Inleiding tot api's voor het koppelen/ontkoppelen van bestanden in Azure Synapse Analytics
Het Azure Synapse Studio-team heeft twee nieuwe API's voor koppelen/ontkoppelen gebouwd in het pakket Microsoft Spark Utilities (mssparkutils). U kunt deze API's gebruiken om externe opslag (Azure Blob Storage of Azure Data Lake Storage Gen2) te koppelen aan alle werkknooppunten (stuurprogrammaknooppunt en werkknooppunten). Nadat de opslag is ingesteld, kunt u de API voor het lokale bestand gebruiken om toegang te krijgen tot gegevens alsof deze zijn opgeslagen in het lokale bestandssysteem. Zie Inleiding tot Microsoft Spark-hulpprogramma's voor meer informatie.
In het artikel wordt beschreven hoe u API's voor koppelen/ontkoppelen gebruikt in uw werkruimte. U leert het volgende:
- Data Lake Storage Gen2 of Blob Storage koppelen.
- Toegang krijgen tot bestanden onder het koppelpunt via de API van het lokale bestandssysteem.
- Toegang krijgen tot bestanden onder het koppelpunt met behulp van de
mssparkutils fsAPI. - Toegang krijgen tot bestanden onder het koppelpunt met behulp van de Spark-lees-API.
- Het koppelpunt ontkoppelen.
Waarschuwing
Koppelen van Azure-bestandsshares is tijdelijk uitgeschakeld. U kunt in plaats daarvan Data Lake Storage Gen2 of Azure Blob Storage koppelen, zoals beschreven in de volgende sectie.
Azure Data Lake Storage Gen1-opslag wordt niet ondersteund. U kunt migreren naar Data Lake Storage Gen2 door de migratierichtlijnen van Azure Data Lake Storage Gen1 naar Gen2 te volgen voordat u de koppelings-API's gebruikt.
Opslag koppelen
In deze sectie ziet u hoe u Data Lake Storage Gen2 stap voor stap koppelt als voorbeeld. Het koppelen van Blob Storage werkt op dezelfde manier.
In het voorbeeld wordt ervan uitgegaan dat u één Data Lake Storage Gen2-account hebt met de naam storegen2. Het account heeft één container met de naam mycontainer waaraan u wilt koppelen /test in uw Spark-pool.
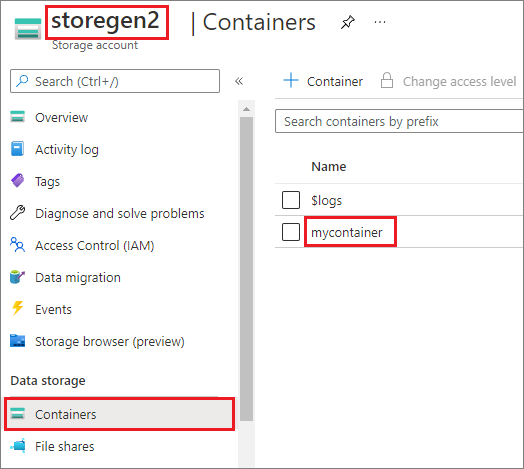
Als u de aangeroepen mycontainercontainer wilt koppelen, mssparkutils moet u eerst controleren of u gemachtigd bent om toegang te krijgen tot de container. Momenteel ondersteunt Azure Synapse Analytics drie verificatiemethoden voor de triggerkoppelingsbewerking: linkedService, accountKeyen sastoken.
Koppelen met behulp van een gekoppelde service (aanbevolen)
We raden een triggerkoppeling aan via een gekoppelde service. Deze methode voorkomt beveiligingslekken, omdat mssparkutils er geen geheime of verificatiewaarden zelf worden opgeslagen. In plaats daarvan mssparkutils haalt u altijd verificatiewaarden van de gekoppelde service op om blobgegevens op te vragen uit externe opslag.
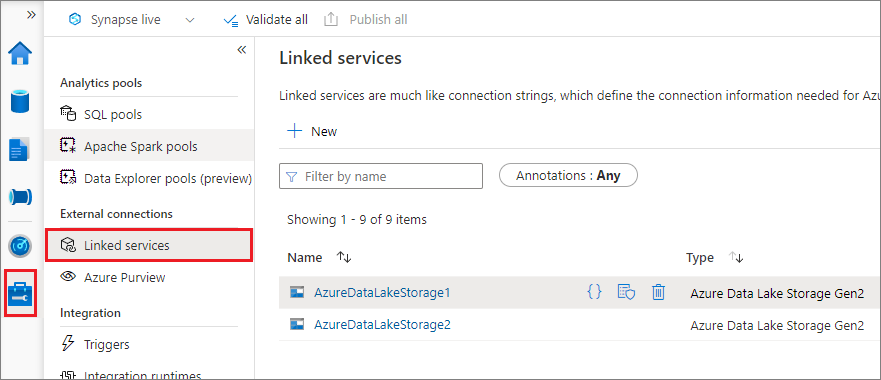
U kunt een gekoppelde service maken voor Data Lake Storage Gen2 of Blob Storage. Momenteel ondersteunt Azure Synapse Analytics twee verificatiemethoden wanneer u een gekoppelde service maakt:
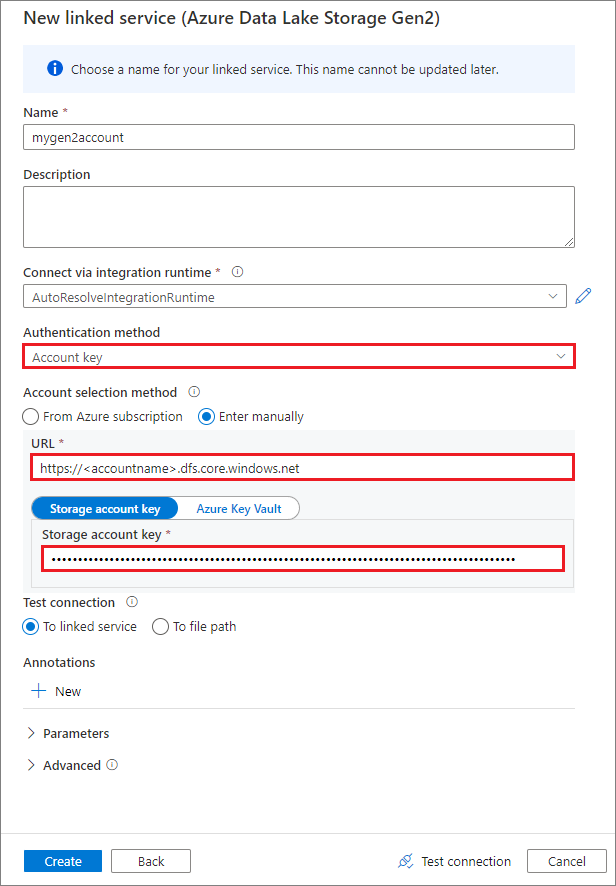
Een gekoppelde service maken met behulp van een accountsleutel
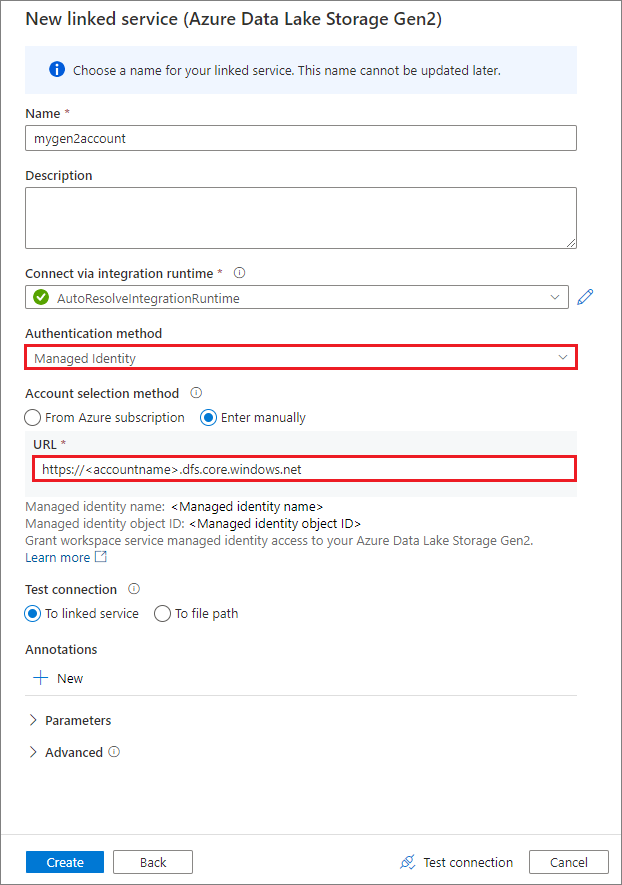
Een gekoppelde service maken met behulp van een door het systeem toegewezen beheerde identiteit
Belangrijk
- Als de bovenstaande gekoppelde service voor Azure Data Lake Storage Gen2 gebruikmaakt van een beheerd privé-eindpunt (met een dfs-URI ), moeten we een ander secundair beheerd privé-eindpunt maken met behulp van de Azure Blob Storage-optie (met een blob-URI ) om ervoor te zorgen dat de interne fsspec/adlfs-code verbinding kan maken met behulp van de BlobServiceClient-interface .
- Als het secundaire beheerde privé-eindpunt niet juist is geconfigureerd, wordt er een foutbericht weergegeven zoals ServiceRequestError: Kan geen verbinding maken met host [storageaccountname].blob.core.windows.net:443 ssl:True [Naam of service niet bekend]
Notitie
Als u een gekoppelde service maakt met behulp van een beheerde identiteit als verificatiemethode, moet u ervoor zorgen dat het MSI-bestand van de werkruimte de rol Inzender voor opslagblobgegevens van de gekoppelde container heeft.
Nadat u een gekoppelde service hebt gemaakt, kunt u de container eenvoudig koppelen aan uw Spark-pool met behulp van de volgende Python-code:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService": "mygen2account"}
)
Notitie
Mogelijk moet u importeren mssparkutils als deze niet beschikbaar is:
from notebookutils import mssparkutils
Het is niet raadzaam om een hoofdmap te koppelen, ongeacht welke verificatiemethode u gebruikt.
Parameters koppelen:
- fileCacheTimeout: Blobs worden standaard gedurende 120 seconden in de lokale tijdelijke map in de cache opgeslagen. Gedurende deze periode controleert blobfuse niet of het bestand up-to-date is of niet. De parameter kan worden ingesteld om de standaardtime-outtijd te wijzigen. Wanneer meerdere clients tegelijkertijd bestanden wijzigen, om inconsistenties tussen lokale en externe bestanden te voorkomen, raden we u aan de cachetijd te verkorten of zelfs te wijzigen in 0 en altijd de meest recente bestanden van de server op te halen.
- time-out: de time-out voor de koppelbewerking is standaard 120 seconden. De parameter kan worden ingesteld om de standaardtime-outtijd te wijzigen. Als er te veel uitvoerders zijn of wanneer er een time-out optreedt voor de koppeling, raden we u aan de waarde te verhogen.
- scope: De bereikparameter wordt gebruikt om het bereik van de koppeling op te geven. De standaardwaarde is 'taak'. Als het bereik is ingesteld op 'taak', is de koppeling alleen zichtbaar voor het huidige cluster. Als het bereik is ingesteld op 'werkruimte', is de koppeling zichtbaar voor alle notitieblokken in de huidige werkruimte en wordt het koppelpunt automatisch gemaakt als het niet bestaat. Voeg dezelfde parameters toe aan de ontkoppelde API om het koppelpunt los te koppelen. De koppeling op werkruimteniveau wordt alleen ondersteund voor verificatie van gekoppelde services.
U kunt deze parameters als volgt gebruiken:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService":"mygen2account", "fileCacheTimeout": 120, "timeout": 120}
)
Koppelen via shared access Signature-token of accountsleutel
Naast koppelen via een gekoppelde service, mssparkutils ondersteunt het expliciet doorgeven van een accountsleutel of SAS-token (Shared Access Signature) als parameter om het doel te koppelen.
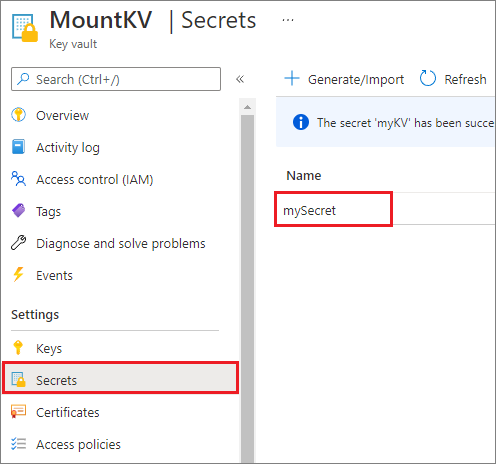
Om veiligheidsredenen raden we u aan accountsleutels of SAS-tokens op te slaan in Azure Key Vault (zoals in de volgende voorbeeldschermafbeelding wordt weergegeven). U kunt ze vervolgens ophalen met behulp van de mssparkutil.credentials.getSecret API. Zie Opslagaccountsleutels beheren met Key Vault en de Azure CLI (verouderd) voor meer informatie.
Dit is de voorbeeldcode:
from notebookutils import mssparkutils
accountKey = mssparkutils.credentials.getSecret("MountKV","mySecret")
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"accountKey":accountKey}
)
Notitie
Sla om veiligheidsredenen geen referenties op in code.
Toegang tot bestanden onder het koppelpunt met behulp van de mssparkutils fs-API
Het belangrijkste doel van de koppelingsbewerking is om klanten toegang te geven tot de gegevens die zijn opgeslagen in een extern opslagaccount met behulp van een api voor het lokale bestandssysteem. U kunt de gegevens ook openen met behulp van de mssparkutils fs API met een gekoppeld pad als parameter. De padindeling die hier wordt gebruikt, is iets anders.
Ervan uitgaande dat u de Mycontainer van de Data Lake Storage Gen2-container hebt gekoppeld aan /test met behulp van de koppelings-API. Wanneer u de gegevens opent via een API voor een lokaal bestandssysteem:
- Voor Spark-versies kleiner dan of gelijk aan 3.3 is
/synfs/{jobId}/test/{filename}de padindeling. - Voor Spark-versies groter dan of gelijk aan 3.4 is
/synfs/notebook/{jobId}/test/{filename}de padindeling.
U wordt aangeraden een mssparkutils.fs.getMountPath() pad te gebruiken om het juiste pad op te halen:
path = mssparkutils.fs.getMountPath("/test")
Notitie
Wanneer u de opslag koppelt met workspace een bereik, wordt het koppelpunt gemaakt onder de /synfs/workspace map. En u moet het juiste mssparkutils.fs.getMountPath("/test", "workspace") pad gebruiken.
Wanneer u toegang wilt krijgen tot de gegevens met behulp van de mssparkutils fs API, ziet de padindeling er als volgt uit: synfs:/notebook/{jobId}/test/{filename}. U kunt zien dat dit synfs wordt gebruikt als het schema in dit geval, in plaats van een deel van het gekoppelde pad. U kunt natuurlijk ook het lokale bestandssysteemschema gebruiken om toegang te krijgen tot de gegevens. Bijvoorbeeld: file:/synfs/notebook/{jobId}/test/{filename}.
In de volgende drie voorbeelden ziet u hoe u toegang hebt tot een bestand met een koppelpuntpad met behulp van mssparkutils fs.
Mappen weergeven:
mssparkutils.fs.ls(f'file:{mssparkutils.fs.getMountPath("/test")}')Bestandsinhoud lezen:
mssparkutils.fs.head(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv')Een map maken:
mssparkutils.fs.mkdirs(f'file:{mssparkutils.fs.getMountPath("/test")}/myDir')
Toegang tot bestanden onder het koppelpunt met behulp van de Spark read-API
U kunt een parameter opgeven voor toegang tot de gegevens via de Spark-lees-API. De padindeling hier is hetzelfde wanneer u de mssparkutils fs API gebruikt.
Een bestand lezen uit een gekoppeld Data Lake Storage Gen2-opslagaccount
In het volgende voorbeeld wordt ervan uitgegaan dat er al een Data Lake Storage Gen2-opslagaccount is gekoppeld en dat u het bestand vervolgens leest met behulp van een koppelpad:
%%pyspark
df = spark.read.load(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv', format='csv')
df.show()
Notitie
Wanneer u de opslag koppelt met behulp van een gekoppelde service, moet u altijd expliciet de configuratie van de gekoppelde Spark-service instellen voordat u het synfs-schema gebruikt om toegang te krijgen tot de gegevens. Raadpleeg ADLS Gen2-opslag met gekoppelde services voor meer informatie.
Een bestand lezen uit een gekoppeld Blob Storage-account
Als u een Blob Storage-account hebt gekoppeld en dit wilt openen met behulp van mssparkutils of de Spark-API, moet u het SAS-token expliciet configureren via Spark-configuratie voordat u de container probeert te koppelen met behulp van de koppelings-API:
Als u toegang wilt krijgen tot een Blob Storage-account met behulp van
mssparkutilsof de Spark-API na een triggerkoppeling, werkt u de Spark-configuratie bij, zoals wordt weergegeven in het volgende codevoorbeeld. U kunt deze stap overslaan als u alleen toegang wilt krijgen tot de Spark-configuratie met behulp van de API voor het lokale bestand na het koppelen.blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds("myblobstorageaccount") spark.conf.set('fs.azure.sas.mycontainer.<blobStorageAccountName>.blob.core.windows.net', blob_sas_token)Maak de gekoppelde service
myblobstorageaccounten koppel het Blob Storage-account met behulp van de gekoppelde service:%%spark mssparkutils.fs.mount( "wasbs://mycontainer@<blobStorageAccountName>.blob.core.windows.net", "/test", Map("linkedService" -> "myblobstorageaccount") )Koppel de Blob Storage-container en lees het bestand met behulp van een koppelpad via de lokale bestands-API:
# mount the Blob Storage container, and then read the file by using a mount path with open(mssparkutils.fs.getMountPath("/test") + "/myFile.txt") as f: print(f.read())Lees de gegevens uit de gekoppelde Blob Storage-container via de Spark-lees-API:
%%spark // mount blob storage container and then read file using mount path val df = spark.read.text(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.txt') df.show()
Koppelpunt ontkoppelen
Gebruik de volgende code om het koppelpunt los te koppelen (/test in dit voorbeeld):
mssparkutils.fs.unmount("/test")
Bekende beperkingen
Het mechanisme voor ontkoppelen is niet automatisch. Wanneer de uitvoering van de toepassing is voltooid, moet u een ontkoppelings-API expliciet aanroepen in uw code om het koppelpunt los te koppelen om de schijfruimte vrij te geven. Anders bestaat het koppelpunt nog steeds in het knooppunt nadat de uitvoering van de toepassing is voltooid.
Het koppelen van een Data Lake Storage Gen1-opslagaccount wordt voorlopig niet ondersteund.