Compute-sessie voor promptstroom beheren in Azure Machine Learning-studio
Een rekensessie voor een promptstroom biedt rekenresources die nodig zijn om de toepassing uit te voeren, inclusief een Docker-installatiekopieën die alle benodigde afhankelijkheidspakketten bevat. Dankzij deze betrouwbare en schaalbare omgeving kan promptstroom de taken en functies efficiënt uitvoeren voor een naadloze gebruikerservaring.
Machtigingen en rollen voor rekensessiebeheer
Als u rollen wilt toewijzen, moet u beschikken owner over of Microsoft.Authorization/roleAssignments/write gemachtigd zijn voor de resource.
Wijs voor gebruikers van de rekensessie de AzureML Data Scientist rol toe in de werkruimte. Zie Toegang tot een Azure Machine Learning-werkruimte beheren voor meer informatie.
Het kan enkele minuten duren voordat de roltoewijzing is doorgevoerd.
Een rekensessie starten in Studio
Voordat u Azure Machine Learning-studio gebruikt om een rekensessie te starten, moet u ervoor zorgen dat:
- U hebt de
AzureML Data Scientistrol in de werkruimte. - Het standaardgegevensarchief (meestal
workspaceblobstore) in uw werkruimte is het blobtype. - De werkmap (
workspaceworkingdirectory) bestaat in de werkruimte. - Als u een virtueel netwerk gebruikt voor promptstroom, begrijpt u de overwegingen in netwerkisolatie in promptstroom.
Een rekensessie starten op een stroompagina
Eén stroom wordt gekoppeld aan één rekensessie. U kunt een rekensessie starten op een stroompagina.
Selecteer Starten. Start een rekensessie met behulp van de omgeving die is gedefinieerd in
flow.dag.yamlde stroommap. Deze wordt uitgevoerd op de grootte van de virtuele machine (VM) van serverloze berekeningen die u voldoende quotum in de werkruimte hebt.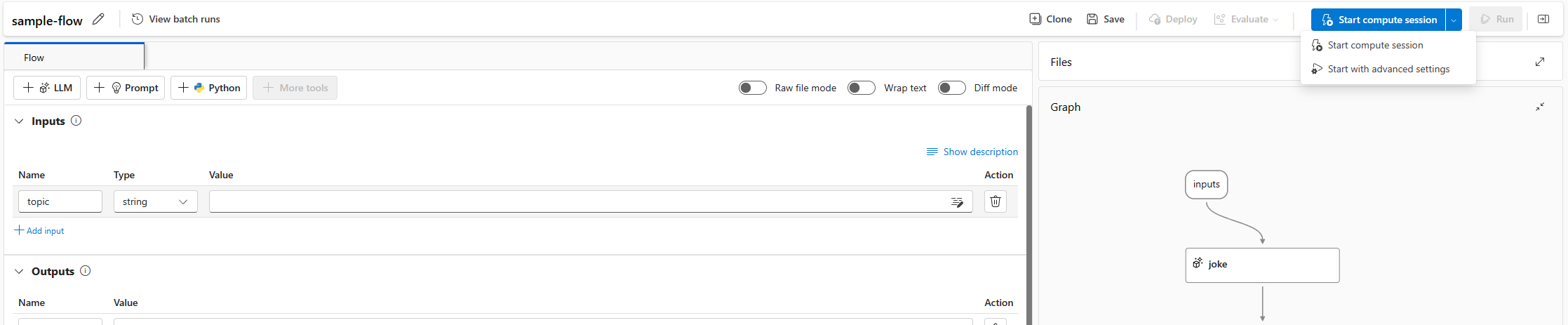
Selecteer Beginnen met geavanceerde instellingen. In de geavanceerde instellingen kunt u het volgende doen:
- Selecteer het rekentype. U kunt kiezen tussen een serverloze reken- en rekeninstantie.
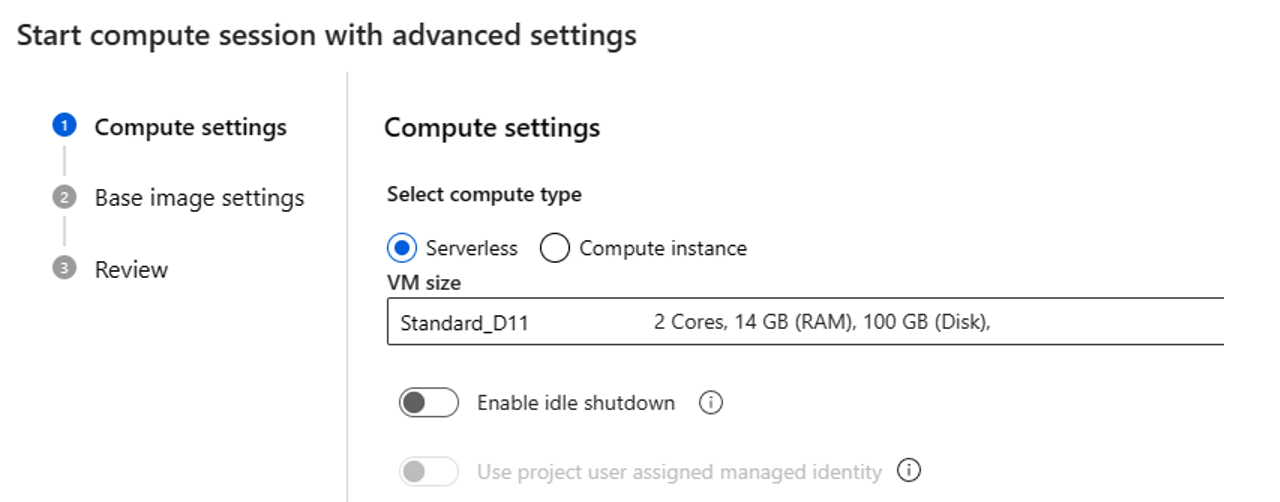
Als u serverloze berekeningen kiest, kunt u de volgende instellingen instellen:
- Pas de VM-grootte aan die door de rekensessie wordt gebruikt. Kies voor VM-serie D en hoger. Zie de sectie over ondersteunde VM-reeksen en -grootten voor meer informatie
- Pas de niet-actieve tijd aan, waardoor de rekensessie automatisch wordt verwijderd als deze gedurende een tijdje niet in gebruik is.
- Stel de door de gebruiker toegewezen beheerde identiteit in. De rekensessie gebruikt deze identiteit om een basisinstallatiekopie op te halen, verificatie met verbinding te maken en pakketten te installeren. Zorg ervoor dat de door de gebruiker toegewezen beheerde identiteit voldoende machtigingen heeft. Als u deze identiteit niet instelt, gebruiken we standaard de gebruikersidentiteit.
- U kunt de volgende CLI-opdracht gebruiken om door de gebruiker toegewezen beheerde identiteit toe te wijzen aan de werkruimte. Meer informatie over het maken en bijwerken van door de gebruiker toegewezen identiteiten voor een werkruimte.
az ml workspace update -f workspace_update_with_multiple_UAIs.yml --subscription <subscription ID> --resource-group <resource group name> --name <workspace name>Waar de inhoud van workspace_update_with_multiple_UAIs.yml als volgt is:
identity: type: system_assigned, user_assigned user_assigned_identities: '/subscriptions/<subscription_id>/resourcegroups/<resource_group_name>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<uai_name>': {} '<UAI resource ID 2>': {}Tip
De volgende Azure RBAC-roltoewijzingen zijn vereist voor uw door de gebruiker toegewezen beheerde identiteit voor uw Azure Machine Learning-werkruimte voor toegang tot gegevens op de aan de werkruimte gekoppelde resources.
Bron Machtiging Azure Machine Learning-werkruimte Inzender Azure Storage Inzender (besturingsvlak) + Inzender voor opslagblobgegevens + Inzender voor opslagbestandsgegevens (gegevensvlak, stroomconcept gebruiken in bestandsshare en gegevens in blob) Azure Key Vault (bij gebruik van machtigingsmodel voor toegangsbeleid) Inzender en machtigingen voor toegangsbeleid naast opschoningsbewerkingen . Dit is de standaardmodus voor gekoppelde Azure Key Vault. Azure Key Vault (wanneer u een RBAC-machtigingsmodel gebruikt) Inzender (besturingsvlak) + Key Vault-beheerder (gegevensvlak) Azure Container Registry Inzender Azure Application Insights Inzender Notitie
De inzender van de taak heeft machtigingen nodig
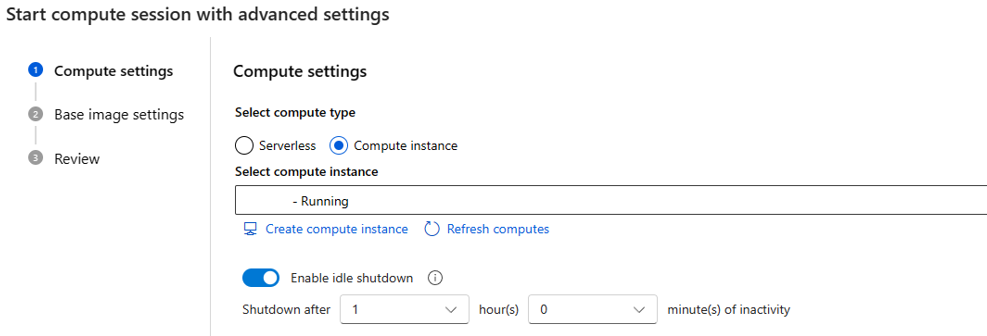
assignvoor door de gebruiker toegewezen beheerde identiteit. U kunt de rol toewijzenManaged Identity Operator, omdat telkens wanneer u een serverloze rekensessie maakt, de door de gebruiker toegewezen beheerde identiteit wordt toegewezen om te berekenen.Als u een rekenproces kiest als rekentype, kunt u alleen de afsluittijd voor inactiviteit instellen.
Omdat deze wordt uitgevoerd op een bestaand rekenproces, is de VM-grootte vast en kan deze niet worden gewijzigd aan de sessiezijde.
De identiteit die voor deze sessie wordt gebruikt, wordt ook gedefinieerd in het rekenproces. Deze maakt standaard gebruik van de gebruikersidentiteit. Meer informatie over het toewijzen van identiteit aan rekenproces
Voor de niet-actieve afsluittijd wordt deze gebruikt om de levenscyclus van de rekensessie te definiëren, als de sessie niet actief is voor de tijd die u hebt ingesteld, wordt deze automatisch verwijderd. En van u hebt niet-actieve afsluiting ingeschakeld voor het rekenproces, waarna het van kracht wordt vanaf het rekenniveau.
Meer informatie over het maken en beheren van een rekenproces
- Selecteer het rekentype. U kunt kiezen tussen een serverloze reken- en rekeninstantie.



Een rekensessie gebruiken om een stroomuitvoering te verzenden in CLI/SDK
Naast studio kunt u ook de rekensessie in CLI/SDK opgeven wanneer u een stroomuitvoering verzendt.
U kunt ook het exemplaartype of de naam van het rekenproces opgeven onder het resourceonderdeel. Als u het exemplaartype of de naam van het rekenproces niet opgeeft, kiest Azure Machine Learning een exemplaartype (VM-grootte) op basis van factoren zoals quotum, kosten, prestaties en schijfgrootte. Meer informatie over serverloze berekeningen.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
# specify identity used by serverless compute.
# default value
# identity:
# type: user_identity
# use workspace first UAI
# identity:
# type: managed
# use specified client_id's UAI
# identity:
# type: managed
# client_id: xxx
column_mapping:
url: ${data.url}
# define cloud resource
resources:
instance_type: <instance_type> # serverless compute type
# compute: <compute_instance_name> # use compute instance as compute type
Verzend deze uitvoering via CLI:
pfazure run create --file run.yml
Notitie
Het afsluiten van de inactiviteit is één uur als u CLI/SDK gebruikt om een stroomuitvoering te verzenden. U kunt naar de pagina Compute gaan om rekenkracht vrij te geven.
Verwijzingsbestanden buiten de stroommap
Soms wilt u mogelijk verwijzen naar een requirements.txt bestand dat zich buiten de stroommap bevindt. U hebt bijvoorbeeld een complex project met meerdere stromen en ze delen hetzelfde requirements.txt bestand. Hiervoor kunt u dit veld additional_includes toevoegen aan de flow.dag.yaml. De waarde van dit veld is een lijst met het relatieve bestands-/mappad naar de stroommap. Als requirements.txt zich bijvoorbeeld in de bovenliggende map van de stroommap bevindt, kunt u toevoegen ../requirements.txt aan het additional_includes veld.
inputs:
question:
type: string
outputs:
output:
type: string
reference: ${answer_the_question_with_context.output}
environment:
python_requirements_txt: requirements.txt
additional_includes:
- ../requirements.txt
...
Het requirements.txt bestand wordt gekopieerd naar de stroommap en wordt gebruikt om de rekensessie te starten.
Een rekensessie bijwerken op de pagina studiostroom
Op een stroompagina kunt u de volgende opties gebruiken om een rekensessie te beheren:
- Wijzig de instellingen voor rekensessies, u wijzigt de rekeninstellingen, zoals DE VM-grootte en de door de gebruiker toegewezen beheerde identiteit voor serverloze berekening, als u een rekenproces gebruikt, kunt u wijzigen in het gebruik van een ander exemplaar. U kunt ook wijzigen
- kan ook de door de gebruiker toegewezen beheerde identiteit voor serverloze berekeningen wijzigen. Als u de VM-grootte wijzigt, wordt de rekensessie opnieuw ingesteld met de nieuwe VM-grootte. Als u
- Installeer pakketten vanuit requirements.txt Openen
requirements.txtin de gebruikersinterface van de promptstroom. U kunt er pakketten aan toevoegen. - Geïnstalleerde pakketten weergeven toont de pakketten die zijn geïnstalleerd in de rekensessie. Het bevat de pakketten die zijn geïnstalleerd op basisinstallatiekopieën en pakketten die zijn opgegeven in het
requirements.txtbestand in de stroommap. - Als u de rekensessie opnieuw instelt, wordt de huidige rekensessie verwijderd en wordt er een nieuwe gemaakt met dezelfde omgeving. Als er een probleem met een pakketconflict optreedt, kunt u deze optie proberen.
- Als u de rekensessie stopt, wordt de huidige rekensessie verwijderd. Als er geen actieve rekensessie op de onderliggende berekening is, wordt de serverloze rekenresource ook verwijderd.

U kunt ook de omgeving aanpassen die u gebruikt om deze stroom uit te voeren door pakketten toe te voegen aan het requirements.txt bestand in de stroommap. Nadat u meer pakketten in dit bestand hebt toegevoegd, kunt u een van de volgende opties kiezen:
- Sla triggers op en installeer deze
pip install -r requirements.txtin de stroommap. Het proces kan enkele minuten duren, afhankelijk van de pakketten die u installeert. - Sla het
requirements.txtbestand alleen op. U kunt de pakketten later zelf installeren.

Notitie
U kunt de locatie en zelfs de bestandsnaam wijzigen, requirements.txtmaar zorg ervoor dat u deze ook wijzigt in het flow.dag.yaml bestand in de stroommap.
Maak de versie van promptflow en promptflow-tools in requirements.txtniet vast, omdat deze al zijn opgenomen in de sessiebasisinstallatiekopieën.
requirements.txt biedt geen ondersteuning voor lokale wielbestanden. Bouw deze in uw installatiekopieën en werk de aangepaste basisinstallatiekopieën bij in flow.dag.yaml. Meer informatie over het bouwen van een aangepaste basisinstallatiekopieën.
Pakketten toevoegen in een privéfeed in Azure DevOps
Als u een privéfeed in Azure DevOps wilt gebruiken, voert u de volgende stappen uit:
Wijs beheerde identiteit toe aan werkruimte of rekenproces.
Gebruik serverloze compute als rekensessie. U moet door de gebruiker toegewezen beheerde identiteit toewijzen aan de werkruimte.
Maak een door de gebruiker toegewezen beheerde identiteit en voeg deze identiteit toe in de Azure DevOps-organisatie. Zie Service-principals en beheerde identiteiten gebruiken voor meer informatie.
Notitie
Als de knop Gebruikers toevoegen niet zichtbaar is, beschikt u waarschijnlijk niet over de benodigde machtigingen om deze actie uit te voeren.
Door de gebruiker toegewezen identiteiten aan een werkruimte toevoegen of bijwerken.
Notitie
Zorg ervoor dat de door de gebruiker toegewezen beheerde identiteit de gekoppelde sleutelkluis van de werkruimte bevat
Microsoft.KeyVault/vaults/read.
Gebruik rekenproces als rekensessie. U moet een door de gebruiker toegewezen beheerde identiteit toewijzen aan een rekenproces.
Voeg deze toe
{private}aan de URL van uw privéfeed. Als u bijvoorbeeld wilt installerentest_packagevanuittest_feedAzure DevOps, voegt-i https://{private}@{test_feed_url_in_azure_devops}u het volgende toerequirements.txt:-i https://{private}@{test_feed_url_in_azure_devops} test_packageGeef het gebruik van door de gebruiker toegewezen beheerde identiteit op in de configuratie van de rekensessie.
Als u serverloze berekening gebruikt, geeft u de door de gebruiker toegewezen beheerde identiteit op in Start met geavanceerde instellingen als de rekensessie niet wordt uitgevoerd of gebruikt u de knop Instellingen voor rekensessies wijzigen als de rekensessie wordt uitgevoerd.
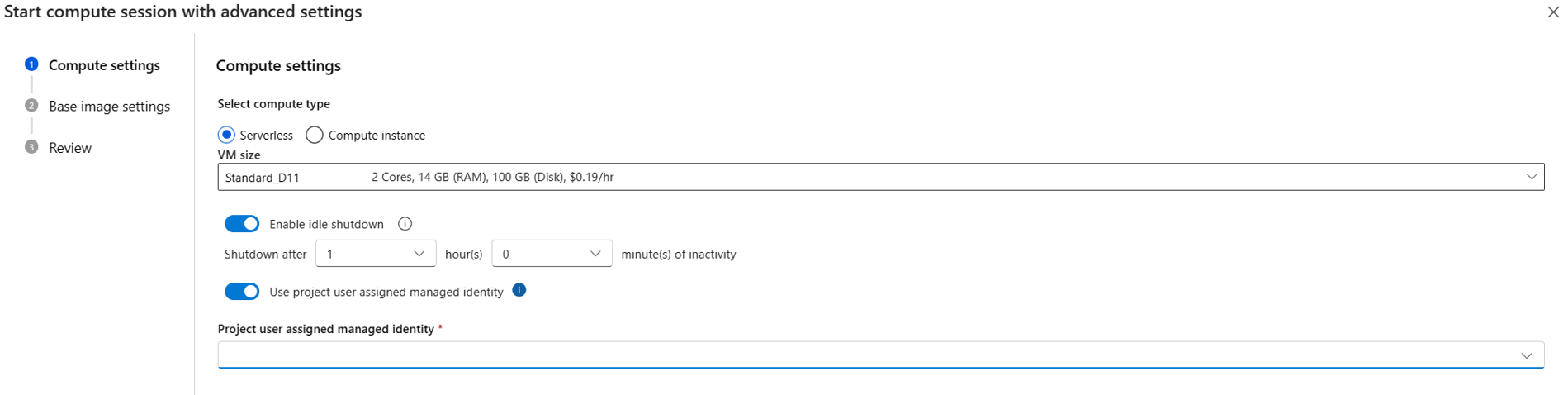
Als u een rekenproces gebruikt, wordt de door de gebruiker toegewezen beheerde identiteit gebruikt die u aan het rekenproces hebt toegewezen.

Notitie
Deze benadering is voornamelijk gericht op snelle tests in de ontwikkelingsfase van de stroom, als u deze stroom ook wilt implementeren als eindpunt, moet u deze privéfeed in uw installatiekopieën bouwen en de basisinstallatiekopieën bijwerken in flow.dag.yaml. Meer informatie over het bouwen van een aangepaste basisinstallatiekopieën
De basisinstallatiekopieën voor de rekensessie wijzigen
Standaard gebruiken we de meest recente basisinstallatiekopieën voor promptstromen. Als u een andere basisinstallatiekopieën wilt gebruiken, kunt u een aangepaste installatiekopieën maken.
- In Studio kunt u de basisinstallatiekopieën wijzigen in de basisinstallatiekopieën onder instellingen voor rekensessies.

U kunt ook de nieuwe basisinstallatiekopieën in
environmenthetflow.dag.yamlbestand in de stroommap opgeven.
environment: image: <your-custom-image> python_requirements_txt: requirements.txt

Als u de nieuwe basisinstallatiekopieën wilt gebruiken, moet u de rekensessie opnieuw instellen. Dit proces duurt enkele minuten wanneer het de nieuwe basisinstallatiekopie ophaalt en pakketten opnieuw installeert.
Serverloze instantie beheren die wordt gebruikt door de rekensessie
Wanneer u serverloze berekeningen gebruikt als een rekensessie, kunt u het serverloze exemplaar beheren. Bekijk het serverloze exemplaar op het tabblad Lijst met rekensessies op de pagina Compute.

U kunt ook toegang krijgen tot stromen en uitvoeringen die worden uitgevoerd op de berekening onder het tabblad Actieve stromen en uitvoeringen . Wanneer het exemplaar wordt verwijderd, is dit van invloed op de stroom en wordt erop uitgevoerd.

Relatie tussen rekensessie, rekenresource, stroom en gebruiker
- Eén gebruiker kan meerdere rekenresources (serverloos of rekenproces) hebben. Vanwege verschillende behoeften kan één gebruiker meerdere rekenresources hebben. Eén gebruiker kan bijvoorbeeld meerdere rekenresources hebben met een andere VM-grootte of een andere door de gebruiker toegewezen beheerde identiteit.
- Eén rekenresource kan slechts door één gebruiker worden gebruikt. Een rekenresource wordt gebruikt als privéontwikkelingsvak van één gebruiker. Meerdere gebruikers kunnen niet dezelfde rekenresources delen.
- Eén rekenresource kan meerdere rekensessies hosten. Een rekensessie is een container die wordt uitgevoerd op een onderliggende rekenresource. Het ontwerpen van promptstromen heeft bijvoorbeeld niet te veel rekenresources nodig, dus één rekenresource kan meerdere rekensessies van dezelfde gebruiker hosten.
- Eén rekensessie behoort slechts tot één rekenresource tegelijk. Maar u kunt een rekensessie verwijderen of stoppen en deze opnieuw toewijzen aan een andere rekenresource.
- Eén stroom kan slechts één rekensessie hebben. Elke stroom is zelfstandig en definieert de basisinstallatiekopieën en vereiste Python-pakketten in de stroommap voor de rekensessie.
Runtime overschakelen naar rekensessie
Rekensessies hebben de volgende voordelen ten opzichte van runtimes voor rekenprocessen:
- De levenscyclus van sessie en onderliggende compute automatisch beheren. U hoeft ze niet handmatig te maken en te beheren.
- U kunt pakketten eenvoudig aanpassen door pakketten toe te voegen aan het
requirements.txtbestand in de stroommap in plaats van een aangepaste omgeving te maken.
Schakel een rekenprocesruntime over naar een rekensessie met behulp van de volgende stappen:
- Bereid het
requirements.txtbestand voor in de stroommap. Zorg ervoor dat u de versie vanpromptflowenpromptflow-toolsinrequirements.txtniet vastmaken, omdat deze al zijn opgenomen in de basisinstallatiekopieën. De rekensessie installeert de pakketten inrequirements.txthet bestand wanneer deze wordt gestart. - Als u een aangepaste omgeving maakt om een runtime voor een rekenproces te maken, kunt u de installatiekopieën ophalen op de pagina met omgevingsgegevens en deze opgeven in het
flow.dag.yamlbestand in de stroommap. Zie De basisinstallatiekopieën voor de rekensessie wijzigen voor meer informatie. Zorg ervoor dat u of de gerelateerde door de gebruiker toegewezen beheerde identiteit in de werkruimte gemachtigd isacr pullvoor de installatiekopieën.

- Voor de rekenresource kunt u het bestaande rekenproces blijven gebruiken als u de levenscyclus handmatig wilt beheren of u kunt serverloze berekeningen proberen waarvan de levenscyclus wordt beheerd door het systeem.