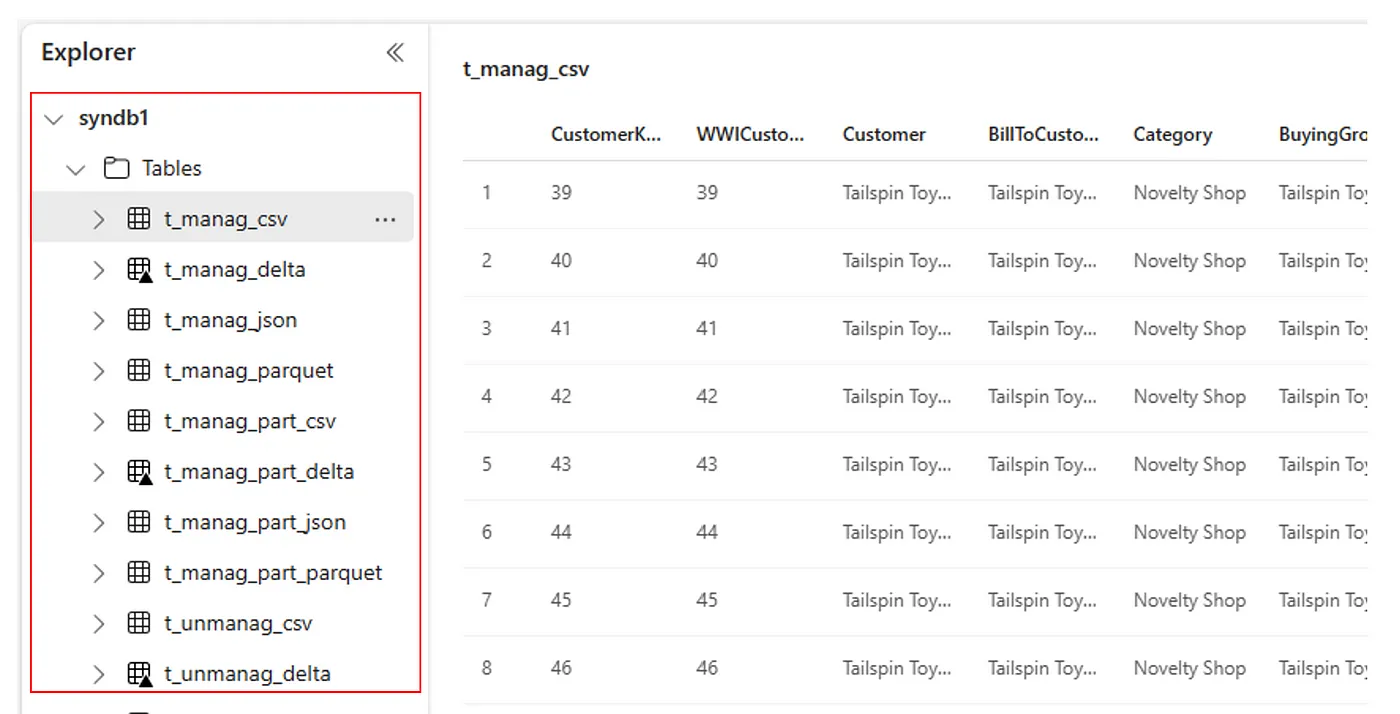
U kunt ook alle geïmporteerde tabellen zien in de sectie UI-tabellen van Lakehouse Explorer voor elk lakehouse.
Andere overwegingen
- Schaalbaarheid: de oplossing die hier gebruikmaakt van de interne Spark-catalogus-API om import/export uit te voeren, maar er wordt niet rechtstreeks verbinding gemaakt met HMS om catalogusobjecten op te halen, zodat de oplossing niet goed kan worden geschaald als de catalogus groot is. U moet de exportlogica wijzigen met HMS DB.
- Gegevensnauwkeurigheid: er is geen isolatiegarantie, wat betekent dat als de Spark-berekeningsengine gelijktijdige wijzigingen aan de metastore uitvoert terwijl het migratienotebook wordt uitgevoerd, inconsistente gegevens kunnen worden geïntroduceerd in Fabric Lakehouse.
Gerelateerde inhoud
- Fabric versus Azure Synapse Spark
- Meer informatie over migratieopties voor Spark-pools, configuraties, bibliotheken, notebooks en Spark-taakdefinitie