Azure Machine Learning-modellen gebruiken
De geharmoniseerde gegevens in Dynamics 365 Customer Insights- Data zijn een bron voor het bouwen van Machine Learning-modellen die aanvullende zakelijke inzichten kunnen genereren. Customer Insights - Data integreert met Azure Machine Learning om uw eigen aangepaste modellen te gebruiken.
Vereisten
- Toegang tot Customer Insights - Data
- Actief Azure Enterprise-abonnement
- Geharmoniseerde klantprofielen
- Tabel exporteren naar Azure Blob Storage geconfigureerd
Azure Machine Learning-werkruimte instellen
Zie een Azure Machine Learning-werkruimte maken voor verschillende opties om de werkruimte te maken. Voor de beste prestaties maakt u de werkruimte in een Azure-regio die geografisch het dichtst bij uw Customer Insights-omgeving ligt.
Toegang tot uw werkruimte via Azure Machine Learning Studio. Er zijn meerdere manieren om te communiceren met uw werkruimte.
Werken met Azure Machine Learning designer
Azure Machine Learning-ontwerper biedt een visueel canvas waar u gegevenssets en modules kunt slepen en neerzetten. Een batchpijplijn die is gemaakt vanuit de designer, kan worden geïntegreerd in Customer Insights - Data als deze dienovereenkomstig zijn geconfigureerd.
Werken met Azure Machine Learning SDK
Datawetenschappers en AI-ontwikkelaars gebruiken de Azure Machine Learning SDK om Machine Learning-workflows te bouwen. Momenteel kunnen modellen die zijn getraind met de SDK, niet rechtstreeks worden geïntegreerd. Een batch-inferentiepijplijn die dat model verbruikt, is vereist voor integratie met Customer Insights - Data.
Batchpijplijnvereisten om te integreren met Customer Insights - Data
Configuratie van gegevensset
Maak gegevenssets om tabelgegevens uit Customer Insights te gebruiken voor uw batch-inferentiepijplijn. Registreer deze gegevenssets in de werkruimte. Momenteel ondersteunen we alleen gegevenssets in tabelvorm in .csv-indeling. Voorzie de gegevenssets van parameters die overeenkomen met tabelgegevens, als een pijplijnparameter.
Gegevenssetparameters in Designer
Open in de ontwerper Kolommen in gegevensset selecteren en selecteer Instellen als pijplijnparameter, waar u een naam opgeeft voor de parameter.
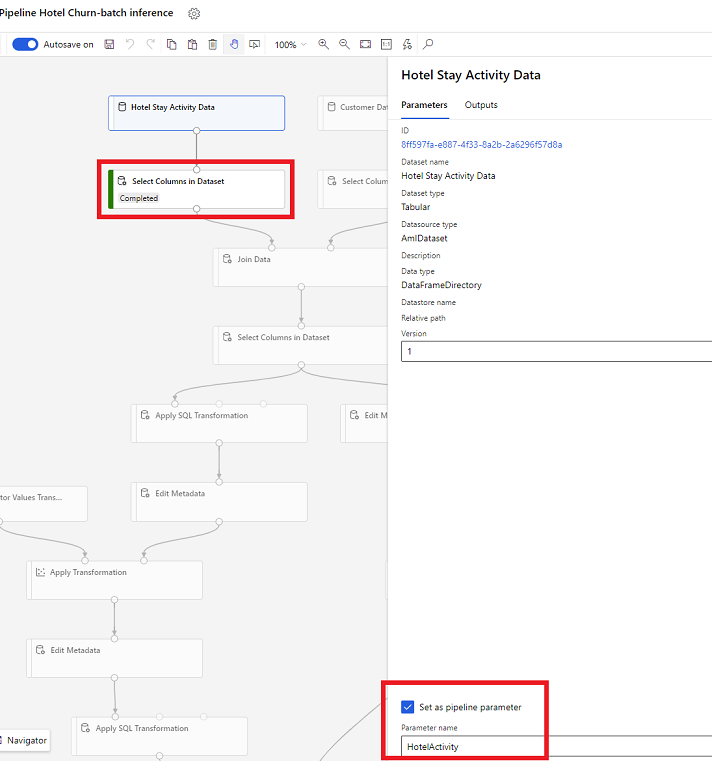
Gegevenssetparameter in SDK (Python)
HotelStayActivity_dataset = Dataset.get_by_name(ws, name='Hotel Stay Activity Data') HotelStayActivity_pipeline_param = PipelineParameter(name="HotelStayActivity_pipeline_param", default_value=HotelStayActivity_dataset) HotelStayActivity_ds_consumption = DatasetConsumptionConfig("HotelStayActivity_dataset", HotelStayActivity_pipeline_param)
Batch-inferentiepijplijn
Gebruik in de ontwerper een trainingspijplijn voor het maken of bijwerken van een inferentiepijplijn. Momenteel worden alleen batch-inferentiepijplijnen ondersteund.
Publiceer met behulp van de SDK de pijplijn naar een eindpunt. Momenteel integreert Customer Insights - Data met de standaardpijplijn in een batchpijplijneindpunt in de Machine Learning-werkruimte.
published_pipeline = pipeline.publish(name="ChurnInferencePipeline", description="Published Churn Inference pipeline") pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name="ChurnPipelineEndpoint") pipeline_endpoint.add_default(pipeline=published_pipeline)
Pijplijngegevens importeren
De designer levert de module Gegevens exporteren waarmee de uitvoer van een pijplijn kan worden geëxporteerd naar Azure Storage. Momenteel moet de module het gegevensopslagtype Azure Blob Storage gebruiken en de Gegevensopslag en het relatieve Pad parametriseren. Het systeem overschrijft beide parameters tijdens de uitvoering van een pijplijn met een gegevensopslag en pad dat toegankelijk is voor de toepassing.
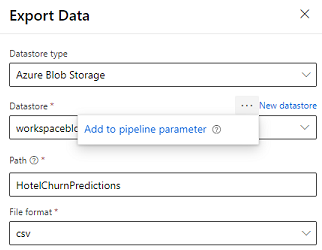
Wanneer u de inferentie-uitvoer schrijft met behulp van code, uploadt u de uitvoer naar een pad binnen een geregistreerde gegevensopslag in de werkruimte. Als het pad en de gegevensopslag in de pijplijn zijn geparametriseerd, kan Customer Insights de inferentie-uitvoer lezen en importeren. Momenteel wordt één uitvoer in tabelvorm in csv-indeling ondersteund. Het pad moet de map en de bestandsnaam bevatten.
# In Pipeline setup script OutputPathParameter = PipelineParameter(name="output_path", default_value="HotelChurnOutput/HotelChurnOutput.csv") OutputDatastoreParameter = PipelineParameter(name="output_datastore", default_value="workspaceblobstore") ... # In pipeline execution script run = Run.get_context() ws = run.experiment.workspace datastore = Datastore.get(ws, output_datastore) # output_datastore is parameterized directory_name = os.path.dirname(output_path) # output_path is parameterized. # Datastore.upload() or Dataset.File.upload_directory() are supported methods to uplaod the data # datastore.upload(src_dir=<<working directory>>, target_path=directory_name, overwrite=False, show_progress=True) output_dataset = Dataset.File.upload_directory(src_dir=<<working directory>>, target = (datastore, directory_name)) # Remove trailing "/" from directory_name