Inhoud parseren of segmenteren voor werkstromen in Azure Logic Apps (preview)
Van toepassing op: Azure Logic Apps (Verbruik + Standard)
Belangrijk
Deze mogelijkheid is in preview en is onderworpen aan de aanvullende gebruiksvoorwaarden voor Microsoft Azure Previews.
Soms moet u inhoud converteren naar tokens, zoals woorden of segmenten tekens, of een groot document in kleinere stukken verdelen voordat u deze inhoud met bepaalde acties kunt gebruiken. De Azure AI Search- of Azure OpenAI-acties verwachten bijvoorbeeld tokenized invoer en kunnen slechts een beperkt aantal tokens verwerken.
Voor deze scenario's gebruikt u de acties voor gegevensbewerkingen met de naam Een document en segmenttekst parseren in uw werkstroom voor logische apps. Met deze acties worden respectievelijk inhoud, zoals een PDF-document, CSV-bestand, Excel-bestand, enzovoort, omgezet in tokenized tekenreeksuitvoer en splitst u de tekenreeks vervolgens op basis van het aantal tokens. U kunt deze uitvoer vervolgens raadplegen en gebruiken met volgende acties in uw werkstroom.
Tip
Voor meer informatie kunt u Azure Copilot deze vragen stellen:
- Wat is een token in AI?
- Wat is tokenized invoer?
- Wat is tokenized tekenreeksuitvoer?
- Wat is parseren in AI?
- Wat is segmenteren in AI?
Selecteer Copilot op de werkbalk van Azure Portal om Azure Copilot te vinden.
Deze handleiding laat zien hoe u deze bewerkingen toevoegt en instelt in uw werkstroom.
Bekende problemen en beperkingen
De acties voor het parseren van een document en segmenttekst bieden momenteel geen ondersteuning voor hostbestanden, zoals mainframe- en midrange binaire bestanden zoals VSAM-bestanden (Virtual Storage Access Method). Als u echter met Standaardwerkstromen werkt, kunt u in plaats daarvan de ingebouwde actie IBM Host File met de naam Hostbestandsinhoud parseren gebruiken.
Vereisten
Een Azure-account en -abonnement. Als u nog geen abonnement op Azure hebt, registreer u dan nu voor een gratis Azure-account.
Een werkstroom voor een logische of standaard-app met een bestaande trigger, omdat de bewerkingen voor het parseren van een document en segmenttekst alleen beschikbaar zijn als acties. Zorg ervoor dat de actie die de inhoud ophaalt die u wilt parseren of segment voorafgaat aan deze gegevensbewerkingen.
Een document parseren
Met de actie Een document parseren wordt inhoud, zoals een PDF-document, CSV-bestand, Excel-bestand, enzovoort, geconverteerd naar een tokenized tekenreeks. Stel dat uw werkstroom begint met de aanvraagtrigger met de naam Wanneer een HTTP-aanvraag wordt ontvangen. Deze trigger wacht totdat een HTTP-aanvraag wordt ontvangen die is verzonden vanuit een ander onderdeel, zoals een Azure-functie, een andere werkstroom voor logische apps, enzovoort. De HTTP-aanvraag bevat de URL voor een nieuw geüpload document dat beschikbaar is voor de werkstroom om op te halen en te parseren. Een HTTP-actie volgt onmiddellijk de trigger en verzendt een HTTP-aanvraag naar de URL van het document en retourneert met de inhoud van het document vanaf de opslaglocatie.
Als u andere inhoudsbronnen gebruikt, zoals Azure Blob Storage, SharePoint, OneDrive, Bestandssysteem, FTP, enzovoort, kunt u controleren of triggers beschikbaar zijn voor deze bronnen. U kunt ook controleren of acties beschikbaar zijn om de inhoud voor deze bronnen op te halen. Zie Ingebouwde bewerkingen en beheerde connectors voor meer informatie.
Open in Azure Portal de resource en werkstroom van uw logische app in de ontwerpfunctie.
Volg onder de bestaande trigger en acties deze algemene stappen om de actie Gegevensbewerkingen met de naam Een document parseren aan uw werkstroom toe te voegen.
Selecteer in de ontwerpfunctie de actie Een document parseren.
Nadat het deelvenster actiegegevens is geopend, geeft u op het tabblad Parameters in de eigenschap Documentinhoud de inhoud op die u wilt parseren door de volgende stappen uit te voeren:
Selecteer in het vak Documentinhoud .
De opties voor de lijst met dynamische inhoud (bliksempictogram) en de expressie-editor (functiepictogram) worden weergegeven.
Als u de uitvoer van een voorgaande actie wilt kiezen, selecteert u de lijst met dynamische inhoud.
Als u een expressie wilt maken waarmee de uitvoer van een voorgaande actie wordt bewerkt, selecteert u de expressie-editor.
Dit voorbeeld wordt voortgezet door het bliksempictogram voor de lijst met dynamische inhoud te selecteren.
Nadat de lijst met dynamische inhoud is geopend, selecteert u de gewenste uitvoer uit een vorige bewerking.
In dit voorbeeld verwijst de documentactie Parseren naar de hoofdtekstuitvoer van de HTTP-actie.
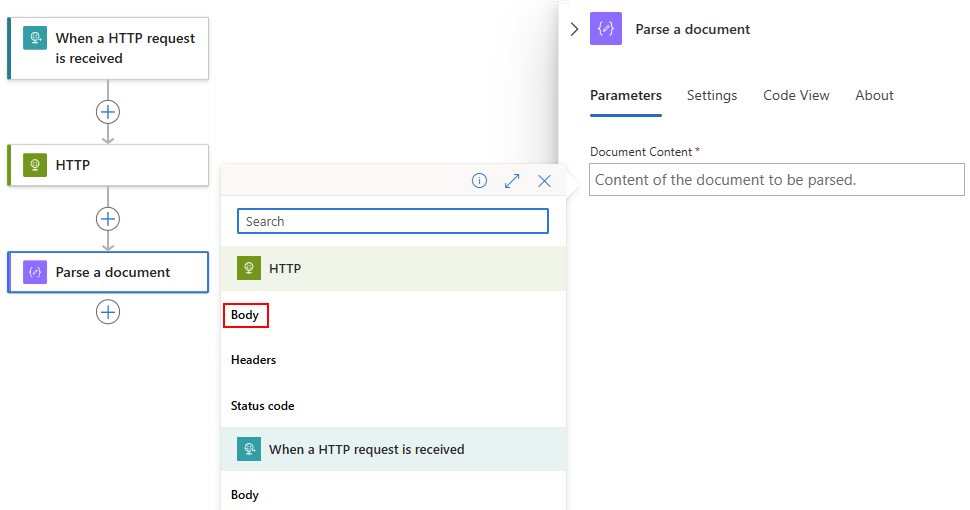
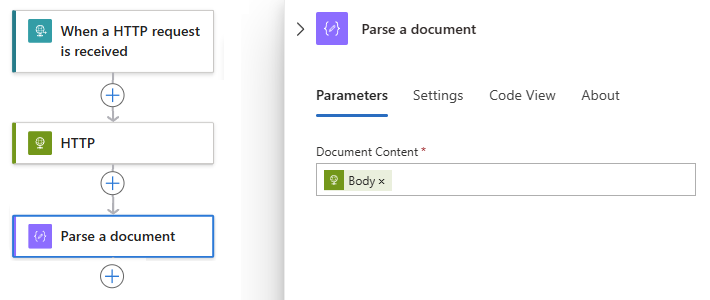
De uitvoer van de hoofdtekst wordt nu weergegeven in het vak Documentinhoud :
Voeg onder de actie Een document parseren de acties toe die u wilt gebruiken met de uitvoer van de tokenized tekenreeks, bijvoorbeeld segmenttekst, die in deze handleiding later wordt beschreven.
Een document parseren - Naslaginformatie
Parameters
| Naam | Weergegeven als | Gegevenstype | Beschrijving | Grenswaarde |
|---|---|---|---|---|
| Documentinhoud | < inhoud naar parseren> | Alle | De inhoud die moet worden geparseerd. | Geen |
Uitvoerwaarden
| Naam | Gegevenstype | Beschrijving |
|---|---|---|
| Geparseerde resultaattekst | Tekenreeksmatrix | Een matrix met tekenreeksen. |
| Geparseerd resultaat | Object | Een object dat de volledige geparseerde tekst bevat. |
Segmenttekst
Met de tekstactie Segment wordt inhoud gesplitst in kleinere stukken voor volgende acties, zodat u deze gemakkelijker kunt gebruiken in de huidige werkstroom. De volgende stappen zijn gebaseerd op het voorbeeld uit de sectie Een document parseren en splitst tokentekenreeksuitvoer voor gebruik met Azure AI-bewerkingen waarvoor tokenized, kleine inhoudssegmenten worden verwacht.
Notitie
Voorgaande acties die segmenteren gebruiken, hebben geen invloed op de tekstactie Segmenteren, noch heeft de actie Segmenttekst invloed op volgende acties die segmenteren gebruiken.
Open in Azure Portal de resource en werkstroom van uw logische app in de ontwerpfunctie.
Volg onder de actie Een documentparseren deze algemene stappen om de actie Gegevensbewerkingen met de naam Segmenttekst toe te voegen.
Selecteer in de ontwerpfunctie de tekstactie Segmenttekst .
Nadat het deelvenster met actiegegevens is geopend, selecteert u op het tabblad Parameters voor de eigenschap Segmenteringsstrategie tokenSize als de segmenteringsmethode, als deze nog niet is geselecteerd.
Strategie Beschrijving TokenSize Splits de opgegeven inhoud op basis van het aantal tokens. Nadat u de strategie hebt geselecteerd, selecteert u in het tekstvak om de inhoud voor segmentering op te geven.
De opties voor de lijst met dynamische inhoud (bliksempictogram) en de expressie-editor (functiepictogram) worden weergegeven.
Als u de uitvoer van een voorgaande actie wilt kiezen, selecteert u de lijst met dynamische inhoud.
Als u een expressie wilt maken waarmee de uitvoer van een voorgaande actie wordt bewerkt, selecteert u de expressie-editor.
Dit voorbeeld wordt voortgezet door het bliksempictogram voor de lijst met dynamische inhoud te selecteren.
Nadat de lijst met dynamische inhoud is geopend, selecteert u de gewenste uitvoer uit een vorige bewerking.
In dit voorbeeld verwijst de tekstactie Segmenttekst naar de tekstuitvoer van het geparseerde resultaat van de actie Een document parseren.
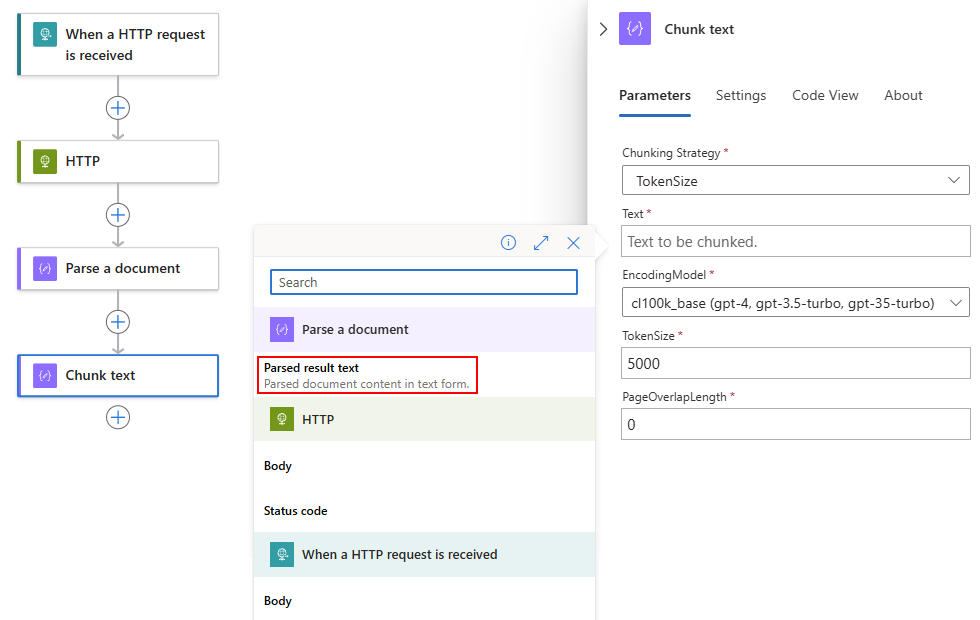
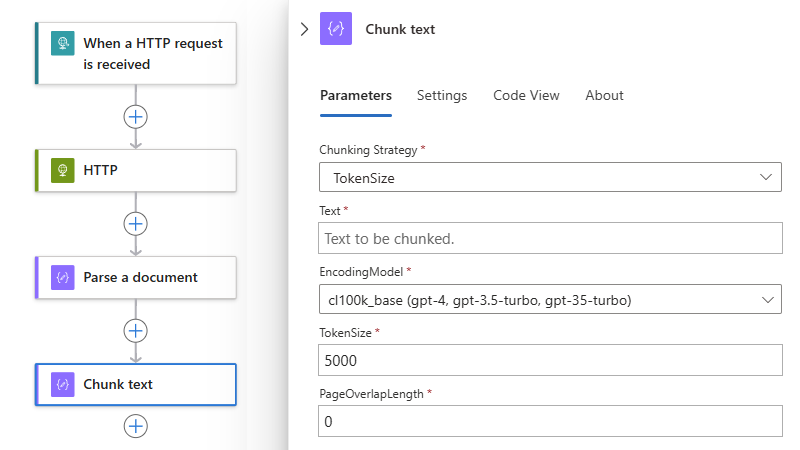
In het tekstvak wordt nu de uitvoer van de actie Geparseerd resultaat weergegeven:
Voltooi de installatie voor de tekstactie Segmenttekst op basis van uw geselecteerde strategie en scenario. Zie Segmenttekst - Naslaginformatie voor meer informatie.
Wanneer u nu andere acties toevoegt die getokeniseerde invoer verwachten en gebruiken, zoals de Azure AI-acties, wordt de invoerinhoud opgemaakt voor eenvoudiger gebruik.
Segmenttekst - Verwijzing
Parameters
| Naam | Weergegeven als | Gegevenstype | Beschrijving | Limieten |
|---|---|---|---|---|
| Segmenteringsstrategie | TokenSize | Opsommingstekenreeks | Splits de inhoud op basis van het aantal tokens. Standaard: TokenSize |
Niet van toepassing |
| Text | < inhoud naar segment> | Alle | De inhoud die u wilt segmenteren. | Raadpleeg de referentiehandleiding voor limieten en configuratie |
| EncodingModel | < coderingsmethode> | Opsommingstekenreeks | Het coderingsmodel dat moet worden gebruikt: - Standaard: cl100k_base (gpt4, gpt-3.5-turbo, gpt-35-turbo) - r50k_base (gpt-3) - p50k_base (gpt-3) - p50k_edit (gpt-3) - cl200k_base (gpt-4o) Zie Het overzicht van OpenAI - Modellen voor meer informatie. |
Niet van toepassing |
| TokenSize | < max-tokens-per-chunk> | Geheel getal | Het maximum aantal tokens per inhoudssegment. Standaard: Geen |
Minimum: 1 Maximum: 8000 |
| PageOverlapLength | < aantal overlappende tekens> | Geheel getal | Het aantal tekens van het einde van het vorige segment dat moet worden opgenomen in het volgende segment. Met deze instelling voorkomt u dat belangrijke informatie verloren gaat wanneer u inhoud splitst in segmenten en continuïteit en context behoudt tussen segmenten. Standaard: 0: er bestaan geen overlappende tekens. |
Minimum: 0 |
Tip
Voor meer informatie kunt u Azure Copilot deze vragen stellen:
- Wat is PageOverlapLength in segmentering?
- Wat is codering in Azure AI?
Selecteer Copilot op de werkbalk van Azure Portal om Azure Copilot te vinden.
Uitvoerwaarden
| Naam | Gegevenstype | Beschrijving |
|---|---|---|
| Gesegmenteerde resultaattekstitems | Tekenreeksmatrix | Een matrix met tekenreeksen. |
| Tekstitem gesegmenteerd resultaat | String | Eén tekenreeks in de matrix. |
| Gesegmenteerd resultaat | Object | Een object dat de volledige gesegmenteerde tekst bevat. |
Voorbeeldwerkstroom
Het volgende voorbeeld bevat andere acties waarmee een volledig werkstroompatroon wordt gemaakt voor het opnemen van gegevens uit elke bron:
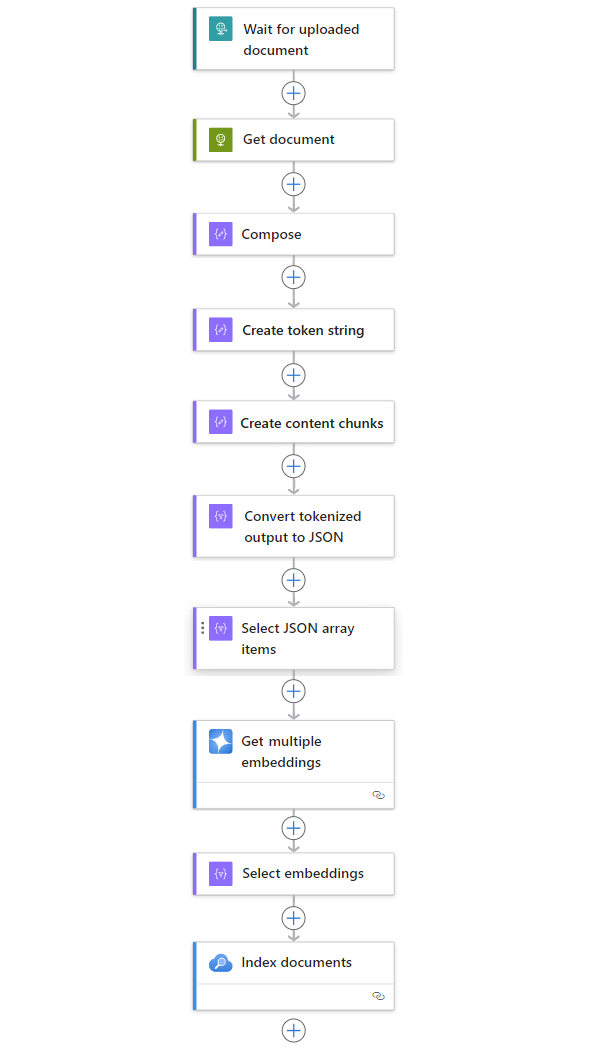
| Stap | Taak | Onderliggende bewerking | Beschrijving |
|---|---|---|---|
| 1 | Wacht of controleer op nieuwe inhoud. | Wanneer een HTTP-aanvraag wordt ontvangen | Een trigger die pollt of wacht tot nieuwe gegevens binnenkomen, hetzij op basis van een gepland terugkeerpatroon of in reactie op specifieke gebeurtenissen. Een dergelijke gebeurtenis kan een nieuw bestand zijn dat wordt geüpload naar een specifiek opslagsysteem, zoals Azure Blob Storage, SharePoint, OneDrive, Bestandssysteem, FTP, enzovoort. In dit voorbeeld wacht de aanvraagtriggerbewerking op een HTTP- of HTTPS-aanvraag die is verzonden vanaf een ander eindpunt. De aanvraag bevat de URL voor een nieuw geüpload document. |
| 2 | Haal de inhoud op. | HTTP | Een HTTP-actie waarmee het geüploade document wordt opgehaald met behulp van de bestands-URL uit de uitvoer van de trigger. |
| 3 | Documentdetails opstellen. | Compose | Een actie Gegevensbewerkingen waarmee verschillende items worden samengevoegd. In dit voorbeeld worden sleutelwaardegegevens over het document samengevoegd. |
| 4 | Een tokentekenreeks maken. | Een document parseren | Een actie Gegevensbewerkingen die een tokenized tekenreeks produceert met behulp van de uitvoer van de actie Opstellen . |
| 5 | Inhoudssegmenten maken. | Segmenttekst | Een gegevensbewerkingsactie waarmee de tokentekenreeks wordt gesplitst in stukken, op basis van het aantal tokens per inhoudssegment. |
| 6 | Converteer tokenized en gesegmenteerde tekst naar JSON. | JSON parseren | Een gegevensbewerkingsactie waarmee de gesegmenteerde uitvoer wordt geconverteerd naar een JSON-matrix. |
| 7 | Selecteer JSON-matrixitems. | Selecteren | Een actie Gegevensbewerkingen waarmee meerdere items uit de JSON-matrix worden geselecteerd. |
| 8 | Genereer de insluitingen. | Meerdere insluitingen ophalen | Een Azure OpenAI-actie waarmee insluitingen voor elk JSON-matrixitem worden gemaakt. |
| 9 | Selecteer insluitingen en andere informatie. | Selecteren | Een bewerking voor gegevensbewerkingen waarmee insluitingen en andere documentgegevens worden geselecteerd. |
| 10 | Indexeer de gegevens. | Documenten indexeren | Een Azure AI Search-actie waarmee de gegevens worden geïndexeerd op basis van elke geselecteerde insluiting. |