Logboeken en metrische gegevens van Uw Apache Spark-toepassingen verzamelen met behulp van een Azure Storage-account
De diagnostische emitterextensie van Synapse Apache Spark is een bibliotheek waarmee de Apache Spark-toepassing de logboeken, gebeurtenislogboeken en metrische gegevens naar een of meer bestemmingen kan verzenden, waaronder Azure Log Analytics, Azure Storage en Azure Event Hubs.
In deze zelfstudie leert u hoe u de diagnostische emitterextensie van Synapse Apache Spark gebruikt om logboeken, gebeurtenislogboeken en metrische gegevens van Apache Spark-toepassingen te verzenden naar uw Azure-opslagaccount.
Logboeken en metrische gegevens verzamelen voor opslagaccount
Stap 1: Een opslagaccount maken
Als u diagnostische logboeken en metrische gegevens voor het opslagaccount wilt verzamelen, kunt u bestaande Azure Storage-accounts gebruiken. Of als u er nog geen hebt, kunt u een Azure Blob Storage-account maken of een opslagaccount maken voor gebruik met Azure Data Lake Storage Gen2.
Stap 2: een Apache Spark-configuratiebestand maken
Maak een diagnostic-emitter-azure-storage-conf.txt en kopieer de volgende inhoud naar het bestand. Of download een voorbeeldsjabloonbestand voor de configuratie van apache Spark-pools.
spark.synapse.diagnostic.emitters MyDestination1
spark.synapse.diagnostic.emitter.MyDestination1.type AzureStorage
spark.synapse.diagnostic.emitter.MyDestination1.categories Log,EventLog,Metrics
spark.synapse.diagnostic.emitter.MyDestination1.uri https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>
spark.synapse.diagnostic.emitter.MyDestination1.auth AccessKey
spark.synapse.diagnostic.emitter.MyDestination1.secret <storage-access-key>
Vul de volgende parameters in het configuratiebestand in: <my-blob-storage>, <container-name>, , <folder-name>. <storage-access-key>
Voor meer beschrijving van de parameters kunt u verwijzen naar Azure Storage-configuraties
Stap 3: Upload het Apache Spark-configuratiebestand naar Synapse Studio en gebruik het in de Spark-pool
- Open de pagina Apache Spark-configuraties (Beheren -> Apache Spark-configuraties).
- Klik op de knop Importeren om het Apache Spark-configuratiebestand te uploaden naar Synapse Studio.
- Navigeer naar uw Apache Spark-pool in Synapse Studio (Beheren -> Apache Spark-pools).
- Klik op de knop '...' rechts van uw Apache Spark-pool en selecteer de Apache Spark-configuratie.
- U kunt het configuratiebestand selecteren dat u zojuist hebt geüpload in de vervolgkeuzelijst.
- Klik op Toepassen nadat u het configuratiebestand hebt geselecteerd.
Stap 4: De logboekbestanden in het Azure-opslagaccount weergeven
Nadat u een taak hebt verzonden naar de geconfigureerde Apache Spark-pool, moet u de logboeken en metrische gegevensbestanden in het doelopslagaccount kunnen zien.
De logboeken worden in overeenkomstige paden geplaatst volgens verschillende toepassingen door <workspaceName>.<sparkPoolName>.<livySessionId>.
Alle logboekbestanden hebben de indeling van JSON-regels (ook wel newline-gescheiden JSON, ndjson genoemd), wat handig is voor gegevensverwerking.
Beschikbare configuraties
| Configuratie | Beschrijving |
|---|---|
spark.synapse.diagnostic.emitters |
Vereist. De door komma's gescheiden doelnamen van diagnostische emitters. Bijvoorbeeld MyDest1,MyDest2 |
spark.synapse.diagnostic.emitter.<destination>.type |
Vereist. Ingebouwd doeltype. Als u azure-opslagbestemming wilt inschakelen, AzureStorage moet u in dit veld worden opgenomen. |
spark.synapse.diagnostic.emitter.<destination>.categories |
Optioneel. De door komma's gescheiden geselecteerde logboekcategorieën. Beschikbare waarden zijn onder andere DriverLog, ExecutorLog, EventLog. Metrics Als deze niet is ingesteld, is de standaardwaarde alle categorieën. |
spark.synapse.diagnostic.emitter.<destination>.auth |
Vereist. AccessKeyvoor het gebruik van toegangssleutelautorisatie voor opslagaccounts. SASvoor autorisatie van handtekeningen voor gedeelde toegang. |
spark.synapse.diagnostic.emitter.<destination>.uri |
Vereist. De doel-blobcontainermap-URI. Moet overeenkomen met het patroon https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>. |
spark.synapse.diagnostic.emitter.<destination>.secret |
Optioneel. De geheime inhoud (AccessKey of SAS). |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault |
Vereist als .secret dit niet is opgegeven. De naam van de Azure Key Vault waar het geheim (AccessKey of SAS) is opgeslagen. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.secretName |
Vereist als .secret.keyVault dit is opgegeven. De naam van het Azure Key Vault-geheim waar het geheim (AccessKey of SAS) is opgeslagen. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.linkedService |
Optioneel. De naam van de gekoppelde Azure Key Vault-service. Wanneer deze functie is ingeschakeld in de Synapse-pijplijn, is dit nodig om het geheim van AKV te verkrijgen. (Zorg ervoor dat MSI leesmachtigingen heeft voor de AKV). |
spark.synapse.diagnostic.emitter.<destination>.filter.eventName.match |
Optioneel. De namen van door komma's gescheiden Spark-gebeurtenissen kunt u opgeven welke gebeurtenissen moeten worden verzameld. Bijvoorbeeld: SparkListenerApplicationStart,SparkListenerApplicationEnd |
spark.synapse.diagnostic.emitter.<destination>.filter.loggerName.match |
Optioneel. De door komma's gescheiden log4j-logboeknamen kunt u opgeven welke logboeken moeten worden verzameld. Bijvoorbeeld: org.apache.spark.SparkContext,org.example.Logger |
spark.synapse.diagnostic.emitter.<destination>.filter.metricName.match |
Optioneel. Met de door komma's gescheiden naamachtervoegsels voor spark-metrische gegevens kunt u opgeven welke metrische gegevens moeten worden verzameld. Bijvoorbeeld: jvm.heap.used |
Voorbeeld van logboekgegevens
Hier volgt een voorbeeld van een logboekrecord in JSON-indeling:
{
"timestamp": "2021-01-02T12:34:56.789Z",
"category": "Log|EventLog|Metrics",
"workspaceName": "<my-workspace-name>",
"sparkPool": "<spark-pool-name>",
"livyId": "<livy-session-id>",
"applicationId": "<application-id>",
"applicationName": "<application-name>",
"executorId": "<driver-or-executor-id>",
"properties": {
// The message properties of logs, events and metrics.
"timestamp": "2021-01-02T12:34:56.789Z",
"message": "Registering signal handler for TERM",
"logger_name": "org.apache.spark.util.SignalUtils",
"level": "INFO",
"thread_name": "main"
// ...
}
}
Synapse-werkruimte waarvoor beveiliging tegen gegevensexfiltratie is ingeschakeld
Azure Synapse Analytics-werkruimten bieden ondersteuning voor het inschakelen van gegevensexfiltratiebeveiliging voor werkruimten. Met exfiltratiebeveiliging kunnen de logboeken en metrische gegevens niet rechtstreeks naar de doeleindpunten worden verzonden. In dit scenario kunt u bijbehorende beheerde privé-eindpunten maken voor verschillende doeleindpunten of IP-firewallregels maken.
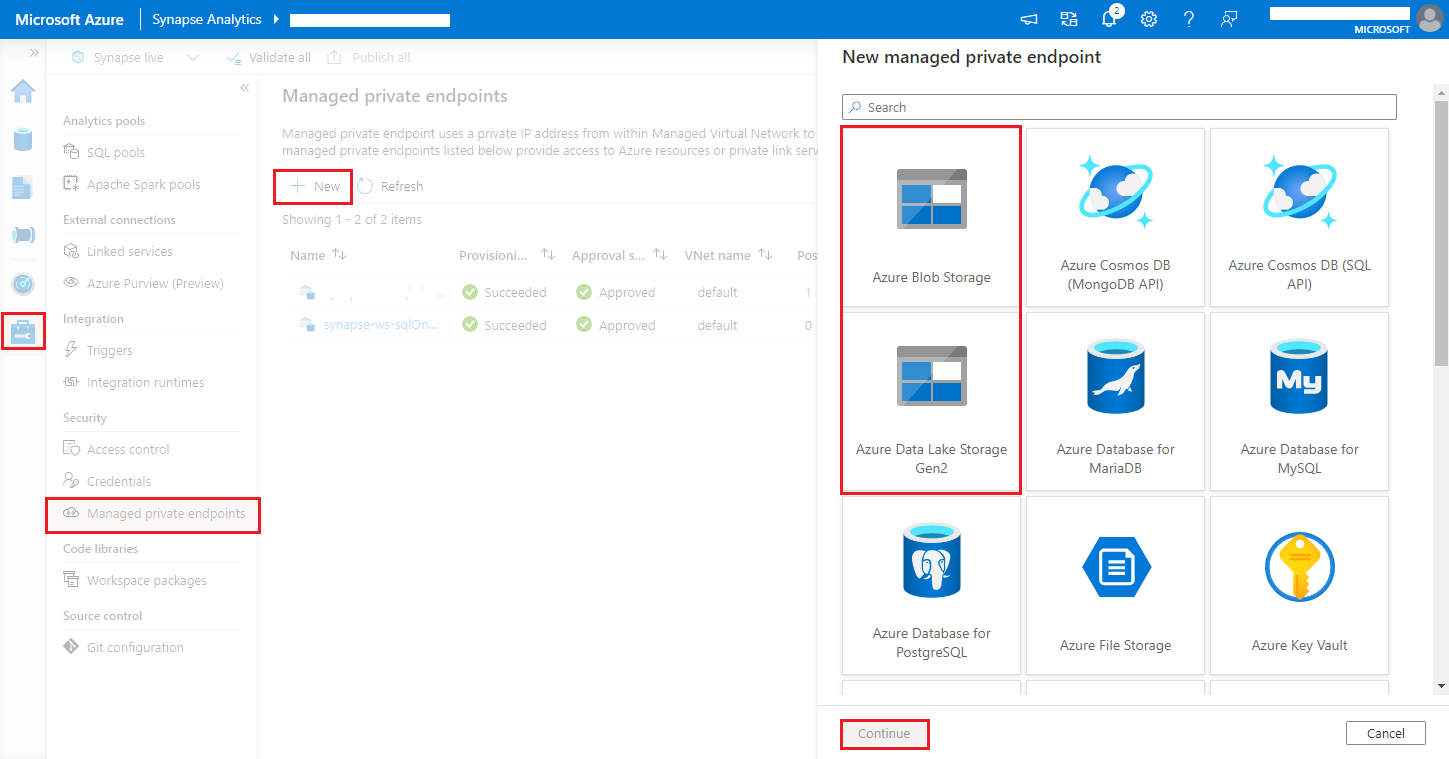
Navigeer naar Synapse Studio > Beheerde privé-eindpunten beheren>, klik op de knop Nieuw, selecteer Azure Blob Storage of Azure Data Lake Storage Gen2 en ga door.
Notitie
We kunnen zowel Azure Blob Storage als Azure Data Lake Storage Gen2 ondersteunen. Maar we konden de abfss:// -indeling niet parseren. Azure Data Lake Storage Gen2-eindpunten moeten worden opgemaakt als een blob-URL:
https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>Kies uw Azure Storage-account in de naam van het opslagaccount en klik op de knop Maken.
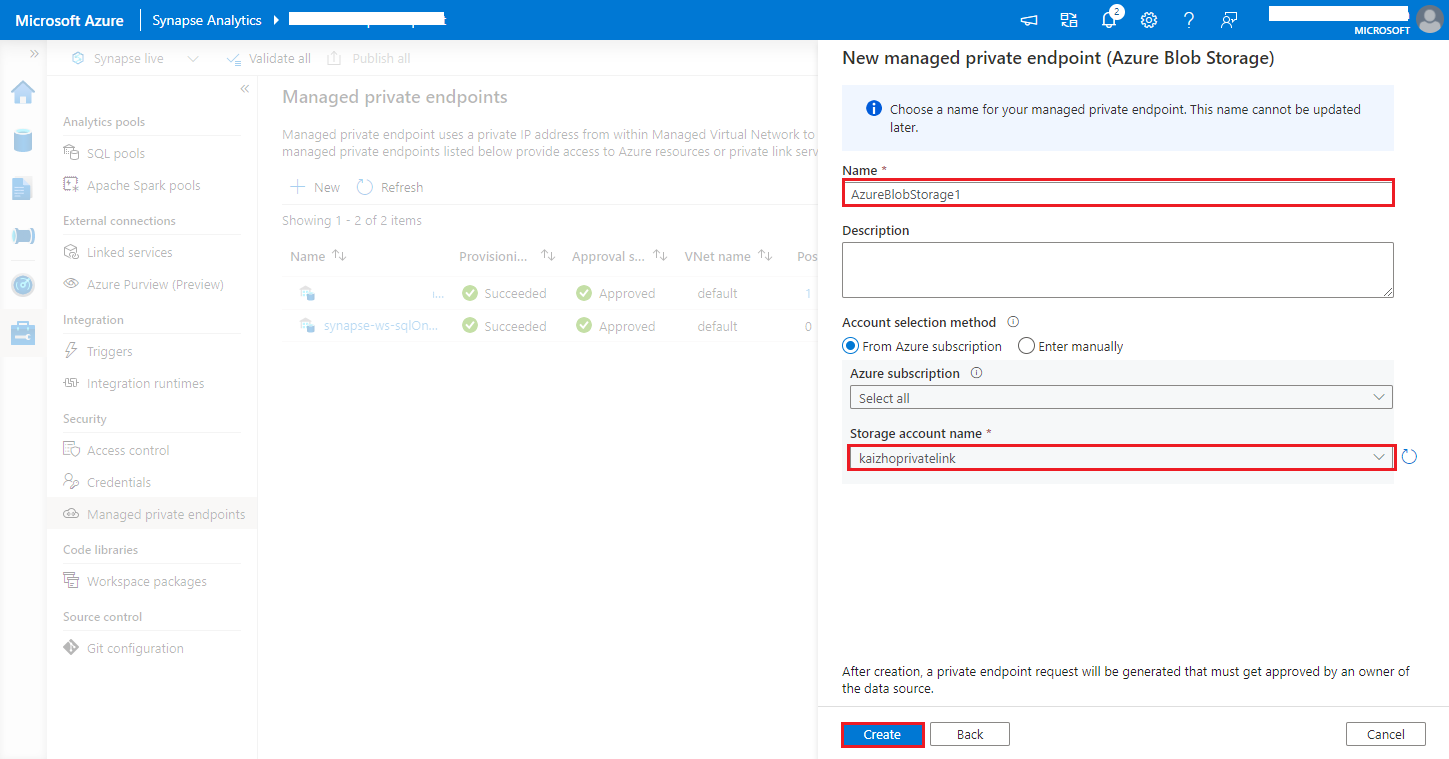
Wacht enkele minuten tot het inrichten van privé-eindpunten is uitgevoerd.
Ga naar uw opslagaccount in Azure Portal en selecteer op de >pagina Verbindingen met privé-eindpunten voor netwerken de verbinding die is ingericht en goedkeuren.