Het proces voor implementatiepijplijnen
Met het implementatieproces kunt u inhoud klonen van de ene fase in de implementatiepijplijn naar een andere, meestal van ontwikkeling tot test en van test tot productie.
Tijdens de implementatie kopieert Microsoft Fabric de inhoud van de bronfase naar de doelfase. De verbindingen tussen de gekopieerde items worden bewaard tijdens het kopieerproces. Fabric past ook de geconfigureerde implementatieregels toe op de bijgewerkte inhoud in de doelfase. Het implementeren van inhoud kan enige tijd duren, afhankelijk van het aantal items dat wordt geïmplementeerd. Gedurende deze tijd kunt u naar andere pagina's in de portal navigeren, maar u kunt de inhoud niet gebruiken in de doelfase.
U kunt inhoud ook programmatisch implementeren met behulp van de REST API's voor implementatiepijplijnen. Meer informatie over dit proces vindt u in Uw implementatiepijplijn automatiseren met behulp van API's en DevOps.
Notitie
De nieuwe gebruikersinterface voor de implementatiepijplijn bevindt zich momenteel in preview-versie. Als u de nieuwe gebruikersinterface wilt inschakelen of gebruiken, raadpleegt u De nieuwe gebruikersinterfacegaan gebruiken.
Er zijn twee hoofdonderdelen van het implementatiepijplijnproces:
De structuur van de implementatiepijplijn definiëren
Wanneer u een pijplijn maakt, definieert u hoeveel fasen u wilt en wat ze moeten worden genoemd. U kunt ook een of meer fasen openbaar maken. Het aantal fasen en de bijbehorende namen is permanent en kan niet worden gewijzigd nadat de pijplijn is gemaakt. U kunt de openbare status van een fase echter op elk gewenst moment wijzigen.
Volg de instructies in Een implementatiepijplijn maken om een pijplijn te definiëren.
Inhoud toevoegen aan de fasen
U kunt op twee manieren inhoud toevoegen aan een pijplijnfase:
Een werkruimte toewijzen aan een lege fase
Wanneer u inhoud toewijst aan een lege fase, wordt er een nieuwe werkruimte gemaakt op een capaciteit voor de fase waarin u implementeert. Alle metagegevens in de rapporten, dashboards en semantische modellen van de oorspronkelijke werkruimte worden gekopieerd naar de nieuwe werkruimte in de fase waarin u implementeert.
Nadat de implementatie is voltooid, vernieuwt u de semantische modellen, zodat u de zojuist gekopieerde inhoud kunt gebruiken. Het vernieuwen van het semantische model is vereist omdat gegevens niet van de ene fase naar de andere worden gekopieerd. Als u wilt weten welke itemeigenschappen tijdens het implementatieproces worden gekopieerd en welke itemeigenschappen niet worden gekopieerd, controleert u de itemeigenschappen die tijdens de implementatiesectie zijn gekopieerd.
Zie Een werkruimte toewijzen aan een Microsoft Fabric-implementatiepijplijnpijplijn voor instructies voor het toewijzen en intrekken van werkruimten.
Een werkruimte maken
De eerste keer dat u inhoud implementeert, controleert implementatiepijplijnen of u machtigingen hebt.
Als u machtigingen hebt, wordt de inhoud van de werkruimte gekopieerd naar de fase waarnaar u implementeert en wordt er een nieuwe werkruimte voor die fase gemaakt op de capaciteit.
Als u geen machtigingen hebt, wordt de werkruimte gemaakt, maar wordt de inhoud niet gekopieerd. U kunt een capaciteitsbeheerder vragen om uw werkruimte toe te voegen aan een capaciteit of om toewijzingsmachtigingen voor de capaciteit vragen. Wanneer de werkruimte later is toegewezen aan een capaciteit, kunt u inhoud implementeren in deze werkruimte.
Als u PPU (Premium Per User) gebruikt, wordt uw werkruimte automatisch gekoppeld aan uw PPU. In dergelijke gevallen zijn geen machtigingen vereist. Als u echter een werkruimte met een PPU maakt, hebben alleen andere PPU-gebruikers er toegang toe. Daarnaast kunnen alleen PPU-gebruikers inhoud gebruiken die in dergelijke werkruimten is gemaakt.
Eigendom van werkruimte en inhoud
De implementerende gebruiker wordt automatisch de eigenaar van de gekloonde semantische modellen en de enige beheerder van de nieuwe werkruimte.
Inhoud van de ene fase naar de andere implementeren
Er zijn verschillende manieren om inhoud van de ene fase naar de andere te implementeren. U kunt alle inhoud implementeren of u kunt selecteren welke items u wilt implementeren.
U kunt inhoud in elke aangrenzende fase implementeren, in beide richtingen.
Het implementeren van inhoud van een werkende productiepijplijn naar een fase met een bestaande werkruimte omvat de volgende stappen:
Nieuwe inhoud implementeren als aanvulling op de inhoud die daar al aanwezig is.
Bijgewerkte inhoud implementeren om een deel van de inhoud te vervangen.
Implementatieproces
Wanneer inhoud uit de bronfase naar de doelfase wordt gekopieerd, identificeert Fabric bestaande inhoud in de doelfase en overschrijft deze. Om te bepalen welk inhoudsitem moet worden overschreven, maken implementatiepijplijnen gebruik van de verbinding tussen het bovenliggende item en de bijbehorende klonen. Deze verbinding wordt bewaard wanneer er nieuwe inhoud wordt gemaakt. De overschrijfbewerking overschrijft alleen de inhoud van het item. De id, URL en machtigingen van het item blijven ongewijzigd.
In de doelfase blijven itemeigenschappen die niet worden gekopieerd, ongewijzigd als vóór de implementatie. Nieuwe inhoud en nieuwe items worden gekopieerd van de bronfase naar de doelfase.
Automatisch binden
Wanneer items zijn verbonden in Fabric, is een van de items afhankelijk van de andere. Een rapport is bijvoorbeeld altijd afhankelijk van het semantische model waaraan het is gekoppeld. Een semantisch model kan afhankelijk zijn van een ander semantisch model en kan ook worden verbonden met verschillende rapporten die ervan afhankelijk zijn. Als er een verbinding tussen twee items is, proberen implementatiepijplijnen altijd deze verbinding te onderhouden.
Automatisch verbinden in dezelfde werkruimte
Tijdens de implementatie controleert implementatiepijplijnen op afhankelijkheden. De implementatie slaagt of mislukt, afhankelijk van de locatie van het item dat de gegevens levert waarvan het geïmplementeerde item afhankelijk is.
Gekoppeld item bestaat in de doelfase : implementatiepijplijnen verbinden het geïmplementeerde item automatisch (automatisch koppelen) aan het item dat het afhankelijk is in de geïmplementeerde fase. Als u bijvoorbeeld een gepagineerd rapport implementeert van ontwikkeling naar test en het rapport is verbonden met een semantisch model dat eerder in de testfase is geïmplementeerd, maakt het automatisch verbinding met het semantische model in de testfase.
Gekoppeld item bestaat niet in de doelfase : implementatiepijplijnen mislukken een implementatie als een item afhankelijk is van een ander item en het item dat de gegevens opgeeft, niet is geïmplementeerd en zich niet in de doelfase bevindt. Als u bijvoorbeeld een rapport implementeert van ontwikkeling naar test en de testfase het semantische model niet bevat, mislukt de implementatie. Gebruik de knop Gerelateerde items selecteren om mislukte implementaties te voorkomen omdat afhankelijke items niet worden geïmplementeerd. Als u gerelateerde items selecteert, worden automatisch alle gerelateerde items geselecteerd die afhankelijkheden bieden voor de items die u gaat implementeren.
Autobinding werkt alleen met items die worden ondersteund door implementatiepijplijnen en zich in Fabric bevinden. Als u de afhankelijkheden van een item wilt weergeven, selecteert u in het menu Meer opties van het item de optie Herkomst weergeven.
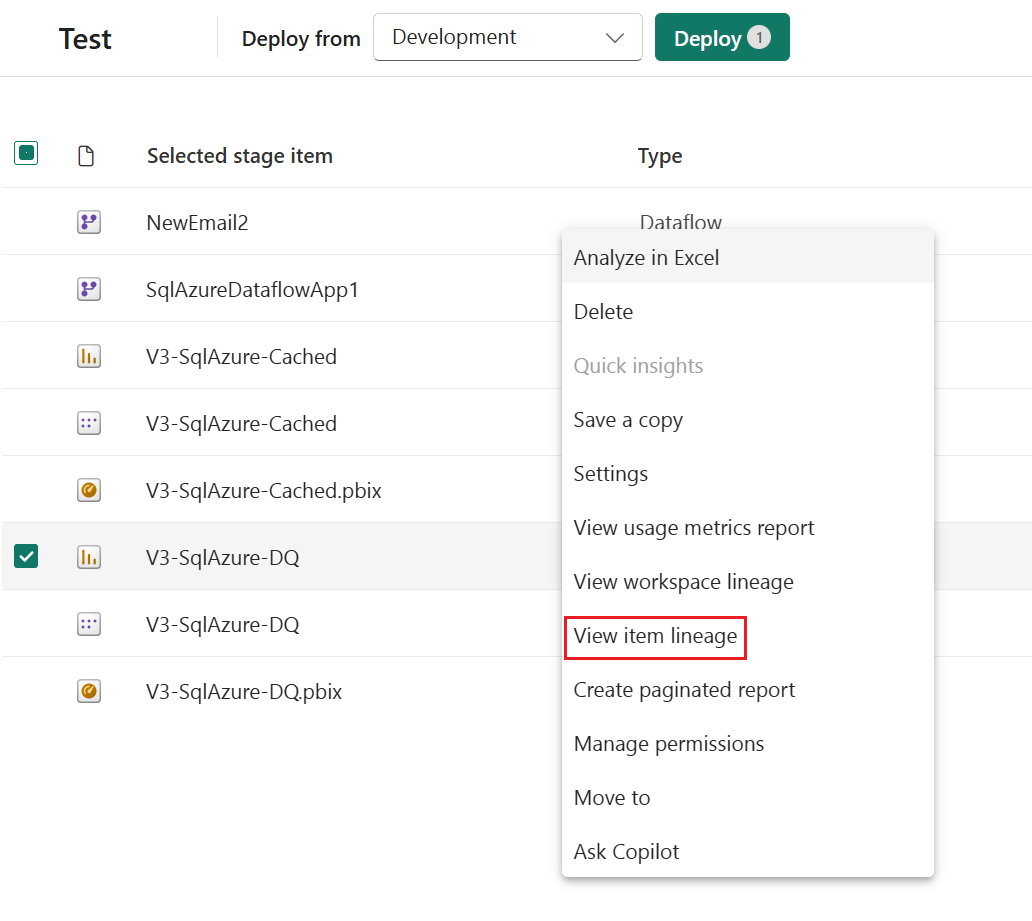
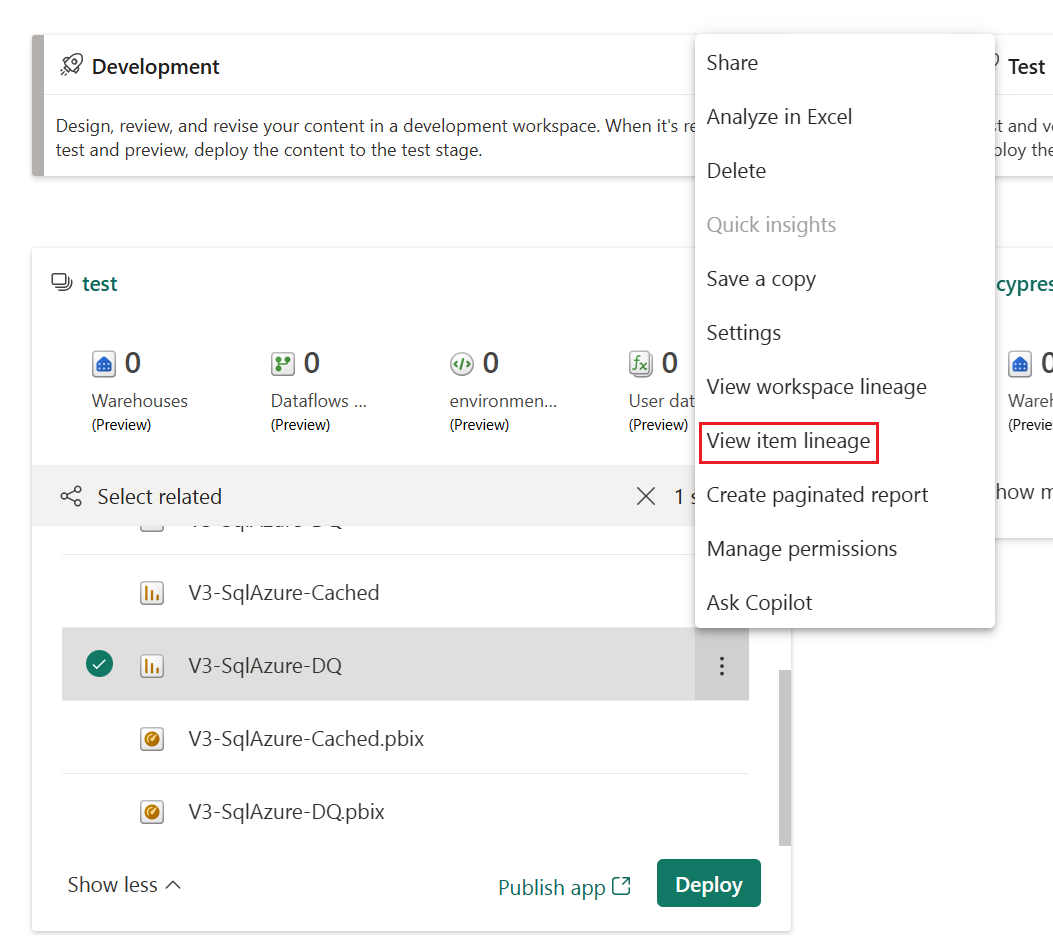
Automatisch verbinden tussen werkruimten
Met implementatiepijplijnen worden items die zijn verbonden via pijplijnen automatisch gekoppeld als ze zich in dezelfde pijplijnfase bevinden. Wanneer u dergelijke items implementeert, proberen implementatiepijplijnen een nieuwe verbinding tot stand te brengen tussen het geïmplementeerde item en het item waarmee het is verbonden in de andere pijplijn. Als u bijvoorbeeld een rapport hebt in de testfase van pijplijn A die is verbonden met een semantisch model in de testfase van pijplijn B, herkent implementatiepijplijnen deze verbinding.
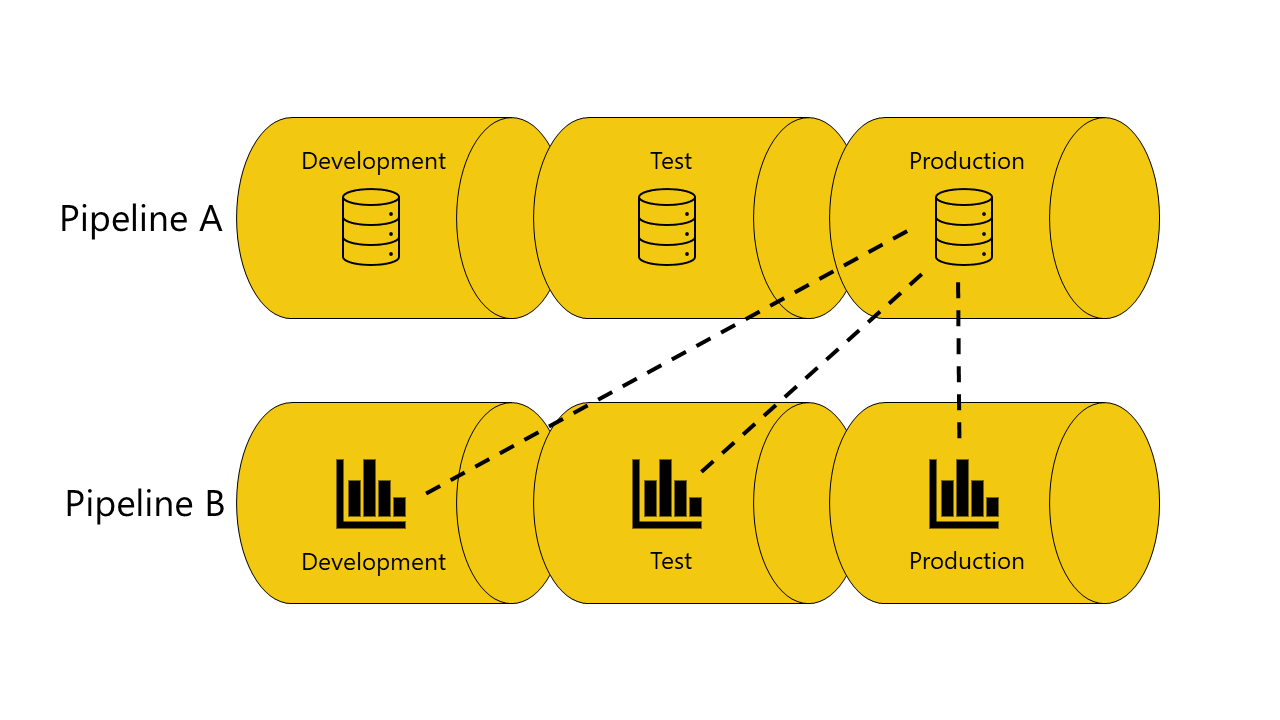
Hier volgt een voorbeeld met illustraties waarmee u kunt laten zien hoe automatisch verbinden tussen pijplijnen werkt:
U hebt een semantisch model in de ontwikkelingsfase van pijplijn A.
U hebt ook een rapport in de ontwikkelingsfase van pijplijn B.
Uw rapport in pijplijn B is verbonden met uw semantische model in pijplijn A. Uw rapport is afhankelijk van dit semantische model.
U implementeert het rapport in pijplijn B vanuit de ontwikkelingsfase naar de testfase.
De implementatie slaagt of mislukt, afhankelijk van of u een kopie van het semantische model hebt waarvan het afhankelijk is in de testfase van pijplijn A:
Als u een kopie van het semantische model hebt, is het rapport afhankelijk van in de testfase van pijplijn A:
De implementatie slaagt en implementatiepijplijnen verbinden (automatisch koppelen) het rapport in de testfase van pijplijn B met het semantische model in de testfase van pijplijn A.
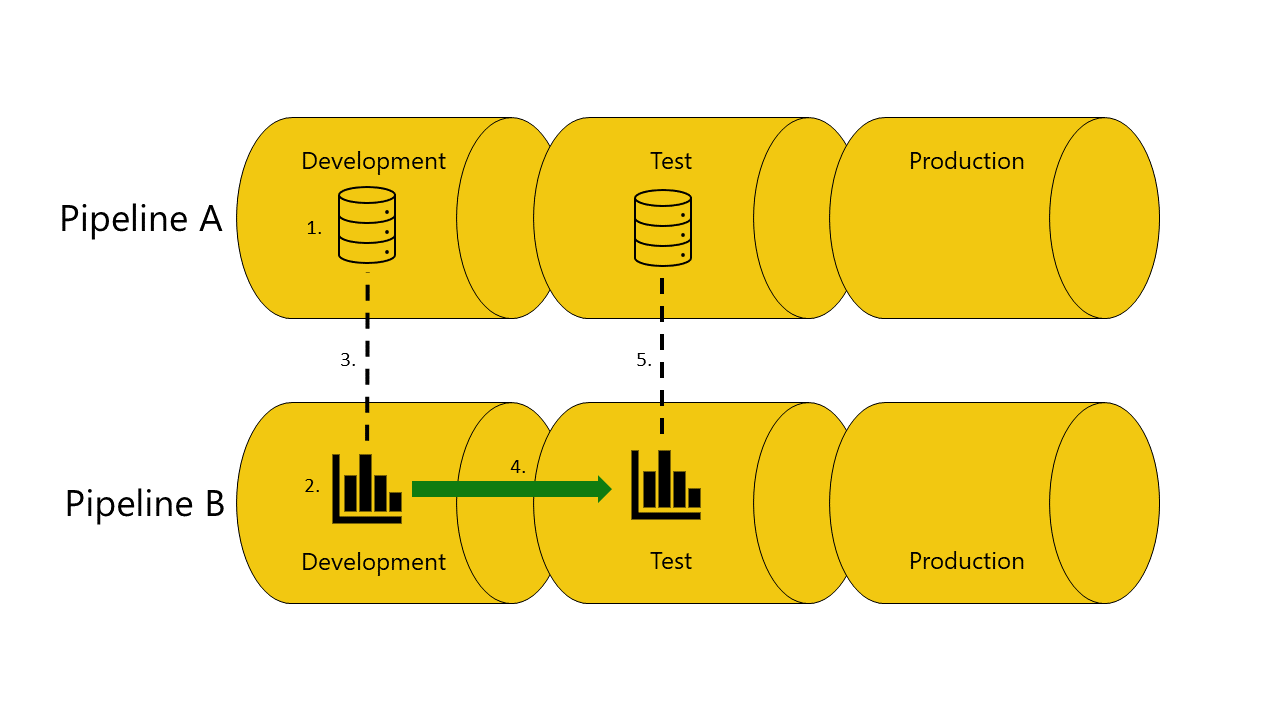
Als u geen kopie van het semantische model hebt, is het rapport afhankelijk van in de testfase van pijplijn A:
De implementatie mislukt omdat implementatiepijplijnen het rapport in de testfase in pijplijn B niet kunnen verbinden (autobind) met het semantische model waarvan het afhankelijk is in de testfase van pijplijn A.
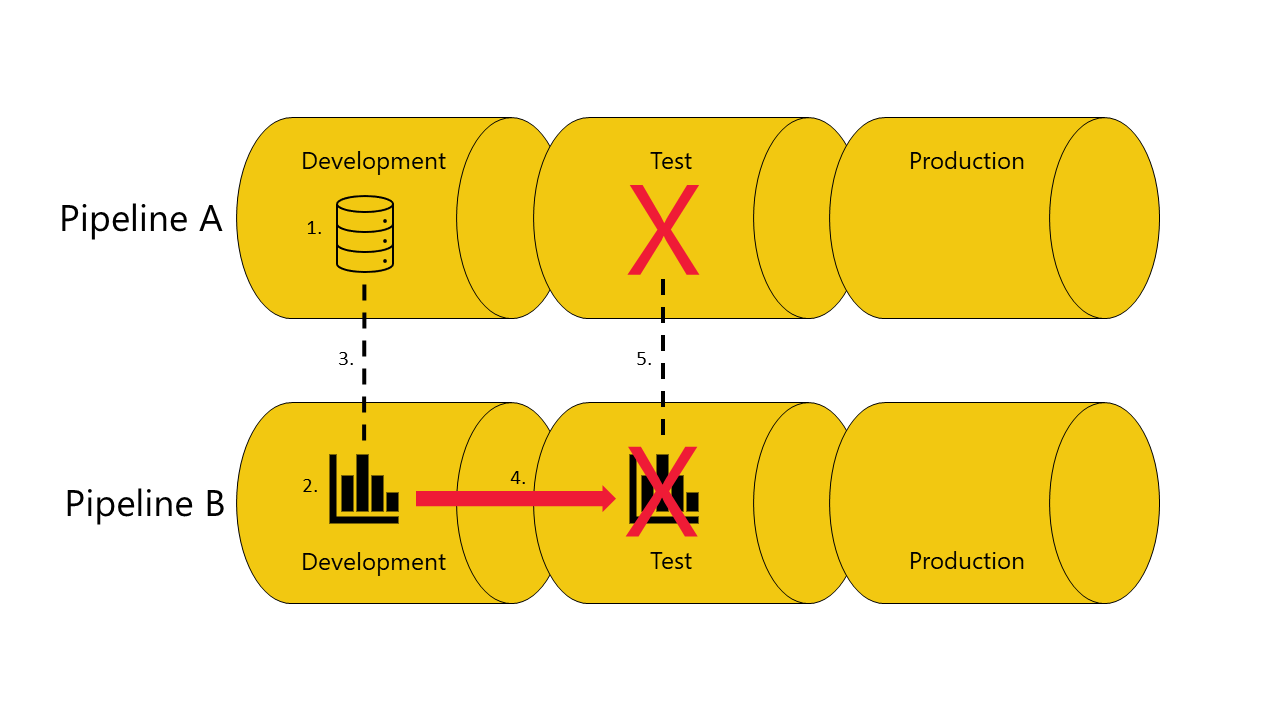
Vermijd het gebruik van automatisch verbinden
In sommige gevallen wilt u mogelijk geen automatische binding gebruiken. Als u bijvoorbeeld één pijplijn hebt voor het ontwikkelen van semantische organisatiemodellen en een andere voor het maken van rapporten. In dit geval wilt u mogelijk dat alle rapporten altijd zijn verbonden met semantische modellen in de productiefase van de pijplijn waartoe ze behoren. Vermijd in dit geval het gebruik van de functie voor automatisch verbinden.
Er zijn drie methoden die u kunt gebruiken om automatisch verbinden te voorkomen:
Verbind het item niet met de bijbehorende fasen. Wanneer de items niet in dezelfde fase zijn verbonden, behouden implementatiepijplijnen de oorspronkelijke verbinding. Als u bijvoorbeeld een rapport hebt in de ontwikkelingsfase van pijplijn B die is verbonden met een semantisch model in de productiefase van pijplijn A. Wanneer u het rapport implementeert in de testfase van pijplijn B, blijft het verbonden met het semantische model in de productiefase van pijplijn A.
Definieer een parameterregel. Deze optie is niet beschikbaar voor rapporten. U kunt deze alleen gebruiken met semantische modellen en gegevensstromen.
Verbind uw rapporten, dashboards en tegels met een semantisch proxymodel of een gegevensstroom die niet is verbonden met een pijplijn.
Automatisch verbinden en parameters
Parameters kunnen worden gebruikt om de verbindingen tussen semantische modellen of gegevensstromen en de items waarop ze afhankelijk zijn te beheren. Wanneer een parameter de verbinding bepaalt, wordt automatisch verbinden na de implementatie niet uitgevoerd, zelfs niet wanneer de verbinding een parameter bevat die van toepassing is op de id van het semantische model of de gegevensstroom, of de werkruimte-id. In dergelijke gevallen moet u de items na de implementatie opnieuw koppelen door de parameterwaarde te wijzigen of door parameterregels te gebruiken.
Notitie
Als u parameterregels gebruikt om items opnieuw te koppelen, moeten de parameters van het type Textzijn.
Gegevens vernieuwen
Gegevens in het doelitem, zoals een semantisch model of gegevensstroom, worden indien mogelijk bewaard. Als er geen wijzigingen zijn in een item dat de gegevens bevat, worden de gegevens bewaard zoals deze vóór de implementatie waren.
In veel gevallen, wanneer u een kleine wijziging hebt, zoals het toevoegen of verwijderen van een tabel, bewaart Fabric de oorspronkelijke gegevens. Voor belangrijke schemawijzigingen of wijzigingen in de gegevensbronverbinding is een volledige vernieuwing vereist.
Vereisten voor het implementeren in een fase met een bestaande werkruimte
Elke gelicentieerde gebruiker die een inzender is van zowel de doelwerkruimte als de bronimplementatiewerkruimte, kan inhoud implementeren die zich in een capaciteit bevindt in een fase met een bestaande werkruimte. Raadpleeg de sectie machtigingen voor meer informatie.
Mappen in implementatiepijplijnen (preview)
Met mappen kunnen gebruikers werkruimte-items op een efficiënte manier ordenen en beheren. Wanneer u inhoud implementeert die mappen bevat in een andere fase, wordt de maphiërarchie van de toegepaste items automatisch toegepast.
Mappenweergave
- Nieuwe gebruikersinterface voor mappenweergave
- Oorspronkelijke gebruikersinterface voor mappenweergave
De inhoud van de werkruimte wordt weergegeven omdat deze is gestructureerd in de werkruimte. Mappen worden weergegeven en om de items te zien die u nodig hebt om de map te selecteren. Het volledige pad van een item wordt boven aan de lijst met items weergegeven. Omdat een implementatie alleen van items is, kunt u alleen een map selecteren die ondersteunde items bevat. Als u een map voor implementatie selecteert, worden alle items en submappen geselecteerd met hun items voor een implementatie.
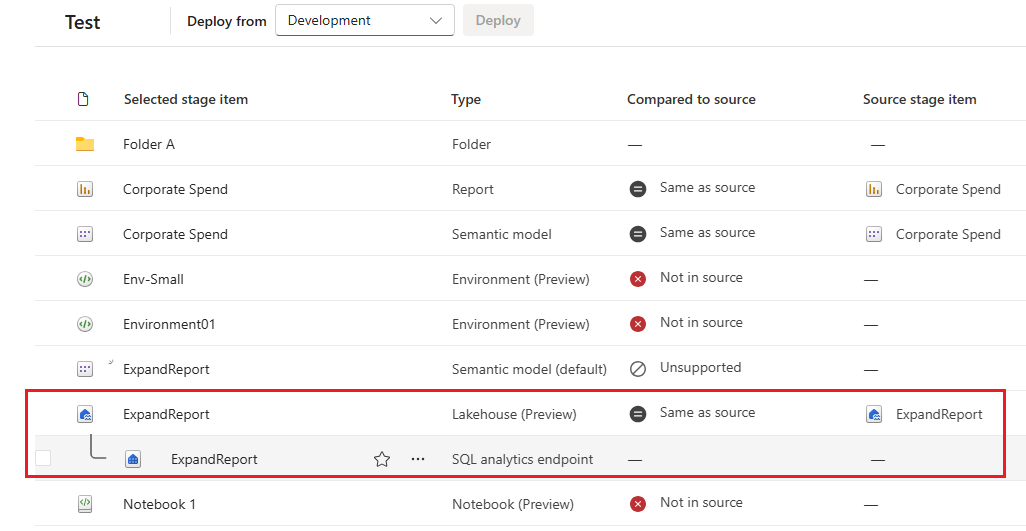
In deze afbeelding ziet u de inhoud van een map in de werkruimte. De volledige padnaam van de map wordt boven aan de lijst weergegeven.
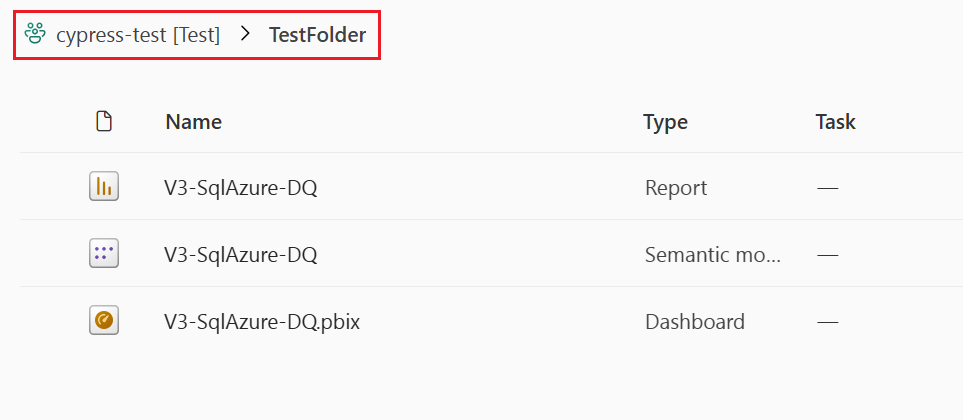
In implementatiepijplijnen worden mappen beschouwd als onderdeel van de naam van een item (een itemnaam bevat het volledige pad). Wanneer een item is geïmplementeerd, nadat het pad is gewijzigd (bijvoorbeeld verplaatst van map A naar map B), past de implementatiepijplijn deze wijziging toe op het gekoppelde item tijdens de implementatie. Als gevolg daarvan wordt het gekoppelde item ook naar map B verplaatst. Als map B niet bestaat in de fase waarin we implementeren, wordt deze eerst in de werkruimte aangemaakt. Mappen kunnen alleen worden weergegeven en beheerd op de werkruimtepagina.
Items in een map uit die map implementeren. U kunt items uit verschillende hiërarchieën niet tegelijkertijd implementeren.
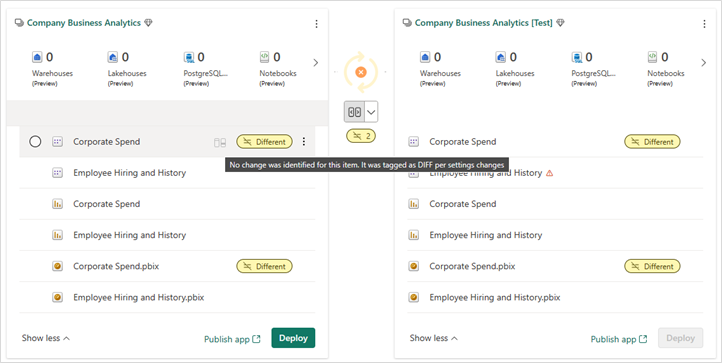
Items identificeren die naar verschillende mappen zijn verplaatst
Omdat mappen worden beschouwd als onderdeel van de naam van het item, worden items die zijn verplaatst naar een andere map in de werkruimte, geïdentificeerd op de pagina Implementatiepijplijnen als Verschillend in vergelijking. Dit item wordt niet weergegeven in het vergelijkingsvenster omdat het geen schemawijziging is, maar instellingen worden gewijzigd.
- Verplaatst mapitem in nieuwe gebruikersinterface
- Verplaatst mapitem in de oorspronkelijke gebruikersinterface

Afzonderlijke mappen kunnen niet handmatig worden geïmplementeerd in implementatiepijplijnen. De implementatie wordt automatisch geactiveerd wanneer ten minste één van de items wordt geïmplementeerd.
De maphiërarchie van gekoppelde items wordt alleen bijgewerkt tijdens de implementatie. Tijdens de toewijzing wordt de hiërarchie van gekoppelde items na het koppelingsproces nog niet bijgewerkt.
Omdat een map alleen wordt geïmplementeerd als een van de items is geïmplementeerd, kan er geen lege map worden geïmplementeerd.
Als u één item uit meerdere items in een map implementeert, wordt ook de structuur bijgewerkt van de items die niet zijn geïmplementeerd in de doelfase, ook al worden de items zelf niet geïmplementeerd.
Weergave van bovenliggend/onderliggend item
Deze worden alleen weergegeven in de nieuwe gebruikersinterface. Ziet er hetzelfde uit als in de werkruimte. Onderliggend element wordt niet geïmplementeerd, maar opnieuw gemaakt in de doelfase
Itemeigenschappen die tijdens de implementatie zijn gekopieerd
Zie Ondersteunde items voor implementatiepijplijnen voor een lijst met ondersteunde items.
Tijdens de implementatie worden de volgende itemeigenschappen gekopieerd en overschreven in de doelfase:
Gegevensbronnen (implementatieregels worden ondersteund)
Parameters (implementatieregels worden ondersteund)
Rapportvisuals
Rapportpagina's
Dashboardtegels
Modelmetagegevens
Itemrelaties
Vertrouwelijkheidslabels worden alleen gekopieerd wanneer aan een van de volgende voorwaarden wordt voldaan. Als niet aan deze voorwaarden wordt voldaan, worden vertrouwelijkheidslabels niet gekopieerd tijdens de implementatie.
Er wordt een nieuw item geïmplementeerd of een bestaand item wordt geïmplementeerd in een lege fase.
Notitie
In gevallen waarin standaardlabels zijn ingeschakeld op de tenant en het standaardlabel geldig is, als het item dat wordt geïmplementeerd een semantisch model of gegevensstroom is, wordt het label gekopieerd uit het bronitem alleen als het label beveiliging heeft. Als het label niet is beveiligd, wordt het standaardlabel toegepast op het zojuist gemaakte semantische doelmodel of gegevensstroom.
Het bronitem heeft een label met beveiliging en het doelitem niet. In dit geval vraagt een pop-upvenster om toestemming om het doelgevoeligheidslabel te overschrijven.
Itemeigenschappen die niet worden gekopieerd
De volgende itemeigenschappen worden niet gekopieerd tijdens de implementatie:
Gegevens - Gegevens worden niet gekopieerd. Alleen metagegevens worden gekopieerd
URL
Id
Machtigingen : voor een werkruimte of een specifiek item
Werkruimte-instellingen : elke fase heeft een eigen werkruimte
App-inhoud en -instellingen : zie Inhoud bijwerken naar Power BI-apps om uw apps bij te werken
De volgende semantische modeleigenschappen worden ook niet gekopieerd tijdens de implementatie:
Roltoewijzing
Planning vernieuwen
Gegevensbronreferenties
Cache-instellingen voor query's (kunnen worden overgenomen van de capaciteit)
Goedkeuringsinstellingen
Ondersteunde semantische modelfuncties
Implementatiepijplijnen ondersteunen veel semantische modelfuncties. In deze sectie vindt u twee semantische modelfuncties waarmee u uw implementatiepijplijnen kunt verbeteren:
Incrementele vernieuwing
Implementatiepijplijnen ondersteunen incrementeel vernieuwen, een functie waarmee grote semantische modellen sneller en betrouwbaarder kunnen worden vernieuwd, met een lager verbruik.
Met implementatiepijplijnen kunt u updates aanbrengen in een semantisch model met incrementele vernieuwing en tegelijkertijd gegevens en partities behouden. Wanneer u het semantische model implementeert, wordt het beleid samen gekopieerd.
Als u wilt weten hoe incrementeel vernieuwen zich gedraagt met gegevensstromen, raadpleegt u waarom zie ik twee gegevensbronnen die zijn verbonden met mijn gegevensstroom nadat ik gegevensstroomregels hebt gebruikt?
Notitie
Instellingen voor incrementeel vernieuwen worden niet gekopieerd in Gen 1.
Incrementeel vernieuwen activeren in een pijplijn
Als u incrementeel vernieuwen wilt inschakelen, configureert u het in Power BI Desktop en publiceert u vervolgens uw semantische model. Nadat u het beleid voor incrementeel vernieuwen hebt gepubliceerd, is het vergelijkbaar met de pijplijn en kan het alleen worden gemaakt in Power BI Desktop.
Zodra uw pijplijn is geconfigureerd met incrementeel vernieuwen, wordt u aangeraden de volgende stroom te gebruiken:
Breng wijzigingen aan in uw PBIX-bestand in Power BI Desktop. Als u lange wachttijden wilt voorkomen, kunt u wijzigingen aanbrengen met behulp van een voorbeeld van uw gegevens.
Upload uw PBIX-bestand naar de eerste fase (meestal ontwikkeling).
Implementeer uw inhoud in de volgende fase. Na de implementatie zijn de wijzigingen die u hebt aangebracht van toepassing op het hele semantische model dat u gebruikt.
Controleer de wijzigingen die u in elke fase hebt aangebracht en nadat u deze hebt gecontroleerd, implementeert u deze in de volgende fase totdat u bij de laatste fase bent.
Voorbeelden van gebruik
Hier volgen enkele voorbeelden van hoe u incrementeel vernieuwen kunt integreren met implementatiepijplijnen.
Maak een nieuwe pijplijn en verbind deze met een werkruimte met een semantisch model waarvoor incrementeel vernieuwen is ingeschakeld.
Schakel incrementeel vernieuwen in een semantisch model in dat zich al in een ontwikkelwerkruimte bevindt .
Maak een pijplijn op basis van een productiewerkruimte met een semantisch model dat gebruikmaakt van incrementeel vernieuwen. Wijs bijvoorbeeld de werkruimte toe aan de productiefase van een nieuwe pijplijn en gebruik achterwaartse implementatie om te implementeren in de testfase en vervolgens naar de ontwikkelingsfase.
Publiceer een semantisch model dat gebruikmaakt van incrementeel vernieuwen naar een werkruimte die deel uitmaakt van een bestaande pijplijn.
Beperkingen voor incrementeel vernieuwen
Voor incrementeel vernieuwen ondersteunen implementatiepijplijnen alleen semantische modellen die gebruikmaken van verbeterde metagegevens van het semantische model. Alle semantische modellen die zijn gemaakt of gewijzigd met Power BI Desktop, implementeren automatisch verbeterde metagegevens van het semantische model.
Wanneer u een semantisch model opnieuw publiceert naar een actieve pijplijn waarvoor incrementeel vernieuwen is ingeschakeld, resulteren de volgende wijzigingen in een implementatiefout vanwege mogelijk gegevensverlies:
Een semantisch model dat geen incrementeel vernieuwen gebruikt, opnieuw publiceren om een semantisch model te vervangen waarvoor incrementeel vernieuwen is ingeschakeld.
Wijzig de naam van een tabel waarvoor incrementeel vernieuwen is ingeschakeld.
De naam van niet-berekende kolommen in een tabel wijzigen waarvoor incrementeel vernieuwen is ingeschakeld.
Andere wijzigingen, zoals het toevoegen van een kolom, het verwijderen van een kolom en het wijzigen van de naam van een berekende kolom, zijn toegestaan. Als de wijzigingen echter van invloed zijn op de weergave, moet u vernieuwen voordat de wijziging zichtbaar is.
Samengestelde modellen
Met samengestelde modellen kunt u een rapport met meerdere gegevensverbindingen instellen.
U kunt de functionaliteit van samengestelde modellen gebruiken om een semantisch Fabric-model te verbinden met een extern semantisch model, zoals Azure Analysis Services. Zie DirectQuery gebruiken voor semantische Fabric-modellen en Azure Analysis Services voor meer informatie.
In een implementatiepijplijn kunt u samengestelde modellen gebruiken om een semantisch model te verbinden met een ander semantisch Fabric-model buiten de pijplijn.
Automatische aggregaties
Automatische aggregaties zijn gebouwd op basis van door de gebruiker gedefinieerde aggregaties en gebruiken machine learning om directQuery-semantische modellen continu te optimaliseren voor maximale rapportqueryprestaties.
Elk semantisch model behoudt de automatische aggregaties na de implementatie. Met implementatiepijplijnen wordt de automatische aggregatie van een semantisch model niet gewijzigd. Dit betekent dat als u een semantisch model implementeert met een automatische aggregatie, de automatische aggregatie in de doelfase ongewijzigd blijft en niet wordt overschreven door de automatische aggregatie die is geïmplementeerd vanuit de bronfase.
Als u automatische aggregaties wilt inschakelen, volgt u de instructies in het configureren van de automatische aggregatie.
Hybride tabellen
Hybride tabellen zijn tabellen met incrementeel vernieuwen die zowel import- als directe querypartities kunnen bevatten. Tijdens een schone implementatie worden zowel het vernieuwingsbeleid als de hybride tabelpartities gekopieerd. Wanneer u implementeert in een pijplijnfase met al hybride tabelpartities, wordt alleen het vernieuwingsbeleid gekopieerd. Vernieuw de tabel om de partities bij te werken.
Inhoud bijwerken naar Power BI-apps
Power BI-apps zijn de aanbevolen manier om inhoud te distribueren naar gratis Fabric-consumenten. U kunt de inhoud van uw Power BI-apps bijwerken met behulp van een implementatiepijplijn, zodat u meer controle en flexibiliteit hebt als het gaat om de levenscyclus van uw app.
Maak een app voor elke implementatiepijplijnfase, zodat u elke update kunt testen vanuit het oogpunt van een eindgebruiker. Gebruik de knop Publiceren of weergeven in de werkruimtekaart om de app in een specifieke pijplijnfase te publiceren of weer te geven.
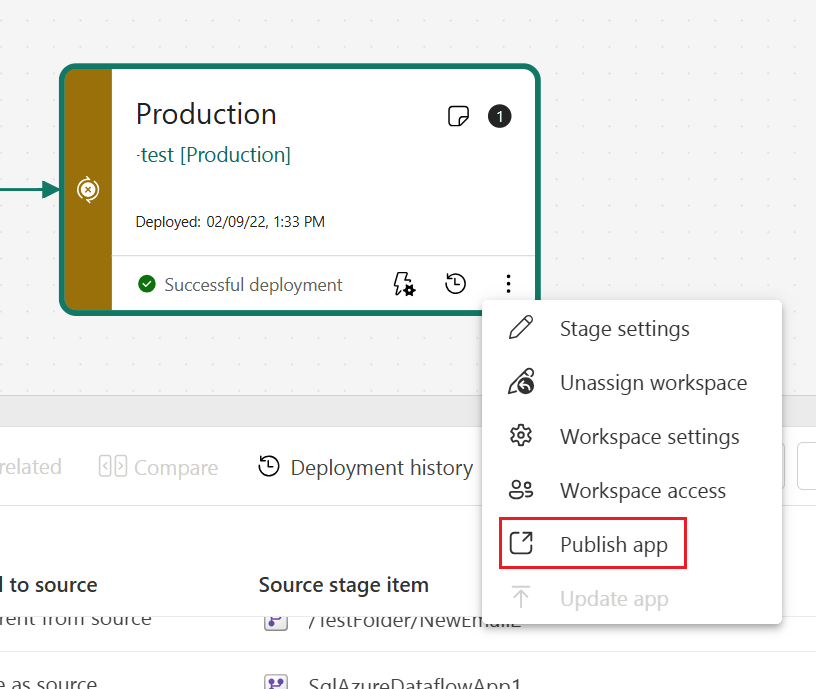

In de productiefase kunt u ook de app-pagina in Fabric bijwerken, zodat alle inhoudsupdates beschikbaar worden voor app-gebruikers.

Belangrijk
Het implementatieproces omvat niet het bijwerken van de app-inhoud of -instellingen. Als u wijzigingen wilt toepassen op inhoud of instellingen, moet u de app handmatig bijwerken in de vereiste pijplijnfase.
Machtigingen
Machtigingen zijn vereist voor de pijplijn en voor de werkruimten die eraan zijn toegewezen. Pijplijnmachtigingen en werkruimtemachtigingen worden afzonderlijk verleend en beheerd.
Pijplijnen hebben slechts één machtiging, beheerder, die vereist is voor het delen, bewerken en verwijderen van een pijplijn.
Werkruimten hebben verschillende machtigingen, ook wel rollen genoemd. Werkruimterollen bepalen het toegangsniveau voor een werkruimte in een pijplijn.
Implementatiepijplijnen bieden geen ondersteuning voor Microsoft 365-groepen als pijplijnbeheerders.
Als u vanuit de ene fase naar de andere in de pijplijn wilt implementeren, moet u een pijplijnbeheerder zijn en een inzender, lid of beheerder van de werkruimten die zijn toegewezen aan de betrokken fasen. Een pijplijnbeheerder waaraan geen werkruimterol is toegewezen, kan bijvoorbeeld de pijplijn bekijken en met anderen delen. Deze gebruiker kan echter de inhoud van de werkruimte in de pijplijn of in de service niet bekijken en kan geen implementaties uitvoeren.
Machtigingstabel
In deze sectie worden de machtigingen voor de implementatiepijplijn beschreven. De machtigingen die in deze sectie worden vermeld, hebben mogelijk verschillende toepassingen in andere Fabric-functies.
De laagste machtiging voor de implementatiepijplijn is pijplijnbeheerder en is vereist voor alle implementatiepijplijnbewerkingen.
| User | Pijplijnmachtigingen | Opmerkingen |
|---|---|---|
| Pijplijnbeheerder |
|
Pijplijntoegang verleent geen machtigingen om de inhoud van de werkruimte weer te geven of uit te voeren. |
|
Werkruimteviewer (en pijplijnbeheerder) |
|
Werkruimteleden hebben de rol Viewer zonder samenstellingsmachtigingen toegewezen, hebben geen toegang tot het semantische model of kunnen werkruimte-inhoud bewerken. |
|
Inzender voor werkruimten (en pijplijnbeheerder) |
|
|
|
Lid van werkruimte (en pijplijnbeheerder) |
|
Als de instelling voor het opnieuw publiceren en uitschakelen van pakketvernieuwing in de sectie beveiliging van het tenantsemantische model is ingeschakeld, kunnen alleen semantische modeleigenaren semantische modellen bijwerken. |
|
Werkruimtebeheerder (en pijplijnbeheerder) |
|
Verleende machtigingen
Wanneer u Power BI-items implementeert, kan het eigendom van het geïmplementeerde item veranderen. Bekijk de volgende tabel om te begrijpen wie elk item kan implementeren en hoe de implementatie van invloed is op het eigendom van het item.
| Fabric-item | Vereiste machtiging voor het implementeren van een bestaand item | Eigendom van items na een eerste implementatie | Eigendom van items na implementatie in een fase met het item |
|---|---|---|---|
| Semantisch model | Lid van werkruimte | De gebruiker die de implementatie heeft gemaakt, wordt de eigenaar | Ongewijzigd |
| Gegevensstroom | Eigenaar van gegevensstroom | De gebruiker die de implementatie heeft gemaakt, wordt de eigenaar | Ongewijzigd |
| Datamart | Datamart-eigenaar | De gebruiker die de implementatie heeft gemaakt, wordt de eigenaar | Ongewijzigd |
| Gepagineerd rapport | Lid van werkruimte | De gebruiker die de implementatie heeft gemaakt, wordt de eigenaar | De gebruiker die de implementatie heeft gemaakt, wordt de eigenaar |
Vereiste machtigingen voor populaire acties
De volgende tabel bevat de vereiste machtigingen voor populaire implementatiepijplijnacties. Tenzij anders is opgegeven, hebt u voor elke actie alle vermelde machtigingen nodig.
| Actie | Vereiste machtigingen |
|---|---|
| De lijst met pijplijnen in uw organisatie weergeven | Geen licentie vereist (gratis gebruiker) |
| Een pipeline maken | Een gebruiker met een van de volgende licenties:
|
| Een pijplijn verwijderen | Pijplijnbeheerder |
| Een pijplijngebruiker toevoegen of verwijderen | Pijplijnbeheerder |
| Een werkruimte toewijzen aan een fase |
|
| Een werkruimte toewijzen aan een fase | Een van de volgende rollen:
|
| Uitrollen naar een lege omgeving (zie opmerking) |
|
| Items implementeren in de volgende fase (zie opmerking) |
|
| Een regel weergeven of instellen |
|
| Pijplijninstellingen beheren | Pijplijnbeheerder |
| Een pijplijnfase weergeven |
|
| De lijst met items in een fase weergeven | Pijplijnbeheerder |
| Twee fasen vergelijken |
|
| Implementatiegeschiedenis weergeven | Pijplijnbeheerder |
Notitie
Als u inhoud in de GCC-omgeving wilt implementeren, moet u ten minste lid zijn van zowel de bron- als doelwerkruimte. Implementeren als inzender wordt nog niet ondersteund.
Overwegingen en beperkingen
In deze sectie vindt u een overzicht van de meeste beperkingen in implementatiepijplijnen.
- De werkruimte moet zich in een infrastructuurcapaciteit bevinden.
- Wanneer u momenteel een werkruimte implementeert in een bestaande doelwerkruimte in een andere regio, is er mogelijk geen waarschuwing in het dialoogvenster Implementeren.
- Het maximum aantal items dat in één implementatie kan worden geïmplementeerd, is 300.
- Het downloaden van een PBIX-bestand na de implementatie wordt niet ondersteund.
- Microsoft 365-groepen worden niet ondersteund als pijplijnbeheerders.
- Wanneer u een Power BI-item voor het eerst implementeert, mislukt de implementatie als een ander item in de doelfase dezelfde naam en hetzelfde type heeft (bijvoorbeeld als beide bestanden rapporten zijn).
- Zie de beperkingen voor werkruimtetoewijzingen voor een lijst met werkruimtebeperkingen.
- Zie ondersteunde items voor een lijst met ondersteunde items. Een item dat niet in de lijst staat, wordt niet ondersteund.
- De implementatie mislukt als een van de items kring- of zelfafhankelijkheden heeft (bijvoorbeeld item A verwijst naar item B en item B naar item A).
- PBIR-rapporten worden niet ondersteund.
Beperkingen voor semantische modellen
Gegevenssets die realtime gegevensconnectiviteit gebruiken, kunnen niet worden geïmplementeerd.
Een semantisch model met de DirectQuery- of samengestelde connectiviteitsmodus die gebruikmaakt van variatie- of automatische datum/tijd-tabellen , wordt niet ondersteund. Zie Wat kan ik doen als ik een gegevensset heb met de DirectQuery- of samengestelde connectiviteitsmodus, die gebruikmaakt van variatie- of agendatabellen?
Als het doelsemantische model tijdens de implementatie gebruikmaakt van een liveverbinding, moet het semantische bronmodel deze verbindingsmodus ook gebruiken.
Na de implementatie wordt het downloaden van een semantisch model (van de fase waarnaar het is geïmplementeerd) niet ondersteund.
Zie beperkingen voor implementatieregels voor een lijst met beperkingen voor implementatieregels.
Als automatisch verbinden is ingeschakeld, gaat u als volgt te werk:
- Systeemeigen query's en DirectQuery worden niet samen ondersteund. Dit omvat proxy-datasets.
- De gegevensbronverbinding moet de eerste stap in de mashup-expressie zijn.
Wanneer een semantisch Direct Lake-model wordt geïmplementeerd, wordt het niet automatisch gekoppeld aan items in de doelfase. Als een LakeHouse bijvoorbeeld een bron is voor een DirectLake-semantisch model en ze beide worden geïmplementeerd in de volgende fase, is het semantische DirectLake-model in de doelfase nog steeds gebonden aan het LakeHouse in de bronfase. Gebruik gegevensbronregels om het te binden aan een item in de doelfase. Andere typen semantische modellen worden automatisch gebonden aan het gekoppelde item in de doelfase.
Beperkingen voor gegevensstromen
Instellingen voor incrementeel vernieuwen worden niet gekopieerd in Gen 1.
Wanneer u een gegevensstroom in een lege fase implementeert, maken implementatiepijplijnen een nieuwe werkruimte en worden de gegevensstroomopslag ingesteld op een Fabric-blobopslag. Blob Storage wordt gebruikt, zelfs als de bronwerkruimte is geconfigureerd voor het gebruik van Azure Data Lake Storage Gen2 (ADLS Gen2).
Service-principal wordt niet ondersteund voor gegevensstromen.
Het implementeren van common data model (CDM) wordt niet ondersteund.
Zie Implementatieregelsbeperkingen voor beperkingen voor implementatiepijplijnen die van invloed zijn op gegevensstromen.
Als een gegevensstroom tijdens de implementatie wordt vernieuwd, mislukt de implementatie.
Als u fasen vergelijkt tijdens het vernieuwen van een gegevensstroom, zijn de resultaten onvoorspelbaar.
Datamart-beperkingen
U kunt geen datamart implementeren met vertrouwelijkheidslabels.
U moet de eigenaar van de datamart zijn om een datamart te implementeren.