Fouten opsporen in Apache Spark-toepassingen in een HDInsight-cluster met Azure Toolkit voor IntelliJ via SSH
In dit artikel vindt u stapsgewijze instructies voor het gebruik van HDInsight Tools in Azure Toolkit for IntelliJ voor het opsporen van fouten in toepassingen op afstand in een HDInsight-cluster.
Vereisten
Een Apache Spark-cluster in HDInsight. Zie Een Apache Spark-cluster maken.
Voor Windows-gebruikers: terwijl u de lokale Spark Scala-toepassing op een Windows-computer uitvoert, krijgt u mogelijk een uitzondering, zoals uitgelegd in SPARK-2356. De uitzondering treedt op omdat WinUtils.exe ontbreekt op Windows.
Als u deze fout wilt oplossen, downloadt u Winutils.exe naar een locatie zoals C:\WinUtils\bin. Vervolgens voegt u de omgevingsvariabele HADOOP_HOME toe en stelt u de waarde van de variabele in op C:\WinUtils.
IntelliJ IDEA (De Community-editie is gratis.).
Een SSH-client. Zie voor meer informatie Verbinding maken met HDInsight (Apache Hadoop) via SSH.
Een Spark Scala-toepassing maken
Start IntelliJ IDEA en selecteer Create New Project om het venster New Project te openen.
Selecteer Apache Spark/HDInsight in het linkerdeelvenster.
Selecteer Spark-project met voorbeelden (Scala) in het hoofdvenster.
Selecteer in de vervolgkeuzelijst Build tool een van de volgende opties:
- Maven, voor de ondersteuning van de wizard Scala-project maken.
- SBT, voor het beheren van de afhankelijkheden en het maken van het Scala-project.
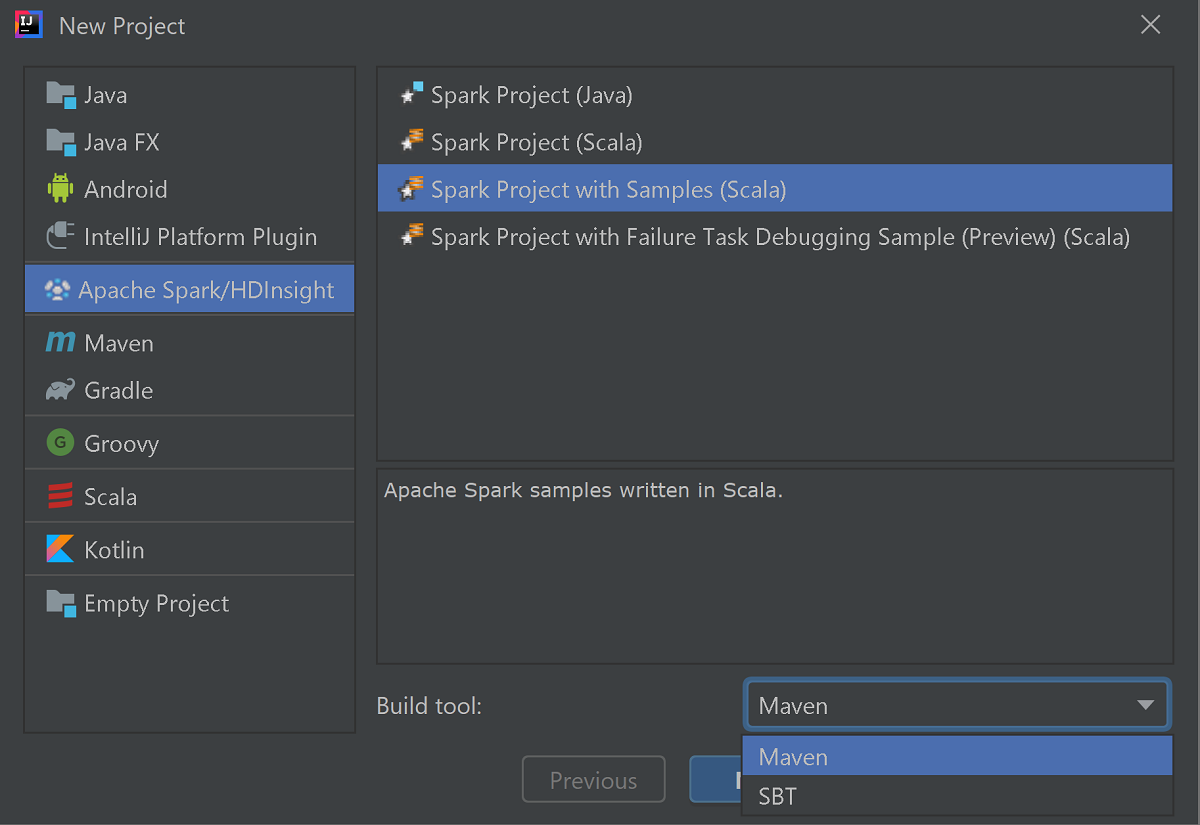
Selecteer Volgende.
Geef in het volgende venster Nieuw project de volgende informatie op:
Eigenschappen Beschrijving Projectnaam Voer een naam in. In deze rondleiding wordt gebruikgemaakt myAppvan .Projectlocatie Voer de gewenste locatie in om uw project in op te slaan. Project SDK Als dit leeg is, selecteert u Nieuw... en navigeert u naar uw JDK. Spark-versie De wizard voor het maken van het project integreert de juiste versie voor Spark SDK en Scala SDK. Selecteer Spark 1.x als de Spark-clusterversie ouder is dan 2.0. Selecteer anders Spark 2.x.. In dit voorbeeld wordt Spark 2.3.0 (Scala 2.11.8) gebruikt. 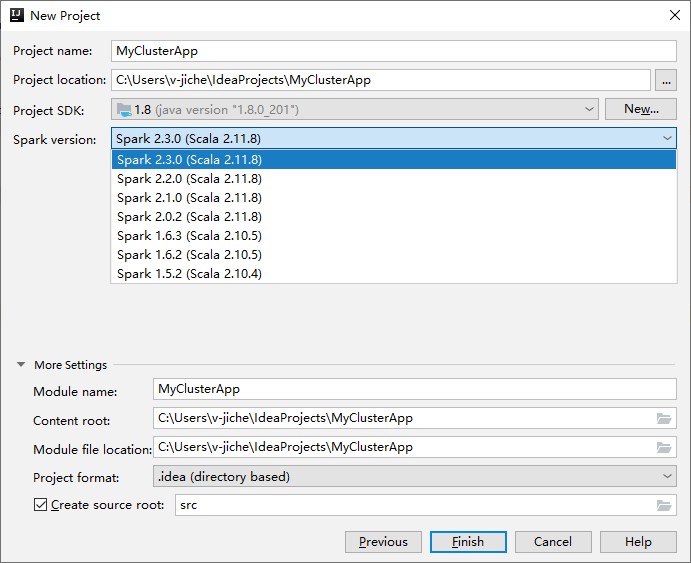
Selecteer Voltooien. Het kan enkele minuten duren voordat het project beschikbaar wordt. Bekijk de rechterbenedenhoek voor voortgang.
Vouw uw project uit en navigeer naar het belangrijkste>scala-voorbeeld>van src.> Dubbelklik op SparkCore_WasbIOTest.
Lokale uitvoering uitvoeren
Klik in het SparkCore_WasbIOTest-script met de rechtermuisknop op de scripteditor en selecteer vervolgens de optie SparkCore_WasbIOTest uitvoeren om een lokale uitvoering uit te voeren.
Zodra de lokale uitvoering is voltooid, ziet u dat het uitvoerbestand wordt opgeslagen in de huidige standaardgegevens van> projectverkenner.
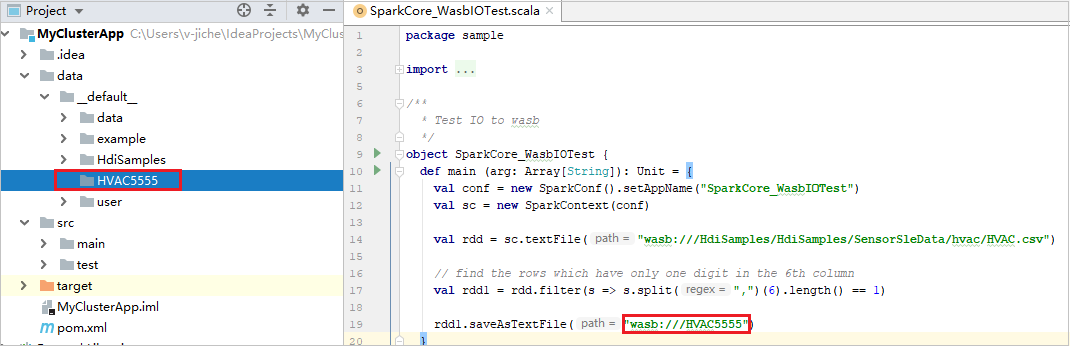
Onze hulpprogramma's hebben de standaardconfiguratie voor lokale uitvoering automatisch ingesteld wanneer u de lokale uitvoering en lokale foutopsporing uitvoert. Open de configuratie [Spark in HDInsight] XXX in de rechterbovenhoek. U ziet de [Spark in HDInsight]XXX die al is gemaakt onder Apache Spark in HDInsight. Schakel over naar het tabblad Lokaal uitvoeren .
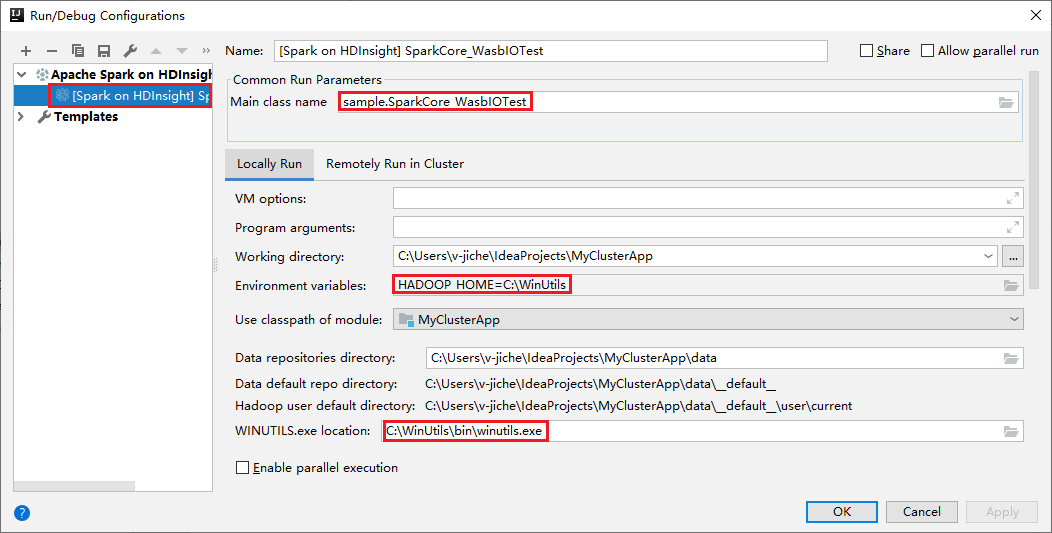
- Omgevingsvariabelen: Als u de omgevingsvariabele van het systeem al instelt HADOOP_HOME op C:\WinUtils, kan automatisch worden gedetecteerd dat u deze niet handmatig hoeft toe te voegen.
- WinUtils.exe Locatie: Als u de omgevingsvariabele van het systeem niet hebt ingesteld, kunt u de locatie vinden door op de knop ervan te klikken.
- Kies een van de twee opties en ze zijn niet nodig in macOS en Linux.
U kunt de configuratie ook handmatig instellen voordat u lokale uitvoering en lokale foutopsporing uitvoert. Selecteer in de voorgaande schermopname het plusteken (+). Selecteer vervolgens de optie Apache Spark in HDInsight . Voer informatie in voor Naam, Hoofdklassenaam die u wilt opslaan en klik vervolgens op de knop Lokaal uitvoeren.
Lokale foutopsporing uitvoeren
Open het SparkCore_wasbloTest script en stel onderbrekingspunten in.
Klik met de rechtermuisknop op de scripteditor en selecteer vervolgens de optie Foutopsporing [Spark in HDInsight]XXX om lokale foutopsporing uit te voeren.
Externe uitvoering uitvoeren
Navigeer naar Bewerkingsconfiguraties uitvoeren>.... In dit menu kunt u de configuraties voor externe foutopsporing maken of bewerken.
Selecteer in het dialoogvenster Configuraties uitvoeren /fouten opsporen het plusteken (+). Selecteer vervolgens de optie Apache Spark in HDInsight .
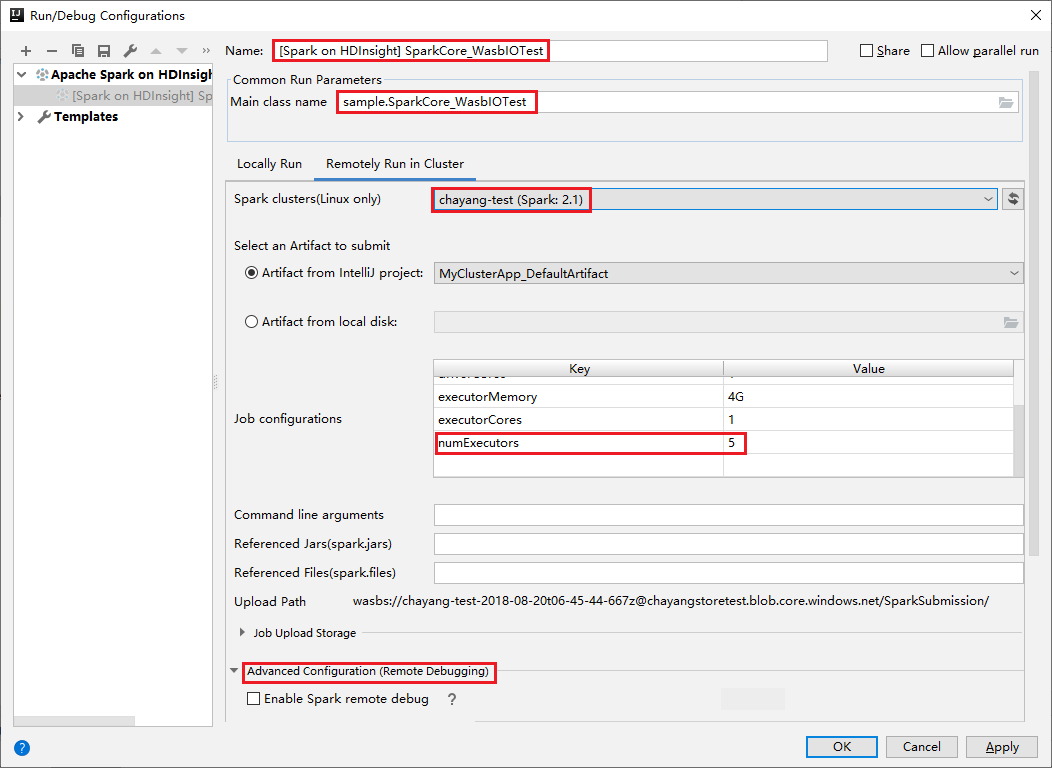
Schakel over naar extern uitvoeren op het tabblad Cluster . Voer informatie in voor de naam, het Spark-cluster en de naam van de hoofdklasse. Klik vervolgens op Geavanceerde configuratie (externe foutopsporing). Onze hulpprogramma's ondersteunen foutopsporing met executors. De numExecutors, de standaardwaarde is 5. U kunt beter niet hoger dan 3 instellen.
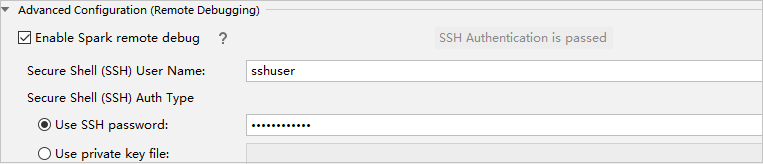
Selecteer in het gedeelte Geavanceerde configuratie (externe foutopsporing) de optie Externe foutopsporing van Spark inschakelen. Voer de SSH-gebruikersnaam in en voer een wachtwoord in of gebruik een bestand met een persoonlijke sleutel. Als u externe foutopsporing wilt uitvoeren, moet u deze instellen. U hoeft deze niet in te stellen als u alleen externe uitvoering wilt gebruiken.
De configuratie wordt nu opgeslagen met de naam die u hebt opgegeven. Als u de configuratiedetails wilt weergeven, selecteert u de configuratienaam. Als u wijzigingen wilt aanbrengen, selecteert u Configuraties bewerken.
Nadat u de configuratie-instellingen hebt voltooid, kunt u het project uitvoeren op het externe cluster of externe foutopsporing uitvoeren.

Klik op de knop Verbinding verbreken die de indieningslogboeken niet in het linkerdeelvenster worden weergegeven. Deze wordt echter nog steeds uitgevoerd op de back-end.
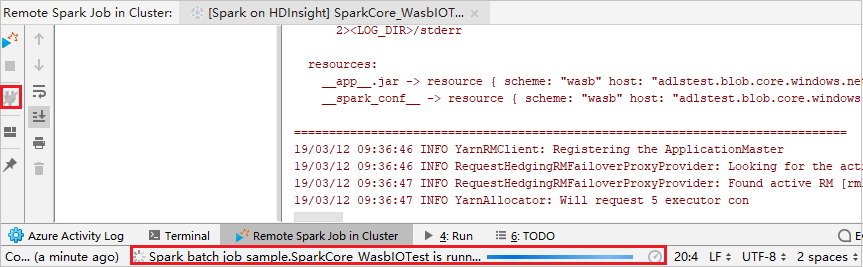
Externe foutopsporing uitvoeren
Stel belangrijke punten in en klik vervolgens op het pictogram externe foutopsporing . Het verschil met externe inzending is dat SSH-gebruikersnaam en -wachtwoord moeten worden geconfigureerd.

Wanneer de uitvoering van het programma het onderbrekingspunt bereikt, ziet u een tabblad Stuurprogramma en twee uitvoerderstabbladen in het deelvenster Foutopsporingsprogramma . Selecteer het pictogram Programma hervatten om door te gaan met het uitvoeren van de code, die vervolgens het volgende onderbrekingspunt bereikt. U moet overschakelen naar het juiste tabblad Executor om de doeluitvoerer te vinden om fouten op te sporen. U kunt de uitvoeringslogboeken bekijken op het bijbehorende consoletabblad .
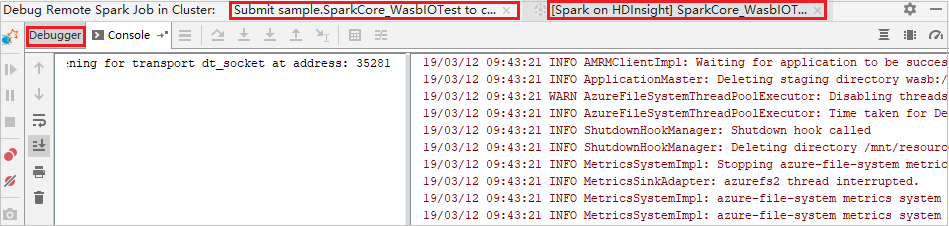
Externe foutopsporing en foutopsporing uitvoeren
Stel twee belangrijke punten in en selecteer vervolgens het pictogram Foutopsporing om het externe foutopsporingsproces te starten.
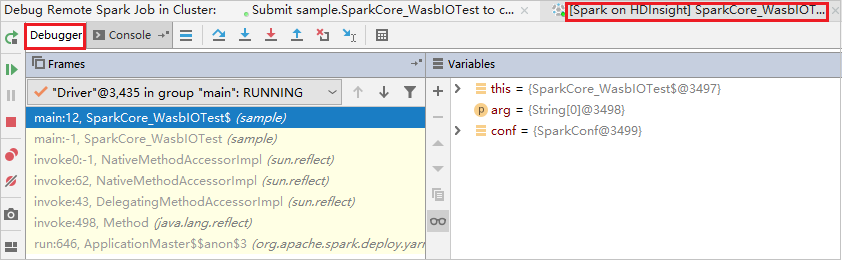
De code stopt bij het eerste breekpunt en de parameter- en variabelegegevens worden weergegeven in het deelvenster Variabelen .
Selecteer het pictogram Programma hervatten om door te gaan. De code stopt op het tweede punt. De uitzondering wordt opgevangen zoals verwacht.
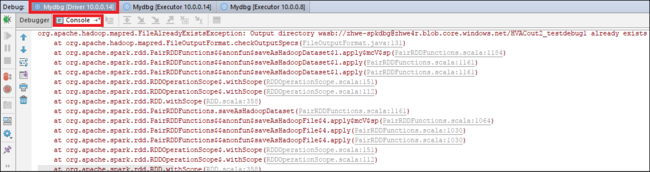
Selecteer het pictogram Programma hervatten opnieuw. In het hdInsight Spark-indieningsvenster wordt de fout 'taakuitvoering is mislukt' weergegeven.
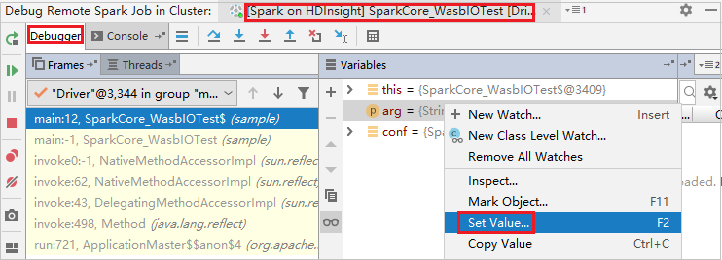
Als u de waarde van de variabele dynamisch wilt bijwerken met behulp van de intelliJ-foutopsporingsfunctie, selecteert u de foutopsporing opnieuw. Het deelvenster Variabelen wordt opnieuw weergegeven.
Klik met de rechtermuisknop op het doel op het tabblad Foutopsporing en selecteer Waarde instellen. Voer vervolgens een nieuwe waarde in voor de variabele. Selecteer vervolgens Enter om de waarde op te slaan.
Selecteer het pictogram Programma hervatten om door te gaan met het uitvoeren van het programma. Deze keer wordt er geen uitzondering opgetreden. U kunt zien dat het project zonder uitzonderingen wordt uitgevoerd.
Volgende stappen
Scenario's
- Apache Spark met BI: interactieve gegevensanalyse uitvoeren met Behulp van Spark in HDInsight met BI-hulpprogramma's
- Apache Spark met Machine Learning: Spark in HDInsight gebruiken om de gebouwtemperatuur te analyseren met behulp van HVAC-gegevens
- Apache Spark met Machine Learning: Spark in HDInsight gebruiken om resultaten van voedselinspectie te voorspellen
- Analyse van websitelogboeken met Apache Spark in HDInsight
Toepassingen maken en uitvoeren
- Een zelfstandige toepassing maken met behulp van Scala
- Apache Livy gebruiken om taken op afstand uit te voeren in een Apache Spark-cluster
Tools en uitbreidingen
- Azure Toolkit voor IntelliJ gebruiken om Apache Spark-toepassingen te maken voor een HDInsight-cluster
- Azure Toolkit voor IntelliJ gebruiken om op afstand fouten in Apache Spark-toepassingen op te sporen via VPN
- HDInsight Tools gebruiken in Azure Toolkit voor Eclipse om Apache Spark-toepassingen te maken
- Apache Zeppelin-notebooks gebruiken met een Apache Spark-cluster in HDInsight
- Kernels beschikbaar voor Jupyter Notebook in het Apache Spark-cluster voor HDInsight
- Externe pakketten gebruiken met Jupyter Notebooks
- Jupyter op uw computer installeren en verbinding maken met een HDInsight Spark-cluster