Invoer en uitvoer voor onderdelen en pijplijnen beheren
Azure Machine Learning-pijplijnen ondersteunen invoer en uitvoer op zowel het onderdeel- als de pijplijnniveaus. In dit artikel worden de invoer en uitvoer van pijplijnen en onderdelen beschreven en hoe u deze beheert.
Op onderdeelniveau definiëren de invoer en uitvoer de onderdeelinterface. U kunt de uitvoer van het ene onderdeel gebruiken als invoer voor een ander onderdeel in dezelfde bovenliggende pijplijn, zodat gegevens of modellen tussen onderdelen kunnen worden doorgegeven. Deze interconnectiviteit vertegenwoordigt de gegevensstroom in de pijplijn.
Op pijplijnniveau kunt u invoer en uitvoer gebruiken om pijplijntaken te verzenden met verschillende gegevensinvoer of parameters, zoals learning_rate. Invoer en uitvoer zijn vooral handig wanneer u een pijplijn aanroept via een REST-eindpunt. U kunt verschillende waarden toewijzen aan de pijplijninvoer of toegang krijgen tot de uitvoer van verschillende pijplijntaken. Zie Taken en invoergegevens maken voor batcheindpunten voor meer informatie.
Invoer- en uitvoertypen
De volgende typen worden ondersteund als invoer en uitvoer van onderdelen of pijplijnen:
Gegevenstypen voor meer informatie over IntDate. Zie Gegevenstypen voor meer informatie.
uri_fileuri_foldermltable
Modeltypen.
mlflow_modelcustom_model
De volgende primitieve typen worden ook alleen ondersteund voor invoer:
- Primitieve typen
stringnumberintegerboolean
Uitvoer van primitieve typen wordt niet ondersteund.
Voorbeeldinvoer en uitvoer
Deze voorbeelden zijn afkomstig van de NYC Taxi Data Regression-pijplijn in de GitHub-opslagplaats met Azure Machine Learning-voorbeelden .
- Het trainonderdeel heeft een invoer met de
numbernaamtest_split_ratio. - Het voorbereidingsonderdeel heeft een
uri_foldertype-uitvoer. De broncode van het onderdeel leest de CSV-bestanden uit de invoermap, verwerkt de bestanden en schrijft de verwerkte CSV-bestanden naar de uitvoermap. - Het trainonderdeel heeft een
mlflow_modeltype-uitvoer. De broncode van het onderdeel slaat het getrainde model op met behulp van demlflow.sklearn.save_modelmethode.
Uitvoerserialisatie
Als u gegevens of modeluitvoer gebruikt, worden de uitvoer geserialiseerd en opgeslagen als bestanden op een opslaglocatie. Latere stappen hebben toegang tot de bestanden tijdens het uitvoeren van de taak door deze opslaglocatie te koppelen of door de bestanden te downloaden of te uploaden naar het rekenbestandssysteem.
De broncode van het onderdeel moet het uitvoerobject, dat meestal in het geheugen wordt opgeslagen, serialiseren in bestanden. U kunt bijvoorbeeld een pandas-dataframe serialiseren in een CSV-bestand. Azure Machine Learning definieert geen gestandaardiseerde methoden voor objectserialisatie. U hebt de flexibiliteit om uw voorkeursmethoden te kiezen om objecten in bestanden te serialiseren. In het downstreamonderdeel kunt u kiezen hoe u deze bestanden deserialiseert en leest.
Invoer- en uitvoerpaden van gegevenstype
Voor invoer en uitvoer van gegevensassets moet u een padparameter opgeven die verwijst naar de gegevenslocatie. In de volgende tabel ziet u de ondersteunde gegevenslocaties voor azure Machine Learning-pijplijninvoer en -uitvoer, met path parametervoorbeelden.
| Locatie | Invoer | Uitvoer | Opmerking |
|---|---|---|---|
| Een pad op uw lokale computer | ✓ | ./home/<username>/data/my_data |
|
| Een pad op een openbare HTTP/s-server | ✓ | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
|
| Een pad in Azure Storage | * | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>or abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
|
| Een pad in een Azure Machine Learning-gegevensarchief | ✓ | ✓ | azureml://datastores/<data_store_name>/paths/<path> |
| Een pad naar een gegevensasset | ✓ | ✓ | azureml:my_data:<version> |
* Het rechtstreeks gebruiken van Azure Storage wordt niet aanbevolen voor invoer, omdat er mogelijk extra identiteitsconfiguratie nodig is om de gegevens te lezen. Het is beter om Azure Machine Learning-gegevensopslagpaden te gebruiken, die worden ondersteund in verschillende typen pijplijntaken.
Invoer- en uitvoermodi voor gegevenstypen
Voor invoer en uitvoer van gegevenstypen kunt u kiezen uit verschillende download-, upload- en koppelmodi om te bepalen hoe het rekendoel toegang heeft tot gegevens. In de volgende tabel ziet u de ondersteunde modi voor verschillende typen invoer en uitvoer.
| Type | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|
uri_folder invoer |
✓ | ✓ | ✓ | ||||
uri_file invoer |
✓ | ✓ | ✓ | ||||
mltable invoer |
✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder uitvoer |
✓ | ✓ | |||||
uri_file uitvoer |
✓ | ✓ | |||||
mltable uitvoer |
✓ | ✓ | ✓ |
De ro_mount of rw_mount modi worden aanbevolen voor de meeste gevallen. Zie Modi voor meer informatie.
Invoer en uitvoer in pijplijngrafieken
Op de pagina pijplijntaak in Azure Machine Learning-studio worden onderdeelinvoer en -uitvoer weergegeven als kleine cirkels met de naam invoer-/uitvoerpoorten. Deze poorten vertegenwoordigen de gegevensstroom in de pijplijn. Uitvoer op pijplijnniveau wordt weergegeven in paarse vakken voor eenvoudige identificatie.
In de volgende schermopname van de pijplijngrafiek nyc taxigegevens worden veel onderdelen en pijplijninvoer en -uitvoer weergegeven.

Wanneer u de muisaanwijzer boven een invoer-/uitvoerpoort houdt, wordt het type weergegeven.
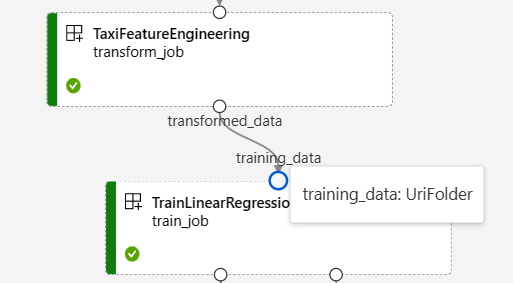
In de pijplijngrafiek worden geen primitieve invoertypen weergegeven. Deze invoer wordt weergegeven op het tabblad Instellingen van het overzichtsvenster van de pijplijntaak voor invoer op pijplijnniveau of het onderdeelpaneel voor invoer op onderdeelniveau. Als u het onderdeelpaneel wilt openen, dubbelklikt u op het onderdeel in de grafiek.

Wanneer u een pijplijn bewerkt in studio Designer, bevinden pijplijninvoer en -uitvoer zich in het deelvenster Pijplijninterface en bevinden de invoer en uitvoer van onderdelen zich in het onderdeelpaneel.
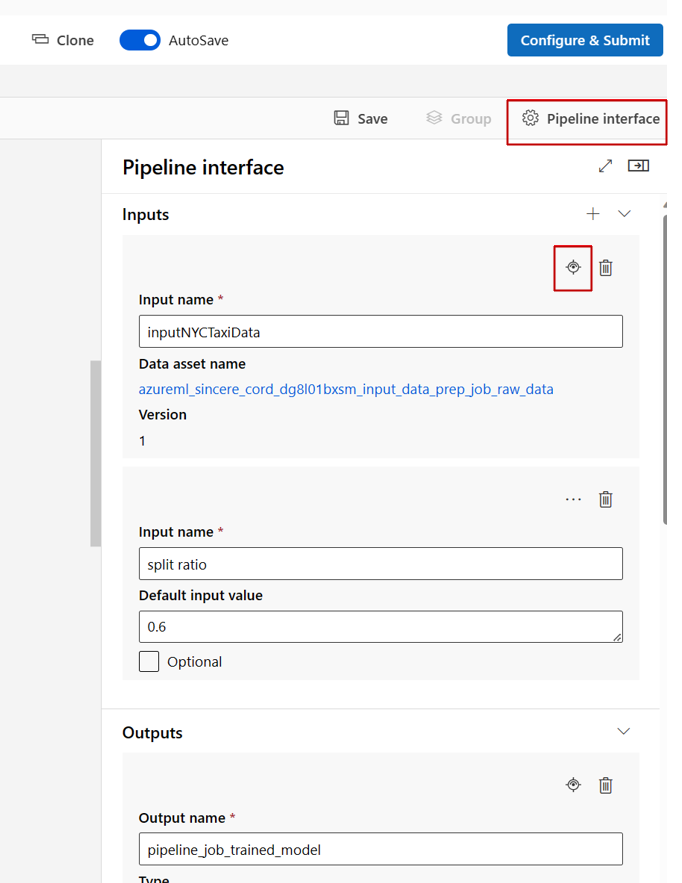
Niveau van onderdeelinvoer/uitvoer verhogen naar pijplijnniveau
Door de invoer/uitvoer van een onderdeel te promoveren naar het pijplijnniveau, kunt u de invoer/uitvoer van het onderdeel overschrijven wanneer u een pijplijntaak verzendt. Deze mogelijkheid is vooral handig voor het activeren van pijplijnen met behulp van REST-eindpunten.
In de volgende voorbeelden ziet u hoe u invoer/uitvoer op onderdeelniveau promoveert naar invoer/uitvoer op pijplijnniveau.
De volgende pijplijn bevordert drie invoer en drie uitvoerwaarden naar het pijplijnniveau. Is bijvoorbeeld pipeline_job_training_max_epocs invoer op pijplijnniveau, omdat deze wordt gedeclareerd onder de inputs sectie op het hoofdniveau.
Onder train_job in de jobs sectie wordt naar de benoemde max_epocs invoer verwezen als ${{parent.inputs.pipeline_job_training_max_epocs}}, wat betekent dat de invoer van het train_jobmax_epocs pijplijnniveau verwijst naar de invoer op pijplijnniveaupipeline_job_training_max_epocs. Pijplijnuitvoer wordt gepromoveerd met hetzelfde schema.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 1b_e2e_registered_components
description: E2E dummy train-score-eval pipeline with registered components
inputs:
pipeline_job_training_max_epocs: 20
pipeline_job_training_learning_rate: 1.8
pipeline_job_learning_rate_schedule: 'time-based'
outputs:
pipeline_job_trained_model:
mode: upload
pipeline_job_scored_data:
mode: upload
pipeline_job_evaluation_report:
mode: upload
settings:
default_compute: azureml:cpu-cluster
jobs:
train_job:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
type: vs_code
my_jupyter_lab:
type: jupyter_lab
my_tensorboard:
type: tensor_board
log_dir: "outputs/tblogs"
# my_ssh:
# type: tensor_board
# ssh_public_keys: <paste the entire pub key content>
# nodes: all # Use the `nodes` property to pick which node you want to enable interactive services on. If `nodes` are not selected, by default, interactive applications are only enabled on the head node.
score_job:
type: command
component: azureml:my_score@latest
inputs:
model_input: ${{parent.jobs.train_job.outputs.model_output}}
test_data:
type: uri_folder
path: ./data
outputs:
score_output: ${{parent.outputs.pipeline_job_scored_data}}
evaluate_job:
type: command
component: azureml:my_eval@latest
inputs:
scoring_result: ${{parent.jobs.score_job.outputs.score_output}}
outputs:
eval_output: ${{parent.outputs.pipeline_job_evaluation_report}}
U vindt het volledige voorbeeld in de pijplijn train-score-eval met geregistreerde onderdelen in de opslagplaats met Voorbeelden van Azure Machine Learning .
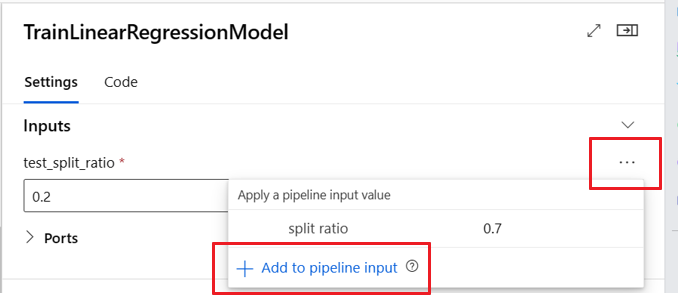
Optionele invoer definiëren
Standaard zijn alle invoer vereist en moeten ze een standaardwaarde hebben of elke keer dat u een pijplijntaak verzendt, een waarde toewijzen. U kunt echter een optionele invoer definiëren.
Notitie
Optionele uitvoer wordt niet ondersteund.
Het instellen van optionele invoer kan nuttig zijn in twee scenario's:
Als u een optionele invoer voor gegevens/modeltypen definieert en er geen waarde aan toewijst wanneer u de pijplijntaak verzendt, ontbreekt het pijplijnonderdeel aan die gegevensafhankelijkheid. Als de invoerpoort van het onderdeel niet is gekoppeld aan een onderdeel- of gegevens-/modelknooppunt, roept de pijplijn het onderdeel rechtstreeks aan in plaats van te wachten op een voorgaande afhankelijkheid.
Als u voor de pijplijn instelt
continue_on_step_failure = True, maarnode2de vereiste invoer vannode1de pijplijn gebruikt,node2wordt deze niet uitgevoerd alsnode1dit mislukt. Alsnode1invoer optioneel is, wordt deze uitgevoerd,node2zelfs alsnode1dit mislukt. In de volgende grafiek ziet u dit scenario.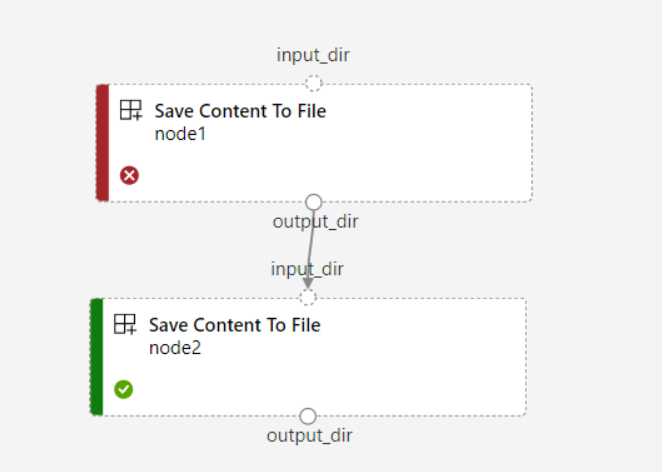
In het volgende codevoorbeeld ziet u hoe u optionele invoer definieert. Wanneer de invoer is ingesteld als optional = true, moet u de $[[]] opdrachtregelinvoer omhelzen, zoals in de gemarkeerde regels van het voorbeeld.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_data_component_cli
display_name: train_data
description: A example train component
tags:
author: azureml-sdk-team
type: command
inputs:
training_data:
type: uri_folder
max_epocs:
type: integer
optional: true
learning_rate:
type: number
default: 0.01
optional: true
learning_rate_schedule:
type: string
default: time-based
optional: true
outputs:
model_output:
type: uri_folder
code: ./train_src
environment: azureml://registries/azureml/environments/sklearn-1.5/labels/latest
command: >-
python train.py
--training_data ${{inputs.training_data}}
$[[--max_epocs ${{inputs.max_epocs}}]]
$[[--learning_rate ${{inputs.learning_rate}}]]
$[[--learning_rate_schedule ${{inputs.learning_rate_schedule}}]]
--model_output ${{outputs.model_output}}

Uitvoerpaden aanpassen
Standaard wordt onderdeeluitvoer opgeslagen in de {default_datastore} uitvoer die u voor de pijplijn hebt ingesteld. azureml://datastores/${{default_datastore}}/paths/${{name}}/${{output_name}} Als dit niet is ingesteld, is de standaardwaarde de blobopslag van de werkruimte.
De taak {name} wordt opgelost tijdens de uitvoering van de taak en {output_name} is de naam die u hebt gedefinieerd in de YAML van het onderdeel. U kunt aanpassen waar de uitvoer moet worden opgeslagen door een uitvoerpad te definiëren.
Het pipeline.yml-bestand bij de pijplijn train-score-eval met geregistreerde onderdelen definieert een pijplijn met drie uitvoer op pijplijnniveau. U kunt de volgende opdracht gebruiken om aangepaste uitvoerpaden in te stellen voor de pipeline_job_trained_model uitvoer.
# define the custom output path using datastore uri
# add relative path to your blob container after "azureml://datastores/<datastore_name>/paths"
output_path="azureml://datastores/{datastore_name}/paths/{relative_path_of_container}"
# create job and define path using --outputs.<outputname>
az ml job create -f ./pipeline.yml --set outputs.pipeline_job_trained_model.path=$output_path

Uitvoer downloaden
U kunt uitvoer downloaden op pijplijn- of onderdeelniveau.
Uitvoer op pijplijnniveau downloaden
U kunt alle uitvoer van een taak downloaden of een specifieke uitvoer downloaden.
# Download all the outputs of the job
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
# Download a specific output
az ml job download --output-name <OUTPUT_PORT_NAME> -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>

Uitvoer van onderdelen downloaden
Als u de uitvoer van een onderliggend onderdeel wilt downloaden, moet u eerst alle onderliggende taken van een pijplijntaak weergeven en vervolgens vergelijkbare code gebruiken om de uitvoer te downloaden.
# List all child jobs in the job and print job details in table format
az ml job list --parent-job-name <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID> -o table
# Select the desired child job name to download output
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
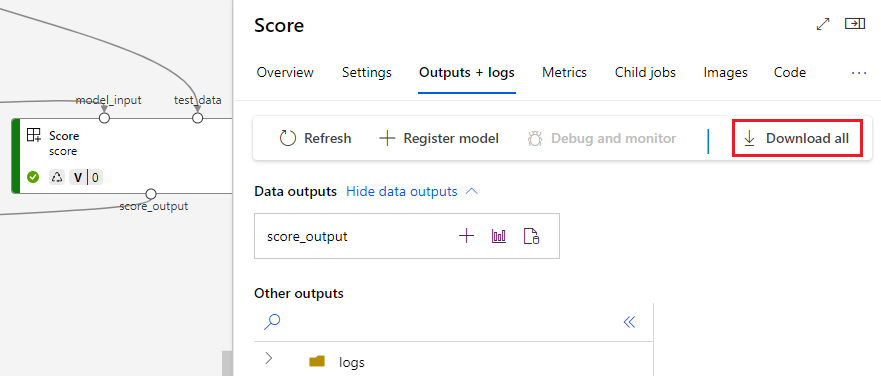
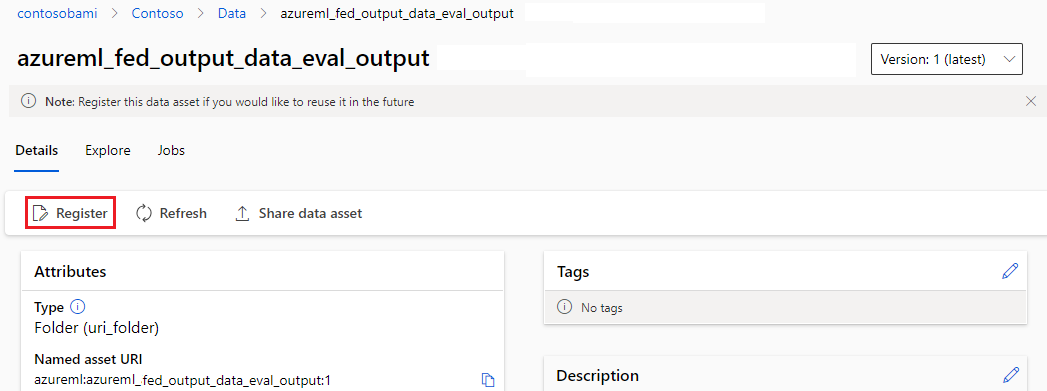
Uitvoer registreren als een benoemde asset
U kunt de uitvoer van een onderdeel of pijplijn registreren als een benoemde asset door een name en version aan de uitvoer toe te wijzen. De geregistreerde asset kan worden vermeld in uw werkruimte via de gebruikersinterface van studio, CLI of SDK en kan worden verwezen in toekomstige werkruimtetaken.
Uitvoer op pijplijnniveau registreren
display_name: register_pipeline_output
type: pipeline
jobs:
node:
type: command
inputs:
component_in_path:
type: uri_file
path: https://dprepdata.blob.core.windows.net/demo/Titanic.csv
component: ../components/helloworld_component.yml
outputs:
component_out_path: ${{parent.outputs.component_out_path}}
outputs:
component_out_path:
type: mltable
name: pipeline_output # Define name and version to register pipeline output
version: '1'
settings:
default_compute: azureml:cpu-cluster
Uitvoer van onderdeel registreren
display_name: register_node_output
type: pipeline
jobs:
node:
type: command
component: ../components/helloworld_component.yml
inputs:
component_in_path:
type: uri_file
path: 'https://dprepdata.blob.core.windows.net/demo/Titanic.csv'
outputs:
component_out_path:
type: uri_folder
name: 'node_output' # Define name and version to register a child job's output
version: '1'
settings:
default_compute: azureml:cpu-cluster