Foutopsporing in Spark-taken met Azure Toolkit voor IntelliJ (preview)
Dit artikel bevat stapsgewijze richtlijnen voor het gebruik van HDInsight Tools in Azure Toolkit for IntelliJ om Spark Failure Debug Applications uit te voeren.
Vereisten
Oracle Java Development Kit. In deze zelfstudie wordt gebruikgemaakt van Java-versie 8.0.202.
IntelliJ IDEA. In dit artikel wordt gebruikgemaakt van IntelliJ IDEA Community 2019.1.3.
Azure-toolkit voor IntelliJ. Zie Installing the Azure Toolkit for IntelliJ (De Azure Toolkit voor IntelliJ installeren).
Maak verbinding met uw HDInsight-cluster. Zie Verbinding maken met uw HDInsight-cluster.
Microsoft Azure Storage Explorer. Zie Microsoft Azure Storage Explorer downloaden.
Een project maken met een foutopsporingssjabloon
Maak een spark2.3.2-project om door te gaan met foutopsporing. Neem foutopsporingsvoorbeeldbestand voor fouttaken in dit document.
Open IntelliJ IDEA. Open het venster Nieuw project .
a. Selecteer Azure Spark/HDInsight in het linkerdeelvenster.
b. Selecteer Spark-project met foutopsporingsvoorbeeld (preview)(Scala) in het hoofdvenster.
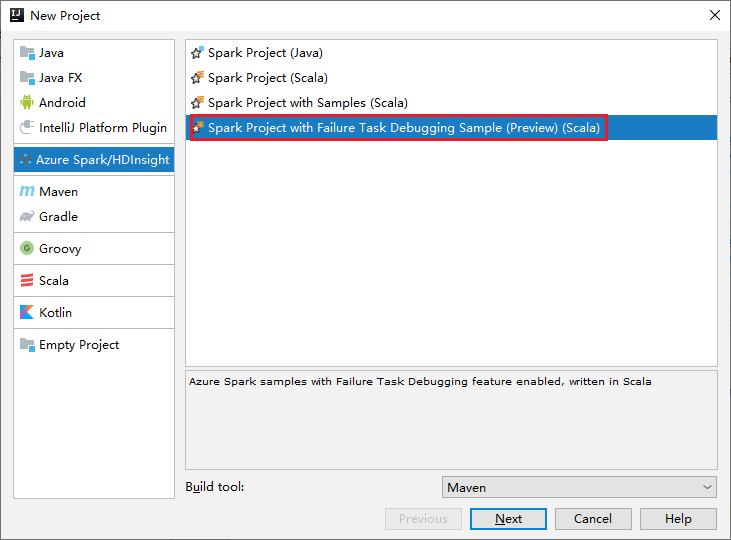
c. Selecteer Volgende.
Voer in het venster Nieuw project de volgende stappen uit:
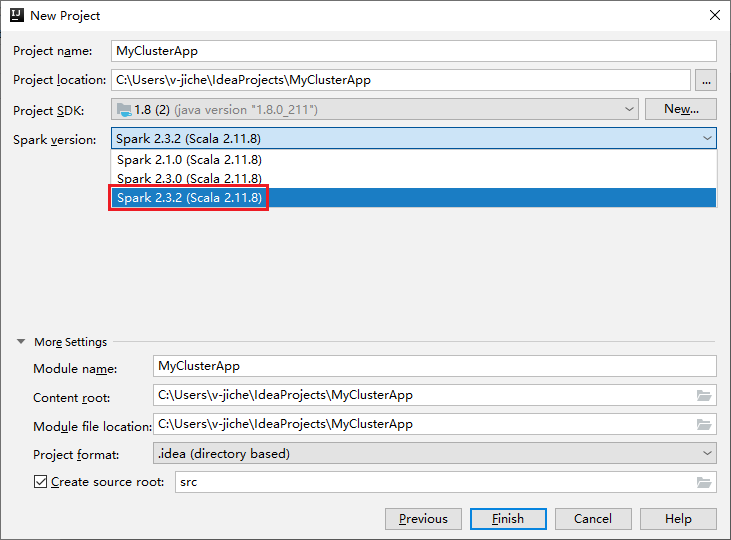
a. Voer een projectnaam en projectlocatie in.
b. Selecteer In de vervolgkeuzelijst Project SDK Java 1.8 voor Spark 2.3.2-cluster.
c. Selecteer Spark 2.3.2(Scala 2.11.8) in de vervolgkeuzelijst Spark-versie.
d. Selecteer Voltooien.
Selecteer src>main>scala om uw code in het project te openen. In dit voorbeeld wordt het script AgeMean_Div() gebruikt.
Een Spark Scala/Java-toepassing uitvoeren op een HDInsight-cluster
Maak een Spark Scala/Java-toepassing en voer de toepassing vervolgens uit op een Spark-cluster door de volgende stappen uit te voeren:
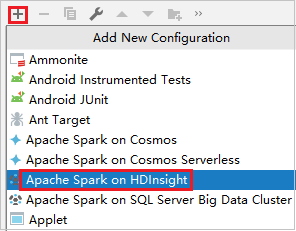
Klik op Configuratie toevoegen om het venster Uitvoeren/foutopsporingsconfiguraties te openen.

Selecteer in het dialoogvenster Configuraties uitvoeren /fouten opsporen het plusteken (+). Selecteer vervolgens de optie Apache Spark in HDInsight .
Schakel over naar extern uitvoeren op het tabblad Cluster . Voer informatie in voor de naam, het Spark-cluster en de naam van de hoofdklasse. Onze hulpprogramma's ondersteunen foutopsporing met executors. De numExecutors, de standaardwaarde is 5 en u kunt beter niet hoger dan 3 instellen. Als u de runtime wilt verminderen, kunt u spark.yarn.maxAppAttempts toevoegen aan taakconfiguraties en de waarde instellen op 1. Klik op de knop OK om de configuratie op te slaan.
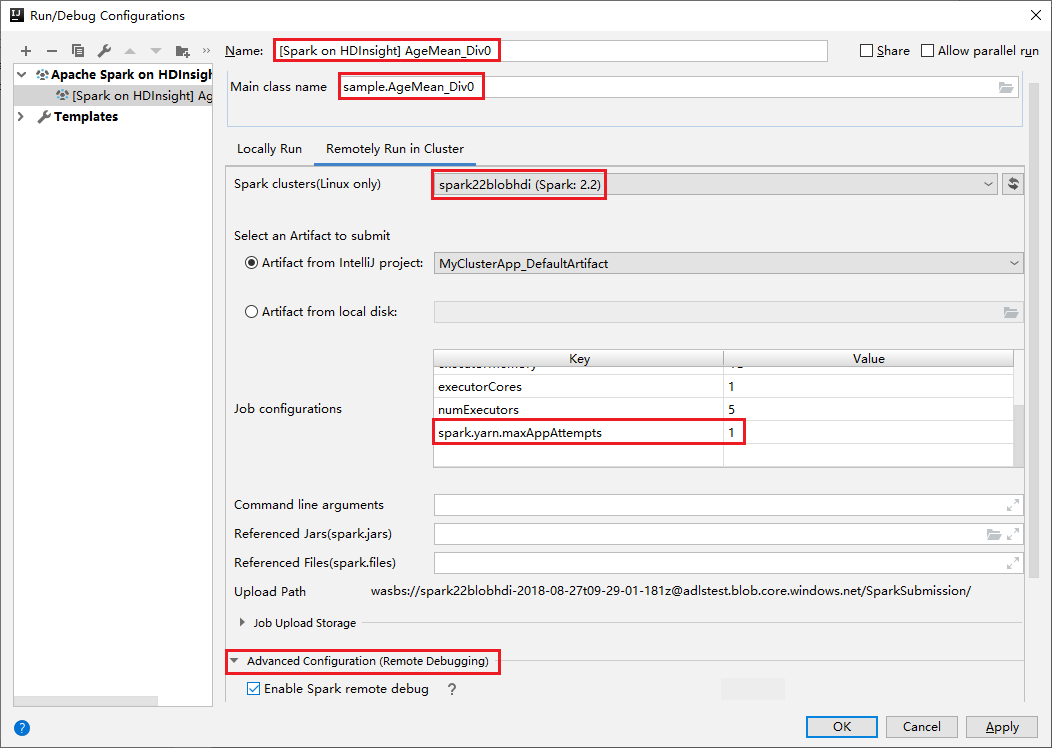
De configuratie wordt nu opgeslagen met de naam die u hebt opgegeven. Als u de configuratiedetails wilt weergeven, selecteert u de configuratienaam. Als u wijzigingen wilt aanbrengen, selecteert u Configuraties bewerken.
Nadat u de configuratie-instellingen hebt voltooid, kunt u het project uitvoeren op het externe cluster.

U kunt de toepassings-id in het uitvoervenster controleren.

Mislukt taakprofiel downloaden
Als het indienen van de taak mislukt, kunt u het mislukte taakprofiel downloaden naar de lokale computer voor verdere foutopsporing.
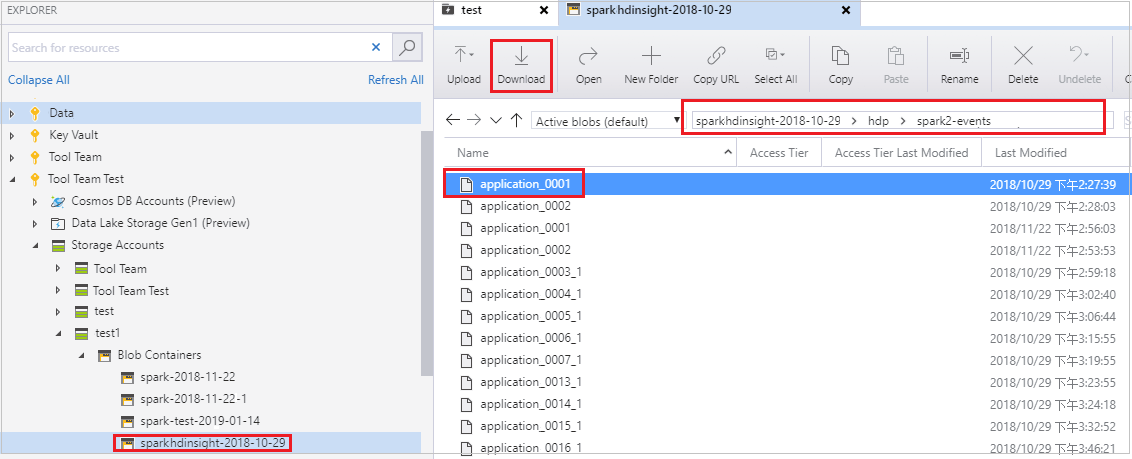
Open Microsoft Azure Storage Explorer, zoek het HDInsight-account van het cluster voor de mislukte taak, download de resources van de mislukte taak vanaf de bijbehorende locatie: \hdp\spark2-events\.spark-failures\<application ID> naar een lokale map. In het activiteitenvenster wordt de voortgang van het downloaden weergegeven.
Lokale foutopsporingsomgeving configureren en fouten opsporen bij fouten
Open het oorspronkelijke project of maak een nieuw project en koppel het aan de oorspronkelijke broncode. Momenteel wordt alleen spark2.3.2-versie ondersteund voor foutopsporing.
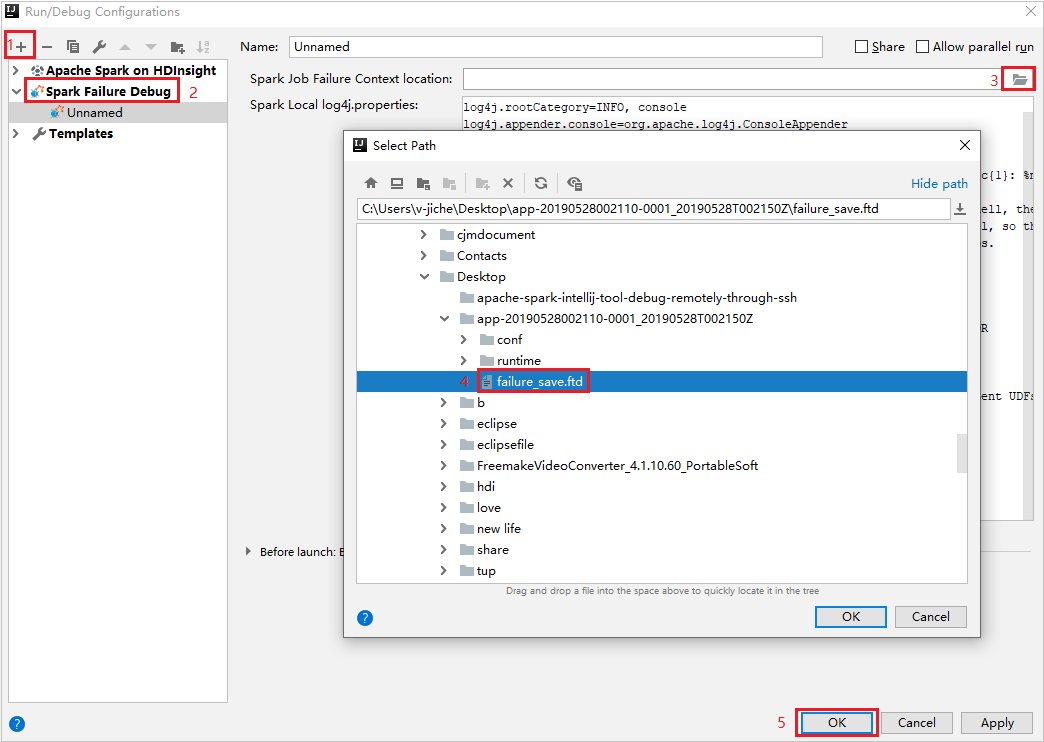
Maak in IntelliJ IDEA een Spark-foutopsporingsconfiguratiebestand en selecteer het FTD-bestand uit de eerder gedownloade mislukte taakbronnen voor het locatieveld Spark-taakfoutcontext .
Klik op de knop Lokaal uitvoeren op de werkbalk. De fout wordt weergegeven in het venster Uitvoeren.
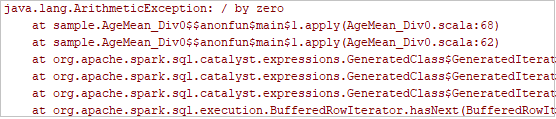
Stel het onderbrekingspunt in zoals het logboek aangeeft en klik vervolgens op de lokale foutopsporingsknop om lokale foutopsporing uit te voeren, net zoals uw normale Scala/Java-projecten in IntelliJ.
Als de foutopsporing is voltooid, kunt u de mislukte taak opnieuw indienen bij uw Spark in HDInsight-cluster als het project is voltooid.
Volgende stappen
Scenario's
- Apache Spark met BI: Interactieve gegevensanalyse uitvoeren met Behulp van Spark in HDInsight met BI-hulpprogramma's
- Apache Spark met Machine Learning: Spark in HDInsight gebruiken om de gebouwtemperatuur te analyseren met behulp van HVAC-gegevens
- Apache Spark met Machine Learning: Spark in HDInsight gebruiken om resultaten van voedselinspectie te voorspellen
- Analyse van websitelogboeken met Apache Spark in HDInsight
Toepassingen maken en uitvoeren
- Een zelfstandige toepassing maken met behulp van Scala
- Apache Livy gebruiken om taken op afstand uit te voeren in een Apache Spark-cluster
Tools en uitbreidingen
- Azure Toolkit voor IntelliJ gebruiken om Apache Spark-toepassingen te maken voor een HDInsight-cluster
- Azure Toolkit voor IntelliJ gebruiken om op afstand fouten in Apache Spark-toepassingen op te sporen via VPN
- HDInsight Tools gebruiken in Azure Toolkit voor Eclipse om Apache Spark-toepassingen te maken
- Apache Zeppelin-notebooks gebruiken met een Apache Spark-cluster in HDInsight
- Kernels beschikbaar voor Jupyter Notebook in het Apache Spark-cluster voor HDInsight
- Externe pakketten gebruiken met Jupyter Notebooks
- Jupyter op uw computer installeren en verbinding maken met een HDInsight Spark-cluster