Apache Spark-taakdefinities maken en beheren in Visual Studio Code
De Visual Studio (VS) Code-extensie voor Synapse ondersteunt de SPARK-taakdefinitiebewerkingen (maken, bijwerken, lezen en verwijderen) in Fabric. Nadat u een Spark-taakdefinitie hebt gemaakt, kunt u meer bibliotheken uploaden waarnaar wordt verwezen, een aanvraag indienen om de Spark-taakdefinitie uit te voeren en de uitvoeringsgeschiedenis te controleren.
Een Spark-taakdefinitie maken
Een nieuwe Spark-taakdefinitie maken:
Selecteer in VS Code Explorer de optie Spark-taakdefinitie maken.

Voer de initiële vereiste velden in: naam, naar lakehouse verwezen en standaard lakehouse.
De aanvraagprocessen en de naam van de zojuist gemaakte Spark-taakdefinitie worden weergegeven onder het hoofdknooppunt van de Spark-taakdefinitie in VS Code Explorer. Onder het naamknooppunt van de Spark-taakdefinitie ziet u drie subknooppunten:
- Bestanden: Lijst met het hoofddefinitiebestand en andere bibliotheken waarnaar wordt verwezen. U kunt nieuwe bestanden uploaden vanuit deze lijst.
- Lakehouse: Lijst met alle lakehouses waarnaar wordt verwezen door deze Spark-taakdefinitie. Het standaard lakehouse is gemarkeerd in de lijst en u kunt het openen via het relatieve pad
Files/…, Tables/…. - Uitvoeren: Lijst met de uitvoeringsgeschiedenis van deze Spark-taakdefinitie en de taakstatus van elke uitvoering.
Een hoofddefinitiebestand uploaden naar een bibliotheek waarnaar wordt verwezen
Als u het hoofddefinitiebestand wilt uploaden of overschrijven, selecteert u de optie Hoofdbestand toevoegen.
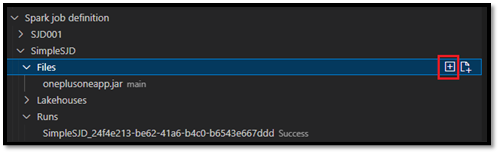
Als u het bibliotheekbestand wilt uploaden waarnaar het hoofddefinitiebestand verwijst, selecteert u de optie Lib-bestand toevoegen.
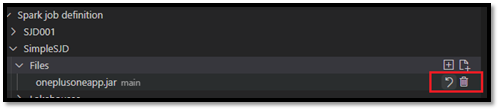
Nadat u een bestand hebt geüpload, kunt u het overschrijven door op de optie Bestand bijwerken te klikken en een nieuw bestand te uploaden, of u kunt het bestand verwijderen via de optie Verwijderen .
Een uitvoeringsaanvraag indienen
Een aanvraag indienen om de Spark-taakdefinitie uit te voeren vanuit VS Code:
Selecteer in de opties rechts van de naam van de Spark-taakdefinitie die u wilt uitvoeren de optie Spark-taak uitvoeren.

Nadat u de aanvraag hebt ingediend, wordt een nieuwe Apache Spark-toepassing weergegeven in het knooppunt Runs in de lijst Explorer. U kunt de actieve taak annuleren door de optie Spark-taak annuleren te selecteren.
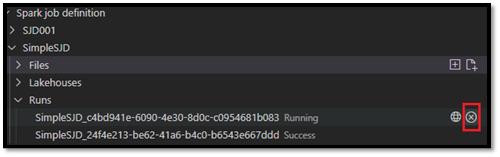
Een Spark-taakdefinitie openen in de Fabric-portal
U kunt de ontwerppagina van de Spark-taakdefinitie openen in de Fabric-portal door de optie Openen in browser te selecteren.
U kunt ook Openen in browser naast een voltooide uitvoering selecteren om de detailmonitorpagina van die uitvoering te bekijken.

Fouten opsporen in de broncode van de Spark-taakdefinitie (Python)
Als de Spark-taakdefinitie is gemaakt met PySpark (Python), kunt u het .py script van het hoofddefinitiebestand en het bestand waarnaar wordt verwezen, downloaden en fouten opsporen in het bronscript in VS Code.
Als u de broncode wilt downloaden, selecteert u de optie Debug Spark-taakdefinitie rechts van de Spark-taakdefinitie.

Nadat het downloaden is voltooid, wordt de map van de broncode automatisch geopend.
Selecteer de optie De auteurs vertrouwen wanneer hierom wordt gevraagd. (Deze optie wordt alleen weergegeven wanneer u de map de eerste keer opent. Als u deze optie niet selecteert, kunt u geen fouten opsporen of het bronscript uitvoeren. Zie De vertrouwensbeveiliging van Visual Studio Code Workspace Trust voor meer informatie.)
Als u de broncode eerder hebt gedownload, wordt u gevraagd om te bevestigen dat u de lokale versie wilt overschrijven met de nieuwe download.
Notitie
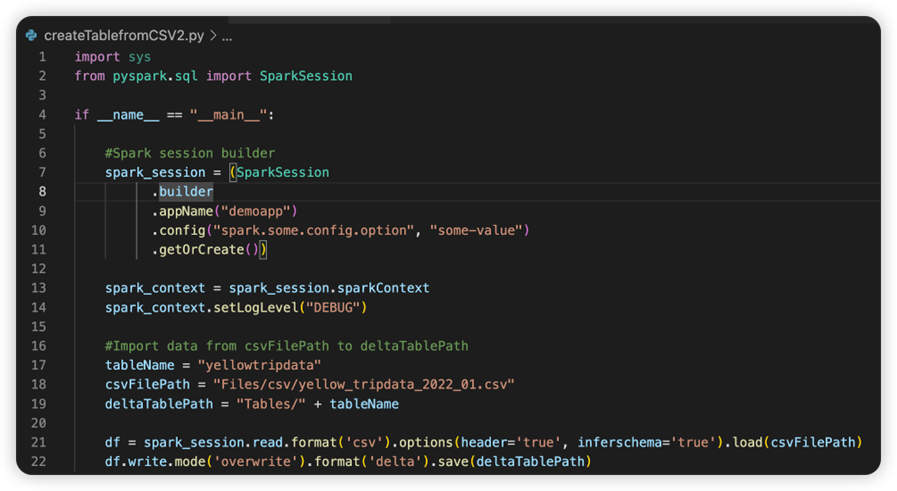
In de hoofdmap van het bronscript maakt het systeem een submap met de naam conf. In deze map bevat een bestand met de naam lighter-config.json enkele systeemmetagegevens die nodig zijn voor de externe uitvoering. Breng geen wijzigingen aan.
Het bestand met de naam sparkconf.py bevat een codefragment dat u moet toevoegen om het SparkConf-object in te stellen. Als u de externe foutopsporing wilt inschakelen, moet u ervoor zorgen dat het SparkConf-object juist is ingesteld. In de volgende afbeelding ziet u de oorspronkelijke versie van de broncode.
De volgende afbeelding is de bijgewerkte broncode nadat u het fragment hebt gekopieerd en geplakt.
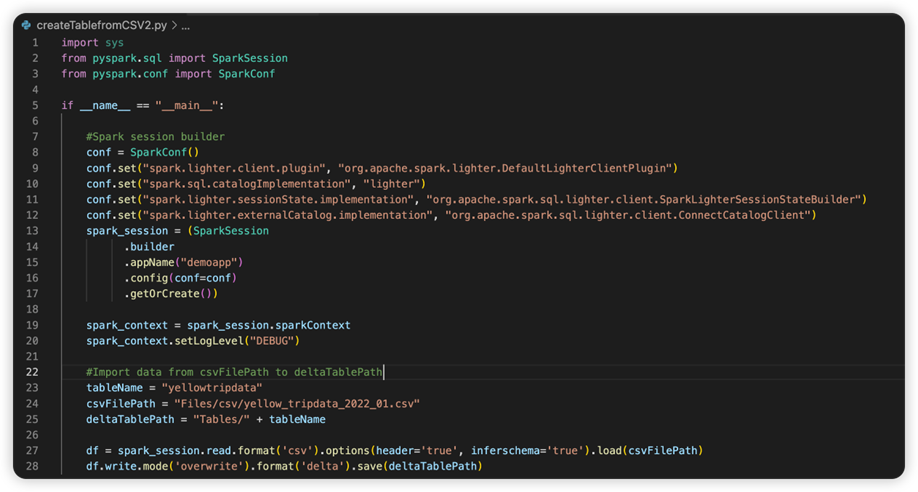
Nadat u de broncode hebt bijgewerkt met de benodigde conf, moet u de juiste Python-interpreter kiezen. Zorg ervoor dat u degene selecteert die is geïnstalleerd in de synapse-spark-kernel conda-omgeving.
Eigenschappen van Spark-taakdefinitie bewerken
U kunt de detaileigenschappen van Spark-taakdefinities bewerken, zoals opdrachtregelargumenten.
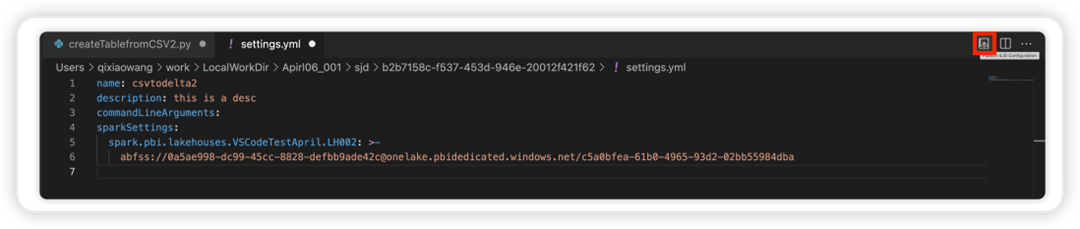
Selecteer de optie SJD-configuratie bijwerken om een settings.yml-bestand te openen. De bestaande eigenschappen vullen de inhoud van dit bestand in.
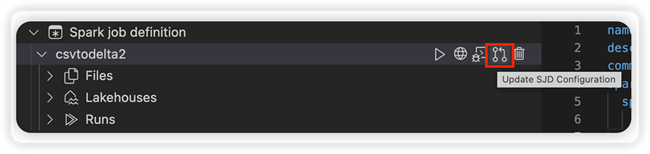
Werk het .yml-bestand bij en sla het op.
Selecteer de optie SJD-eigenschap publiceren in de rechterbovenhoek om de wijziging terug te synchroniseren naar de externe werkruimte.