Betrouwbaarheid in Azure HDInsight
In dit artikel wordt ondersteuning voor betrouwbaarheid in Azure HDInsight beschreven en worden beschikbaarheidszones en herstel in meerdere regio's en bedrijfscontinuïteit behandeld. Zie Azure-betrouwbaarheid voor een gedetailleerder overzicht van betrouwbaarheid in Azure.
Ondersteuning voor beschikbaarheidszone
Beschikbaarheidszones zijn fysiek afzonderlijke groepen datacenters binnen elke Azure-regio. Wanneer één zone uitvalt, kunnen services een failover uitvoeren naar een van de resterende zones.
Zie Wat zijn beschikbaarheidszones in Azure voor meer informatie over beschikbaarheidszones?
Azure HDInsight ondersteunt een zonegebonden implementatieconfiguratie. Azure HDInsight-clusterknooppunten worden in één zone geplaatst die u selecteert in de geselecteerde regio. Een zonegebonden HDInsight-cluster is geïsoleerd van storingen die zich in andere zones voordoen. Als een storing echter van invloed is op de specifieke zone die is gekozen voor het HDInsight-cluster, is het cluster niet beschikbaar. Dit implementatiemodel biedt goedkope netwerkconnectiviteit met lage latentie binnen het cluster. Het repliceren van dit implementatiemodel in meerdere beschikbaarheidszones kan een hoger beschikbaarheidsniveau bieden om te beschermen tegen hardwarefouten.
Belangrijk
Voor implementaties waarbij gebruikers geen specifieke zone opgeven, zijn knooppunttypen niet zonebestendig en kunnen er downtime optreden tijdens een storing in een zone in die regio.
Vereisten
Beschikbaarheidszones worden alleen ondersteund voor clusters die zijn gemaakt na 15 juni 2023. Instellingen voor beschikbaarheidszones kunnen niet worden bijgewerkt nadat het cluster is gemaakt. U kunt ook geen bestaand cluster met een niet-beschikbaarheidszone bijwerken om beschikbaarheidszones te gebruiken.
Clusters moeten worden gemaakt onder een aangepast VNet.
U moet uw eigen SQL DB voor Ambari DB en externe metastore, zoals Hive-metastore, gebruiken, zodat u deze DB's in dezelfde beschikbaarheidszone kunt configureren.
Uw HDInsight-clusters moeten worden gemaakt met de optie beschikbaarheidszone in een van de volgende regio's:
- Australië - oost
- Brazilië - zuid
- Canada - midden
- VS - centraal
- VS - oost
- VS - oost 2
- Frankrijk - centraal
- Duitsland - west-centraal
- Japan - oost
- Korea - centraal
- Europa - noord
- Qatar - centraal
- Azië - zuidoost
- VS - zuid-centraal
- Verenigd Koninkrijk Zuid
- VS (overheid) - Virginia
- Europa -west
- VS - west 2
Een HDInsight-cluster maken met behulp van beschikbaarheidszone
U kunt een ARM-sjabloon (Azure Resource Manager) gebruiken om een HDInsight-cluster te starten in een opgegeven beschikbaarheidszone.
In de sectie Resources moet u een sectie van 'zones' toevoegen en opgeven in welke beschikbaarheidszone u dit cluster wilt implementeren.
"resources": [
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('cluster name')]",
"location": "East US 2",
"zones": [
"1"
],
}
]
Knooppunten binnen één beschikbaarheidszone tussen zones controleren
Wanneer het HDInsight-cluster gereed is, kunt u de locatie controleren om te zien in welke beschikbaarheidszone ze zijn geïmplementeerd.

API-antwoord ophalen:
[
{
"location": "East US 2",
"zones": [
"1"
],
}
]
Het cluster omhoog schalen
U kunt een HDInsight-cluster omhoog schalen met meer werkknooppunten. De zojuist toegevoegde werkknooppunten worden in dezelfde beschikbaarheidszone van dit cluster geplaatst.
Migratie van beschikbaarheidszone
Azure HDInsight-clusters bieden momenteel geen ondersteuning voor in-place migratie van bestaande clusterexemplaren naar ondersteuning voor beschikbaarheidszones. U kunt er echter voor kiezen om uw cluster opnieuw te maken en een andere beschikbaarheidszone of regio te kiezen tijdens het maken van het cluster. Een secundair stand-bycluster in een andere regio en een andere beschikbaarheidszone kan worden gebruikt in scenario's voor herstel na noodgevallen.
Zone-down-ervaring
Wanneer een beschikbaarheidszone uitvalt:
- U kunt geen ssh naar dit cluster uitvoeren.
- U kunt dit cluster niet verwijderen of omhoog schalen of omlaag schalen.
- U kunt geen taken verzenden of de taakgeschiedenis bekijken.
- U kunt nog steeds een aanvraag indienen voor het maken van een nieuw cluster in een andere regio.
Herstel na noodgevallen en bedrijfscontinuïteit tussen regio's
Herstel na noodgevallen (DR) gaat over het herstellen van gebeurtenissen met een hoge impact, zoals natuurrampen of mislukte implementaties die downtime en gegevensverlies tot gevolg hebben. Ongeacht de oorzaak is de beste oplossing voor een noodgeval een goed gedefinieerd en getest DR-plan en een toepassingsontwerp dat actief dr ondersteunt. Zie aanbevelingen voor het ontwerpen van een strategie voor herstel na noodgevallen voordat u begint na te denken over het maken van uw plan voor herstel na noodgevallen.
Als het gaat om herstel na noodgevallen, gebruikt Microsoft het model voor gedeelde verantwoordelijkheid. In een model voor gedeelde verantwoordelijkheid zorgt Microsoft ervoor dat de basisinfrastructuur en platformservices beschikbaar zijn. Tegelijkertijd repliceren veel Azure-services niet automatisch gegevens of vallen ze terug van een mislukte regio om kruislings te repliceren naar een andere ingeschakelde regio. Voor deze services bent u verantwoordelijk voor het instellen van een plan voor herstel na noodgevallen dat geschikt is voor uw workload. De meeste services die worden uitgevoerd op PaaS-aanbiedingen (Platform as a Service) van Azure bieden functies en richtlijnen ter ondersteuning van herstel na noodgeval en u kunt servicespecifieke functies gebruiken om snel herstel te ondersteunen om uw DR-plan te ontwikkelen.
Azure HDInsight-clusters zijn afhankelijk van veel Azure-services, zoals opslag, databases, Active Directory, Active Directory-domein Services, netwerken en Key Vault. Een goed ontworpen, maximaal beschikbare en fouttolerante analysetoepassing moet worden ontworpen met voldoende redundantie om regionale of lokale onderbrekingen in een of meer van deze services te weerstaan. In deze sectie vindt u een overzicht van aanbevolen procedures, beschikbaarheid van één en meerdere regio's en optimalisatieopties voor bedrijfscontinuïteitsplanning.
Herstel na noodgevallen in geografie in meerdere regio's
Voor het verbeteren van bedrijfscontinuïteit met herstel na noodgevallen in meerdere regio's zijn architectuurontwerpen van hogere complexiteit en hogere kosten vereist. In de volgende tabellen worden enkele technische gebieden beschreven die de totale eigendomskosten kunnen verhogen.
Kostenoptimalisaties
| Gebied | Oorzaak van escalatie van kosten | Optimalisatiestrategieën |
|---|---|---|
| Gegevensopslag | Primaire gegevens/tabellen dupliceren in een secundaire regio | Alleen gecureerde gegevens repliceren |
| Uitgaand gegevensverkeer | Uitgaande gegevensoverdrachten voor meerdere regio's hebben een prijs. Richtlijnen voor bandbreedteprijzen bekijken | Alleen gecureerde gegevens repliceren om de footprint van het uitgaand verkeer van regio's te verminderen |
| Cluster Compute | Extra HDInsight-cluster/s in secundaire regio | Gebruik geautomatiseerde scripts om secundaire berekeningen te implementeren na een primaire fout. Gebruik Automatisch schalen om de secundaire clustergrootte tot een minimum te beperken. Gebruik goedkopere VM-SKU's. Maak secundaire bestanden in regio's waar VM-SKU's mogelijk worden korting. |
| Verificatie | Bij scenario's met meerdere gebruikers in de secundaire regio worden extra Setups voor Microsoft Entra Domain Services uitgevoerd | Vermijd setups voor meerdere gebruikers in secundaire regio. |
Complexiteitsoptimalisaties
| Gebied | Oorzaak van escalatie van complexiteit | Optimalisatiestrategieën |
|---|---|---|
| Schrijfpatronen lezen | Vereisen dat zowel primaire als secundaire gegevens lezen en schrijven zijn ingeschakeld | De secundaire ontwerpen om alleen-lezen te zijn |
| Nul RPO & RTO | Het vereisen van nul gegevensverlies (RPO=0) en nul downtime (RTO=0) | Ontwerp RPO en RTO op manieren om het aantal onderdelen te verminderen dat een failover moet uitvoeren. Zie Wat zijn bedrijfscontinuïteit, hoge beschikbaarheid en herstel na noodgevallen voor meer informatie over RTO en RPO. |
| Bedrijfsfunctionaliteit | Volledige bedrijfsfunctionaliteit van primair in secundaire | Evalueer of u kunt uitvoeren met een minimale kritieke subset van de bedrijfsfunctionaliteit in secundaire. |
| Connectiviteit | Vereisen dat alle upstream- en downstreamsystemen van primaire systemen verbinding maken met de secundaire | Beperk de secundaire connectiviteit tot een minimale kritieke subset. |
Wanneer u uw plan voor herstel na noodgevallen voor meerdere regio's maakt, moet u rekening houden met de volgende aanbevelingen:
Bepaal de minimale bedrijfsfunctionaliteit die u nodig hebt als er een noodgeval is en waarom. Evalueer bijvoorbeeld of u failovermogelijkheden nodig hebt voor de gegevenstransformatielaag (geel) en de gegevensservicelaag (blauw weergegeven) of als u alleen failover nodig hebt voor de gegevensservicelaag.
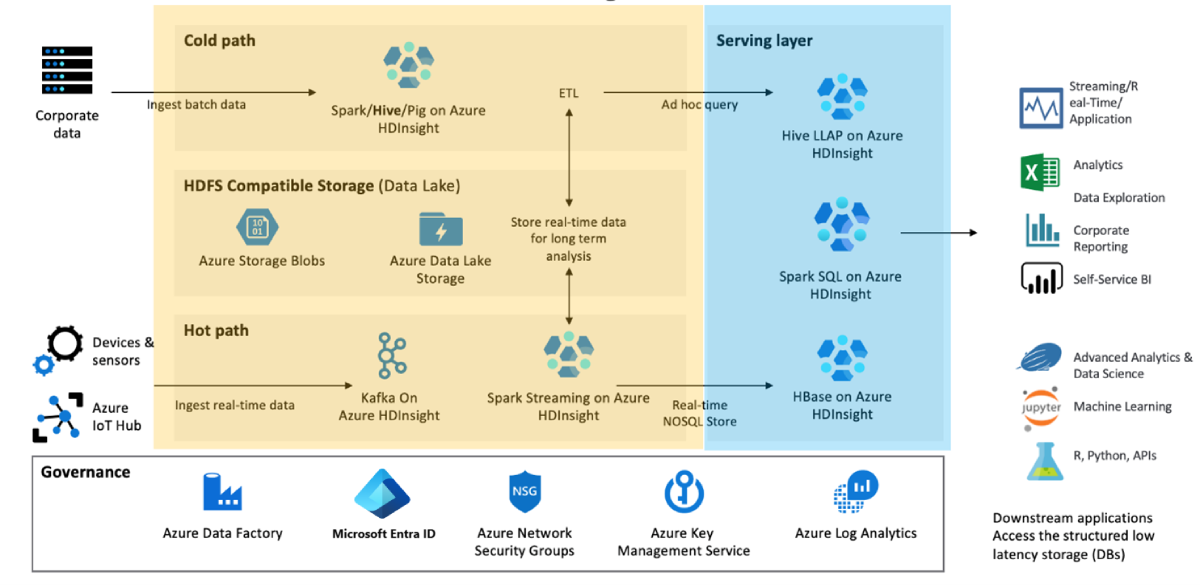
Segmenteer uw clusters op basis van workload, ontwikkelingslevenscyclus en afdelingen. Als u meer clusters hebt, vermindert u de kans op één grote fout die van invloed is op meerdere verschillende bedrijfsprocessen.
Zorg ervoor dat uw secundaire regio's alleen-lezen zijn. Failoverregio's met zowel lees- als schrijfmogelijkheden kunnen leiden tot complexe architecturen.
Tijdelijke clusters zijn gemakkelijker te beheren wanneer zich een noodgeval voordoet. Ontwerp uw workloads op een manier waarop clusters kunnen worden gecyclusd en er geen status wordt onderhouden in clusters.
Workloads worden vaak onvoltooid als er een noodgeval is en opnieuw moeten worden opgestart in de nieuwe regio. Ontwerp uw workloads als idempotent in de natuur.
Gebruik automatisering tijdens clusterimplementaties en zorg ervoor dat de clusterconfiguratie-instellingen zoveel mogelijk worden gescript om snelle en volledig geautomatiseerde implementatie te garanderen als er zich een noodgeval voordoet.
Detectie, melding en beheer van storingen
Gebruik Azure-bewakingshulpprogramma's in HDInsight om abnormaal gedrag in het cluster te detecteren en bijbehorende waarschuwingsmeldingen in te stellen. U kunt de vooraf geconfigureerde HDInsight-clusterspecifieke beheeroplossingen implementeren die belangrijke prestatiegegevens van het specifieke clustertype verzamelen. Zie Azure Monitoring voor HDInsight voor meer informatie.
Abonneer u op Azure-statuswaarschuwingen om op de hoogte te worden gesteld van serviceproblemen, gepland onderhoud, status- en beveiligingsadviezen voor een abonnement, service of regio. Statusmeldingen met de oorzaak van het probleem en een resolute ETA helpen u om failover- en failbacks beter uit te voeren. Zie de documentatie voor Azure Service Health voor meer informatie.
Herstel na noodgevallen in geografie met één regio
Elk onderdeel in een eenvoudig HDInsight-systeem heeft zijn eigen mechanismen voor fouttolerantie voor één regio. Houd er rekening mee dat er niet altijd een catastrofale gebeurtenis nodig is om de bedrijfsfunctionaliteit te beïnvloeden. Service-incidenten in een of meer van de volgende services in één regio kunnen ook leiden tot verlies van verwachte bedrijfsfunctionaliteit.
Compute (virtuele machines): Azure HDInsight-cluster. HDInsight biedt een SLA voor beschikbaarheid van 99,9%. Als u hoge beschikbaarheid in één implementatie wilt bieden, gaat HDInsight gepaard met veel services die standaard in de modus voor hoge beschikbaarheid staan. Fouttolerantiemechanismen in HDInsight worden geleverd door services voor hoge beschikbaarheid van microsoft- en Apache OSS-ecosysteem.
De volgende infrastructuuronderdelen zijn ontworpen om maximaal beschikbaar te zijn:
- Actieve en stand-by headnodes
- Meerdere gatewayknooppunten
- Drie Zookeeper Quorum-knooppunten
- Werkknooppunten gedistribueerd door fout- en updatedomeinen
De volgende services zijn ook ontworpen om maximaal beschikbaar te zijn:
- Apache Ambari-server
- Tijdlijnen van toepassingen voor YARN
- Taakgeschiedenisserver voor Hadoop MapReduce
- Apache Livy
- HDFS
- YARN Resource Manager
- HBase-master
Zie services voor hoge beschikbaarheid die worden ondersteund door Azure HDInsight voor meer informatie.
Metastore(s): Azure SQL Database. HDInsight maakt gebruik van Azure SQL Database als een metastore, die een SLA van 99,99% biedt. Drie replica's van gegevens blijven behouden in een datacenter met synchrone replicatie. Als er sprake is van een replicaverlies, wordt een alternatieve replica naadloos geleverd. Actieve geo-replicatie wordt standaard ondersteund met maximaal vier datacenters. Wanneer er een failover is, ofwel handmatig of datacenter, wordt de eerste replica in de hiërarchie automatisch geschikt voor lezen/schrijven. Zie De bedrijfscontinuïteit van Azure SQL Database voor meer informatie.
Opslag: Azure Data Lake Gen2 of Blob Storage. HDInsight raadt Azure Data Lake Storage Gen2 aan als de onderliggende opslaglaag. Azure Storage, inclusief Azure Data Lake Storage Gen2, biedt een SLA van 99,9%. HDInsight maakt gebruik van de LRS-service waarin drie replica's van gegevens zich in een datacenter bevinden en replicatie synchroon is. Wanneer er sprake is van een replicaverlies, wordt een replica naadloos geleverd.
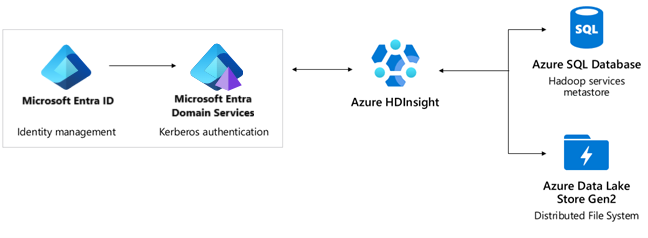
Verificatie: Microsoft Entra ID, Microsoft Entra Domain Services, Enterprise Security Package.
- Microsoft Entra ID biedt een SLA van 99,9%. Active Directory is een globale service met meerdere niveaus van interne redundantie en automatische herstelbaarheid. Zie voor meer informatie hoe Microsoft voortdurend de betrouwbaarheid van Microsoft Entra ID verbetert.
- Microsoft Entra Domain Services biedt een SLA van 99,9%. Microsoft Entra Domain Services is een maximaal beschikbare service die wordt gehost in wereldwijd gedistribueerde datacenters. Replicasets zijn een preview-functie in Microsoft Entra Domain Services waarmee geografisch herstel na noodgevallen mogelijk is als een Azure-regio offline gaat. Zie concepten en functies van replicasets voor Microsoft Entra Domain Services voor meer informatie.
- Azure DNS biedt een SLA van 100%. HDInsight gebruikt Azure DNS op verschillende plaatsen voor domeinnaamomzetting.
Optionele services, zoals Azure Key Vault en Azure Data Factory.