Rapportage over facturering en gebruik voor Apache Spark in Microsoft Fabric
Van toepassing op:✅ Data-engineer ing en Datawetenschap in Microsoft Fabric
In dit artikel wordt het rekengebruik en de rapportage voor ApacheSpark uitgelegd die de Infrastructuur-Data-engineer ing- en Wetenschapsworkloads in Microsoft Fabric mogelijk maakt. Het rekengebruik omvat lakehouse-bewerkingen zoals tabelvoorbeelden, belasting naar delta, notebookuitvoeringen vanaf de interface, geplande uitvoeringen, uitvoeringen die worden geactiveerd door notebookstappen in de pijplijnen en Uitvoeringen van Apache Spark-taken.
Net als bij andere ervaringen in Microsoft Fabric gebruikt Data-engineer ing ook de capaciteit die is gekoppeld aan een werkruimte om deze taak uit te voeren en worden uw totale capaciteitskosten weergegeven in Azure Portal onder uw Microsoft Cost Management-abonnement. Zie Inzicht in uw Azure-factuur in een infrastructuurcapaciteit voor meer informatie over infrastructuurfacturering.
Infrastructuurcapaciteit
U kunt als gebruiker een Fabric-capaciteit aanschaffen bij Azure door een Azure-abonnement op te geven. De grootte van de capaciteit bepaalt de hoeveelheid rekenkracht die beschikbaar is. Voor Apache Spark for Fabric vertaalt elke aangeschafte CU zich in 2 Apache Spark VCores. Als u bijvoorbeeld een Infrastructuurcapaciteit F128 koopt, wordt dit omgezet in 256 SparkVCores. Een infrastructuurcapaciteit wordt gedeeld in alle werkruimten die eraan zijn toegevoegd en waarin het totale aantal toegestane Apache Spark-berekeningen wordt gedeeld over alle taken die zijn verzonden vanuit alle werkruimten die aan een capaciteit zijn gekoppeld. Zie Gelijktijdigheidslimieten en wachtrijen in Apache Spark voor Microsoft Fabric voor meer informatie over de verschillende SKU's, kerntoewijzing en beperking in Spark.
Spark-rekenconfiguratie en aangeschafte capaciteit
Apache Spark Compute for Fabric biedt twee opties als het gaat om de rekenconfiguratie.
Starterspools: deze standaardgroepen zijn binnen enkele seconden snel en eenvoudig om Spark te gebruiken op het Microsoft Fabric-platform. U kunt Spark-sessies meteen gebruiken, in plaats van te wachten tot Spark de knooppunten voor u instelt, zodat u meer kunt doen met gegevens en sneller inzichten krijgt. Als het gaat om facturering en capaciteitsverbruik, worden er kosten in rekening gebracht wanneer u begint met het uitvoeren van uw notebook- of Spark-taakdefinitie of lakehouse-bewerking. Er worden geen kosten in rekening gebracht voor het moment dat de clusters inactief zijn in de pool.
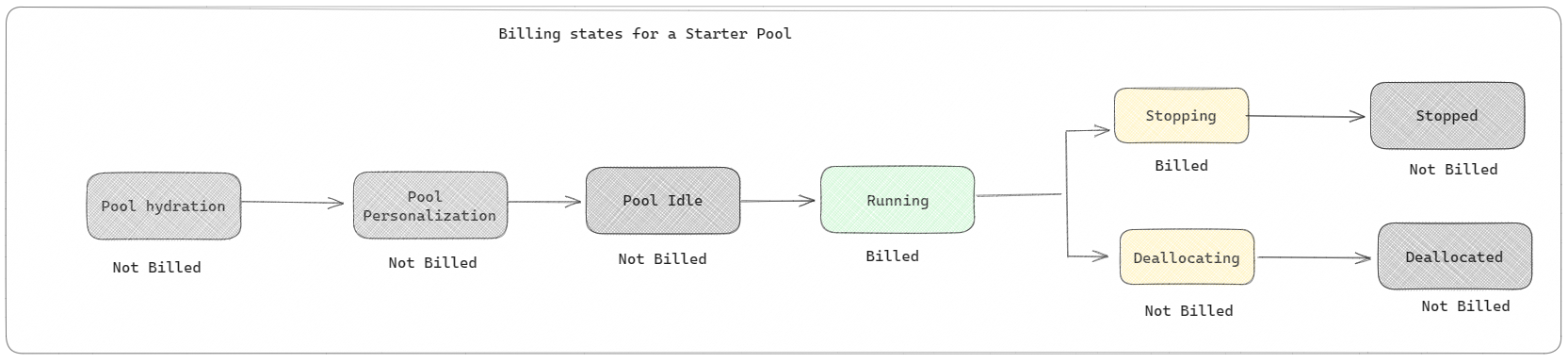
Als u bijvoorbeeld een notebooktaak naar een starterspool verzendt, wordt u alleen gefactureerd voor de periode waarin de notebooksessie actief is. De gefactureerde tijd bevat niet de niet-actieve tijd of de tijd die nodig is om de sessie aan te passen met de Spark-context. Voor meer informatie over het configureren van Starter-pools op basis van de aangeschafte Fabric Capacity SKU gaat u naar Starter-pools configureren op basis van infrastructuurcapaciteit
Spark-pools: dit zijn aangepaste pools, waar u kunt aanpassen welke grootte van resources u nodig hebt voor uw gegevensanalysetaken. U kunt uw Spark-pool een naam geven en kiezen hoeveel en hoe groot de knooppunten (de computers die het werk uitvoeren) zijn. U kunt spark ook laten weten hoe u het aantal knooppunten kunt aanpassen, afhankelijk van hoeveel werk u hebt. Het maken van een Spark-pool is gratis; u betaalt alleen wanneer u een Spark-taak uitvoert in de pool en vervolgens worden de knooppunten voor u ingesteld.
- De grootte en het aantal knooppunten dat u in uw aangepaste Spark-pool kunt hebben, is afhankelijk van uw Microsoft Fabric-capaciteit. U kunt deze Spark VCores gebruiken om knooppunten van verschillende grootten te maken voor uw aangepaste Spark-pool, zolang het totale aantal Spark-VCores niet groter is dan 128.
- Spark-pools worden gefactureerd als starterspools; u betaalt niet voor de aangepaste Spark-pools die u hebt gemaakt, tenzij u een actieve Spark-sessie hebt gemaakt voor het uitvoeren van een notebook of Spark-taakdefinitie. U wordt alleen gefactureerd voor de duur van de uitvoering van uw taak. U wordt niet gefactureerd voor fasen zoals het maken van het cluster en de toewijzing van de deal nadat de taak is voltooid.
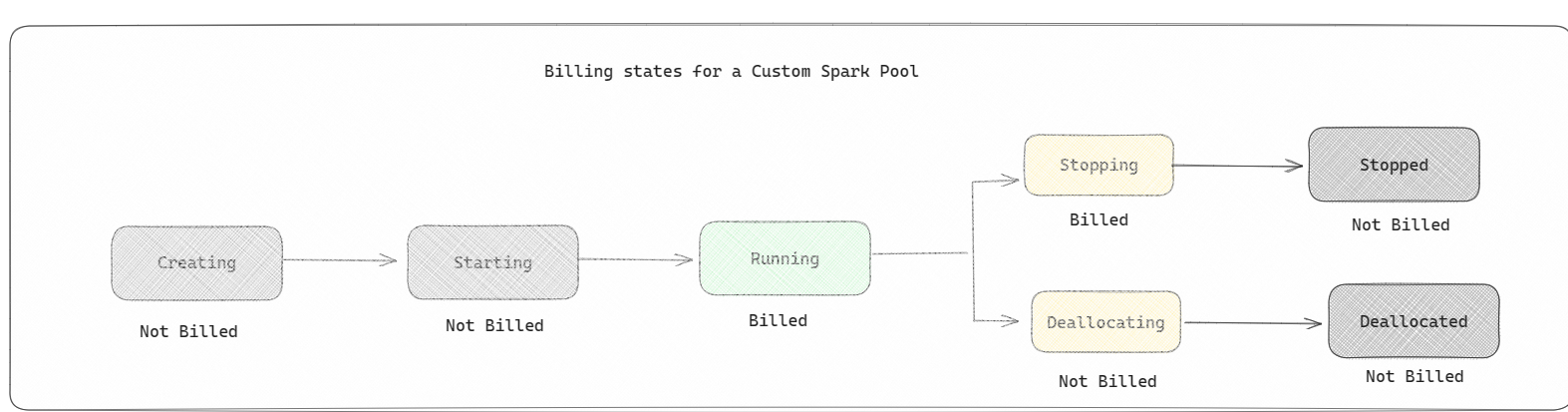
Als u bijvoorbeeld een notebooktaak verzendt naar een aangepaste Spark-pool, worden er alleen kosten in rekening gebracht voor de periode waarin de sessie actief is. De facturering voor die notebooksessie stopt zodra de Spark-sessie is gestopt of verlopen. Er worden geen kosten in rekening gebracht voor de tijd die nodig is om clusterexemplaren te verkrijgen uit de cloud of voor de tijd die nodig is voor het initialiseren van de Spark-context. Als u meer wilt weten over het configureren van Spark-pools op basis van de aangeschafte Fabric Capacity SKU, gaat u naar Pools configureren op basis van infrastructuurcapaciteit


Notitie
De standaardperiode voor het verlopen van de sessie voor de Starter-pools en Spark-pools die u maakt, is ingesteld op 20 minuten. Als u uw Spark-pool niet gedurende 2 minuten gebruikt nadat uw sessie is verlopen, wordt de toewijzing van uw Spark-pool ongedaan gemaakt. Als u de sessie en de facturering wilt stoppen nadat u de uitvoering van uw notitieblok vóór de verloopperiode van de sessie hebt voltooid, klikt u op de knop Sessie stoppen in het startmenu van notitieblokken of gaat u naar de pagina bewakingshub en stopt u de sessie daar.
Rapportage van Spark-rekengebruik
De microsoft Fabric Capacity Metrics-app biedt inzicht in het capaciteitsgebruik voor alle Fabric-workloads op één plaats. Het wordt gebruikt door capaciteitsbeheerders om de prestaties van workloads en hun gebruik te bewaken, vergeleken met aangeschafte capaciteit.
Nadat u de app hebt geïnstalleerd, selecteert u het itemtype Notebook, Lakehouse, Spark-taakdefinitie in de vervolgkeuzelijst Item selecteren. Het grafiekdiagram met meerdere metrische gegevens kan nu worden aangepast aan een gewenst tijdsbestek om inzicht te hebben in het gebruik van al deze geselecteerde items.
Alle Spark-gerelateerde bewerkingen worden geclassificeerd als achtergrondbewerkingen. Capaciteitsverbruik van Spark wordt weergegeven onder een notebook, een Spark-taakdefinitie of een lakehouse, en wordt geaggregeerd op basis van de naam en het item van de bewerking. Als u bijvoorbeeld een notebooktaak uitvoert, ziet u de uitvoering van het notebook, de CA's die door het notebook worden gebruikt (Totaal aantal Spark-VCores/2 als 1 CU 2 Spark-VCores geeft), de duur die de taak in het rapport heeft genomen.

Voorbeeld van facturering
Bekijk het volgende scenario:
Er is een Capaciteit C1 die als host fungeert voor een infrastructuurwerkruimte W1 en deze werkruimte bevat Lakehouse LH1 en Notebook NB1.
- Elke Spark-bewerking die door het notebook (NB1) of lakehouse (LH1) wordt uitgevoerd, wordt gerapporteerd aan de capaciteit C1.
Als u dit voorbeeld uitbreidt naar een scenario waarin er nog een Capaciteit C2 is die als host fungeert voor een infrastructuurwerkruimte W2 en laat u zeggen dat deze werkruimte een Spark-taakdefinitie (SJD1) en Lakehouse (LH2) bevat.
- Als de Spark-taakdefinitie (SDJ2) uit werkruimte (W2) gegevens uit Lakehouse (LH1) leest, wordt het gebruik gerapporteerd aan de Capaciteit C2 die is gekoppeld aan de werkruimte (W2) die als host fungeert voor het item.
- Als het notebook (NB1) een leesbewerking uitvoert vanuit Lakehouse (LH2), wordt het capaciteitsverbruik gerapporteerd aan de Capaciteit C1 die de werkruimte W1 aangeeft die als host fungeert voor het notebookitem.