Inleiding tot Microsoft Spark-hulpprogramma's
Microsoft Spark Utilities (MSSparkUtils) is een ingebouwd pakket om u te helpen eenvoudig algemene taken uit te voeren. U kunt MSSparkUtils gebruiken om te werken met bestandssystemen, om omgevingsvariabelen op te halen, notebooks te koppelen en met geheimen te werken. MSSparkUtils zijn beschikbaar inPySpark (Python), Scalaen .NET Spark (C#)R (Preview) notebooks en Synapse-pijplijnen.
Vereisten
Toegang tot Azure Data Lake Storage Gen2 configureren
Synapse-notebooks gebruiken Microsoft Entra Pass Through voor toegang tot de ADLS Gen2-accounts. U moet een Inzender voor opslagblobgegevens zijn om toegang te krijgen tot het ADLS Gen2-account (of de map).
Synapse-pijplijnen gebruiken de Managed Service Identity (MSI) van de werkruimte voor toegang tot de opslagaccounts. Als u MSSparkUtils wilt gebruiken in uw pijplijnactiviteiten, moet uw werkruimte-id Inzender voor opslagblobgegevens zijn voor toegang tot het ADLS Gen2-account (of de map).
Volg deze stappen om ervoor te zorgen dat uw Microsoft Entra-id en werkruimte-MSI toegang hebben tot het ADLS Gen2-account:
Open Azure Portal en het opslagaccount dat u wilt openen. U kunt naar de specifieke container navigeren die u wilt openen.
Selecteer het toegangsbeheer (IAM) in het linkerdeelvenster.
Selecteer Toevoegen>Roltoewijzing toevoegen om het deelvenster Roltoewijzing toevoegen te openen.
Wijs de volgende rol toe. Raadpleeg Azure-rollen toewijzen met Azure Portal voor informatie over het toewijzen van rollen.
Instelling Weergegeven als Role Inzender voor opslagblobgegevens Toegang toewijzen aan USER en MANAGEDIDENTITY Leden uw Microsoft Entra-account en uw werkruimte-id Notitie
De naam van de beheerde identiteit is ook de naam van de werkruimte.

Selecteer Opslaan.
U hebt toegang tot gegevens in ADLS Gen2 met Synapse Spark via de volgende URL:
abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<path>
Toegang tot Azure Blob Storage configureren
Synapse maakt gebruik van Shared Access Signature (SAS) voor toegang tot Azure Blob Storage. Om te voorkomen dat SAS-sleutels in de code worden weergegeven, raden we u aan om een nieuwe gekoppelde service in de Synapse-werkruimte te maken voor het Azure Blob Storage-account dat u wilt openen.
Volg deze stappen om een nieuwe gekoppelde service toe te voegen voor een Azure Blob Storage-account:
- Open Azure Synapse Studio.
- Selecteer Beheren in het linkerdeelvenster en selecteer Gekoppelde services onder de externe verbindingen.
- Zoek in Azure Blob Storage in het deelvenster Nieuwe gekoppelde service aan de rechterkant.
- Selecteer Doorgaan.
- Selecteer het Azure Blob Storage-account om de naam van de gekoppelde service te openen en te configureren. Stel voor om accountsleutel te gebruiken voor de verificatiemethode.
- Selecteer Verbinding testen om te controleren of de instellingen juist zijn.
- Selecteer Eerst maken en klik op Alles publiceren om uw wijzigingen op te slaan.
U hebt toegang tot gegevens in Azure Blob Storage met Synapse Spark via de volgende URL:
wasb[s]://<container_name>@<storage_account_name>.blob.core.windows.net/<path>
Hier volgt een codevoorbeeld:
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
val blob_account_name = "" // replace with your blob name
val blob_container_name = "" //replace with your container name
val blob_relative_path = "/" //replace with your relative folder path
val linked_service_name = "" //replace with your linked service name
val blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
val wasbs_path = f"wasbs://$blob_container_name@$blob_account_name.blob.core.windows.net/$blob_relative_path"
spark.conf.set(f"fs.azure.sas.$blob_container_name.$blob_account_name.blob.core.windows.net",blob_sas_token)
var blob_account_name = ""; // replace with your blob name
var blob_container_name = ""; // replace with your container name
var blob_relative_path = ""; // replace with your relative folder path
var linked_service_name = ""; // replace with your linked service name
var blob_sas_token = Credentials.GetConnectionStringOrCreds(linked_service_name);
spark.Conf().Set($"fs.azure.sas.{blob_container_name}.{blob_account_name}.blob.core.windows.net", blob_sas_token);
var wasbs_path = $"wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}";
Console.WriteLine(wasbs_path);
# Azure storage access info
blob_account_name <- 'Your account name' # replace with your blob name
blob_container_name <- 'Your container name' # replace with your container name
blob_relative_path <- 'Your path' # replace with your relative folder path
linked_service_name <- 'Your linked service name' # replace with your linked service name
blob_sas_token <- mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
sparkR.session()
wasb_path <- sprintf('wasbs://%s@%s.blob.core.windows.net/%s',blob_container_name, blob_account_name, blob_relative_path)
sparkR.session(sprintf('fs.azure.sas.%s.%s.blob.core.windows.net',blob_container_name, blob_account_name), blob_sas_token)
print( paste('Remote blob path: ',wasb_path))
Toegang tot Azure Key Vault configureren
U kunt een Azure Key Vault als gekoppelde service toevoegen om uw referenties in Synapse te beheren. Volg deze stappen om een Azure Key Vault toe te voegen als een gekoppelde Synapse-service:
Open Azure Synapse Studio.
Selecteer Beheren in het linkerdeelvenster en selecteer Gekoppelde services onder de externe verbindingen.
Zoek in Azure Key Vault in het deelvenster Nieuwe gekoppelde service aan de rechterkant.
Selecteer het Azure Key Vault-account om de naam van de gekoppelde service te openen en te configureren.
Selecteer Verbinding testen om te controleren of de instellingen juist zijn.
Selecteer Eerst maken en klik op Alles publiceren om uw wijziging op te slaan.
Synapse-notebooks gebruiken Microsoft Entra Pass Through voor toegang tot Azure Key Vault. Synapse-pijplijnen gebruiken werkruimte-identiteit (MSI) voor toegang tot Azure Key Vault. Om ervoor te zorgen dat uw code zowel in notebook als in de Synapse-pijplijn werkt, raden we u aan geheime toegangsmachtigingen te verlenen voor zowel uw Microsoft Entra-account als werkruimte-id.
Volg deze stappen om geheime toegang te verlenen tot uw werkruimte-id:
- Open De Azure-portal en de Azure Key Vault die u wilt openen.
- Selecteer het toegangsbeleid in het linkerdeelvenster.
- Selecteer Toegangsbeleid toevoegen:
- Kies Sleutel, Geheim en Certificaatbeheer als configuratiesjabloon.
- Selecteer uw Microsoft Entra-account en uw werkruimte-id (hetzelfde als de naam van uw werkruimte) in de select-principal of zorg ervoor dat deze al is toegewezen.
- Selecteer Selecteren en toevoegen.
- Selecteer de knop Opslaan om wijzigingen door te voeren.
Hulpprogramma's voor bestandssysteem
mssparkutils.fs biedt hulpprogramma's voor het werken met verschillende bestandssystemen, waaronder Azure Data Lake Storage Gen2 (ADLS Gen2) en Azure Blob Storage. Zorg ervoor dat u de toegang tot Azure Data Lake Storage Gen2 en Azure Blob Storage op de juiste manier configureert.
Voer de volgende opdrachten uit voor een overzicht van de beschikbare methoden:
from notebookutils import mssparkutils
mssparkutils.fs.help()
mssparkutils.fs.help()
using Microsoft.Spark.Extensions.Azure.Synapse.Analytics.Notebook.MSSparkUtils;
FS.Help()
library(notebookutils)
mssparkutils.fs.help()
Resulteert in:
mssparkutils.fs provides utilities for working with various FileSystems.
Below is overview about the available methods:
cp(from: String, to: String, recurse: Boolean = false): Boolean -> Copies a file or directory, possibly across FileSystems
mv(src: String, dest: String, create_path: Boolean = False, overwrite: Boolean = False): Boolean -> Moves a file or directory, possibly across FileSystems
ls(dir: String): Array -> Lists the contents of a directory
mkdirs(dir: String): Boolean -> Creates the given directory if it does not exist, also creating any necessary parent directories
put(file: String, contents: String, overwrite: Boolean = false): Boolean -> Writes the given String out to a file, encoded in UTF-8
head(file: String, maxBytes: int = 1024 * 100): String -> Returns up to the first 'maxBytes' bytes of the given file as a String encoded in UTF-8
append(file: String, content: String, createFileIfNotExists: Boolean): Boolean -> Append the content to a file
rm(dir: String, recurse: Boolean = false): Boolean -> Removes a file or directory
Use mssparkutils.fs.help("methodName") for more info about a method.
Bestanden in een lijst weergeven
De inhoud van een map weergeven.
mssparkutils.fs.ls('Your directory path')
mssparkutils.fs.ls("Your directory path")
FS.Ls("Your directory path")
mssparkutils.fs.ls("Your directory path")
Bestandseigenschappen weergeven
Retourneert bestandseigenschappen, waaronder bestandsnaam, bestandspad, bestandsgrootte, wijzigingstijd van bestanden en of het een map en een bestand is.
files = mssparkutils.fs.ls('Your directory path')
for file in files:
print(file.name, file.isDir, file.isFile, file.path, file.size, file.modifyTime)
val files = mssparkutils.fs.ls("/")
files.foreach{
file => println(file.name,file.isDir,file.isFile,file.size,file.modifyTime)
}
var Files = FS.Ls("/");
foreach(var File in Files) {
Console.WriteLine(File.Name+" "+File.IsDir+" "+File.IsFile+" "+File.Size);
}
files <- mssparkutils.fs.ls("/")
for (file in files) {
writeLines(paste(file$name, file$isDir, file$isFile, file$size, file$modifyTime))
}
Nieuwe map maken
Hiermee maakt u de opgegeven map als deze niet bestaat en eventuele benodigde bovenliggende mappen.
mssparkutils.fs.mkdirs('new directory name')
mssparkutils.fs.mkdirs("new directory name")
FS.Mkdirs("new directory name")
mssparkutils.fs.mkdirs("new directory name")
Bestand kopiëren
Kopieert een bestand of map. Ondersteunt kopiëren tussen bestandssystemen.
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)# Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
FS.Cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)
Performant kopieerbestand
Deze methode biedt een snellere manier om bestanden te kopiëren of te verplaatsen, met name grote hoeveelheden gegevens.
mssparkutils.fs.fastcp('source file or directory', 'destination file or directory', True) # Set the third parameter as True to copy all files and directories recursively
Notitie
De methode ondersteunt alleen in Azure Synapse Runtime voor Apache Spark 3.3 en Azure Synapse Runtime voor Apache Spark 3.4.
Voorbeeld van bestandsinhoud
Retourneert tot de eerste 'maxBytes' bytes van het opgegeven bestand als een tekenreeks die is gecodeerd in UTF-8.
mssparkutils.fs.head('file path', maxBytes to read)
mssparkutils.fs.head("file path", maxBytes to read)
FS.Head("file path", maxBytes to read)
mssparkutils.fs.head('file path', maxBytes to read)
Bestand verplaatsen
Hiermee verplaatst u een bestand of map. Ondersteunt verplaatsing tussen bestandssystemen.
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
mssparkutils.fs.mv("source file or directory", "destination directory", true) // Set the last parameter as True to firstly create the parent directory if it does not exist
FS.Mv("source file or directory", "destination directory", true)
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
Bestand schrijven
Hiermee schrijft u de opgegeven tekenreeks naar een bestand, gecodeerd in UTF-8.
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
FS.Put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
Inhoud toevoegen aan een bestand
Voegt de opgegeven tekenreeks toe aan een bestand, gecodeerd in UTF-8.
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path","content to append",true) // Set the last parameter as True to create the file if it does not exist
FS.Append("file path", "content to append", true) // Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
Notitie
mssparkutils.fs.append()enmssparkutils.fs.put()bieden geen ondersteuning voor gelijktijdig schrijven naar hetzelfde bestand vanwege een gebrek aan atomiciteitsgaranties.- Wanneer u de
mssparkutils.fs.appendAPI in eenforlus gebruikt om naar hetzelfde bestand te schrijven, wordt u aangeraden eensleepinstructie rond 0,5s~1s toe te voegen tussen de terugkerende schrijfbewerkingen. Dit komt doordat de interneflushbewerking van demssparkutils.fs.appendAPI asynchroon is, dus een korte vertraging zorgt voor gegevensintegriteit.
Bestand of map verwijderen
Hiermee verwijdert u een bestand of map.
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
FS.Rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
Hulpprogramma's voor notitieblokken
Wordt niet ondersteund.
U kunt de MSSparkUtils Notebook Utilities gebruiken om een notebook uit te voeren of een notebook af te sluiten met een waarde. Voer de volgende opdracht uit om een overzicht te krijgen van de beschikbare methoden:
mssparkutils.notebook.help()
Resultaten ophalen:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Notitie
Hulpprogramma's voor notebooks zijn niet van toepassing op Apache Spark-taakdefinities (SJD).
Verwijzen naar een notitieblok
Verwijs naar een notebook en retourneert de afsluitwaarde. U kunt geneste functie-aanroepen in een notebook interactief of in een pijplijn uitvoeren. Het notebook waarnaar wordt verwezen, wordt uitgevoerd in de Spark-pool van welke notebook deze functie aanroept.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Voorbeeld:
mssparkutils.notebook.run("folder/Sample1", 90, {"input": 20 })
Nadat de uitvoering is voltooid, ziet u een momentopnamekoppeling met de naam 'Uitvoering van notitieblok weergeven: Naam van notitieblok' weergegeven in de celuitvoer. U kunt op de koppeling klikken om de momentopname voor deze specifieke uitvoering te zien.

Naslaginformatie over het parallel uitvoeren van meerdere notebooks
Met de methode mssparkutils.notebook.runMultiple() kunt u meerdere notebooks parallel of met een vooraf gedefinieerde topologische structuur uitvoeren. De API maakt gebruik van een implementatiemechanisme met meerdere threads binnen een Spark-sessie, wat betekent dat de rekenresources worden gedeeld door de referentienotebookuitvoeringen.
Met mssparkutils.notebook.runMultiple()kunt u het volgende doen:
Voer meerdere notebooks tegelijk uit, zonder te wachten tot elke notebook is voltooid.
Geef de afhankelijkheden en de volgorde van uitvoering voor uw notebooks op met behulp van een eenvoudige JSON-indeling.
Optimaliseer het gebruik van Spark-rekenresources en verlaag de kosten van uw Synapse-projecten.
Bekijk de momentopnamen van elke notebookuitvoeringsrecord in de uitvoer en foutopsporing/bewaak uw notebooktaken gemakkelijk.
Haal de afsluitwaarde van elke leidinggevende activiteit op en gebruik deze in downstreamtaken.
U kunt ook proberen de mssparkutils.notebook.help("runMultiple") uit te voeren om het voorbeeld en het gedetailleerde gebruik te vinden.
Hier volgt een eenvoudig voorbeeld van het parallel uitvoeren van een lijst met notebooks met behulp van deze methode:
mssparkutils.notebook.runMultiple(["NotebookSimple", "NotebookSimple2"])
Het uitvoerresultaat van het hoofdnotebook is als volgt:

Hier volgt een voorbeeld van het uitvoeren van notebooks met topologische structuur met behulp van mssparkutils.notebook.runMultiple(). Gebruik deze methode om eenvoudig notebooks te organiseren via een code-ervaring.
# run multiple notebooks with parameters
DAG = {
"activities": [
{
"name": "NotebookSimple", # activity name, must be unique
"path": "NotebookSimple", # notebook path
"timeoutPerCellInSeconds": 90, # max timeout for each cell, default to 90 seconds
"args": {"p1": "changed value", "p2": 100}, # notebook parameters
},
{
"name": "NotebookSimple2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 2", "p2": 200}
},
{
"name": "NotebookSimple2.2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 3", "p2": 300},
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["NotebookSimple"] # list of activity names that this activity depends on
}
]
}
mssparkutils.notebook.runMultiple(DAG)
Notitie
- De methode ondersteunt alleen in Azure Synapse Runtime voor Apache Spark 3.3 en Azure Synapse Runtime voor Apache Spark 3.4.
- De mate van parallelle uitvoering van meerdere notebooks is beperkt tot de totale beschikbare rekenresource van een Spark-sessie.
Een notitieblok afsluiten
Hiermee wordt een notitieblok afgesloten met een waarde. U kunt geneste functie-aanroepen in een notebook interactief of in een pijplijn uitvoeren.
Wanneer u een exit() -functie aanroept vanuit een notebook, genereert Azure Synapse een uitzondering, slaat u subsequencecellen over en blijft de Spark-sessie actief.
Wanneer u een notebook organiseert dat een
exit()functie aanroept in een Synapse-pijplijn, retourneert Azure Synapse een afsluitwaarde, voltooit u de pijplijnuitvoering en stopt u de Spark-sessie.Wanneer u een
exit()functie aanroept in een notebook waarnaar wordt verwezen, stopt Azure Synapse de verdere uitvoering in het notebook waarnaar wordt verwezen en gaat u verder met het uitvoeren van volgende cellen in het notebook waarmee derun()functie wordt aangeroepen. Bijvoorbeeld: Notebook1 heeft drie cellen en roept eenexit()functie aan in de tweede cel. Notebook2 heeft vijf cellen en aanroepenrun(notebook1)in de derde cel. Wanneer u Notebook2 uitvoert, wordt Notebook1 gestopt in de tweede cel wanneer u deexit()functie bereikt. Notebook2 blijft de vierde cel en vijfde cel uitvoeren.
mssparkutils.notebook.exit("value string")
Voorbeeld:
Voorbeeld1 notebook zoekt onder map/ met de volgende twee cellen:
- cel 1 definieert een invoerparameter met de standaardwaarde ingesteld op 10.
- cel 2 sluit het notitieblok af met invoer als afsluitwaarde.
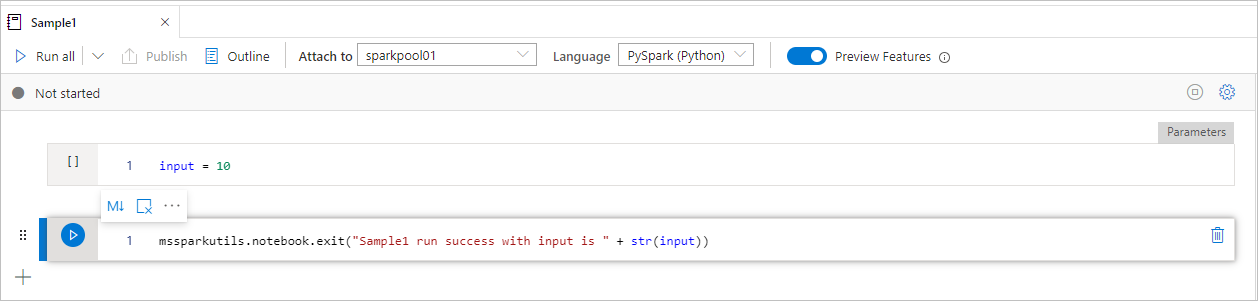
U kunt het voorbeeld1 uitvoeren in een ander notebook met standaardwaarden:
exitVal = mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
Resulteert in:
Sample1 run success with input is 10
U kunt het voorbeeld1 uitvoeren in een ander notebook en de invoerwaarde instellen als 20:
exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print (exitVal)
Resulteert in:
Sample1 run success with input is 20
U kunt de MSSparkUtils Notebook Utilities gebruiken om een notebook uit te voeren of een notebook af te sluiten met een waarde. Voer de volgende opdracht uit om een overzicht te krijgen van de beschikbare methoden:
mssparkutils.notebook.help()
Resultaten ophalen:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Verwijzen naar een notitieblok
Verwijs naar een notebook en retourneert de afsluitwaarde. U kunt geneste functie-aanroepen in een notebook interactief of in een pijplijn uitvoeren. Het notebook waarnaar wordt verwezen, wordt uitgevoerd in de Spark-pool van welke notebook deze functie aanroept.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Voorbeeld:
mssparkutils.notebook.run("folder/Sample1", 90, Map("input" -> 20))
Nadat de uitvoering is voltooid, ziet u een momentopnamekoppeling met de naam 'Uitvoering van notitieblok weergeven: Naam van notitieblok' weergegeven in de celuitvoer. U kunt op de koppeling klikken om de momentopname voor deze specifieke uitvoering te zien.
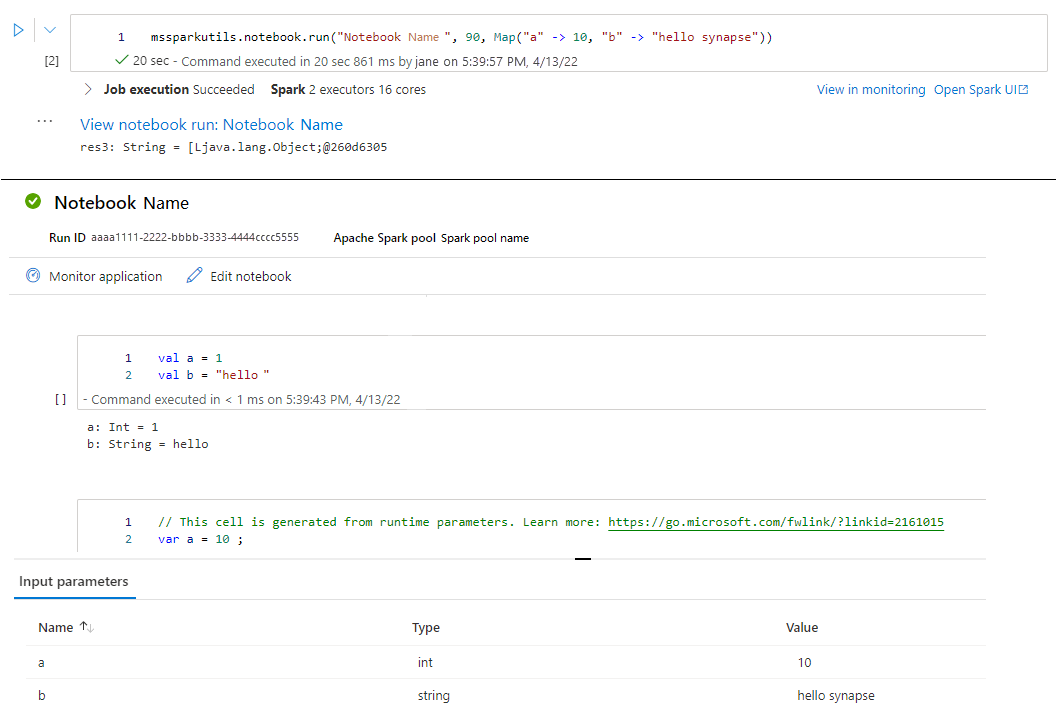
Een notitieblok afsluiten
Hiermee wordt een notitieblok afgesloten met een waarde. U kunt geneste functie-aanroepen in een notebook interactief of in een pijplijn uitvoeren.
Wanneer u een
exit()functie interactief aanroept, genereert Azure Synapse een uitzondering, slaat u het uitvoeren van subsequencecellen over en blijft de Spark-sessie actief.Wanneer u een notebook organiseert dat een
exit()functie aanroept in een Synapse-pijplijn, retourneert Azure Synapse een afsluitwaarde, voltooit u de pijplijnuitvoering en stopt u de Spark-sessie.Wanneer u een
exit()functie aanroept in een notebook waarnaar wordt verwezen, stopt Azure Synapse de verdere uitvoering in het notebook waarnaar wordt verwezen en gaat u verder met het uitvoeren van volgende cellen in het notebook waarmee derun()functie wordt aangeroepen. Bijvoorbeeld: Notebook1 heeft drie cellen en roept eenexit()functie aan in de tweede cel. Notebook2 heeft vijf cellen en aanroepenrun(notebook1)in de derde cel. Wanneer u Notebook2 uitvoert, wordt Notebook1 gestopt in de tweede cel wanneer u deexit()functie bereikt. Notebook2 blijft de vierde cel en vijfde cel uitvoeren.
mssparkutils.notebook.exit("value string")
Voorbeeld:
Voorbeeld1 notebook zoekt onder mssparkutils/folder/ met de volgende twee cellen:
- cel 1 definieert een invoerparameter met de standaardwaarde ingesteld op 10.
- cel 2 sluit het notitieblok af met invoer als afsluitwaarde.
U kunt het voorbeeld1 uitvoeren in een ander notebook met standaardwaarden:
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1")
print(exitVal)
Resulteert in:
exitVal: String = Sample1 run success with input is 10
Sample1 run success with input is 10
U kunt het voorbeeld1 uitvoeren in een ander notebook en de invoerwaarde instellen als 20:
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print(exitVal)
Resulteert in:
exitVal: String = Sample1 run success with input is 20
Sample1 run success with input is 20
U kunt de MSSparkUtils Notebook Utilities gebruiken om een notebook uit te voeren of een notebook af te sluiten met een waarde. Voer de volgende opdracht uit om een overzicht te krijgen van de beschikbare methoden:
mssparkutils.notebook.help()
Resultaten ophalen:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Verwijzen naar een notitieblok
Verwijs naar een notebook en retourneert de afsluitwaarde. U kunt geneste functie-aanroepen in een notebook interactief of in een pijplijn uitvoeren. Het notebook waarnaar wordt verwezen, wordt uitgevoerd in de Spark-pool van welke notebook deze functie aanroept.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Voorbeeld:
mssparkutils.notebook.run("folder/Sample1", 90, list("input": 20))
Nadat de uitvoering is voltooid, ziet u een momentopnamekoppeling met de naam 'Uitvoering van notitieblok weergeven: Naam van notitieblok' weergegeven in de celuitvoer. U kunt op de koppeling klikken om de momentopname voor deze specifieke uitvoering te zien.
Een notitieblok afsluiten
Hiermee wordt een notitieblok afgesloten met een waarde. U kunt geneste functie-aanroepen in een notebook interactief of in een pijplijn uitvoeren.
Wanneer u een
exit()functie interactief aanroept, genereert Azure Synapse een uitzondering, slaat u het uitvoeren van subsequencecellen over en blijft de Spark-sessie actief.Wanneer u een notebook organiseert dat een
exit()functie aanroept in een Synapse-pijplijn, retourneert Azure Synapse een afsluitwaarde, voltooit u de pijplijnuitvoering en stopt u de Spark-sessie.Wanneer u een
exit()functie aanroept in een notebook waarnaar wordt verwezen, stopt Azure Synapse de verdere uitvoering in het notebook waarnaar wordt verwezen en gaat u verder met het uitvoeren van volgende cellen in het notebook waarmee derun()functie wordt aangeroepen. Bijvoorbeeld: Notebook1 heeft drie cellen en roept eenexit()functie aan in de tweede cel. Notebook2 heeft vijf cellen en aanroepenrun(notebook1)in de derde cel. Wanneer u Notebook2 uitvoert, wordt Notebook1 gestopt in de tweede cel wanneer u deexit()functie bereikt. Notebook2 blijft de vierde cel en vijfde cel uitvoeren.
mssparkutils.notebook.exit("value string")
Voorbeeld:
Voorbeeld1 notebook zoekt onder map/ met de volgende twee cellen:
- cel 1 definieert een invoerparameter met de standaardwaarde ingesteld op 10.
- cel 2 sluit het notitieblok af met invoer als afsluitwaarde.
U kunt het voorbeeld1 uitvoeren in een ander notebook met standaardwaarden:
exitVal <- mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
Resulteert in:
Sample1 run success with input is 10
U kunt het voorbeeld1 uitvoeren in een ander notebook en de invoerwaarde instellen als 20:
exitVal <- mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, list("input": 20))
print (exitVal)
Resulteert in:
Sample1 run success with input is 20
Hulpprogramma's voor referenties
U kunt de MSSparkUtils Credentials Credentials Utilities gebruiken om de toegangstokens van gekoppelde services op te halen en geheimen te beheren in Azure Key Vault.
Voer de volgende opdracht uit om een overzicht te krijgen van de beschikbare methoden:
mssparkutils.credentials.help()
mssparkutils.credentials.help()
Not supported.
mssparkutils.credentials.help()
Resultaat ophalen:
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Notitie
GetSecretWithLS(linkedService, secret) wordt momenteel niet ondersteund in C#.
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Token ophalen
Retourneert Microsoft Entra-token voor een bepaalde doelgroep, naam (optioneel). De onderstaande tabel bevat alle beschikbare doelgroeptypen:
| Doelgroeptype | Letterlijke tekenreeks die moet worden gebruikt in API-aanroep |
|---|---|
| Azure Storage | Storage |
| Azure Key Vault | Vault |
| Azure-beheer | AzureManagement |
| Azure SQL Data Warehouse (toegewezen en serverloos) | DW |
| Azure Synapse | Synapse |
| Azure Data Lake Store | DataLakeStore |
| Azure Data Factory | ADF |
| Azure Data Explorer | AzureDataExplorer |
| Azure Database for MySQL | AzureOSSDB |
| Azure Database for MariaDB | AzureOSSDB |
| Azure Database for PostgreSQL | AzureOSSDB |
mssparkutils.credentials.getToken('audience Key')
mssparkutils.credentials.getToken("audience Key")
Credentials.GetToken("audience Key")
mssparkutils.credentials.getToken('audience Key')
Token valideren
Retourneert waar als het token niet is verlopen.
mssparkutils.credentials.isValidToken('your token')
mssparkutils.credentials.isValidToken("your token")
Credentials.IsValidToken("your token")
mssparkutils.credentials.isValidToken('your token')
Verbindingsreeks of referenties voor gekoppelde service ophalen
Retourneert verbindingsreeks of referenties voor gekoppelde service.
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
mssparkutils.credentials.getConnectionStringOrCreds("linked service name")
Credentials.GetConnectionStringOrCreds("linked service name")
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
Geheim ophalen met behulp van werkruimte-identiteit
Retourneert Azure Key Vault-geheim voor een bepaalde Azure Key Vault-naam, geheime naam en gekoppelde servicenaam met behulp van de werkruimte-id. Zorg ervoor dat u de toegang tot Azure Key Vault op de juiste manier configureert.
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
mssparkutils.credentials.getSecret("azure key vault name","secret name","linked service name")
Credentials.GetSecret("azure key vault name","secret name","linked service name")
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
Geheim ophalen met gebruikersreferenties
Retourneert Azure Key Vault-geheim voor een bepaalde Azure Key Vault-naam, geheime naam en gekoppelde servicenaam met behulp van gebruikersreferenties.
mssparkutils.credentials.getSecret('azure key vault name','secret name')
mssparkutils.credentials.getSecret("azure key vault name","secret name")
Credentials.GetSecret("azure key vault name","secret name")
mssparkutils.credentials.getSecret('azure key vault name','secret name')
Geheim plaatsen met behulp van werkruimte-id
Plaatst Azure Key Vault-geheim voor een bepaalde Azure Key Vault-naam, geheime naam en gekoppelde servicenaam met behulp van werkruimte-id. Zorg ervoor dat u de toegang tot Azure Key Vault op de juiste manier configureert.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Geheim plaatsen met behulp van werkruimte-id
Plaatst Azure Key Vault-geheim voor een bepaalde Azure Key Vault-naam, geheime naam en gekoppelde servicenaam met behulp van werkruimte-id. Zorg ervoor dat u de toegang tot Azure Key Vault op de juiste manier configureert.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value","linked service name")
Geheim plaatsen met behulp van werkruimte-id
Plaatst Azure Key Vault-geheim voor een bepaalde Azure Key Vault-naam, geheime naam en gekoppelde servicenaam met behulp van werkruimte-id. Zorg ervoor dat u de toegang tot Azure Key Vault op de juiste manier configureert.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Geheim plaatsen met gebruikersreferenties
Plaatst Azure Key Vault-geheim voor een bepaalde Azure Key Vault-naam, geheime naam en gekoppelde servicenaam met behulp van gebruikersreferenties.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Geheim plaatsen met gebruikersreferenties
Plaatst Azure Key Vault-geheim voor een bepaalde Azure Key Vault-naam, geheime naam en gekoppelde servicenaam met behulp van gebruikersreferenties.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Geheim plaatsen met gebruikersreferenties
Plaatst Azure Key Vault-geheim voor een bepaalde Azure Key Vault-naam, geheime naam en gekoppelde servicenaam met behulp van gebruikersreferenties.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value")
Omgevingshulpprogramma's
Voer de volgende opdrachten uit om een overzicht te krijgen van de beschikbare methoden:
mssparkutils.env.help()
mssparkutils.env.help()
mssparkutils.env.help()
Env.Help()
Resultaat ophalen:
getUserName(): returns user name
getUserId(): returns unique user id
getJobId(): returns job id
getWorkspaceName(): returns workspace name
getPoolName(): returns Spark pool name
getClusterId(): returns cluster id
Gebruikersnaam ophalen
Retourneert de huidige gebruikersnaam.
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
Env.GetUserName()
Gebruikers-id ophalen
Retourneert de huidige gebruikers-id.
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
Env.GetUserId()
Taak-id ophalen
Retourneert taak-id.
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
Env.GetJobId()
Werkruimtenaam ophalen
Retourneert de naam van de werkruimte.
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
Env.GetWorkspaceName()
Naam van pool ophalen
Retourneert de naam van de Spark-pool.
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
Env.GetPoolName()
Cluster-id ophalen
Retourneert de huidige cluster-id.
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
Env.GetClusterId()
Runtimecontext
Mssparkutils runtime utils blootgesteld 3 runtime-eigenschappen, u kunt de mssparkutils runtime context gebruiken om de eigenschappen op te halen die hieronder worden vermeld:
- Notebookname : de naam van het huidige notitieblok retourneert altijd waarde voor zowel de interactieve modus als de pijplijnmodus.
- Pipelinejobid : de id van de pijplijnuitvoering, retourneert waarde in de pijplijnmodus en retourneert een lege tekenreeks in de interactieve modus.
- Activityrunid : de run-id van de notebookactiviteit retourneert waarde in de pijplijnmodus en retourneert een lege tekenreeks in de interactieve modus.
Momenteel ondersteunt runtimecontext zowel Python als Scala.
mssparkutils.runtime.context
ctx <- mssparkutils.runtime.context()
for (key in ls(ctx)) {
writeLines(paste(key, ctx[[key]], sep = "\t"))
}
%%spark
mssparkutils.runtime.context
Sessiebeheer
Een interactieve sessie stoppen
In plaats van handmatig op de knop Stoppen te klikken, is het soms handiger om een interactieve sessie te stoppen door een API aan te roepen in de code. In dergelijke gevallen bieden we een API mssparkutils.session.stop() ter ondersteuning van het stoppen van de interactieve sessie via code, deze is beschikbaar voor Scala en Python.
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop() DE API stopt de huidige interactieve sessie asynchroon op de achtergrond, het stopt de Spark-sessie en brengt resources vrij die door de sessie worden bezet, zodat ze beschikbaar zijn voor andere sessies in dezelfde pool.
Notitie
Het is niet raadzaam om ingebouwde API's voor aanroepen, zoals sys.exit in Scala of sys.exit() Python, aan te roepen in uw code, omdat dergelijke API's het interpreterproces gewoon beëindigen, waardoor Spark-sessie actief blijft en resources niet worden vrijgegeven.
Pakketafhankelijkheden
Als u notebooks of taken lokaal wilt ontwikkelen en moet verwijzen naar de relevante pakketten voor compilatie/IDE-hints, kunt u de volgende pakketten gebruiken.