Apache Oozie gebruiken met Apache Hadoop voor het definiëren en uitvoeren van een werkstroom in Azure HDInsight op basis van Linux
Meer informatie over het gebruik van Apache Oozie met Apache Hadoop in Azure HDInsight. Oozie is een werkstroom- en coördinatiesysteem dat Hadoop-taken beheert. Oozie is geïntegreerd met de Hadoop-stack en ondersteunt de volgende taken:
- Apache Hadoop MapReduce
- Apache Pig
- Apache Hive
- Apache Sqoop
U kunt Oozie ook gebruiken om taken te plannen die specifiek zijn voor een systeem, zoals Java-programma's of shellscripts.
Notitie
Een andere optie voor het definiëren van werkstromen met HDInsight is het gebruik van Azure Data Factory. Zie Apache Pig en Apache Hive gebruiken met Data Factory voor meer informatie over Data Factory. Als u Oozie wilt gebruiken op clusters met Enterprise Security Package, raadpleegt u Apache Oozie uitvoeren in HDInsight Hadoop-clusters met Enterprise Security Package.
Vereisten
Een Hadoop-cluster in HDInsight. Zie Aan de slag met HDInsight in Linux.
Een SSH-client. Zie Verbinding maken met HDInsight (Apache Hadoop) met behulp van SSH.
Een Azure SQL Database. Zie Een database maken in Azure SQL Database in Azure Portal. In dit artikel wordt een database met de naam oozietest gebruikt.
Het URI-schema voor de primaire opslag voor uw clusters.
wasb://voor Azure Storage,abfs://voor Azure Data Lake Storage Gen2 ofadl://voor Azure Data Lake Storage Gen1. Als beveiligde overdracht is ingeschakeld voor Azure Storage, wordt de URIwasbs://. Zie ook beveiligde overdracht.
Voorbeeldwerkstroom
De werkstroom die in dit document wordt gebruikt, bevat twee acties. Acties zijn definities voor taken, zoals het uitvoeren van Hive, Sqoop, MapReduce of andere processen:
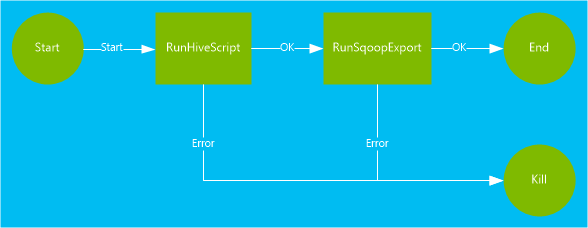
Een Hive-actie voert een HiveQL-script uit om records te extraheren uit de
hivesampletablerecords die zijn opgenomen in HDInsight. Elke rij met gegevens beschrijft een bezoek vanaf een specifiek mobiel apparaat. De recordindeling wordt weergegeven als de volgende tekst:8 18:54:20 en-US Android Samsung SCH-i500 California United States 13.9204007 0 0 23 19:19:44 en-US Android HTC Incredible Pennsylvania United States NULL 0 0 23 19:19:46 en-US Android HTC Incredible Pennsylvania United States 1.4757422 0 1Het Hive-script dat in dit document wordt gebruikt, telt het totale aantal bezoeken voor elk platform, zoals Android of iPhone, en slaat de aantallen op in een nieuwe Hive-tabel.
Zie [Apache Hive gebruiken met HDInsight][hdinsight-use-hive] voor meer informatie over Hive.
Met een Sqoop-actie wordt de inhoud van de nieuwe Hive-tabel geëxporteerd naar een tabel die is gemaakt in Azure SQL Database. Zie Apache Sqoop gebruiken met HDInsight voor meer informatie over Sqoop.
Notitie
De werkmap maken
Oozie verwacht dat u alle benodigde resources voor een taak in dezelfde map opslaat. In dit voorbeeld wordt wasbs:///tutorials/useoozie gebruikt. Voer de volgende stappen uit om deze map te maken:
Bewerk de onderstaande code om te vervangen door
sshuserde SSH-gebruikersnaam voor het cluster en vervang deze doorCLUSTERNAMEde naam van het cluster. Voer vervolgens de code in om verbinding te maken met het HDInsight-cluster met behulp van SSH.ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netGebruik de volgende opdracht om de map te maken:
hdfs dfs -mkdir -p /tutorials/useoozie/dataNotitie
De
-pparameter zorgt ervoor dat alle mappen in het pad worden gemaakt. Dedatamap wordt gebruikt voor het opslaan van de gegevens die door hetuseooziewf.hqlscript worden gebruikt.Bewerk de onderstaande code om deze te vervangen door
sshuseruw SSH-gebruikersnaam. Gebruik de volgende opdracht om ervoor te zorgen dat Oozie uw gebruikersaccount kan imiteren:sudo adduser sshuser usersNotitie
U kunt fouten negeren die aangeven dat de gebruiker al lid is van de
usersgroep.
Een databasestuurprogramma toevoegen
Deze werkstroom maakt gebruik van Sqoop om gegevens te exporteren naar de SQL-database. U moet dus een kopie opgeven van het JDBC-stuurprogramma dat wordt gebruikt voor interactie met de SQL-database. Gebruik de volgende opdracht uit de SSH-sessie om het JDBC-stuurprogramma naar de werkmap te kopiëren:
hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /tutorials/useoozie/
Belangrijk
Controleer het werkelijke JDBC-stuurprogramma dat bestaat op /usr/share/java/.
Als uw werkstroom andere resources heeft gebruikt, zoals een JAR die een MapReduce-toepassing bevat, moet u deze resources ook toevoegen.
De Hive-query definiëren
Gebruik de volgende stappen om een Hive-querytaal (HiveQL)-script te maken waarmee een query wordt gedefinieerd. U gebruikt de query in een Oozie-werkstroom verderop in dit document.
Gebruik vanuit de SSH-verbinding de volgende opdracht om een bestand met de naam
useooziewf.hqlte maken:nano useooziewf.hqlNadat de GNU nano-editor is geopend, gebruikt u de volgende query als de inhoud van het bestand:
DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName}(deviceplatform string, count string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT deviceplatform, COUNT(*) as count FROM hivesampletable GROUP BY deviceplatform;Er worden twee variabelen gebruikt in het script:
${hiveTableName}: Bevat de naam van de tabel die moet worden gemaakt.${hiveDataFolder}: Bevat de locatie voor het opslaan van de gegevensbestanden voor de tabel.Het werkstroomdefinitiebestand, workflow.xml in dit artikel, geeft deze waarden tijdens runtime door aan dit HiveQL-script.
Als u het bestand wilt opslaan, selecteert u Ctrl+X, voert u Y in en selecteert u Enter.
Gebruik de volgende opdracht om te kopiëren
useooziewf.hqlnaarwasbs:///tutorials/useoozie/useooziewf.hql:hdfs dfs -put useooziewf.hql /tutorials/useoozie/useooziewf.hqlMet deze opdracht wordt het
useooziewf.hqlbestand opgeslagen in de HDFS-compatibele opslag voor het cluster.
De werkstroom definiëren
Oozie-werkstroomdefinities worden geschreven in Hadoop Process Definition Language (hPDL), een XML-procesdefinitietaal. Gebruik de volgende stappen om de werkstroom te definiëren:
Gebruik de volgende instructie om een nieuw bestand te maken en te bewerken:
nano workflow.xmlNadat de nano-editor is geopend, voert u de volgende XML in als bestandsinhoud:
<workflow-app name="useooziewf" xmlns="uri:oozie:workflow:0.2"> <start to = "RunHiveScript"/> <action name="RunHiveScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScript}</script> <param>hiveTableName=${hiveTableName}</param> <param>hiveDataFolder=${hiveDataFolder}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>Er zijn twee acties gedefinieerd in de werkstroom:
RunHiveScript: Deze actie is de startactie en voert hetuseooziewf.hqlHive-script uit.RunSqoopExport: Met deze actie exporteert u de gegevens die zijn gemaakt van het Hive-script naar een SQL-database met behulp van Sqoop. Deze actie wordt alleen uitgevoerd als deRunHiveScriptactie is geslaagd.De werkstroom heeft verschillende vermeldingen, zoals
${jobTracker}. U vervangt deze vermeldingen door de waarden die u in de taakdefinitie gebruikt. Verderop in dit document maakt u de taakdefinitie.Let ook op de
<archive>mssql-jdbc-7.0.0.jre8.jar</archive>vermelding in de sectie Sqoop. Deze vermelding geeft Oozie opdracht om dit archief beschikbaar te maken voor Sqoop wanneer deze actie wordt uitgevoerd.
Als u het bestand wilt opslaan, selecteert u Ctrl+X, voert u Y in en selecteert u Enter.
Gebruik de volgende opdracht om het
workflow.xmlbestand te kopiëren naar/tutorials/useoozie/workflow.xml:hdfs dfs -put workflow.xml /tutorials/useoozie/workflow.xml
Een tabel maken
Notitie
Er zijn veel manieren om verbinding te maken met SQL Database om een tabel te maken. In de volgende stappen wordt FreeTDS gebruikt vanuit het HDInsight-cluster.
Gebruik de volgende opdracht om FreeTDS te installeren op het HDInsight-cluster:
sudo apt-get --assume-yes install freetds-dev freetds-binBewerk de onderstaande code om te vervangen door
<serverName>de naam van uw logische SQL-server en<sqlLogin>door de serveraanmelding. Voer de opdracht in om verbinding te maken met de vereiste SQL-database. Voer het wachtwoord in bij de prompt.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestU ontvangt uitvoer zoals de volgende tekst:
locale is "en_US.UTF-8" locale charset is "UTF-8" using default charset "UTF-8" Default database being set to oozietest 1>Voer de volgende regels in bij de prompt
1>:CREATE TABLE [dbo].[mobiledata]( [deviceplatform] [nvarchar](50), [count] [bigint]) GO CREATE CLUSTERED INDEX mobiledata_clustered_index on mobiledata(deviceplatform) GOWanneer u de instructie
GOinvoert, worden de vorige instructies geëvalueerd. Met deze instructies maakt u een tabel met de naammobiledata, die wordt gebruikt door de werkstroom.Gebruik de volgende opdrachten om te controleren of de tabel is gemaakt:
SELECT * FROM information_schema.tables GOU ziet uitvoer zoals de volgende tekst:
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME TABLE_TYPE oozietest dbo mobiledata BASE TABLESluit het hulpprogramma tsql af door bij de prompt in te
1>voerenexit.
De taakdefinitie maken
In de taakdefinitie wordt beschreven waar u de workflow.xml kunt vinden. Ook wordt beschreven waar u andere bestanden vindt die door de werkstroom worden gebruikt, zoals useooziewf.hql. Daarnaast worden de waarden gedefinieerd voor eigenschappen die worden gebruikt in de werkstroom en de bijbehorende bestanden.
Gebruik de volgende opdracht om het volledige adres van de standaardopslag op te halen. Dit adres wordt gebruikt in het configuratiebestand dat u in de volgende stap maakt.
sed -n '/<name>fs.default/,/<\/value>/p' /etc/hadoop/conf/core-site.xmlDeze opdracht retourneert informatie zoals de volgende XML:
<name>fs.defaultFS</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value>Notitie
Als het HDInsight-cluster Azure Storage als standaardopslag gebruikt, begint de inhoud van het
<value>element metwasbs://. Als Azure Data Lake Storage Gen1 in plaats daarvan wordt gebruikt, begint het metadl://. Als Azure Data Lake Storage Gen2 wordt gebruikt, begint het metabfs://.Sla de inhoud van het
<value>element op, zoals in de volgende stappen wordt gebruikt.Bewerk de onderstaande XML als volgt:
Tijdelijke aanduidingswaarde Vervangen waarde wasbs://mycontainer@mystorageaccount.blob.core.windows.net Waarde ontvangen van stap 1. beheerder Uw aanmeldingsnaam voor het HDInsight-cluster als dit niet de beheerder is. serverName Azure SQL Database-servernaam. sqlLogin Azure SQL Database-serveraanmelding. sqlPassword Aanmeldingswachtwoord voor Azure SQL Database-server. <?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>nameNode</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value> </property> <property> <name>jobTracker</name> <value>headnodehost:8050</value> </property> <property> <name>queueName</name> <value>default</value> </property> <property> <name>oozie.use.system.libpath</name> <value>true</value> </property> <property> <name>hiveScript</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/useooziewf.hql</value> </property> <property> <name>hiveTableName</name> <value>mobilecount</value> </property> <property> <name>hiveDataFolder</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/data</value> </property> <property> <name>sqlDatabaseConnectionString</name> <value>"jdbc:sqlserver://serverName.database.windows.net;user=sqlLogin;password=sqlPassword;database=oozietest"</value> </property> <property> <name>sqlDatabaseTableName</name> <value>mobiledata</value> </property> <property> <name>user.name</name> <value>admin</value> </property> <property> <name>oozie.wf.application.path</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property> </configuration>De meeste informatie in dit bestand wordt gebruikt om de waarden te vullen die worden gebruikt in de workflow.xml- of ooziewf.hql-bestanden, zoals
${nameNode}. Als het pad eenwasbspad is, moet u het volledige pad gebruiken. Maak het niet kort tot alleenwasbs:///. Deoozie.wf.application.pathvermelding definieert waar het workflow.xml-bestand moet worden gevonden. Dit bestand bevat de werkstroom die door deze taak is uitgevoerd.Gebruik de volgende opdracht om de configuratie van de Oozie-taakdefinitie te maken:
nano job.xmlNadat de nano-editor is geopend, plakt u de bewerkte XML als de inhoud van het bestand.
Als u het bestand wilt opslaan, selecteert u Ctrl+X, voert u Y in en selecteert u Enter.
De taak verzenden en beheren
In de volgende stappen wordt de Oozie-opdracht gebruikt om Oozie-werkstromen in het cluster te verzenden en te beheren. De Oozie-opdracht is een vriendelijke interface via de Oozie REST API.
Belangrijk
Wanneer u de Oozie-opdracht gebruikt, moet u de FQDN gebruiken voor het HOOFDknooppunt van HDInsight. Deze FQDN is alleen toegankelijk vanuit het cluster of als het cluster zich in een virtueel Azure-netwerk bevindt, van andere machines in hetzelfde netwerk.
Gebruik de volgende opdracht om de URL naar de Oozie-service te verkrijgen:
sed -n '/<name>oozie.base.url/,/<\/value>/p' /etc/oozie/conf/oozie-site.xmlDit retourneert informatie zoals de volgende XML:
<name>oozie.base.url</name> <value>http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozie</value>Het
http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/ooziegedeelte is de URL die moet worden gebruikt met de Oozie-opdracht.Bewerk de code om de URL te vervangen door de URL die u eerder hebt ontvangen. Als u een omgevingsvariabele voor de URL wilt maken, gebruikt u het volgende, zodat u deze niet hoeft in te voeren voor elke opdracht:
export OOZIE_URL=http://HOSTNAMEt:11000/oozieGebruik de volgende code om de taak in te dienen:
oozie job -config job.xml -submitMet deze opdracht worden de taakgegevens geladen van
job.xmlen naar Oozie verzonden, maar wordt deze niet uitgevoerd.Nadat de opdracht is voltooid, moet deze bijvoorbeeld de id van de taak
0000005-150622124850154-oozie-oozi-Wretourneren. Deze id wordt gebruikt om de taak te beheren.Bewerk de onderstaande code om te vervangen door
<JOBID>de id die in de vorige stap is geretourneerd. Gebruik de volgende opdracht om de status van de taak weer te geven:oozie job -info <JOBID>Dit retourneert informatie zoals de volgende tekst:
Job ID : 0000005-150622124850154-oozie-oozi-W ------------------------------------------------------------------------------------------------------------------------------------ Workflow Name : useooziewf App Path : wasb:///tutorials/useoozie Status : PREP Run : 0 User : USERNAME Group : - Created : 2015-06-22 15:06 GMT Started : - Last Modified : 2015-06-22 15:06 GMT Ended : - CoordAction ID: - ------------------------------------------------------------------------------------------------------------------------------------Deze taak heeft de status
PREP. Deze status geeft aan dat de taak is gemaakt, maar niet is gestart.Bewerk de onderstaande code om te vervangen door
<JOBID>de id die eerder is geretourneerd. Gebruik de volgende opdracht om de taak te starten:oozie job -start <JOBID>Als u de status na deze opdracht controleert, heeft deze de status Actief en wordt er informatie geretourneerd voor de acties binnen de taak. Het voltooien van de taak duurt enkele minuten.
Bewerk de onderstaande code om te vervangen door
<serverName>uw servernaam en<sqlLogin>door de serveraanmelding. Nadat de taak is voltooid , kunt u controleren of de gegevens zijn gegenereerd en geëxporteerd naar de SQL-databasetabel met behulp van de volgende opdracht. Voer het wachtwoord in bij de prompt.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestVoer bij de
1>prompt de volgende query in:SELECT * FROM mobiledata GODe geretourneerde informatie lijkt op de volgende tekst:
deviceplatform count Android 31591 iPhone OS 22731 proprietary development 3 RIM OS 3464 Unknown 213 Windows Phone 1791 (6 rows affected)
Zie het opdrachtregelprogramma van Apache Oozie voor meer informatie over de Oozie-opdracht.
Oozie REST API
Met de Oozie REST API kunt u uw eigen hulpprogramma's bouwen die met Oozie werken. De volgende HDInsight-specifieke informatie over het gebruik van de Oozie REST API:
URI: U hebt toegang tot de REST API van buiten het cluster op
https://CLUSTERNAME.azurehdinsight.net/oozie.Verificatie: Gebruik de API voor het HTTP-clusteraccount (beheerder) en wachtwoord om te verifiëren. Voorbeeld:
curl -u admin:PASSWORD https://CLUSTERNAME.azurehdinsight.net/oozie/versions
Zie de Apache Oozie Web Services-API voor meer informatie over het gebruik van de Oozie REST API.
Oozie-webgebruikersinterface
De Oozie-webgebruikersinterface biedt een webweergave in de status van Oozie-taken in het cluster. Met de webgebruikersinterface kunt u de volgende informatie bekijken:
- Taakstatus
- Jobdefinitie
- Configuratie
- Een grafiek van de acties in de taak
- Logboeken voor de taak
U kunt ook de details van de acties in een taak bekijken.
Voer de volgende stappen uit om toegang te krijgen tot de webgebruikersinterface van Oozie:
Maak een SSH-tunnel naar het HDInsight-cluster. Zie SSH-tunneling gebruiken met HDInsight voor meer informatie.
Nadat u een tunnel hebt gemaakt, opent u de Ambari-webgebruikersinterface in uw webbrowser met behulp van URI
http://headnodehost:8080.Selecteer aan de linkerkant van de pagina Oozie>Quick Links>Oozie Web UI.
De webgebruikersinterface van Oozie geeft standaard de actieve werkstroomtaken weer. Als u alle werkstroomtaken wilt zien, selecteert u Alle taken.
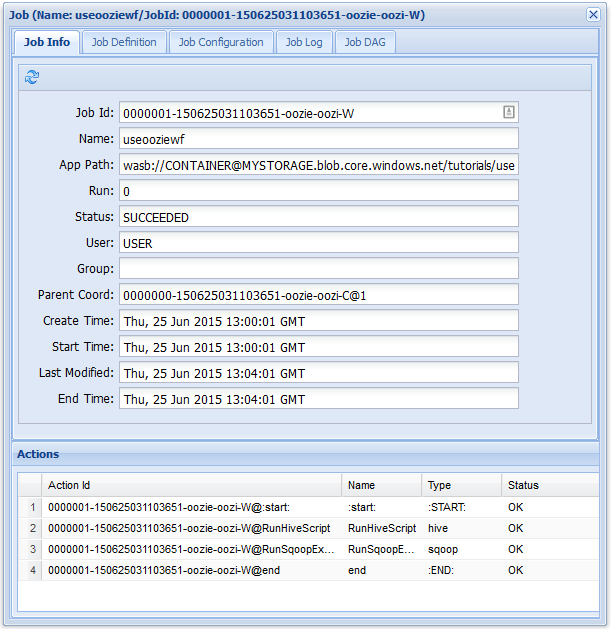
Als u meer informatie over een taak wilt weergeven, selecteert u de taak.
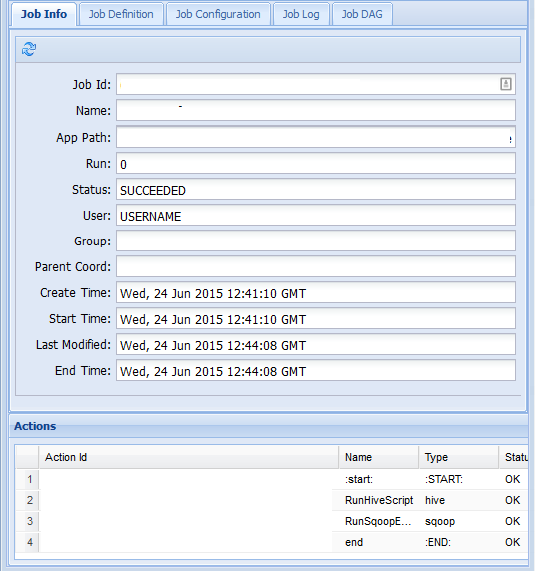
Op het tabblad Taakgegevens ziet u de basistaakgegevens en de afzonderlijke acties in de taak. U kunt de tabbladen bovenaan gebruiken om de taakdefinitie, taakconfiguratie, toegang te krijgen tot het taaklogboek of een gerichte acyclische grafiek (DAG) van de taak onder Taak DAG weer te geven.
Taaklogboek: selecteer de knop Logboeken ophalen om alle logboeken voor de taak op te halen of gebruik het
Enter Search Filterveld om de logboeken te filteren.
Job DAG: De DAG is een grafisch overzicht van de gegevenspaden die via de werkstroom worden genomen.
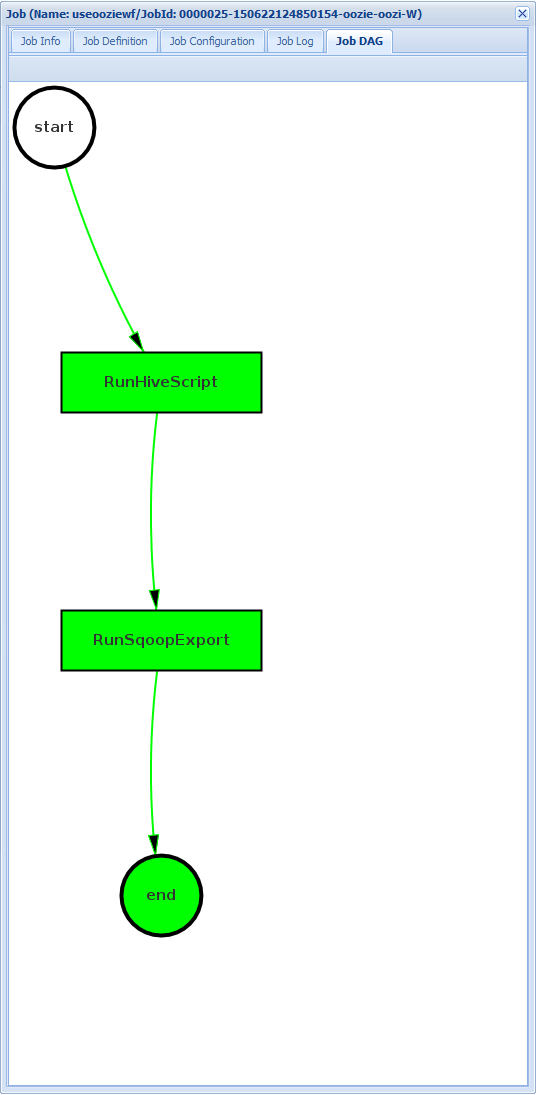
Als u een van de acties selecteert op het tabblad Taakgegevens , wordt informatie voor de actie weergegeven. Selecteer bijvoorbeeld de actie RunSqoopExport .
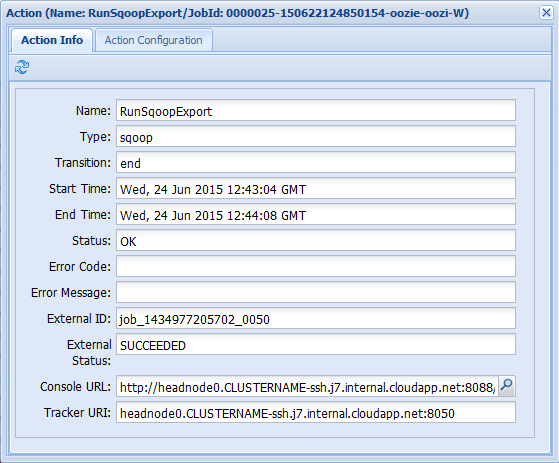
U kunt details voor de actie zien, zoals een koppeling naar de console-URL. Gebruik deze koppeling om informatie over taaktrackers voor de taak weer te geven.
Taken plannen
U kunt de coördinator gebruiken om een begin- en eindfrequentie voor taken op te geven. Voer de volgende stappen uit om een planning voor de werkstroom te definiëren:
Gebruik de volgende opdracht om een bestand met de naam coordinator.xml te maken:
nano coordinator.xmlGebruik de volgende XML als de inhoud van het bestand:
<coordinator-app name="my_coord_app" frequency="${coordFrequency}" start="${coordStart}" end="${coordEnd}" timezone="${coordTimezone}" xmlns="uri:oozie:coordinator:0.4"> <action> <workflow> <app-path>${workflowPath}</app-path> </workflow> </action> </coordinator-app>Notitie
De
${...}variabelen worden tijdens runtime vervangen door waarden in de taakdefinitie. De variabelen zijn:${coordFrequency}: De tijd tussen actieve exemplaren van de taak.${coordStart}: De begintijd van de taak.${coordEnd}: De eindtijd van de taak.${coordTimezone}: Coördinatortaken bevinden zich in een vaste tijdzone zonder zomertijd, meestal vertegenwoordigd door UTC. Deze tijdzone wordt de Oozie-verwerkingstijdzone genoemd.${wfPath}: Het pad naar de workflow.xml.
Als u het bestand wilt opslaan, selecteert u Ctrl+X, voert u Y in en selecteert u Enter.
Gebruik de volgende opdracht om het bestand naar de werkmap voor deze taak te kopiëren:
hadoop fs -put coordinator.xml /tutorials/useoozie/coordinator.xmlGebruik de volgende opdracht om het
job.xmlbestand dat u eerder hebt gemaakt te wijzigen:nano job.xmlBreng de volgende wijzigingen aan:
Als u Oozie wilt instrueren om het coördinatorbestand uit te voeren in plaats van de werkstroom, gaat u naar
<name>oozie.wf.application.path</name><name>oozie.coord.application.path</name>.Als u de
workflowPathvariabele wilt instellen die door de coördinator wordt gebruikt, voegt u de volgende XML toe:<property> <name>workflowPath</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property>Vervang de
wasbs://mycontainer@mystorageaccount.blob.core.windowstekst door de waarde die wordt gebruikt in de andere vermeldingen in het bestand job.xml.Als u het begin, einde en de frequentie voor de coördinator wilt definiëren, voegt u de volgende XML toe:
<property> <name>coordStart</name> <value>2018-05-10T12:00Z</value> </property> <property> <name>coordEnd</name> <value>2018-05-12T12:00Z</value> </property> <property> <name>coordFrequency</name> <value>1440</value> </property> <property> <name>coordTimezone</name> <value>UTC</value> </property>Met deze waarden wordt de begintijd ingesteld op 12:00 uur op 10 mei 2018 en de eindtijd op 12 mei 2018. Het interval voor het uitvoeren van deze taak is ingesteld op dagelijks. De frequentie is in minuten, dus 24 uur x 60 minuten = 1440 minuten. Ten slotte is de tijdzone ingesteld op UTC.
Als u het bestand wilt opslaan, selecteert u Ctrl+X, voert u Y in en selecteert u Enter.
Gebruik de volgende opdracht om de taak in te dienen en te starten:
oozie job -config job.xml -runAls u naar de webgebruikersinterface van Oozie gaat en het tabblad Coördinatortaken selecteert, ziet u informatie zoals in de volgende afbeelding:

De vermelding Volgende materialisatie bevat de volgende keer dat de taak wordt uitgevoerd.
Net als bij de eerdere werkstroomtaak, als u de taakvermelding in de webgebruikersinterface selecteert, wordt informatie over de taak weergegeven:
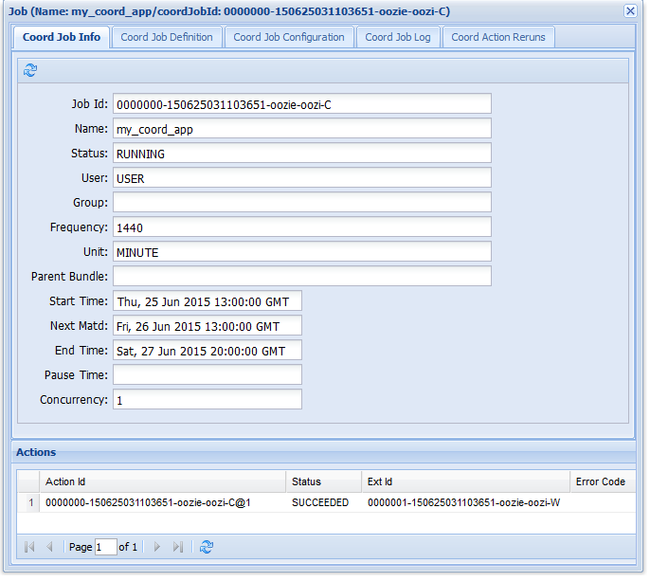
Notitie
In deze afbeelding worden alleen geslaagde uitvoeringen van de taak weergegeven, niet de afzonderlijke acties in de geplande werkstroom. Als u de afzonderlijke acties wilt zien, selecteert u een van de actie-vermeldingen .
Volgende stappen
In dit artikel hebt u geleerd hoe u een Oozie-werkstroom definieert en hoe u een Oozie-taak uitvoert. Zie de volgende artikelen voor meer informatie over het werken met HDInsight: