Zelfstudie: Data Lakes verkennen en analyseren met een serverloze SQL-pool
In deze zelfstudie leert u hoe u verkennende gegevensanalyse uitvoert met behulp van bestaande geopende gegevenssets, zonder dat opslagconfiguratie is vereist. U combineert verschillende Azure Open Datasets met behulp van een serverloze SQL-pool. Vervolgens visualiseert u de resultaten in Synapse Studio voor Azure Synapse Analytics.
In deze zelfstudie hebt u:
- Toegang tot de ingebouwde serverloze SQL-pool
- Toegang tot Azure Open Datasets voor het gebruik van zelfstudiegegevens
- Eenvoudige gegevensanalyse uitvoeren met BEHULP van SQL
Toegang tot de serverloze SQL-pool
Elke werkruimte wordt geleverd met een vooraf geconfigureerde serverloze SQL-pool voor gebruik met de naam Ingebouwd. Ga als volgende te werk om toegang te krijgen tot het:
- Open uw werkruimte en selecteer de hub Ontwikkelen .
- Selecteer de + knop Nieuwe resource toevoegen.'
- Selecteer SQL-script.
U kunt dit script gebruiken om uw gegevens te verkennen zonder SQL-capaciteit te hoeven reserveren.
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Toegang tot de zelfstudiegegevens
Alle gegevens die we in deze zelfstudie gebruiken, worden ondergebracht in het opslagaccount azureopendatastorage, dat Azure Open Datasets bevat voor open gebruik in zelfstudies zoals deze. U kunt alle scripts rechtstreeks vanuit uw werkruimte uitvoeren, zolang uw werkruimte toegang heeft tot een openbaar netwerk.
In deze zelfstudie wordt een gegevensset over New York City (NYC) Taxi gebruikt:
- Datums en tijden ophalen en afzetten
- Ophaal- en afleverlocaties
- Reisafstanden
- Geitemiseerde tarieven
- Tarieftypen
- Betalingstypen
- Aantal door de bestuurder gerapporteerde passagiers
Met de functie OPENROWSET(BULK...) kunt u toegang krijgen tot bestanden in Azure Storage. [OPENROWSET](develop-openrowset.md) leest inhoud van een externe gegevensbron, zoals een bestand, en retourneert de inhoud als een set rijen.
Voer de volgende query uit om vertrouwd te raken met de NYC Taxi-gegevens:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
Andere toegankelijke gegevenssets
Op dezelfde manier kunt u een query uitvoeren op de gegevensset Openbare feestdagen, met behulp van de volgende query:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
U kunt ook een query uitvoeren op de gegevensset Met de volgende query:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
Meer informatie over de betekenis van de afzonderlijke kolommen vindt u in de beschrijvingen van de gegevenssets:
Automatische schemadeductie
Omdat de gegevens worden opgeslagen in de Parquet-bestandsindeling, is automatische schemadeductie beschikbaar. U kunt query's uitvoeren op de gegevens zonder dat de gegevenstypen van alle kolommen in de bestanden worden vermeld. U kunt ook het mechanisme voor virtuele kolommen en de filepath functie gebruiken om een bepaalde subset van bestanden uit te filteren.
Notitie
De standaardsortering is SQL_Latin1_General_CP1_CI_ASIf. Voor een niet-standaardsortering moet u rekening houden met hoofdlettergevoeligheid.
Als u een database met hoofdlettergevoelige sortering maakt wanneer u kolommen opgeeft, moet u de juiste naam van de kolom gebruiken.
Een kolomnaam tpepPickupDateTime zou juist zijn, terwijl tpeppickupdatetime deze niet werkt in een niet-standaardsortering.
Analyse van tijdreeks, seizoensgebondenheid en uitbijter
U kunt het jaarlijkse aantal taxiritten samenvatten met behulp van de volgende query:
SELECT
YEAR(tpepPickupDateTime) AS current_year,
COUNT(*) AS rides_per_year
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) >= '2009' AND nyc.filepath(1) <= '2019'
GROUP BY YEAR(tpepPickupDateTime)
ORDER BY 1 ASC
Het volgende fragment toont het resultaat voor het jaarlijkse aantal taxiritten:
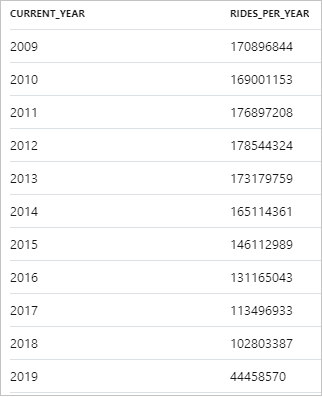
De gegevens kunnen worden gevisualiseerd in Synapse Studio door over te schakelen van de weergave Tabel naar de weergave Grafiek. U kunt kiezen uit verschillende grafiektypen, zoals Gebied, Staaf, Kolom, Lijn, Cirkel en Spreiding. In dit geval tekent u het Kolomdiagram met de kolom Categorie ingesteld op current_year:
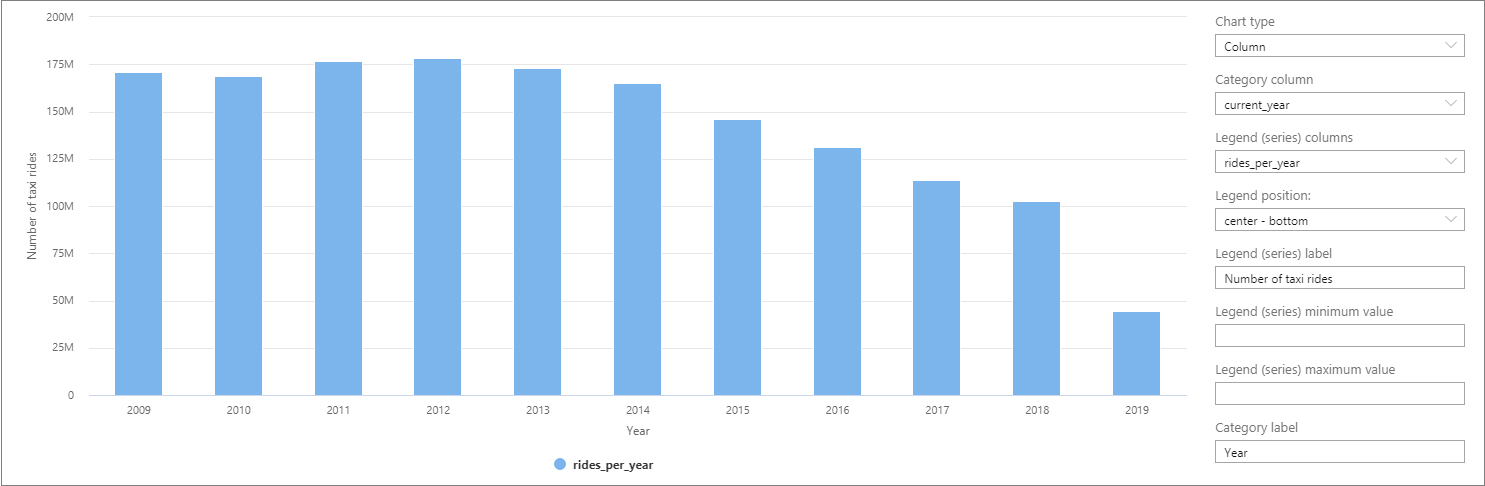
Vanuit deze visualisatie ziet u een trend van het afnemen van het aantal ritten over de jaren. Deze afname is waarschijnlijk te wijten aan de recent toegenomen populariteit van bedrijven die gedeelde ritten aanbieden.
Notitie
Op het moment dat deze zelfstudie wordt geschreven, zijn de gegevens voor 2019 nog incompleet. Als gevolg hiervan is een enorme daling zichtbaar in het aantal ritten voor dat jaar.
U kunt de analyse richten op één jaar, bijvoorbeeld 2016. De volgende query retourneert het dagelijks aantal ritten gedurende dat jaar:
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
ORDER BY 1 ASC
Het volgende fragment toont het resultaat voor deze query:
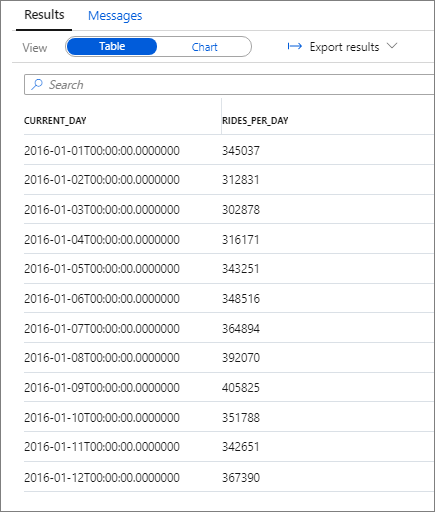
Nogmaals, u kunt gegevens visualiseren door het kolomdiagram te tekenen met de kolom Categorie ingesteld op current_day en de kolom Legenda (reeks) ingesteld op rides_per_day.
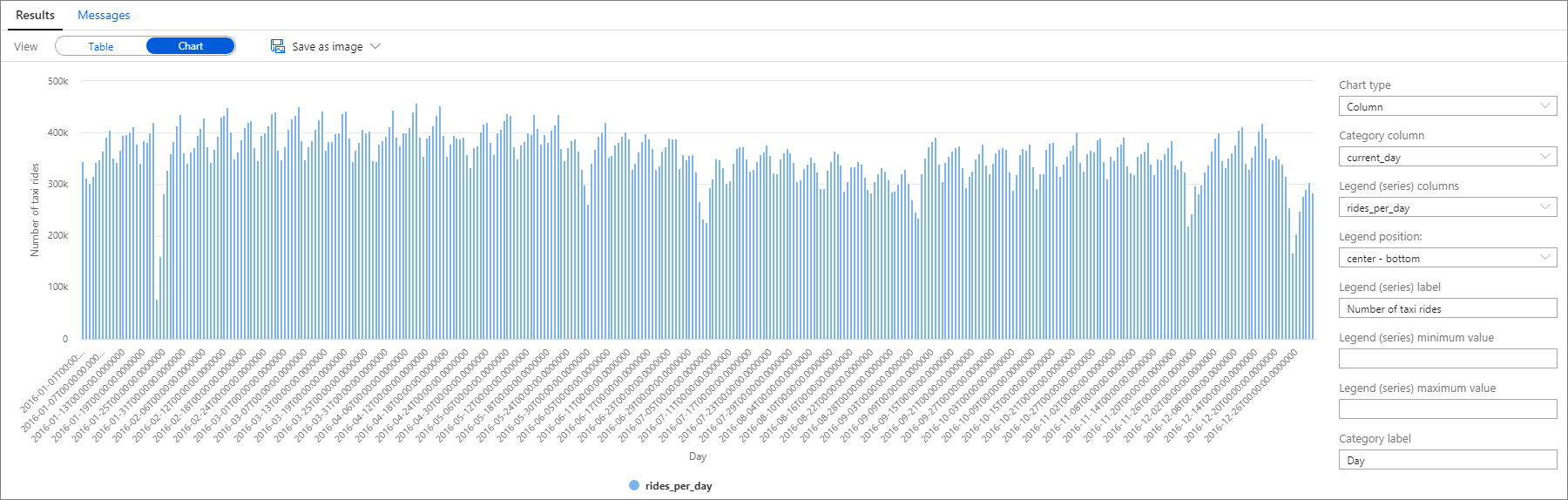
In het getekende diagram kunt u zien dat er sprake is van een wekelijks patroon, met zaterdagen als piekdag. Tijdens de zomermaanden zijn er minder taxiritten vanwege vakanties. U ziet ook aanzienlijke dalingen in het aantal taxiritten zonder duidelijk patroon wanneer en waarom ze optreden.
Kijk vervolgens of de daling van ritten overeenkomt met feestdagen. Controleer of er een correlatie is door de gegevensset nyc taxiritten te koppelen aan de gegevensset Openbare feestdagen:
WITH taxi_rides AS (
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
),
public_holidays AS (
SELECT
holidayname as holiday,
date
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
WHERE countryorregion = 'United States' AND YEAR(date) = 2016
),
joined_data AS (
SELECT
*
FROM taxi_rides t
LEFT OUTER JOIN public_holidays p on t.current_day = p.date
)
SELECT
*,
holiday_rides =
CASE
WHEN holiday is null THEN 0
WHEN holiday is not null THEN rides_per_day
END
FROM joined_data
ORDER BY current_day ASC
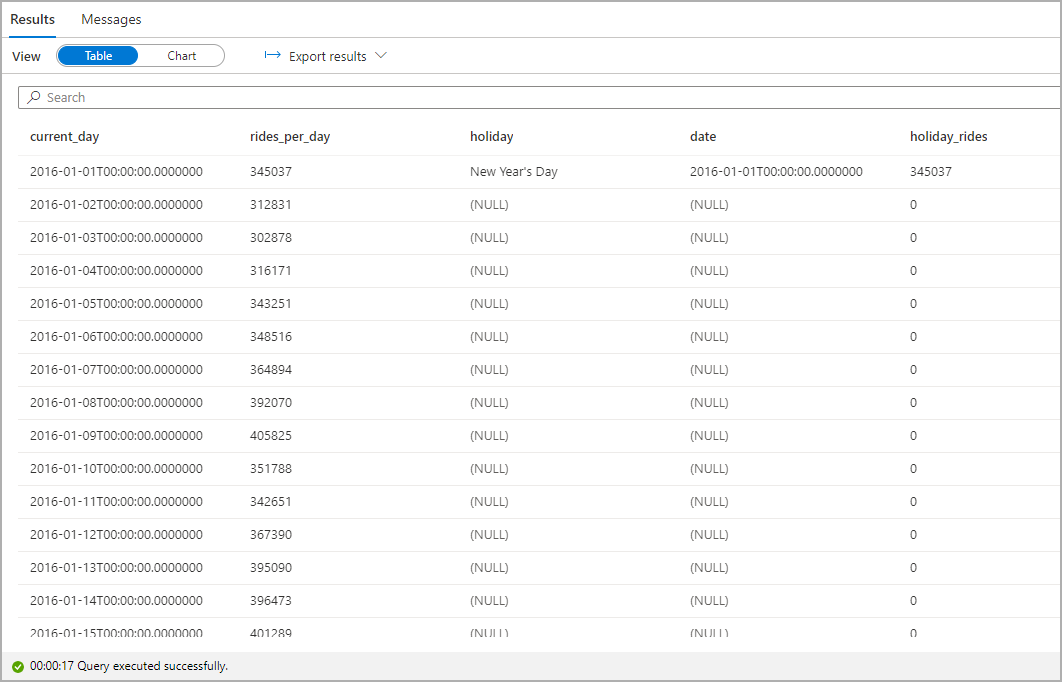
Markeer het aantal taxiritten tijdens feestdagen. Kies hiervoor current_day voor de kolom Categorie en rides_per_day en holiday_rides als de kolommen Legenda (reeks).
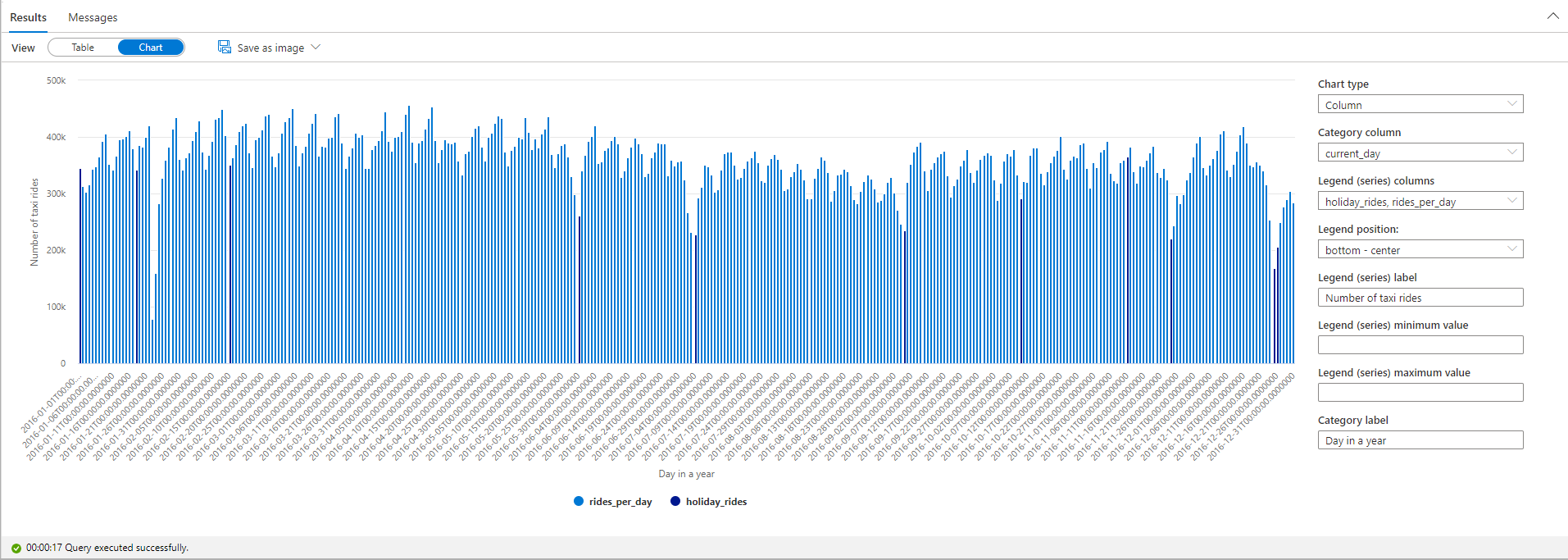
In het getekende diagram kunt u zien dat het aantal taxiritten tijdens openbare feestdagen kleiner is. Er is nog steeds één onverklaarde grote daling op 23 januari. Laten we het weer in NYC op deze dag bekijken door een query uit te voeren op de gegevensset Weer:
SELECT
AVG(windspeed) AS avg_windspeed,
MIN(windspeed) AS min_windspeed,
MAX(windspeed) AS max_windspeed,
AVG(temperature) AS avg_temperature,
MIN(temperature) AS min_temperature,
MAX(temperature) AS max_temperature,
AVG(sealvlpressure) AS avg_sealvlpressure,
MIN(sealvlpressure) AS min_sealvlpressure,
MAX(sealvlpressure) AS max_sealvlpressure,
AVG(precipdepth) AS avg_precipdepth,
MIN(precipdepth) AS min_precipdepth,
MAX(precipdepth) AS max_precipdepth,
AVG(snowdepth) AS avg_snowdepth,
MIN(snowdepth) AS min_snowdepth,
MAX(snowdepth) AS max_snowdepth
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
WHERE countryorregion = 'US' AND CAST([datetime] AS DATE) = '2016-01-23' AND stationname = 'JOHN F KENNEDY INTERNATIONAL AIRPORT'

De resultaten van de query geven aan dat de daling van het aantal taxiritten plaatsvond vanwege het volgende:
- Er was die dag een storm in NYC, met zware sneeuwval (ongeveer 30 cm).
- Het was koud (temperatuur onder nul graden Celsius).
- Het waaide (~ 10 m/s).
In deze zelfstudie ziet u hoe een gegevensanalist snel verkennende gegevensanalyse kan uitvoeren. U kunt verschillende gegevenssets combineren met behulp van een serverloze SQL-pool en de resultaten visualiseren met behulp van Azure Synapse Studio.
Gerelateerde inhoud
Raadpleeg Een serverloze SQL-pool verbinden met Power BI Desktop en rapporten maken voor meer informatie over het verbinden van een serverloze SQL-pool met Power BI Desktop en het maken van rapporten.
Zie Externe tabellen gebruiken met Synapse SQL voor meer informatie over het gebruik van externe tabellen in een serverloze SQL-pool