Overzicht van architectuur voor clusterresourcebeheer
Service Fabric Cluster Resource Manager is een centrale service die in het cluster wordt uitgevoerd. Het beheert de gewenste status van de services in het cluster, met name met betrekking tot resourceverbruik en eventuele plaatsingsregels.
Als u de resources in uw cluster wilt beheren, moet de Service Fabric-clusterbronbeheer verschillende gegevens bevatten:
- Welke services er momenteel bestaan
- Het huidige (of standaard) resourceverbruik van elke service
- De resterende clustercapaciteit
- De capaciteit van de knooppunten in het cluster
- De hoeveelheid resources die op elk knooppunt worden verbruikt
Het resourceverbruik van een bepaalde service kan na verloop van tijd veranderen en services geven meestal om meer dan één type resource. In verschillende services kunnen zowel fysieke als fysieke resources worden gemeten. Services kunnen fysieke metrische gegevens bijhouden, zoals geheugen- en schijfverbruik. Meer vaak geven services om logische metrische gegevens, zoals 'WorkQueueDepth' of 'TotalRequests'. Zowel logische als fysieke metrische gegevens kunnen worden gebruikt in hetzelfde cluster. Metrische gegevens kunnen worden gedeeld in veel services of specifiek zijn voor een bepaalde service.
Andere overwegingen
De eigenaren en operators van het cluster kunnen verschillen van de service- en toepassingsauteurs, of minimaal dezelfde personen die verschillende hoeden dragen. Wanneer u uw toepassing ontwikkelt, weet u een aantal dingen over wat deze nodig heeft. U hebt een schatting van de resources die deze verbruikt en hoe verschillende services moeten worden geïmplementeerd. De weblaag moet bijvoorbeeld worden uitgevoerd op knooppunten die beschikbaar zijn voor internet, terwijl de databaseservices dat niet mogen. Een ander voorbeeld is dat de webservices waarschijnlijk worden beperkt door CPU en netwerk, terwijl de gegevenslaagservices meer zorgen hebben over geheugen- en schijfverbruik. De persoon die echter een livesite-incident verwerkt voor die service in productie of die een upgrade naar de service beheert, heeft een andere taak en vereist verschillende hulpprogramma's.
Zowel het cluster als de services zijn dynamisch:
- Het aantal knooppunten in het cluster kan toenemen en verkleinen
- Knooppunten van verschillende grootten en typen kunnen komen en gaan
- Services kunnen worden gemaakt, verwijderd en de gewenste resourcetoewijzingen en plaatsingsregels wijzigen
- Upgrades of andere beheerbewerkingen kunnen worden geïmplementeerd via het cluster op infrastructuurniveau
- Fouten kunnen op elk gewenst moment optreden.
Onderdelen en gegevensstroom van clusterbronbeheer
De Cluster Resource Manager moet de vereisten van elke service en het verbruik van resources voor elk serviceobject in die services bijhouden. Cluster Resource Manager heeft twee conceptuele onderdelen: agents die worden uitgevoerd op elk knooppunt en een fouttolerante service. De agents op elk knooppunt houden belastingrapporten van services bij, aggregeren ze en rapporteren ze periodiek. De Cluster Resource Manager-service verzamelt alle informatie van de lokale agents en reageert op basis van de huidige configuratie.
Laten we eens kijken naar het volgende diagram:
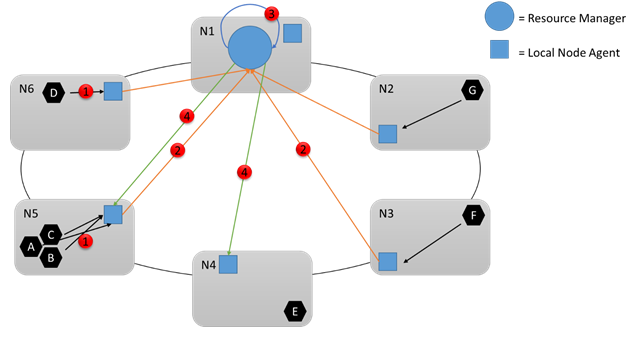
Tijdens runtime zijn er veel wijzigingen die kunnen optreden. Stel bijvoorbeeld dat de hoeveelheid resources die sommige services verbruiken wijzigingen verbruiken, sommige services mislukken en dat sommige knooppunten worden samengevoegd en het cluster verlaten. Alle wijzigingen op een knooppunt worden geaggregeerd en periodiek verzonden naar de Cluster Resource Manager-service (1,2) waar ze opnieuw worden samengevoegd, geanalyseerd en opgeslagen. Om de paar seconden kijkt die service naar de wijzigingen en bepaalt of er acties nodig zijn (3). Het kan bijvoorbeeld zien dat sommige lege knooppunten zijn toegevoegd aan het cluster. Als gevolg hiervan besluit het bepaalde services naar die knooppunten te verplaatsen. De Cluster Resource Manager kan ook merken dat een bepaald knooppunt overbelast is, of dat bepaalde services zijn mislukt of zijn verwijderd, waardoor resources ergens anders worden vrijgemaakt.
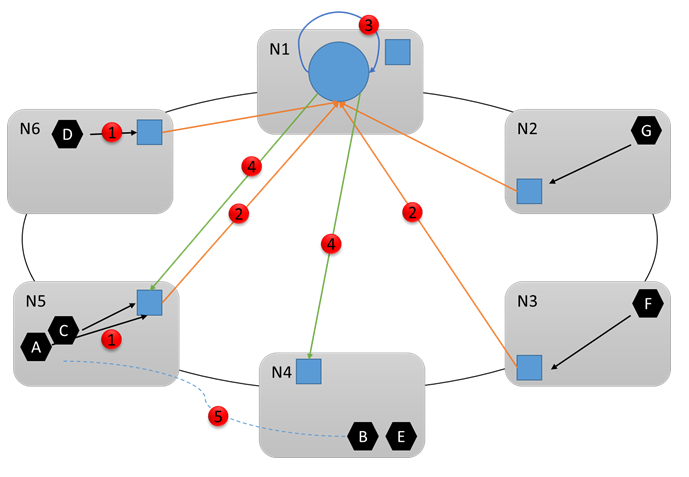
Laten we eens kijken naar het volgende diagram en kijken wat er vervolgens gebeurt. Stel dat de Cluster Resource Manager bepaalt dat wijzigingen nodig zijn. Het coördineert met andere systeemservices (met name failoverbeheer) om de benodigde wijzigingen aan te brengen. Vervolgens worden de benodigde opdrachten verzonden naar de juiste knooppunten (4). Stel bijvoorbeeld dat Resource Manager merkt dat Node5 overbelast is en dus heeft besloten om service B van Node5 naar Node4 te verplaatsen. Aan het einde van de herconfiguratie (5) ziet het cluster er als volgt uit:
Volgende stappen
- Cluster Resource Manager heeft veel opties voor het beschrijven van het cluster. Raadpleeg dit artikel voor meer informatie over het beschrijven van een Service Fabric-cluster
- De primaire taken van Cluster Resource Manager zijn het opnieuw verdelen van het cluster en het afdwingen van plaatsingsregels. Zie De taakverdeling van uw Service Fabric-cluster voor meer informatie over het configureren van dit gedrag