Richtlijnen voor het oplossen van problemen
Dit artikel bevat veelgestelde vragen over het gebruik van promptstromen.
Problemen met betrekking tot stroomcreatie
Fout 'Pakketprogramma is niet gevonden' treedt op wanneer u de flow bijwerkt voor een code-first ervaring
Wanneer u stromen bijwerkt voor een code-first-ervaring, als de stroom gebruikmaakt van de hulpprogramma's Faiss Index Lookup, Vector Index Lookup, Vector DB Lookup of Content Safety (Tekst), kan het volgende foutbericht worden weergegeven:
Package tool 'embeddingstore.tool.faiss_index_lookup.search' is not found in the current environment.
U hebt twee opties om het probleem op te lossen:
Optie 1
Werk uw rekensessie bij naar de meest recente versie van de basisinstallatiekopieën.
Selecteer de modus Raw-bestand om over te schakelen naar de onbewerkte codeweergave. Open vervolgens het bestand flow.dag.yaml .

Werk de namen van de hulpprogramma's bij.
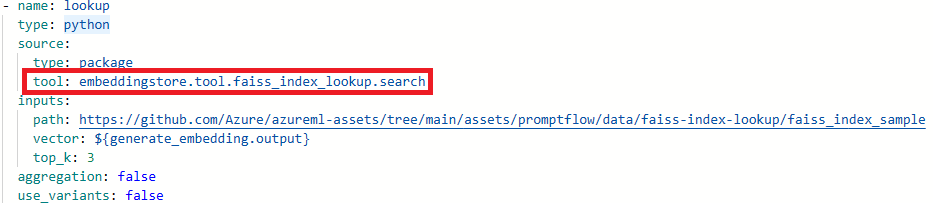
Hulpprogramma Naam van nieuw hulpprogramma Zoeken naar faiss-index promptflow_vectordb.tool.faiss_index_lookup. FaissIndexLookup.search Vector Index Opzoeken promptflow_vectordb.tool.vector_index_lookup. VectorIndexLookup.search Vector DB Opzoeken promptflow_vectordb.tool.vector_db_lookup. VectorDBLookup.search Inhoudsveiligheid (tekst) content_safety_text.tools.content_safety_text_tool.analyze_text Sla het bestand flow.dag.yaml op .
Optie 2
- Uw rekensessie bijwerken naar de meest recente versie van de basisinstallatiekopieën
- Verwijder het oude hulpprogramma en maak een nieuw hulpprogramma opnieuw.
Fout 'Een dergelijk(e) bestand of map bestaat niet'
De promptstroom is afhankelijk van een bestandsshareopslag om een momentopname van de stroom op te slaan. Als de bestandsshareopslag een probleem heeft, kan het volgende probleem optreden. Hier volgen enkele tijdelijke oplossingen die u kunt proberen:
Als u een privéopslagaccount gebruikt, raadpleegt u Netwerkisolatie in promptstroom om ervoor te zorgen dat uw werkruimte toegang heeft tot uw opslagaccount.
Als het opslagaccount is ingeschakeld voor openbare toegang, controleert u of er een gegevensarchief is met de naam
workspaceworkingdirectoryin uw werkruimte. Dit moet een bestandstype zijn.
- Als u dit gegevensarchief niet hebt ontvangen, moet u deze toevoegen aan uw werkruimte.
- Maak een bestandsshare met de naam
code-391ff5ac-6576-460f-ba4d-7e03433c68b6. - Maak een gegevensarchief met de naam
workspaceworkingdirectory. Zie Gegevensarchieven maken.
- Maak een bestandsshare met de naam
- Als u een
workspaceworkingdirectorygegevensarchief hebt, maar het bijbehorende typeblobis in plaats vanfileshare, maakt u een nieuwe werkruimte. Gebruik opslag die hiërarchische naamruimten niet inschakelt voor Azure Data Lake Storage Gen2 als standaardopslagaccount voor werkruimten. Zie Werkruimte maken voor meer informatie.
- Als u dit gegevensarchief niet hebt ontvangen, moet u deze toevoegen aan uw werkruimte.

Flow ontbreekt

Er zijn mogelijke redenen voor dit probleem:
Als openbare toegang tot uw opslagaccount is uitgeschakeld, moet u ervoor zorgen dat u toegang krijgt door uw IP toe te voegen aan de opslagfirewall of toegang in te schakelen via een virtueel netwerk met een privé-eindpunt dat is verbonden met het opslagaccount.
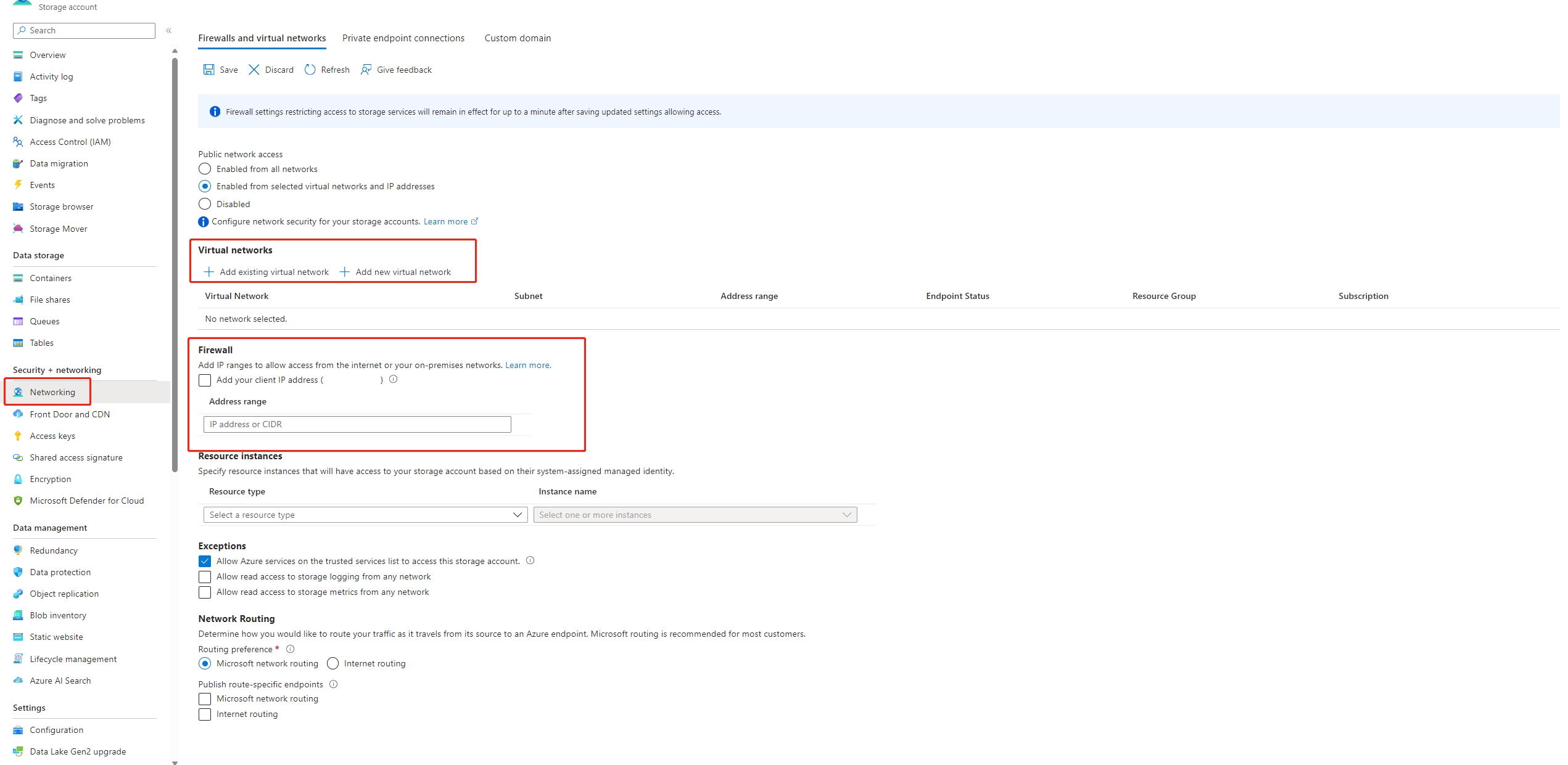
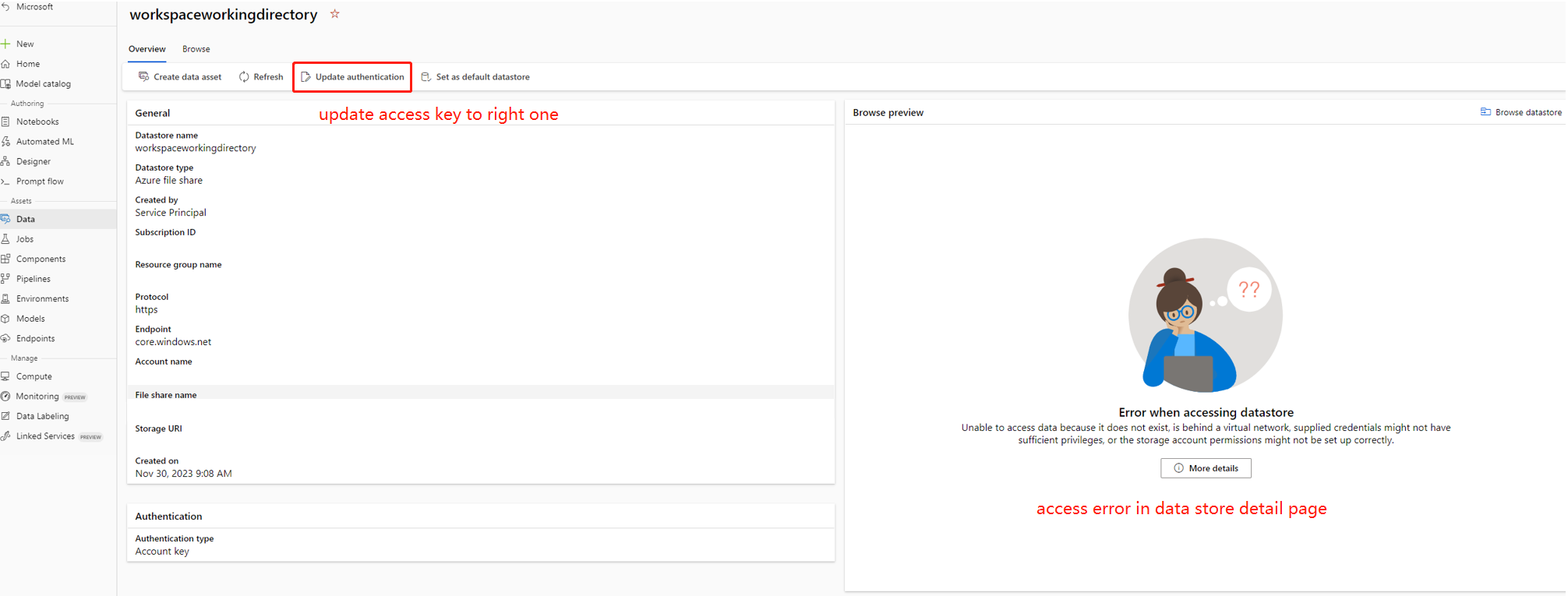
In sommige gevallen is de accountsleutel in het gegevensarchief niet gesynchroniseerd met het opslagaccount. U kunt proberen de accountsleutel bij te werken op de detailpagina van het gegevensarchief om dit op te lossen.
Als u Azure AI Foundry gebruikt, moet het opslagaccount CORS instellen om Azure AI Foundry toegang te geven tot het opslagaccount. Anders ziet u dat de stroom ontbreekt. U kunt de volgende CORS-instellingen toevoegen aan het opslagaccount om dit probleem op te lossen.
- Ga naar de pagina opslagaccount, selecteer
Resource sharing (CORS)ondersettingsen selecteer het tabbladFile service. - Toegestane oorsprongen:
https://mlworkspace.azure.ai,https://ml.azure.com,https://*.ml.azure.com,https://ai.azure.com,https://*.ai.azure.com,https://mlworkspacecanary.azure.ai,https://mlworkspace.azureml-test.net - Toegestane methoden:
DELETE, GET, HEAD, POST, OPTIONS, PUT
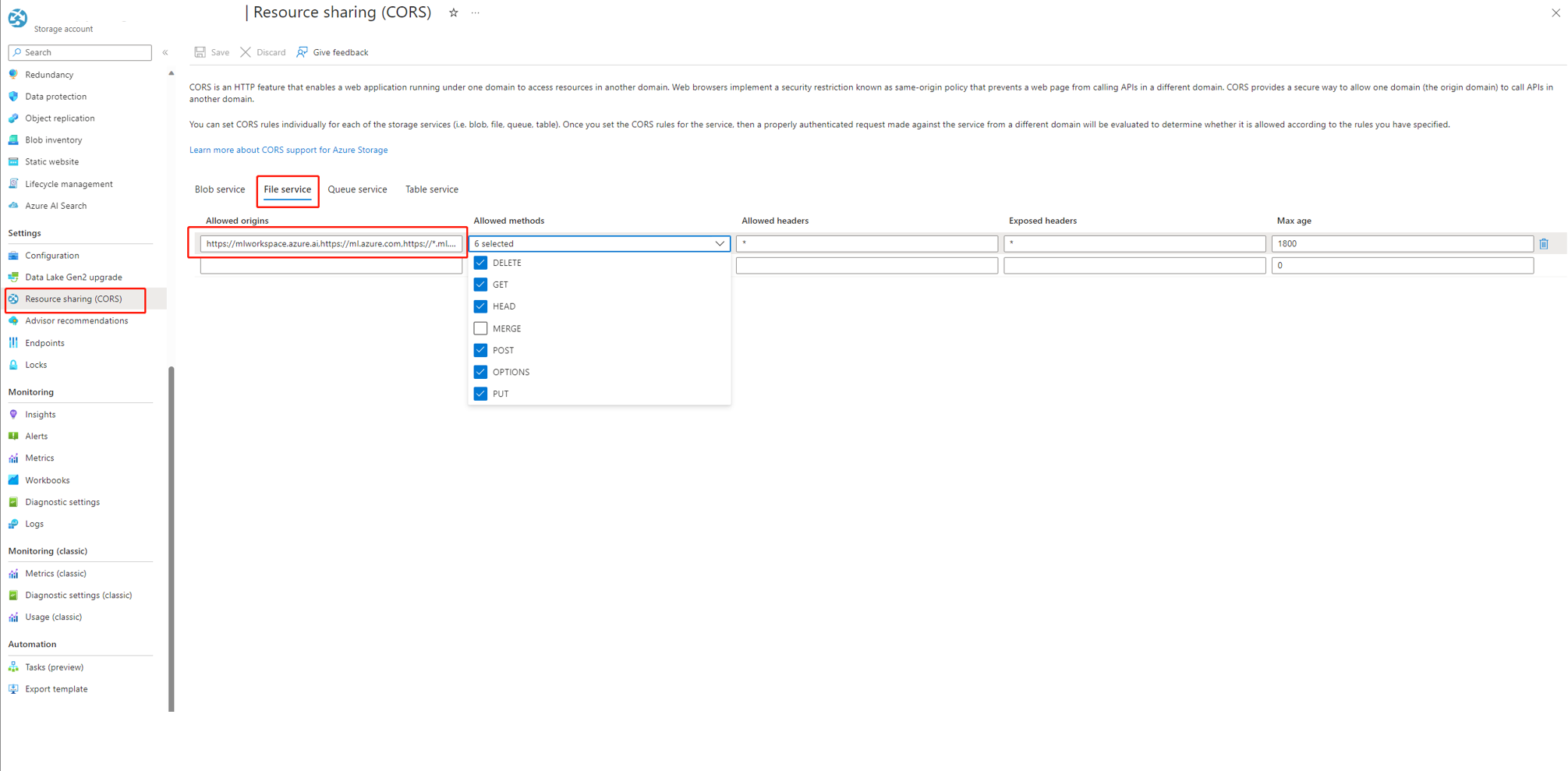
- Ga naar de pagina opslagaccount, selecteer



Problemen met betrekking tot compute-sessies
Uitvoeren is mislukt vanwege 'Geen module met de naam XXX'
Dit type fout met betrekking tot rekensessies ontbreekt vereiste pakketten. Als u een standaardomgeving gebruikt, controleert u of de installatiekopieën van uw rekensessie de nieuwste versie gebruiken. Als u een aangepaste basisinstallatiekopieën gebruikt, moet u ervoor zorgen dat u alle vereiste pakketten in uw Docker-context hebt geïnstalleerd. Zie Basisinstallatiekopieën aanpassen voor de rekensessie voor meer informatie.
Waar vind ik het serverloze exemplaar dat wordt gebruikt door de rekensessie?
U kunt de serverloze instantie bekijken die door de rekensessie wordt gebruikt op het tabblad Lijst met rekensessies op de pagina Compute. Meer informatie over het beheren van serverloze exemplaren.
Fouten in rekensessies met behulp van aangepaste basisinstallatiekopie
Fout bij het starten van de rekensessie met requirements.txt of aangepaste basisinstallatiekopie
Ondersteuning voor rekensessies voor het gebruik requirements.txt of aangepaste basisinstallatiekopieën om flow.dag.yaml de installatiekopieën aan te passen. We raden u aan om te gebruiken requirements.txt voor veelvoorkomende gevallen, die wordt gebruikt pip install -r requirements.txt om de pakketten te installeren. Als u meer afhankelijk bent dan Python-pakketten, moet u de basisinstallatiekopieën aanpassen volgen om een nieuwe installatiekopieënbasis te maken boven op de basisinstallatiekopieën van de promptstroom. Gebruik het vervolgens in flow.dag.yaml. Meer informatie over het opgeven van basisinstallatiekopieën in een rekensessie.
- U kunt geen willekeurige basisinstallatiekopie gebruiken om een Compute-sessie te maken. U moet de basisinstallatiekopie gebruiken die wordt opgegeven door de promptstroom.
- Maak de versie van
promptflowenpromptflow-toolsinrequirements.txtniet vast, omdat deze al zijn opgenomen in de basisinstallatiekopieën. Het gebruik van een oude versie vanpromptflowenpromptflow-toolskan onverwacht gedrag veroorzaken.
Problemen met betrekking tot stroomuitvoering
Hoe vind ik de onbewerkte invoer en uitvoer van het LLM-hulpprogramma voor verder onderzoek?
In de promptstroom, op de stroompagina met geslaagde uitvoering en uitvoeringsdetailpagina, vindt u de onbewerkte invoer en uitvoer van het LLM-hulpprogramma in de uitvoersectie. Selecteer de view full output knop om de volledige uitvoer weer te geven.

Trace sectie bevat elke aanvraag en reactie op het LLM-hulpprogramma. U kunt het onbewerkte bericht controleren dat is verzonden naar het LLM-model en het onbewerkte antwoord van het LLM-model.

Hoe kan ik een 409-fout van Azure OpenAI oplossen?
Er kan een 409-fout optreden van Azure OpenAI. Dit betekent dat u de frequentielimiet van Azure OpenAI hebt bereikt. U kunt het foutbericht controleren in de uitvoersectie van het LLM-knooppunt. Meer informatie over azure OpenAI-frequentielimiet.

Bepalen welk knooppunt de meeste tijd verbruikt
Controleer de rekensessielogboeken.
Probeer de volgende waarschuwingslogboekindeling te vinden:
{node_name} wordt gedurende {duration} seconden uitgevoerd.
Voorbeeld:
Case 1: Python-scriptknooppunt wordt lang uitgevoerd.

In dit geval kunt u vinden dat deze
PythonScriptNodegedurende lange tijd wordt uitgevoerd (bijna 300 seconden). Vervolgens kunt u de details van het knooppunt controleren om te zien wat het probleem is.Case 2: LLM-knooppunt wordt lange tijd uitgevoerd.
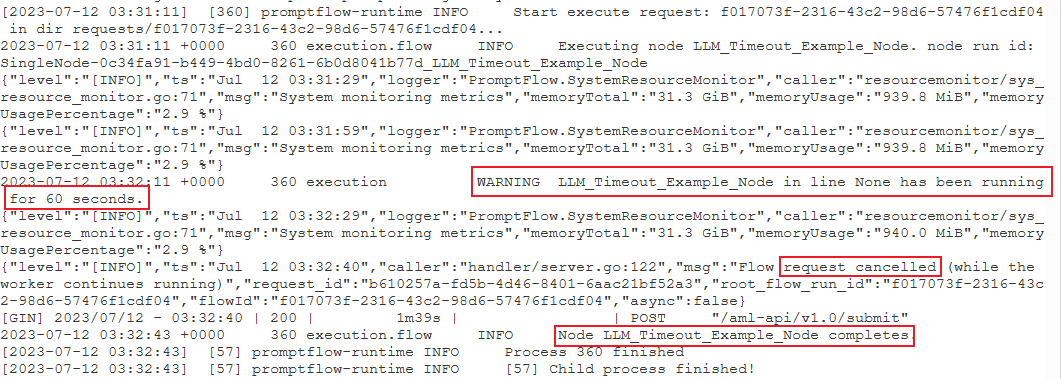
Als u het bericht
request canceledin de logboeken vindt, kan het zijn dat de OpenAI API-aanroep te lang duurt en de time-outlimiet overschrijdt.Een Time-out voor de OpenAI-API kan worden veroorzaakt door een netwerkprobleem of een complexe aanvraag waarvoor meer verwerkingstijd is vereist. Zie Time-out voor OpenAI API voor meer informatie.
Wacht een paar seconden en voer uw aanvraag opnieuw uit. Met deze actie worden eventuele netwerkproblemen meestal opgelost.
Als het opnieuw proberen niet werkt, controleert u of u een lang contextmodel gebruikt, zoals
gpt-4-32k, en hebt u een grote waarde ingesteld voormax_tokens. Zo ja, dan wordt het gedrag verwacht omdat uw prompt mogelijk een lang antwoord genereert dat langer duurt dan de bovenste drempelwaarde van de interactieve modus. In deze situatie wordt u aangeradenBulk testte proberen omdat deze modus geen time-outinstelling heeft.
Als u niets in logboeken kunt vinden om aan te geven dat het een specifiek knooppuntprobleem is:
- Neem contact op met het promptstroomteam (promptflow-eng) met de logboeken. We proberen de hoofdoorzaak te identificeren.


Problemen met betrekking tot stroomimplementatie
Geen autorisatie voor het uitvoeren van de actie 'Microsoft.MachineLearningService/workspaces/datastores/read'
Als uw stroom het hulpprogramma Index Opzoeken bevat, moet het eindpunt na het implementeren van de stroom toegang krijgen tot het gegevensarchief van de werkruimte om het YAML-bestand of de FAISS-map met segmenten en insluitingen te lezen. Daarom moet u de eindpuntidentiteit handmatig toestemming geven om dit te doen.
U kunt de eindpuntidentiteit azureML Datawetenschapper verlenen voor het bereik van de werkruimte of een aangepaste rol die de actie MachineLearningService/workspace/datastore/reader bevat.
Time-outprobleem voor upstream-aanvragen bij gebruik van het eindpunt
Als u CLI of SDK gebruikt om de stroom te implementeren, kan er een time-outfout optreden.
request_timeout_ms De standaardwaarde is 5000. U kunt maximaal 5 minuten opgeven, wat 300.000 ms is. Hieronder ziet u een voorbeeld van het opgeven van een time-out voor aanvragen in het yaml-bestand voor de implementatie. Zie het implementatieschema voor meer informatie.
request_settings:
request_timeout_ms: 300000
OpenAI-API raakt verificatiefout
Als u uw Azure OpenAI-sleutel opnieuw genereert en de verbinding die in de promptstroom wordt gebruikt, handmatig bijwerkt, kunnen er fouten optreden zoals 'Niet geautoriseerd'. Het toegangstoken ontbreekt, is ongeldig, de doelgroep is onjuist of is verlopen. Wanneer u een bestaand eindpunt aanroept dat is gemaakt voordat de sleutel opnieuw wordt gegenereerd.
Dit komt doordat de verbindingen die worden gebruikt in de eindpunten/implementaties niet automatisch worden bijgewerkt. Elke wijziging voor sleutel of geheimen in implementaties moet worden uitgevoerd door handmatige updates, die erop is gericht om te voorkomen dat de online productie-implementatie wordt beïnvloed door onbedoelde offlinebewerkingen.
- Als het eindpunt is geïmplementeerd in de gebruikersinterface van Studio, kunt u de stroom gewoon opnieuw implementeren naar het bestaande eindpunt met dezelfde implementatienaam.
- Als het eindpunt is geïmplementeerd met behulp van SDK of CLI, moet u een aantal wijzigingen aanbrengen in de implementatiedefinitie, zoals het toevoegen van een dummy-omgevingsvariabele en vervolgens gebruiken om uw implementatie bij te werken
az ml online-deployment update.
Problemen met beveiligingsproblemen in promptstroomimplementaties
Voor beveiligingsproblemen met betrekking tot promptstroomruntime zijn de volgende benaderingen die u kunnen helpen beperken:
- Werk de afhankelijkheidspakketten in uw requirements.txt bij in de stroommap.
- Als u een aangepaste basisinstallatiekopie voor uw stroom gebruikt, moet u de promptstroomruntime bijwerken naar de nieuwste versie en de basisinstallatiekopie opnieuw bouwen en vervolgens de stroom opnieuw implementeren.
Voor eventuele andere beveiligingsproblemen van beheerde online-implementaties lost Azure Machine Learning de problemen maandelijks op.
"MissingDriverProgram Error" of "Kan stuurprogrammaprogramma niet vinden in de aanvraag"
Als u uw stroom implementeert en de volgende fout tegenkomt, is deze mogelijk gerelateerd aan de implementatieomgeving.
'error':
{
'code': 'BadRequest',
'message': 'The request is invalid.',
'details':
{'code': 'MissingDriverProgram',
'message': 'Could not find driver program in the request.',
'details': [],
'additionalInfo': []
}
}
Could not find driver program in the request
Er zijn twee manieren om deze fout op te lossen.
(Aanbevolen) U vindt de containerinstallatiekopieën-URI op de detailpagina van uw aangepaste omgeving en stelt deze in als de basisinstallatiekopieën van de stroom in het bestand flow.dag.yaml. Wanneer u de stroom in de gebruikersinterface implementeert, selecteert u Alleen de omgeving van de huidige stroomdefinitie gebruiken. De back-endservice maakt de aangepaste omgeving op basis van deze basisinstallatiekopieën en
requirement.txtvoor uw implementatie. Meer informatie over de omgeving die is opgegeven in de stroomdefinitie.
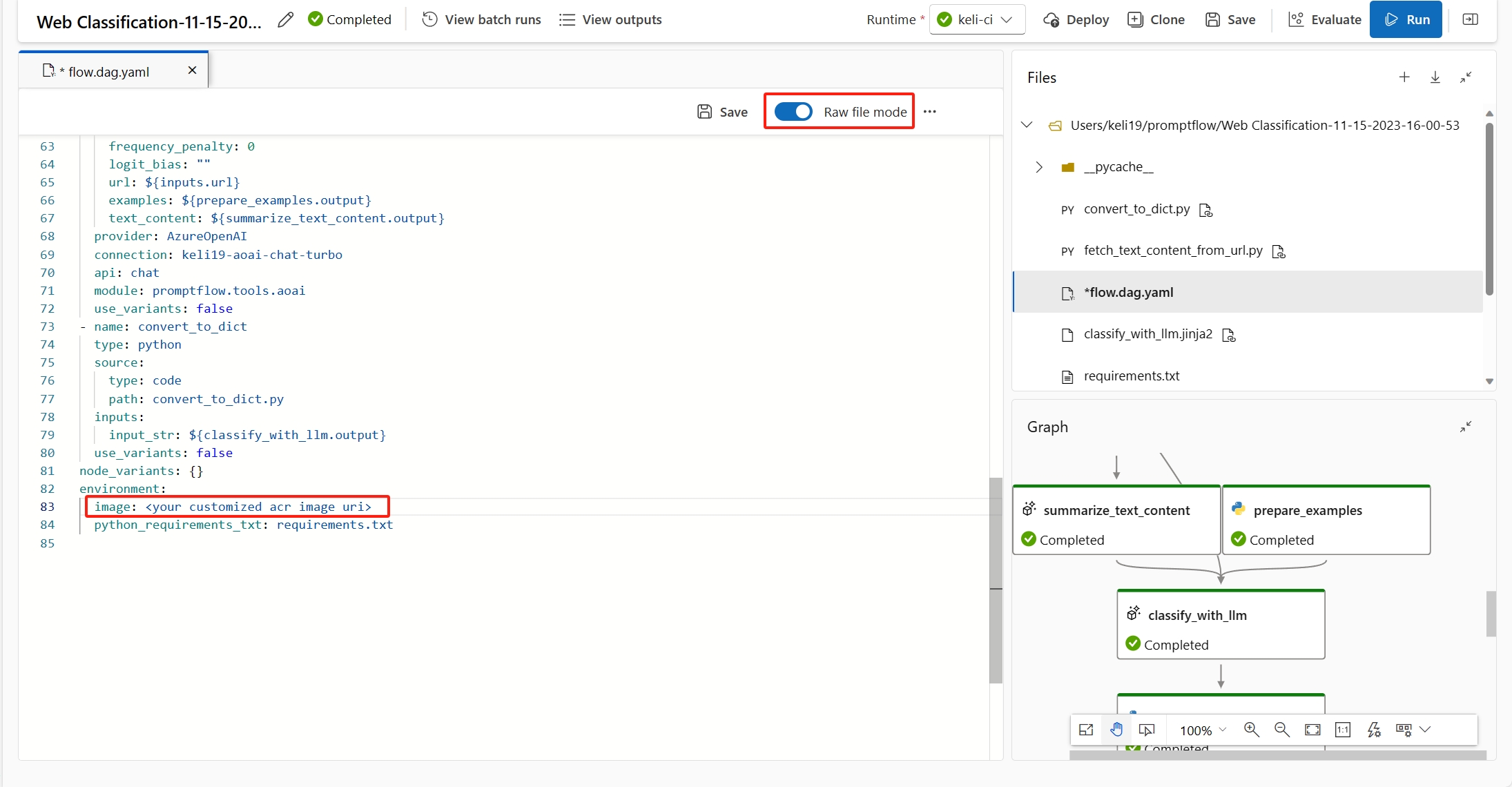
U kunt deze fout oplossen door de definitie van uw aangepaste omgeving toe te voegen
inference_config.Hieronder volgt een voorbeeld van een aangepaste omgevingsdefinitie.


$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
Modelreactie duurt te lang
Soms merkt u misschien dat de implementatie te lang duurt om te reageren. Er zijn verschillende mogelijke factoren voor dit optreden.
- Het model dat in de stroom wordt gebruikt, is niet krachtig genoeg (bijvoorbeeld: GPT 3.5 gebruiken in plaats van tekst-ada)
- Indexquery is niet geoptimaliseerd en duurt te lang
- Flow heeft veel stappen om te verwerken
Overweeg het eindpunt te optimaliseren met bovenstaande overwegingen om de prestaties van het model te verbeteren.
Kan het implementatieschema niet ophalen
Nadat u het eindpunt hebt geïmplementeerd en het wilt testen op het tabblad Testen op de detailpagina van het eindpunt, kunt u de volgende twee methoden proberen om dit probleem te verhelpen als op het tabblad Testen wordt weergegeven dat het implementatieschema niet kan worden opgehaald:

- Zorg ervoor dat u de juiste machtiging hebt verleend voor de eindpuntidentiteit. Meer informatie over het verlenen van machtigingen aan de eindpuntidentiteit.
- Het kan zijn dat u de stroom hebt uitgevoerd in een oude versieruntime en vervolgens de stroom hebt geïmplementeerd, de implementatie de omgeving van de runtime gebruikte die zich ook in de oude versie bevond. Als u de runtime wilt bijwerken, volgt u Een runtime bijwerken in de gebruikersinterface en voert u de stroom opnieuw uit in de meest recente runtime en implementeert u de stroom opnieuw.
Toegang geweigerd om het werkruimtegeheim weer te geven
Als er een fout optreedt als 'Toegang geweigerd om werkruimtegeheim weer te geven', controleert u of u de juiste machtiging hebt verleend voor de eindpuntidentiteit. Meer informatie over het verlenen van machtigingen aan de eindpuntidentiteit.
Problemen met betrekking tot verificatie en identiteit
Hoe kan ik een referentieloos gegevensarchief gebruiken in stroomlijning?
Als u opslag met referenties wilt gebruiken in de Azure AI Foundry-portal, moet u in principe het volgende doen:
- Wijzig het verificatietype voor het gegevensarchief in None.
- Geef project MSI en gebruikers-blob-/bestandsgegevensbijdragermachtigingen voor opslag.
Authenticatietype van gegevensarchief wijzigen in Geen
U kunt op identiteit gebaseerde gegevensverificatie volgen in dit deel om uw gegevensarchiefreferenties minder te maken.
U moet het verificatietype van het gegevensarchief wijzigen in Geen, wat staat voor meid_token gebaseerde verificatie. U kunt wijzigingen aanbrengen op de detailpagina van het gegevensarchief of de CLI/SDK: https://github.com/Azure/azureml-examples/tree/main/cli/resources/datastore

Voor gegevensopslag op basis van blobs kunt u het verificatietype wijzigen en ook msi van werkruimte inschakelen voor toegang tot het opslagaccount.

Voor gegevensopslag op basis van bestandsshares kunt u alleen het verificatietype wijzigen.

Machtigingen toekennen aan gebruikersidentiteit of beheerde identiteit
Als u referentieloze gegevensopslag wilt gebruiken in een promptstroom, moet u voldoende machtigingen verlenen voor gebruikersidentiteit of beheerde identiteit om toegang te krijgen tot het gegevensarchief.
- Zorg ervoor dat aan het werkruimtesysteem toegewezen beheerde identiteit en
Storage File Data Privileged Contributorin het opslagaccount ten minste lees-/schrijfmachtigingen nodig zijnStorage Blob Data Contributor(beter ook verwijderen). - Als u deze standaardoptie in de promptstroom gebruikt voor gebruikersidentiteiten, moet u ervoor zorgen dat de gebruikersidentiteit de volgende rol heeft in het opslagaccount:
-
Storage Blob Data Contributorin het opslagaccount moet u ten minste de machtiging lezen/schrijven (beter ook verwijderen) nodig hebben. -
Storage File Data Privileged Contributorin het opslagaccount moet u ten minste de machtiging lezen/schrijven (beter ook verwijderen) nodig hebben.
-
- Als u een door de gebruiker toegewezen beheerde identiteit gebruikt, moet u ervoor zorgen dat de beheerde identiteit de volgende rol heeft in het opslagaccount:
-
Storage Blob Data Contributorin het opslagaccount moet u ten minste de machtiging lezen/schrijven (beter ook verwijderen) nodig hebben. -
Storage File Data Privileged Contributorin het opslagaccount moet u ten minste de machtiging lezen/schrijven (beter ook verwijderen) nodig hebben. - Ondertussen moet u ten minste de gebruikersidentiteitsrol
Storage Blob Data Readtoewijzen aan het opslagaccount als u een promptstroom wilt gebruiken voor het ontwerpen en testen van de stroom.
-
- Als u de detailpagina van de stroom nog steeds niet kunt bekijken en de eerste keer dat u een promptstroom gebruikt, ouder is dan 2024-01-01, moet u het MSI-bestand
Storage Table Data Contributorvan de werkruimte toewijzen aan het opslagaccount dat is gekoppeld aan de werkruimte.