Grote documenten segmenten voor vectorzoekoplossingen in Azure AI Search
Door grote documenten in kleinere segmenten te partitioneren, kunt u onder de maximale tokeninvoerlimieten van insluitingsmodellen blijven. De maximale lengte van invoertekst voor het Azure OpenAI-model voor tekst-embedding-ada-002 is bijvoorbeeld 8.191 tokens. Aangezien elk token ongeveer vier tekens tekst bevat voor algemene OpenAI-modellen, is deze maximumlimiet gelijk aan ongeveer 6000 woorden aan tekst. Als u deze modellen gebruikt om insluitingen te genereren, is het essentieel dat de invoertekst onder de limiet blijft. Het partitioneren van uw inhoud in segmenten zorgt ervoor dat uw gegevens kunnen worden verwerkt door de insluitingsmodellen en dat u geen informatie kwijtraakt als gevolg van afkapping.
We raden geïntegreerde vectorisatie aan voor ingebouwd segmenteren en insluiten van gegevens. Geïntegreerde vectorisatie heeft een afhankelijkheid van indexeerfuncties, vaardighedensets, de vaardigheid Tekst splitsen en een insluitingsvaardigheden zoals Azure OpenAI Embedding-vaardigheid. Als u geïntegreerde vectorisatie niet kunt gebruiken, worden in dit artikel enkele benaderingen beschreven voor het segmenteren van uw inhoud.
Algemene segmenteringstechnieken
Segmentering is alleen vereist als de brondocumenten te groot zijn voor de maximale invoergrootte die door modellen wordt opgelegd.
Hier volgen enkele veelvoorkomende segmenteringstechnieken, te beginnen met de meest gebruikte methode:
Segmenten met vaste grootte: Definieer een vaste grootte die voldoende is voor semantisch zinvolle alinea's (bijvoorbeeld 200 woorden) en maakt overlapping mogelijk (bijvoorbeeld 10-15% van de inhoud) kan goede segmenten produceren als invoer voor het insluiten van vectorgeneratoren.
Segmenten van variabele grootte op basis van inhoud: Partitioneer uw gegevens op basis van inhoudskenmerken, zoals interpunctiemarkeringen einde van zinnen, einde-van-regelmarkeringen of het gebruik van functies in de NLP-bibliotheken (Natural Language Processing). Markdown-taalstructuur kan ook worden gebruikt om de gegevens te splitsen.
Een van de bovenstaande technieken aanpassen of herhalen. Als u bijvoorbeeld grote documenten gebruikt, kunt u segmenten van variabele grootte gebruiken, maar ook de documenttitel toevoegen aan segmenten in het midden van het document om contextverlies te voorkomen.
Overwegingen voor overlappende inhoud
Wanneer u gegevens segmenteert, kan het overlappen van een kleine hoeveelheid tekst tussen segmenten helpen context te behouden. We raden u aan om te beginnen met een overlapping van ongeveer 10%. Als u bijvoorbeeld een vaste segmentgrootte van 256 tokens hebt, begint u te testen met een overlapping van 25 tokens. De werkelijke hoeveelheid overlapping varieert, afhankelijk van het type gegevens en de specifieke use-case, maar we hebben vastgesteld dat 10-15% voor veel scenario's werkt.
Factoren voor het segmenteren van gegevens
Als het gaat om het segmenteren van gegevens, moet u nadenken over deze factoren:
Vorm en dichtheid van uw documenten. Als u intacte tekst of passages nodig hebt, kunnen grotere segmenten en variabele segmenten die de zinstructuur behouden, betere resultaten opleveren.
Gebruikersquery's: Grotere segmenten en overlappende strategieën helpen context en semantische rijkdom te behouden voor query's waarop specifieke informatie is gericht.
Grote taalmodellen (LLM) hebben prestatierichtlijnen voor segmentgrootte. u moet een segmentgrootte instellen die het beste werkt voor alle modellen die u gebruikt. Als u bijvoorbeeld modellen gebruikt voor samenvattingen en insluitingen, kiest u een optimale segmentgrootte die geschikt is voor beide.
Hoe segmentering in de werkstroom past
Als u grote documenten hebt, moet u een segmentstap invoegen in indexerings- en querywerkstromen die grote tekst opsplitsen. Wanneer u geïntegreerde vectorisatie gebruikt, wordt een standaardsegmenteringsstrategie toegepast met behulp van de vaardigheid Tekst splitsen. U kunt ook een aangepaste segmenteringsstrategie toepassen met behulp van een aangepaste vaardigheid. Enkele bibliotheken die segmentering bieden, zijn onder andere:
De meeste bibliotheken bieden veelgebruikte segmenteringstechnieken voor vaste grootte, variabele grootte of een combinatie. U kunt ook een overlapping opgeven waarmee een kleine hoeveelheid inhoud in elk segment wordt gedupliceerd voor het behoud van de context.
Voorbeelden van segmentering
De volgende voorbeelden laten zien hoe segmenteringsstrategieën worden toegepast op NASA's Earth at Night e-book PDF-bestand:
Voorbeeld van vaardigheid Tekst splitsen
Geïntegreerde gegevenssegmentering via de vaardigheid Tekst splitsen is algemeen beschikbaar.
In deze sectie worden ingebouwde gegevenssegmentering beschreven met behulp van een vaardighedengestuurde benadering en parameters voor vaardigheden splitsen van tekstsplitsing.
Een voorbeeldnotebook voor dit voorbeeld vindt u in de opslagplaats azure-search-vector-samples .
Instellen textSplitMode om inhoud op te splitsen in kleinere segmenten:
pages(standaard). Segmenten bestaan uit meerdere zinnen.sentences. Segmenten bestaan uit enkele zinnen. Wat een 'zin' vormt, is taalafhankelijk. In het Engels wordt standaard zin die interpunctie beëindigt, zoals.of!wordt gebruikt. De taal wordt bepaald door dedefaultLanguageCodeparameter.
Met de pages parameter worden extra parameters toegevoegd:
maximumPageLengthdefinieert het maximum aantal tekens 1 of tokens 2 in elk segment. De tekstsplitser vermijdt het opsplitsen van zinnen, dus het werkelijke aantal tekens is afhankelijk van de inhoud.pageOverlapLengthdefinieert hoeveel tekens van het einde van de vorige pagina worden opgenomen aan het begin van de volgende pagina. Indien ingesteld, moet dit minder dan de helft van de maximale paginalengte zijn.maximumPagesToTakedefinieert hoeveel pagina's/segmenten moeten worden overgenomen uit een document. De standaardwaarde is 0, wat betekent dat alle pagina's of segmenten uit het document worden gebruikt.
1 tekens worden niet uitgelijnd op de definitie van een token. Het aantal tokens dat door de LLM wordt gemeten, kan afwijken van de tekengrootte die wordt gemeten door de vaardigheid Tekst splitsen.
2 Tokensegmentering is beschikbaar in de preview-versie 2024-09-01 en bevat extra parameters voor het opgeven van een tokenizer en eventuele tokens die niet moeten worden gesplitst tijdens segmenten.
In de volgende tabel ziet u hoe de keuze van parameters van invloed is op het totale aantal segmenten van de aarde 's nachts e-book:
textSplitMode |
maximumPageLength |
pageOverlapLength |
Totaal aantal segmenten |
|---|---|---|---|
pages |
1000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000 | 0 | 85 |
pages |
2000 | 500 | 113 |
pages |
5000 | 0 | 34 |
pages |
5000 | 500 | 38 |
sentences |
N.v.t. | N.v.t. | 13361 |
Het gebruik van een textSplitMode van pages de resultaten in een meerderheid van segmenten met het totale aantal tekens dicht bij maximumPageLength. Het aantal segmenttekens varieert vanwege verschillen in de plaats waar de zinsgrenzen binnen het segment vallen. De lengte van het segmenttoken varieert vanwege verschillen in de inhoud van het segment.
De volgende histogrammen laten zien hoe de verdeling van segmenttekenlengte zich verhoudt tot segmenttokenlengte voor gpt-35-turbo bij gebruik van een vanpages, een maximumPageLength textSplitMode van 2000 en een pageOverlapLength van 500 op de aarde bij nacht e-book:
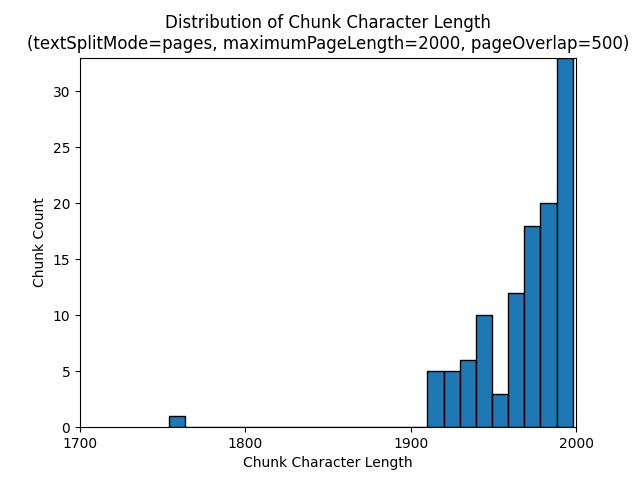
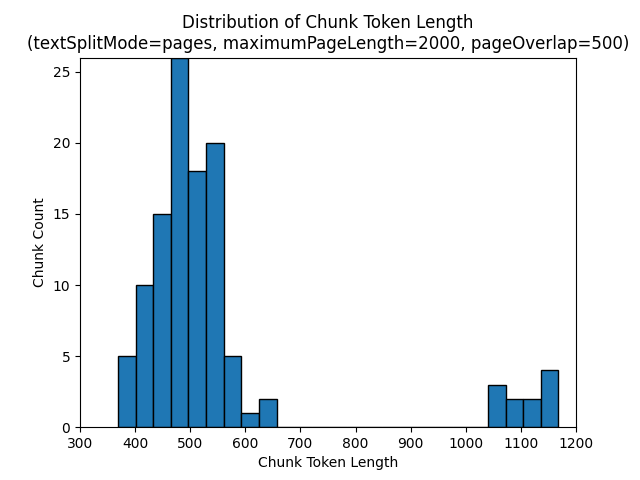
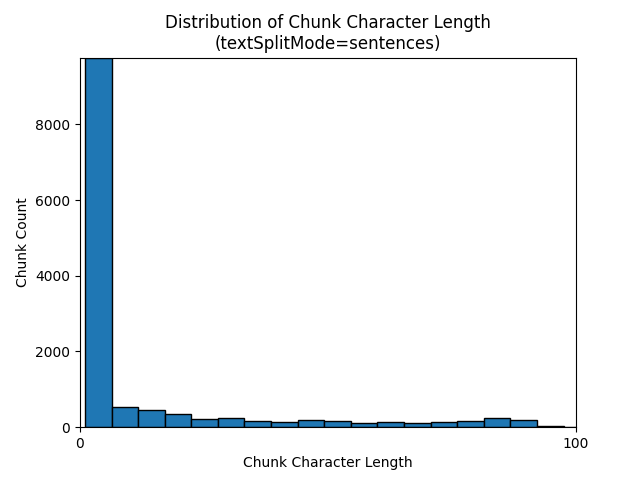
Het gebruik van een textSplitMode van sentences de resultaten in een groot aantal segmenten bestaande uit afzonderlijke zinnen. Deze segmenten zijn aanzienlijk kleiner dan de segmenten die worden pagesgeproduceerd en het tokenaantal van de segmenten komt nauwkeuriger overeen met het aantal tekens.
De volgende histogrammen laten zien hoe de verdeling van chunk-tekenlengte zich verhoudt tot segmenttokenlengte voor gpt-35-turbo bij gebruik van een textSplitMode van sentences op de aarde bij nacht e-book:
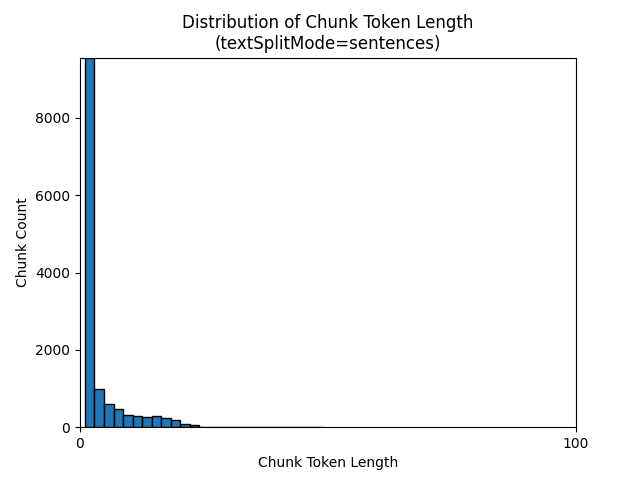
De optimale keuze van parameters is afhankelijk van hoe de segmenten worden gebruikt. Voor de meeste toepassingen is het raadzaam om te beginnen met de volgende standaardparameters:
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000 | 500 |
Voorbeeld van segmentering van LangChain-gegevens
LangChain biedt documentlaadders en tekstsplitsers. In dit voorbeeld ziet u hoe u een PDF laadt, het aantal tokens opvragen en een tekstsplitser instelt. Het ophalen van tokenaantallen helpt u bij het nemen van een weloverwogen beslissing over het aanpassen van segmentgrootten.
Een voorbeeldnotebook voor dit voorbeeld vindt u in de opslagplaats azure-search-vector-samples .
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
Uitvoer geeft 200 documenten of pagina's in het PDF-bestand aan.
Gebruik TikToken om een geschatte tokenaantal voor deze pagina's op te halen.
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
Uitvoer geeft aan dat er geen pagina's nul tokens hebben, dat de gemiddelde tokenlengte per pagina 189 tokens is en het maximum aantal tokens van een pagina 1583 is.
Als u de gemiddelde en maximale tokengrootte kent, krijgt u inzicht in het instellen van segmentgrootte. Hoewel u de standaardaanbieding van 2000 tekens met een overlapping van 500 tekens kunt gebruiken, is het in dit geval zinvol om lager te gaan op basis van het tokenaantallen van het voorbeelddocument. Het instellen van een overlappingswaarde die te groot is, kan ertoe leiden dat er helemaal geen overlapping wordt weergegeven.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
De uitvoer voor twee opeenvolgende segmenten toont de tekst van het eerste segment dat overlapt met het tweede segment. De uitvoer wordt licht bewerkt voor leesbaarheid.
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
Aangepaste vaardigheid
Een voorbeeld van segmenten en insluiten van een vaste grootte laat zien hoe u segmenten en vectoren insluiten kunt genereren met behulp van Azure OpenAI-insluitingsmodellen . In dit voorbeeld wordt een aangepaste vaardigheid van Azure AI Search gebruikt in de opslagplaats Power Skills om de segmenteringsstap te verpakken.