Apache Hive optimaliseren met Apache Ambari in Azure HDInsight
Apache Ambari is een webinterface voor het beheren en bewaken van HDInsight-clusters. Zie HDInsight-clusters beheren met behulp van de Apache Ambari-webinterface voor een inleiding tot de Ambari-webinterface.
In de volgende secties worden configuratieopties beschreven voor het optimaliseren van de algehele Prestaties van Apache Hive.
- Als u hive-configuratieparameters wilt wijzigen, selecteert u Hive in de zijbalk services.
- Navigeer naar het tabblad Configuraties .
De Hive-uitvoeringsengine instellen
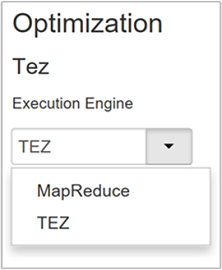
Hive biedt twee uitvoeringsengines: Apache Hadoop MapReduce en Apache TEZ. Tez is sneller dan MapReduce. HDInsight Linux-clusters hebben Tez als de standaarduitvoeringsengine. De uitvoeringsengine wijzigen:
Typ op het tabblad Hive-configuraties de uitvoeringsengine in het filtervak.
De standaardwaarde van de eigenschap Optimalisatie is Tez.
Mappers afstemmen
Hadoop probeert één bestand op te splitsen (toewijzen) in meerdere bestanden en de resulterende bestanden parallel te verwerken. Het aantal mappers is afhankelijk van het aantal splitsingen. Met de volgende twee configuratieparameters wordt het aantal splitsingen voor de Tez-uitvoeringsengine bepaald:
tez.grouping.min-size: Ondergrens voor de grootte van een gegroepeerde splitsing, met een standaardwaarde van 16 MB (16.777.216 bytes).tez.grouping.max-size: Bovengrens voor de grootte van een gegroepeerde splitsing, met een standaardwaarde van 1 GB (1.073.741.824 bytes).
Als prestatierichtlijn verlaagt u beide parameters om de latentie te verbeteren, verhoogt u de doorvoer voor meer doorvoer.
Als u bijvoorbeeld vier toewijzingstaken wilt instellen voor een gegevensgrootte van 128 MB, stelt u beide parameters in op elk 32 MB (33.554.432 bytes).
Als u de limietparameters wilt wijzigen, gaat u naar het tabblad Configuraties van de Tez-service. Vouw het deelvenster Algemeen uit en zoek de
tez.grouping.max-sizeentez.grouping.min-sizeparameters.Stel beide parameters in op 33.554.432 bytes (32 MB).

Deze wijzigingen zijn van invloed op alle Tez-taken op de server. Als u een optimaal resultaat wilt krijgen, kiest u de juiste parameterwaarden.
Reducers afstemmen
Apache ORC en Snappy bieden beide hoge prestaties. Hive kan echter standaard te weinig reducers hebben, wat knelpunten veroorzaakt.
Stel dat u een invoergegevensgrootte van 50 GB hebt. Deze gegevens in ORC-indeling met Snappy-compressie zijn 1 GB. Hive schat het aantal reducers dat nodig is als: (aantal bytes invoer aan mappers / hive.exec.reducers.bytes.per.reducer).
Met de standaardinstellingen is dit voorbeeld vier reducers.
De hive.exec.reducers.bytes.per.reducer parameter geeft het aantal bytes op dat per reducer wordt verwerkt. De standaardwaarde is 64 MB. Het afstemmen van deze waarde verhoogt parallelle uitvoering en kan de prestaties verbeteren. Het afstemmen ervan kan ook te veel reducers produceren, mogelijk nadelig voor de prestaties. Deze parameter is gebaseerd op uw specifieke gegevensvereisten, compressie-instellingen en andere omgevingsfactoren.
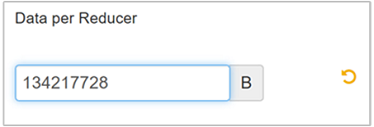
Als u de parameter wilt wijzigen, gaat u naar het tabblad Hive-configuraties en zoekt u de parameter Data per Reducer op de pagina Instellingen.
Selecteer Bewerken om de waarde te wijzigen in 128 MB (134.217.728 bytes) en druk op Enter om op te slaan.
Gezien een invoergrootte van 1024 MB, met 128 MB aan gegevens per reducer, zijn er acht reducers (1024/128).
Een onjuiste waarde voor de parameter Data per Reducer kan leiden tot een groot aantal reducers, wat de queryprestaties nadelig beïnvloedt. Als u het maximum aantal reducers wilt beperken, stelt u deze in
hive.exec.reducers.maxop een geschikte waarde. De standaardwaarde is 1009.
Parallelle uitvoering inschakelen
Een Hive-query wordt uitgevoerd in een of meer fasen. Als de onafhankelijke fasen parallel kunnen worden uitgevoerd, zal dit de queryprestaties verbeteren.
Als u parallelle uitvoering van query's wilt inschakelen, gaat u naar het tabblad Hive Config en zoekt u naar de
hive.exec.paralleleigenschap. De standaardwaarde is false. Wijzig de waarde in waar en druk op Enter om de waarde op te slaan.Als u het aantal taken dat parallel moet worden uitgevoerd, wilt beperken, wijzigt u de
hive.exec.parallel.thread.numbereigenschap. De standaardwaarde is 8.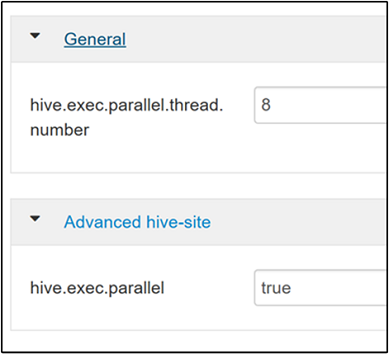
Vectorisatie inschakelen
Hive verwerkt gegevensrij per rij. Vectorization leidt Hive om gegevens te verwerken in blokken van 1024 rijen in plaats van één rij tegelijk. Vectorisatie is alleen van toepassing op de ORC-bestandsindeling.
Als u een gevectoriseerde queryuitvoering wilt inschakelen, gaat u naar het tabblad Hive-configuraties en zoekt u naar de
hive.vectorized.execution.enabledparameter. De standaardwaarde is waar voor Hive 0.13.0 of hoger.Als u gevectoriseerde uitvoering wilt inschakelen voor de reductiezijde van de query, stelt u de
hive.vectorized.execution.reduce.enabledparameter in op true. De standaardwaarde is false.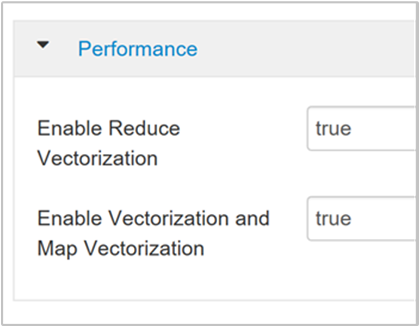
Optimalisatie op basis van kosten inschakelen (CBO)
Hive volgt standaard een set regels om één optimaal queryuitvoeringsplan te vinden. Optimalisatie op basis van kosten (CBO) evalueert meerdere plannen om een query uit te voeren. En wijst een kosten toe aan elk abonnement en bepaalt vervolgens het goedkoopste plan om een query uit te voeren.
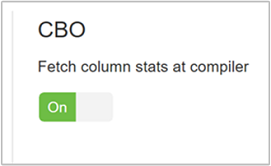
Als u CBO wilt inschakelen, gaat u naar Hive-configuraties>> Instellingen en zoekt u Enable Cost Based Optimizer en schakelt u vervolgens de wisselknop in op Aan.

De volgende aanvullende configuratieparameters verhogen de Hive-queryprestaties wanneer CBO is ingeschakeld:
hive.compute.query.using.statsAls deze is ingesteld op waar, gebruikt Hive statistieken die zijn opgeslagen in de metastore om eenvoudige query's zoals
count(*)te beantwoorden.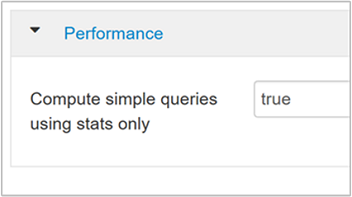
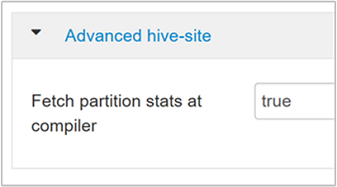
hive.stats.fetch.column.statsKolomstatistieken worden gemaakt wanneer CBO is ingeschakeld. Hive maakt gebruik van kolomstatistieken, die zijn opgeslagen in metastore, om query's te optimaliseren. Het ophalen van kolomstatistieken voor elke kolom duurt langer wanneer het aantal kolommen hoog is. Als deze instelling is ingesteld op false, wordt het ophalen van kolomstatistieken uit de metastore uitgeschakeld.
hive.stats.fetch.partition.statsBasispartitiestatistieken, zoals het aantal rijen, de gegevensgrootte en de bestandsgrootte, worden opgeslagen in metastore. Als deze optie is ingesteld op true, worden de partitiestatistieken opgehaald uit metastore. Als dit onwaar is, wordt de bestandsgrootte opgehaald uit het bestandssysteem. En het aantal rijen wordt opgehaald uit het rijschema.
Raadpleeg het blogbericht op basis van Hive Cost Based Optimization in Analytics op Azure Blog voor meer informatie
Tussenliggende compressie inschakelen
Toewijzingstaken maken tussenliggende bestanden die worden gebruikt door de reducer-taken. Tussenliggende compressie verkleint de tussenliggende bestandsgrootte.
Hadoop-taken zijn meestal Knelpunten in I/O. Het comprimeren van gegevens kan I/O en de algehele netwerkoverdracht versnellen.
De beschikbare compressietypen zijn:
| Indeling | Hulpprogramma | Algoritme | Bestandsextensie | Splitsbaar? |
|---|---|---|---|---|
| Gzip | Gzip | DEFLATE | .gz |
Nee |
| Bzip2 | Bzip2 | Bzip2 | .bz2 |
Ja |
| LZO | Lzop |
LZO | .lzo |
Ja, indien geïndexeerd |
| Snappy | N.v.t. | Snappy | Snappy | Nee |
Over het algemeen is het belangrijk om de compressiemethode te splitsen, anders worden er maar weinig mappers gemaakt. Als de invoergegevens tekst zijn, bzip2 is dit de beste optie. Voor ORC-indeling is Snappy de snelste compressieoptie.
Als u tussenliggende compressie wilt inschakelen, gaat u naar het tabblad Hive-configuraties en stelt u de
hive.exec.compress.intermediateparameter in op true. De standaardwaarde is false.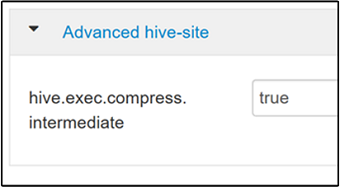
Notitie
Als u tussenliggende bestanden wilt comprimeren, kiest u een compressiecodec met lagere CPU-kosten, zelfs als de codec geen hoge compressie-uitvoer heeft.
Als u de tussenliggende compressiecodec wilt instellen, voegt u de aangepaste eigenschap
mapred.map.output.compression.codectoe aan hethive-site.xmlofmapred-site.xmlbestand.Een aangepaste instelling toevoegen:
a. Navigeer naar Hive>Configs>Advanced>Custom Hive-site.
b. Selecteer Eigenschap toevoegen... onderaan het deelvenster Aangepaste hive-site.
c. Voer
mapred.map.output.compression.codecin het venster Eigenschap toevoegen de sleutel enorg.apache.hadoop.io.compress.SnappyCodecals de waarde in.d. Selecteer Toevoegen.
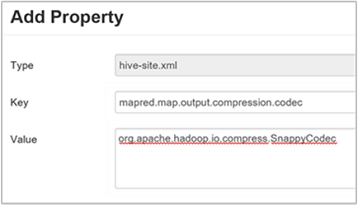
Met deze instelling wordt het tussenliggende bestand gecomprimeerd met snappy-compressie. Zodra de eigenschap is toegevoegd, wordt deze weergegeven in het deelvenster Aangepaste hive-site.
Notitie
Met deze procedure wordt het
$HADOOP_HOME/conf/hive-site.xmlbestand gewijzigd.
Uiteindelijke uitvoer comprimeren
De uiteindelijke Hive-uitvoer kan ook worden gecomprimeerd.
Als u de uiteindelijke Hive-uitvoer wilt comprimeren, gaat u naar het tabblad Hive-configuraties en stelt u de
hive.exec.compress.outputparameter in op true. De standaardwaarde is false.Als u de codec voor uitvoercompressie wilt kiezen, voegt u de
mapred.output.compression.codecaangepaste eigenschap toe aan het deelvenster Aangepaste hive-site, zoals beschreven in stap 3 van de vorige sectie.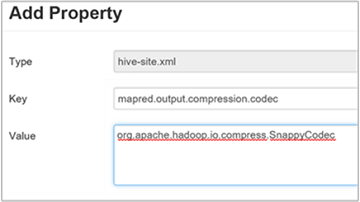
Speculatieve uitvoering inschakelen
Speculatieve uitvoering start een bepaald aantal dubbele taken om de traag uitgevoerde taaktracker te detecteren en te weigeren. Terwijl u de algehele taakuitvoering verbetert door afzonderlijke taakresultaten te optimaliseren.
Speculatieve uitvoering mag niet worden ingeschakeld voor langlopende MapReduce-taken met grote hoeveelheden invoer.
Als u speculatieve uitvoering wilt inschakelen, gaat u naar het tabblad Hive-configuraties en stelt u de
hive.mapred.reduce.tasks.speculative.executionparameter in op waar. De standaardwaarde is false.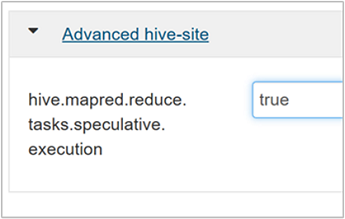
Dynamische partities afstemmen
Met Hive kunnen dynamische partities worden gemaakt bij het invoegen van records in een tabel, zonder dat elke partitie vooraf wordt gedefinieerd. Deze mogelijkheid is een krachtige functie. Hoewel dit kan leiden tot het maken van een groot aantal partities. En een groot aantal bestanden voor elke partitie.
Voor Hive om dynamische partities uit te voeren, moet de
hive.exec.dynamic.partitionparameterwaarde waar zijn (de standaardwaarde).Wijzig de dynamische partitiemodus in strikt. In de strikte modus moet ten minste één partitie statisch zijn. Met deze instelling voorkomt u query's zonder partitiefilter in de WHERE-component, dat wil gezegd, strikt voorkomt u query's die alle partities scannen. Navigeer naar het tabblad Hive-configuraties en stel deze in op
hive.exec.dynamic.partition.modestrikt. De standaardwaarde is niet ingewikkeld.Als u het aantal dynamische partities wilt beperken dat moet worden gemaakt, wijzigt u de
hive.exec.max.dynamic.partitionsparameter. De standaardwaarde is 5000.Als u het totale aantal dynamische partities per knooppunt wilt beperken, wijzigt
hive.exec.max.dynamic.partitions.pernodeu . De standaardwaarde is 2000.
Lokale modus inschakelen
Met de lokale modus kan Hive alle taken van een taak op één computer uitvoeren. Of soms in één proces. Deze instelling verbetert de queryprestaties als de invoergegevens klein zijn. En de overhead van het starten van taken voor query's verbruikt een aanzienlijk percentage van de algehele uitvoering van query's.
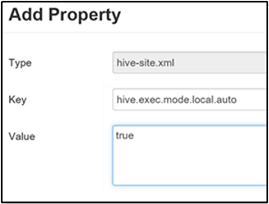
Als u de lokale modus wilt inschakelen, voegt u de hive.exec.mode.local.auto parameter toe aan het deelvenster Aangepaste hive-site, zoals wordt uitgelegd in stap 3 van de sectie Tussenliggende compressie inschakelen.
Eén MapReduce MultiGROUP BY instellen
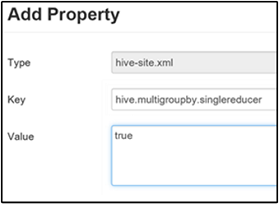
Wanneer deze eigenschap is ingesteld op true, genereert een MultiGROUP BY-query met algemene group-by-sleutels één MapReduce-taak.
Als u dit gedrag wilt inschakelen, voegt u de hive.multigroupby.singlereducer parameter toe aan het deelvenster Aangepaste hive-site, zoals wordt uitgelegd in stap 3 van de sectie Tussenliggende compressie inschakelen.
Aanvullende Hive-optimalisaties
In de volgende secties worden aanvullende Hive-gerelateerde optimalisaties beschreven die u kunt instellen.
Join-optimalisaties
Het standaard jointype in Hive is een shuffle join. In Hive lezen speciale mappers de invoer en verzenden een joinsleutel/waardepaar naar een tussenliggend bestand. Hadoop sorteert en voegt deze paren samen in een willekeurige fase. Deze willekeurige fase is duur. Als u de juiste join selecteert op basis van uw gegevens, kunt u de prestaties aanzienlijk verbeteren.
| Jointype | Wanneer | Hoe | Hive-instellingen | Opmerkingen |
|---|---|---|---|---|
| Join in willekeurige volgorde |
|
|
Er is geen significante Hive-instelling nodig | Werkt elke keer |
| Kaartdeelname |
|
|
hive.auto.convert.join=true |
Snel, maar beperkt |
| Samenvoegingsbucket sorteren | Als beide tabellen zijn:
|
Elk proces:
|
hive.auto.convert.sortmerge.join=true |
Efficiënt |
Optimalisaties van uitvoeringsengines
Aanvullende aanbevelingen voor het optimaliseren van de Hive-uitvoeringsengine:
| Instelling | Aanbevolen | HDInsight-standaard |
|---|---|---|
hive.mapjoin.hybridgrace.hashtable |
True = veiliger, langzamer; false = sneller | false |
tez.am.resource.memory.mb |
4 GB bovengrens voor de meeste | Automatisch afgestemd |
tez.session.am.dag.submit.timeout.secs |
300+ | 300 |
tez.am.container.idle.release-timeout-min.millis |
20000+ | 10000 |
tez.am.container.idle.release-timeout-max.millis |
40000+ | 20000 |