Wat zijn bedrijfscontinuïteit, hoge beschikbaarheid en herstel na noodgevallen?
In dit artikel worden bedrijfscontinuïteit en bedrijfscontinuïteitsplanning gedefinieerd en beschreven in termen van risicobeheer via een ontwerp voor hoge beschikbaarheid en herstel na noodgevallen. Hoewel dit artikel geen expliciete richtlijnen biedt voor het voldoen aan uw eigen bedrijfscontinuïteitsbehoeften, helpt het u om inzicht te krijgen in de concepten die worden gebruikt in de betrouwbaarheidsrichtlijnen van Microsoft.
Bedrijfscontinuïteit is de status waarin een bedrijf bewerkingen kan voortzetten tijdens storingen, storingen of noodgevallen. Bedrijfscontinuïteit vereist proactieve planning, voorbereiding en implementatie van tolerante systemen en processen.
Voor het plannen van bedrijfscontinuïteit moeten risico's worden geïdentificeerd, begrepen, geclassificeerd en beheerd. Op basis van de risico's en hun waarschijnlijkheid ontwerpt u voor hoge beschikbaarheid (HA) en herstel na noodgevallen (DR).
Hoge beschikbaarheid gaat over het ontwerpen van een oplossing die bestand is tegen dagelijkse problemen en om te voldoen aan de bedrijfsbehoeften voor beschikbaarheid.
Herstel na noodgevallen gaat over het plannen van het omgaan met ongebruikelijke risico's en de catastrofale storingen die kunnen resulteren.
Bedrijfscontinuïteit
In het algemeen zijn cloudoplossingen rechtstreeks gekoppeld aan bedrijfsactiviteiten. Wanneer een cloudoplossing niet beschikbaar is of een ernstig probleem ondervindt, kan de impact op bedrijfsactiviteiten ernstig zijn. Een ernstige impact kan de bedrijfscontinuïteit verbreken.
Ernstige gevolgen voor bedrijfscontinuïteit kunnen het volgende omvatten:
- Verlies van bedrijfsinkomen.
- Het onvermogen om gebruikers een belangrijke service te bieden.
- Schending van een toezegging die is gedaan aan een klant of een andere partij.
Het is belangrijk om de zakelijke verwachtingen en de gevolgen van fouten te begrijpen en te communiceren aan belangrijke belanghebbenden, waaronder degenen die de workload ontwerpen, implementeren en uitvoeren. Die belanghebbenden reageren vervolgens door de kosten te delen die betrokken zijn bij het ontmoeten van die visie. Er is doorgaans een proces van onderhandeling en revisies van die visie op basis van budget en andere beperkingen.
Planning voor bedrijfscontinuïteit
Als u een negatieve impact op bedrijfscontinuïteit wilt beheren of volledig wilt voorkomen, is het belangrijk om proactief een bedrijfscontinuïteitsplan te maken. Een bedrijfscontinuïteitsplan is gebaseerd op risicoanalyse en het ontwikkelen van methoden voor het beheersen van deze risico's via verschillende benaderingen. De specifieke risico's en benaderingen om te beperken variëren voor elke organisatie en workload.
Een bedrijfscontinuïteitsplan houdt niet alleen rekening met de tolerantiefuncties van het cloudplatform zelf, maar ook met de functies van de toepassing. Een robuust plan voor bedrijfscontinuïteit omvat ook alle aspecten van ondersteuning in het bedrijf, waaronder personen, zakelijke handmatige of geautomatiseerde processen en andere technologieën.
Planning voor bedrijfscontinuïteit moet de volgende opeenvolgende stappen bevatten:
Risicoidentificatie. Identificeer risico's voor de beschikbaarheid of functionaliteit van een workload. Mogelijke risico's kunnen netwerkproblemen, hardwarefouten, menselijke fouten, regiostoringen, enzovoort zijn. Inzicht in de impact van elk risico.
Risicoclassificatie. Classificeer elk risico als een gemeenschappelijk risico, dat moet worden meegenomen in plannen voor hoge beschikbaarheid of als een ongewoon risico, dat deel moet uitmaken van dr-planning.
Risicobeperking. Ontwerp risicobeperkingsstrategieën voor hoge beschikbaarheid of herstel na noodgevallen om risico's zoals redundantie, replicatie, failover en back-ups te minimaliseren of te beperken. Overweeg ook niet-technische en procesmatige oplossingen en controles.
Bedrijfscontinuïteitsplanning is een proces, geen eenmalige gebeurtenis. Elk plan voor bedrijfscontinuïteit dat wordt gemaakt, moet regelmatig worden herzien en bijgewerkt om ervoor te zorgen dat het relevant en effectief blijft en dat het de huidige bedrijfsbehoeften ondersteunt.
Risicoidentificatie
De eerste fase in de planning van bedrijfscontinuïteit is het identificeren van risico's voor de beschikbaarheid of functionaliteit van een workload. Elk risico moet worden geanalyseerd om de waarschijnlijkheid en ernst ervan te begrijpen. Ernst moet eventuele downtime of gegevensverlies bevatten, en of aspecten van de rest van het oplossingsontwerp negatieve effecten kunnen compenseren.
De volgende tabel is een niet-volledige lijst met risico's, gerangschikt door de kans te verkleinen:
| Voorbeeldrisico | Beschrijving | Regulariteit (waarschijnlijkheid) |
|---|---|---|
| Tijdelijk netwerkprobleem | Een tijdelijke fout in een onderdeel van de netwerkstack, die na korte tijd kan worden hersteld (meestal een paar seconden of minder). | Normaal |
| Virtuele machine opnieuw opstarten | Een herstart van een virtuele machine die u gebruikt of die een afhankelijke service gebruikt. Opnieuw opstarten kan optreden omdat de virtuele machine vastloopt of een patch moet toepassen. | Normaal |
| Hardwarestoring | Een fout van een onderdeel in een datacenter, zoals een hardwareknooppunt, rek of cluster. | Incidenteel |
| Storing in datacenter | Een storing die van invloed is op de meeste of alle datacenters, zoals een stroomstoring, netwerkverbindingsprobleem of problemen met verwarming en koeling. | Ongewoon |
| Regio-storing | Een storing die van invloed is op een hele grootstedelijk gebied of een groter gebied, zoals een grote natuurramp. | Zeer ongebruikelijk |
Bedrijfscontinuïteitsplanning gaat niet alleen over het cloudplatform en de infrastructuur. Het is belangrijk om rekening te houden met het risico op menselijke fouten. Bovendien moeten sommige risico's die traditioneel worden beschouwd als beveiliging, prestaties of operationele risico's, ook worden beschouwd als betrouwbaarheidsrisico's, omdat deze van invloed zijn op de beschikbaarheid van de oplossing.
Hieronder volgen een aantal voorbeelden:
| Voorbeeldrisico | Beschrijving |
|---|---|
| Gegevensverlies of beschadiging | Gegevens zijn verwijderd, overschreven of anderszins beschadigd door een ongeluk, of door een beveiligingsschending zoals een ransomware-aanval. |
| Softwarefout | Een implementatie van nieuwe of bijgewerkte code introduceert een fout die van invloed is op beschikbaarheid of integriteit, waardoor de workload in een storingsstatus blijft. |
| Mislukte implementaties | Een implementatie van een nieuw onderdeel of een nieuwe versie is mislukt, waardoor de oplossing een inconsistente status heeft. |
| Denial of Service-aanvallen | Het systeem is aangevallen in een poging om legitiem gebruik van de oplossing te voorkomen. |
| Rogue-beheerders | Een gebruiker met beheerdersbevoegdheden heeft opzettelijk een schadelijke actie op het systeem uitgevoerd. |
| Onverwachte toestroom van verkeer naar een toepassing | Een piek in het verkeer heeft de resources van het systeem overbelast. |
Analyse van foutmodus (FMA) is het proces voor het identificeren van mogelijke manieren waarop een workload of de onderdelen ervan kunnen mislukken en hoe de oplossing zich in die situaties gedraagt. Zie Aanbevelingen voor het uitvoeren van analyse van de foutmodus voor meer informatie.
Risicoclassificatie
Bedrijfscontinuïteitsplannen moeten zowel veelvoorkomende als ongebruikelijke risico's aanpakken.
Veelvoorkomende risico's worden gepland en verwacht. In een cloudomgeving is het bijvoorbeeld gebruikelijk dat er tijdelijke fouten optreden, waaronder korte netwerkstoringen, opnieuw opstarten van apparatuur vanwege patches, time-outs wanneer een service bezet is, enzovoort. Omdat deze gebeurtenissen regelmatig plaatsvinden, moeten workloads tolerant zijn voor deze gebeurtenissen.
Voor elk risico van dit type moet een strategie voor hoge beschikbaarheid worden overwogen en gecontroleerd.
Ongebruikelijke risico's zijn over het algemeen het gevolg van een onvoorziene gebeurtenis, zoals een natuurramp of een grote netwerkaanval, die kan leiden tot een catastrofale storing.
Processen voor herstel na noodgevallen hebben betrekking op deze zeldzame risico's.
Hoge beschikbaarheid en herstel na noodgevallen zijn onderling verbonden en daarom is het belangrijk om strategieën voor beide samen te plannen.
Het is belangrijk om te begrijpen dat risicoclassificatie afhankelijk is van de workloadarchitectuur en de bedrijfsvereisten, en sommige risico's kunnen worden geclassificeerd als hoge beschikbaarheid voor de ene workload en herstel na noodgevallen voor een andere workload. Een volledige storing in een Azure-regio wordt in het algemeen beschouwd als een dr-risico voor workloads in die regio. Maar voor workloads die gebruikmaken van meerdere Azure-regio's in een actief-actieve configuratie met volledige replicatie, redundantie en automatische regiofailover, wordt een regiostoring geclassificeerd als een ha-risico.
Risicobeperking
Risicobeperking bestaat uit het ontwikkelen van strategieën voor hoge beschikbaarheid of herstel na noodgevallen om risico's voor bedrijfscontinuïteit te minimaliseren of te beperken. Risicobeperking kan op technologie of op basis van mensen zijn.
Risicobeperking op basis van technologie
Risicobeperking op basis van technologie maakt gebruik van risicocontroles die zijn gebaseerd op hoe de workload wordt geïmplementeerd en geconfigureerd, zoals:
- Redundantie
- Gegevensreplicatie
- Failover
- Back-ups
Risicocontroles op basis van technologie moeten worden overwogen binnen de context van het bedrijfscontinuïteitsplan.
Voorbeeld:
Vereisten voor lage downtime. Sommige bedrijfscontinuïteitsplannen kunnen geen enkele vorm van downtimerisico's tolereren vanwege strenge vereisten voor hoge beschikbaarheid . Er zijn bepaalde op technologie gebaseerde controles die mogelijk tijd vereisen voor een mens om een melding te ontvangen en vervolgens te reageren. Risicocontroles op basis van technologie die trage handmatige processen bevatten, zijn waarschijnlijk ongeschikt voor opname in hun risicobeperkingsstrategie.
Tolerantie voor gedeeltelijke fouten. Sommige bedrijfscontinuïteitsplannen kunnen een werkstroom tolereren die in een gedegradeerde status wordt uitgevoerd. Wanneer een oplossing in een gedegradeerde status werkt, kunnen sommige onderdelen worden uitgeschakeld of niet-functioneel zijn, maar de belangrijkste bedrijfsactiviteiten kunnen nog steeds worden uitgevoerd. Zie Aanbevelingen voor zelfherstel en zelfbehoud voor meer informatie.
Risicobeperking op basis van mensen
Risicobeperking op basis van mensen maakt gebruik van risicocontroles die zijn gebaseerd op bedrijfsprocessen, zoals:
- Een antwoordplaybook activeren.
- Terugvallen op handmatige bewerkingen.
- Training en culturele veranderingen.
Belangrijk
Personen die de workload ontwerpen, implementeren, gebruiken en ontwikkelen, moeten bevoegd zijn, aanmoedigen om te spreken als ze zorgen hebben en een gevoel van verantwoordelijkheid voor het systeem voelen.
Omdat risicocontroles op basis van mensen vaak langzamer zijn dan op technologie gebaseerde controles en gevoeliger zijn voor menselijke fouten, moet een goed plan voor bedrijfscontinuïteit een formeel wijzigingsbeheerproces bevatten voor alles wat de status van het actieve systeem zou veranderen. U kunt bijvoorbeeld de volgende processen implementeren:
- Test uw workloads grondig in overeenstemming met workloadkritiek. Als u problemen met betrekking tot wijzigingen wilt voorkomen, moet u alle wijzigingen testen die zijn aangebracht in de workload.
- Introduceer strategische kwaliteitspoorten als onderdeel van de veilige implementatieprocedures van uw workload. Zie Aanbevelingen voor veilige implementatieprocedures voor meer informatie.
- Formaliseer procedures voor ad-hoc productietoegang en gegevensmanipulatie. Deze activiteiten kunnen, ongeacht hoe klein, een hoog risico vormen voor het veroorzaken van betrouwbaarheidsincidenten. Procedures kunnen bestaan uit koppelen met een andere technicus, het gebruik van controlelijsten en het verkrijgen van peerbeoordelingen voordat u scripts uitvoert of wijzigingen toepast.
Hoge beschikbaarheid
Hoge beschikbaarheid is de status waarin een specifieke workload de benodigde uptime kan handhaven op dagelijkse basis, zelfs tijdens tijdelijke fouten en onregelmatige fouten. Omdat deze gebeurtenissen regelmatig plaatsvinden, is het belangrijk dat elke workload is ontworpen en geconfigureerd voor hoge beschikbaarheid in overeenstemming met de vereisten van de specifieke toepassing en de verwachtingen van de klant. De hoge beschikbaarheid van elke workload draagt bij aan uw bedrijfscontinuïteitsplan.
Omdat hoge beschikbaarheid per workload kan variëren, is het belangrijk om inzicht te hebben in de vereisten en de verwachtingen van klanten bij het bepalen van hoge beschikbaarheid. Een toepassing die uw organisatie gebruikt om kantoorbenodigdheden te bestellen, kan bijvoorbeeld een relatief laag uptimeniveau vereisen, terwijl een kritieke financiële toepassing mogelijk een veel hogere uptime vereist. Zelfs binnen een workload kunnen verschillende stromen verschillende vereisten hebben. In een e-commercetoepassing zijn stromen die klanten ondersteunen bijvoorbeeld het bladeren en plaatsen van orders belangrijker dan orderafhandelings- en back-office-verwerkingsstromen. Zie Aanbevelingen voor het identificeren en beoordelen van stromen voor meer informatie over stromen.
De uptime wordt meestal gemeten op basis van het aantal 'negens' in het uptimepercentage. Het uptimepercentage heeft betrekking op hoeveel downtime u gedurende een bepaalde periode toestaat. Hieronder volgen een aantal voorbeelden:
- Een uptimevereiste van 99,9% (drie negens) zorgt voor ongeveer 43 minuten downtime in een maand.
- Een uptimevereiste van 99,95% (drie en een half negens) maakt ongeveer 21 minuten downtime in een maand mogelijk.
Hoe hoger de uptimevereiste, hoe minder tolerantie u hebt voor storingen en hoe meer werk u moet doen om dat beschikbaarheidsniveau te bereiken. Uptime wordt niet gemeten door de uptime van één onderdeel, zoals een knooppunt, maar door de algehele beschikbaarheid van de hele workload.
Belangrijk
Overengineer uw oplossing niet om een hoger betrouwbaarheidsniveau te bereiken dan gerechtvaardigd is. Gebruik zakelijke vereisten om uw beslissingen te begeleiden.
Ontwerpelementen voor hoge beschikbaarheid
Om hoge beschikbaarheidsvereisten te bereiken, kan een workload een aantal ontwerpelementen bevatten. Enkele algemene elementen worden vermeld en hieronder beschreven in deze sectie.
Notitie
Sommige workloads zijn bedrijfskritiek, wat betekent dat downtime ernstige gevolgen kan hebben voor het menselijk leven en de veiligheid, of grote financiële verliezen. Als u een bedrijfskritieke workload ontwerpt, zijn er specifieke dingen die u moet bedenken wanneer u uw oplossing ontwerpt en uw bedrijfscontinuïteit beheert. Zie het Azure Well-Architected Framework: Bedrijfskritieke workloads voor meer informatie.
Azure-services en -lagen die ondersteuning bieden voor hoge beschikbaarheid
Veel Azure-services zijn ontworpen om maximaal beschikbaar te zijn en kunnen worden gebruikt voor het bouwen van workloads met hoge beschikbaarheid. Hieronder volgen een aantal voorbeelden:
- Virtuele-machineschaalsets van Azure bieden hoge beschikbaarheid voor virtuele machines (VM's) door automatisch VM-exemplaren te maken en te beheren en deze VM-exemplaren te distribueren om de impact van infrastructuurfouten te verminderen.
- Azure-app Service biedt hoge beschikbaarheid via verschillende benaderingen, waaronder het automatisch verplaatsen van werknemers van een beschadigd knooppunt naar een gezond knooppunt en door mogelijkheden te bieden voor zelfherstel van veel veelvoorkomende fouttypen.
Gebruik elke servicebetrouwbaarheidshandleiding om inzicht te hebben in de mogelijkheden van de service, te bepalen welke lagen u wilt gebruiken en te bepalen welke mogelijkheden u moet opnemen in uw strategie voor hoge beschikbaarheid.
Bekijk de Service Level Agreements (SLA's) voor elke service om inzicht te hebben in de verwachte beschikbaarheidsniveaus en de voorwaarden waaraan u moet voldoen. Mogelijk moet u specifieke lagen van services selecteren of vermijden om bepaalde beschikbaarheidsniveaus te bereiken. Sommige services van Microsoft worden aangeboden met het inzicht dat er geen SLA wordt geleverd, zoals ontwikkelings- of basislagen, of dat de resource kan worden vrijgemaakt van uw actieve systeem, zoals spot-gebaseerde aanbiedingen. Sommige lagen hebben ook betrouwbaarheidsfuncties toegevoegd, zoals ondersteuning voor beschikbaarheidszones.
Fouttolerantie
Fouttolerantie is de mogelijkheid van een systeem om te blijven werken, in sommige gedefinieerde capaciteit, in het geval van een storing. Een webtoepassing kan bijvoorbeeld zijn ontworpen om door te gaan met werken, zelfs als één webserver mislukt. Fouttolerantie kan worden bereikt via redundantie, failover, partitionering, graceful degradatie en andere technieken.
Fouttolerantie vereist ook dat uw toepassingen tijdelijke fouten verwerken. Wanneer u uw eigen code bouwt, moet u mogelijk zelf tijdelijke foutafhandeling inschakelen. Sommige Azure-services bieden ingebouwde tijdelijke foutafhandeling voor sommige situaties. Standaard probeert Azure Logic Apps bijvoorbeeld automatisch mislukte aanvragen voor andere services opnieuw uit te voeren. Zie Aanbevelingen voor het afhandelen van tijdelijke fouten voor meer informatie.
Redundantie
Redundantie is de praktijk van het dupliceren van exemplaren of gegevens om de betrouwbaarheid van de workload te verhogen.
Redundantie kan worden bereikt door replica's of redundante exemplaren op een van de volgende manieren te distribueren:
- Binnen een datacenter (lokale redundantie)
- Tussen beschikbaarheidszones binnen een regio (zoneredundantie)
- Tussen regio's (geo-redundantie).
Hier volgen enkele voorbeelden van hoe sommige Azure-services redundantieopties bieden:
- Azure-app Service stelt u in staat om meerdere exemplaren van uw toepassing uit te voeren, om ervoor te zorgen dat de toepassing beschikbaar blijft, zelfs als er één exemplaar uitvalt. Als u zoneredundantie inschakelt, worden deze exemplaren verdeeld over meerdere beschikbaarheidszones in de Azure-regio die u gebruikt.
- Azure Storage biedt hoge beschikbaarheid door gegevens ten minste drie keer automatisch te repliceren. U kunt deze replica's distribueren over beschikbaarheidszones door zone-redundante opslag (ZRS) in te schakelen. In veel regio's kunt u uw opslaggegevens ook repliceren in verschillende regio's met behulp van geografisch redundante opslag (GRS).
- Azure SQL Database heeft meerdere replica's om ervoor te zorgen dat de gegevens beschikbaar blijven, zelfs als één replica mislukt.
Zie Aanbevelingen voor het ontwerpen voor redundantie en aanbevelingen voor het gebruik van beschikbaarheidszones en regio's voor meer informatie over redundantie.
Schaalbaarheid en flexibiliteit
Schaalbaarheid en elasticiteit zijn de mogelijkheden van een systeem voor het afhandelen van verhoogde belasting door resources (schaalbaarheid) toe te voegen en te verwijderen, en om dit snel te doen wanneer uw vereisten veranderen (elasticiteit). Schaalbaarheid en elasticiteit kunnen een systeem helpen de beschikbaarheid te behouden tijdens piekbelastingen.
Veel Azure-services ondersteunen schaalbaarheid. Hieronder volgen een aantal voorbeelden:
- Azure Virtual Machine Scale Sets, Azure API Management en verschillende andere services ondersteunen automatische schaalaanpassing van Azure Monitor. Met automatische schaalaanpassing van Azure Monitor kunt u beleidsregels opgeven zoals 'wanneer mijn CPU consistent hoger is dan 80%, een ander exemplaar toevoegen'.
- Azure Functions kan instanties dynamisch inrichten om uw aanvragen te verwerken.
- Azure Cosmos DB ondersteunt doorvoer voor automatisch schalen, waarbij de service automatisch de resources kan beheren die zijn toegewezen aan uw databases op basis van beleid dat u opgeeft.
Schaalbaarheid is een belangrijke factor om rekening mee te houden tijdens gedeeltelijke of volledige storingen. Als een replica of rekenproces niet beschikbaar is, moeten de resterende onderdelen mogelijk meer belasting dragen om de belasting te verwerken die eerder werd verwerkt door het defecte knooppunt. Overweeg overprovisioning als uw systeem niet snel genoeg kan schalen om de verwachte wijzigingen in de belasting af te handelen.
Zie Aanbevelingen voor het ontwerpen van een betrouwbare schaalstrategie voor meer informatie over het ontwerpen van een schaalbaar en elastisch systeem.
Implementatietechnieken zonder downtime
Implementaties en andere systeemwijzigingen veroorzaken een aanzienlijk risico op downtime. Omdat downtimerisico's een uitdaging zijn voor hoge beschikbaarheidsvereisten, is het belangrijk om implementatieprocedures zonder downtime te gebruiken om updates en configuratiewijzigingen aan te brengen zonder dat hiervoor downtime is vereist.
Implementatietechnieken zonder downtime kunnen het volgende omvatten:
- Een subset van uw resources tegelijk bijwerken.
- De hoeveelheid verkeer beheren die de nieuwe implementatie bereikt.
- Controleren op eventuele gevolgen voor uw gebruikers of systeem.
- Het probleem snel oplossen, bijvoorbeeld door terug te keren naar een eerdere bekende goede implementatie.
Zie Veilige implementatieprocedures voor meer informatie over implementatietechnieken zonder downtime.
Azure zelf maakt gebruik van implementatiemethoden zonder downtime voor onze eigen services. Wanneer u uw eigen toepassingen bouwt, kunt u implementaties zonder downtime implementeren via verschillende benaderingen, zoals:
- Azure Container Apps biedt meerdere revisies van uw toepassing, die kunnen worden gebruikt om implementaties zonder downtime te realiseren.
- Azure Kubernetes Service (AKS) ondersteunt diverse implementatietechnieken zonder downtime.
Hoewel implementaties zonder downtime vaak worden gekoppeld aan toepassingsimplementaties, moeten ze ook worden gebruikt voor configuratiewijzigingen. Hier volgen enkele manieren waarop u configuratiewijzigingen veilig kunt toepassen:
- Met Azure Storage kunt u de toegangssleutels van uw opslagaccount in meerdere fasen wijzigen, waardoor downtime tijdens sleutelrotatiebewerkingen wordt voorkomen.
- Azure-app Configuration biedt functievlagmen, momentopnamen en andere mogelijkheden waarmee u kunt bepalen hoe configuratiewijzigingen worden toegepast.
Als u besluit geen implementaties zonder downtime te implementeren, moet u ervoor zorgen dat u onderhoudsvensters definieert, zodat u systeemwijzigingen tegelijk kunt aanbrengen wanneer uw gebruikers dit verwachten.
Geautomatiseerd testen
Het is belangrijk om te testen of uw oplossing bestand is tegen de storingen en storingen die u beschouwt als een hoge beschikbaarheid. Veel van deze fouten kunnen worden gesimuleerd in testomgevingen. Het testen van de mogelijkheid van uw oplossing om automatisch te tolereren of herstellen van verschillende fouttypen wordt chaos-engineering genoemd. Chaos engineering is essentieel voor volwassen organisaties met strenge normen voor hoge beschikbaarheid. Azure Chaos Studio is een hulpprogramma voor chaos-engineering waarmee enkele veelvoorkomende fouttypen kunnen worden gesimuleerd.
Zie Aanbevelingen voor het ontwerpen van een strategie voor betrouwbaarheidstests voor meer informatie.
Bewaking en waarschuwingen
Bewaking laat u weten wat de status van uw systeem is, zelfs wanneer er geautomatiseerde oplossingen worden uitgevoerd. Bewaking is essentieel om te begrijpen hoe uw oplossing zich gedraagt en om te kijken naar vroege signalen van fouten, zoals verhoogde foutpercentages of een hoog resourceverbruik. Met waarschuwingen kunt u proactief belangrijke wijzigingen in uw omgeving ontvangen.
Azure biedt diverse mogelijkheden voor bewaking en waarschuwingen, waaronder de volgende:
- Azure Monitor verzamelt logboeken en metrische gegevens van Azure-resources en -toepassingen en kan waarschuwingen verzenden en gegevens weergeven in dashboards.
- Azure Monitor Application Insights biedt gedetailleerde bewaking van uw toepassingen.
- Azure Service Health en Azure Resource Health bewaken de status van het Azure-platform en uw resources.
- Geplande gebeurtenissen adviseren wanneer onderhoud is gepland voor virtuele machines.
Zie Aanbevelingen voor het ontwerpen van een betrouwbare bewakings- en waarschuwingsstrategie voor meer informatie.
Herstel na noodgeval
Een noodgeval is een afzonderlijke, ongebruikelijke, belangrijke gebeurtenis die een grotere en langere impact heeft dan een toepassing kan beperken via het aspect hoge beschikbaarheid van het ontwerp. Voorbeelden van rampen zijn:
- Natuurrampen, zoals orkanen, aardbevingen, overstromingen of brand.
- Menselijke fouten die leiden tot een grote impact, zoals het per ongeluk verwijderen van productiegegevens of een onjuist geconfigureerde firewall die gevoelige gegevens beschikbaar maakt.
- Belangrijke beveiligingsincidenten, zoals denial of service- of ransomware-aanvallen die leiden tot beschadiging van gegevens, gegevensverlies of servicestoringen.
Herstel na noodgevallen gaat over het plannen van hoe u reageert op dit soort situaties.
Notitie
Volg aanbevolen procedures in uw oplossing om de kans op deze gebeurtenissen te minimaliseren. Zelfs na zorgvuldige proactieve planning is het echter verstandig om te plannen hoe u op deze situaties zou reageren als deze zich voordoen.
Vereisten voor herstel na noodgevallen
Vanwege de zeldzaamheid en ernst van noodgebeurtenissen brengt dr-planning verschillende verwachtingen met zich mee voor uw reactie. Veel organisaties accepteren het feit dat in een noodscenario een bepaald niveau van downtime of gegevensverlies onvermijdelijk is. Een volledig DR-plan moet de volgende kritieke bedrijfsvereisten voor elke stroom opgeven:
Recovery Point Objective (RPO) is de maximale duur van acceptabel gegevensverlies in het geval van een noodgeval. RPO wordt gemeten in tijdseenheden, zoals '30 minuten aan gegevens' of 'vier uur aan gegevens'.
Recovery Time Objective (RTO) is de maximale duur van acceptabele downtime in het geval van een noodgeval, waarbij 'downtime' wordt gedefinieerd door uw specificatie. RTO wordt ook gemeten in tijdseenheden, zoals 'acht uur downtime'.
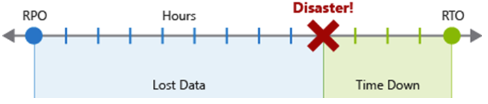
Elk onderdeel of elke stroom in de workload kan afzonderlijke RPO- en RTO-waarden hebben. Bekijk risico's en mogelijke herstelstrategieën voor noodgevallen bij het bepalen van de vereisten. Het proces voor het opgeven van een RPO en RTO creëert effectief DR-vereisten voor uw workload als gevolg van uw unieke zakelijke zorgen (kosten, impact, gegevensverlies, enzovoort).
Notitie
Hoewel het verleidelijk is om te streven naar een RTO en RPO van nul (geen downtime en geen gegevensverlies in het geval van een noodgeval), is het in de praktijk moeilijk en kostbaar om te implementeren. Het is belangrijk voor technische en zakelijke belanghebbenden om deze vereisten samen te bespreken en te beslissen over realistische vereisten. Zie Aanbevelingen voor het definiëren van betrouwbaarheidsdoelen voor meer informatie.
Plannen voor herstel na noodgevallen
Ongeacht de oorzaak van de ramp, is het belangrijk dat u een goed gedefinieerd en testbaar DR-plan maakt. Dat plan wordt gebruikt als onderdeel van infrastructuur- en toepassingsontwerp om het actief te ondersteunen. U kunt meerdere DR-plannen maken voor verschillende soorten situaties. DR-plannen zijn vaak afhankelijk van procescontroles en handmatige interventie.
DR is geen automatische functie van Azure. Veel services bieden echter functies en mogelijkheden die u kunt gebruiken om uw strategieën voor herstel na noodgeval te ondersteunen. Bekijk de betrouwbaarheidshandleidingen voor elke Azure-service om te begrijpen hoe de service werkt en de mogelijkheden ervan, en wijs deze mogelijkheden vervolgens toe aan uw DR-plan.
De volgende secties bevatten enkele algemene elementen van een plan voor herstel na noodgevallen en beschrijven hoe Azure u kan helpen deze te bereiken.
Failover en failback
Sommige noodherstelplannen omvatten het inrichten van een secundaire implementatie op een andere locatie. Als een noodgeval van invloed is op de primaire implementatie van de oplossing, kan het verkeer vervolgens worden overgeschakeld naar de andere site. Failover vereist zorgvuldige planning en implementatie. Azure biedt diverse services om te helpen bij failover, zoals:
- Azure Site Recovery biedt geautomatiseerde failover voor on-premises omgevingen en door virtuele machines gehoste oplossingen in Azure.
- Azure Front Door en Azure Traffic Manager ondersteunen automatische failover van binnenkomend verkeer tussen verschillende implementaties van uw oplossing, zoals in verschillende regio's.
Het duurt meestal enige tijd voordat een failoverproces detecteert dat het primaire exemplaar is mislukt en naar het secundaire exemplaar overschakelt. Zorg ervoor dat de RTO van de workload is afgestemd op de failovertijd.
Het is ook belangrijk om een failback te overwegen. Dit is het proces waarmee u bewerkingen herstelt in de primaire regio nadat deze is hersteld. Failback kan complex zijn om te plannen en implementeren. Gegevens in de primaire regio kunnen bijvoorbeeld zijn geschreven nadat de failover is gestart. U moet zorgvuldige zakelijke beslissingen nemen over de manier waarop u die gegevens verwerkt.
Back-ups
Back-ups omvatten het maken van een kopie van uw gegevens en het veilig opslaan ervan gedurende een bepaalde periode. Met back-ups kunt u herstellen van noodgevallen wanneer automatische failover naar een andere replica niet mogelijk is of wanneer er beschadiging van gegevens is opgetreden.
Wanneer u back-ups gebruikt als onderdeel van een noodherstelplan, is het belangrijk om rekening te houden met het volgende:
Opslaglocatie. Wanneer u back-ups gebruikt als onderdeel van een noodherstelplan, moeten ze afzonderlijk worden opgeslagen in de hoofdgegevens. Back-ups worden meestal opgeslagen in een andere Azure-regio.
Gegevensverlies. Omdat back-ups meestal onregelmatig worden gemaakt, gaat het meestal om gegevensverlies. Daarom moet back-upherstel worden gebruikt als laatste redmiddel en moet een noodherstelplan de volgorde opgeven van de stappen en herstelpogingen die moeten worden uitgevoerd voordat een back-up wordt hersteld. Het is belangrijk om ervoor te zorgen dat de RPO van de workload is afgestemd op het back-upinterval.
Hersteltijd. Het herstellen van back-ups duurt vaak tijd, dus het is essentieel om uw back-ups en herstelprocessen te testen om hun integriteit te controleren en te begrijpen hoe lang het herstelproces duurt. Zorg ervoor dat de RTO-accounts van de werkbelasting gedurende de tijd die nodig is om uw back-up te herstellen.
Veel Azure-gegevens- en opslagservices ondersteunen back-ups, zoals de volgende:
- Azure Backup biedt geautomatiseerde back-ups voor schijven van virtuele machines, opslagaccounts, AKS en diverse andere bronnen.
- Veel Azure-databaseservices, waaronder Azure SQL Database en Azure Cosmos DB, hebben een geautomatiseerde back-upmogelijkheid voor uw databases.
- Azure Key Vault biedt functies voor het maken van back-ups van uw geheimen, certificaten en sleutels.
Geautomatiseerde implementaties
Als u de vereiste resources snel wilt implementeren en configureren in het geval van een noodgeval, gebruikt u Assets voor Infrastructuur als code (IaC), zoals Bicep-bestanden, ARM-sjablonen of Terraform-configuratiebestand. Het gebruik van IaC vermindert de hersteltijd en het potentieel voor fouten, vergeleken met het handmatig implementeren en configureren van resources.
Testen en analyseren
Het is essentieel om uw DR-plannen regelmatig te valideren en te testen, evenals uw bredere betrouwbaarheidsstrategie. Neem alle menselijke processen in uw drills op en richt u niet alleen op de technische processen.
Als u uw herstelprocessen in een noodsimulatie niet hebt getest, ondervindt u waarschijnlijk grote problemen bij het gebruik ervan in een echte ramp. Door uw DR-plannen en vereiste processen te testen, kunt u ook de haalbaarheid van uw RTO valideren.
Zie Aanbevelingen voor het ontwerpen van een strategie voor betrouwbaarheidstests voor meer informatie.
Gerelateerde inhoud
- Gebruik de azure-servicebetrouwbaarheidshandleidingen om te begrijpen hoe elke Azure-service betrouwbaarheid ondersteunt in het ontwerp en om meer te weten te komen over de mogelijkheden die u inbouwt in uw plannen voor hoge beschikbaarheid en herstel na noodgevallen.
- Gebruik het Goed ontworpen Framework van Azure: de pijler Betrouwbaarheid voor meer informatie over het ontwerpen van een betrouwbare workload in Azure.
- Gebruik het perspectief van well-architected Framework op Azure-services voor meer informatie over het configureren van elke Azure-service om te voldoen aan uw vereisten voor betrouwbaarheid en over de andere pijlers van het Well-Architected Framework.
- Zie Aanbevelingen voor het ontwerpen van een strategie voor herstel na noodgevallen voor meer informatie over planning voor herstel na noodgevallen.