Zelfstudie: Apache HBase gebruiken in Azure HDInsight
In deze zelfstudie ziet u hoe u een Apache HBase-cluster maakt in Azure HDInsight, HBase-tabellen maakt en query’s uitvoert op tabellen met behulp van Apache Hive. Zie Overzicht van HDInsight HBase voor algemene informatie over HBase.
In deze zelfstudie leert u het volgende:
- Een Apache HBase-cluster maken
- HBase-tabellen maken en gegevens invoegen
- Query’s uitvoeren op Apache HBase met Apache Hive
- HBase REST API's gebruiken met Curl
- De clusterstatus controleren
Vereisten
Een SSH-client. Zie voor meer informatie Verbinding maken met HDInsight (Apache Hadoop) via SSH.
Bash. In de voorbeelden in dit artikel wordt gebruikgemaakt van de Bash-shell in Windows 10 voor de cURL-opdrachten. Zie Installatiehandleiding voor Windows 10 voor Windows-subsysteem voor Linux voor installatiestappen. Andere Unix-shells werken ook. De cURL-voorbeelden kunnen, met enige aanpassingen, worden gebruikt in een Windows-opdrachtprompt. U kunt ook de Windows PowerShell-cmdlet Invoke-RestMethod gebruiken.
Een Apache HBase-cluster maken
In de volgende procedure wordt een Azure Resource Manager-sjabloon gebruikt om een HBase-cluster te maken. Met de sjabloon wordt ook het afhankelijke standaard Azure Storage-account gemaakt. Zie Op Linux gebaseerde Hadoop-clusters maken in HDInsight voor meer inzicht in de parameters die voor deze procedure worden gebruikt en andere methoden voor het maken van clusters.
Selecteer de volgende afbeelding om de sjabloon in Azure Portal te openen. De sjabloon bevindt zich in Azure Quickstart-sjablonen.

Voer in het dialoogvenster Aangepaste implementatie de volgende waarden in:
Eigenschappen Beschrijving Abonnement Selecteer het Azure-abonnement dat wordt gebruikt om het cluster te maken. Resourcegroep Maak een Azure-resourcebeheergroep of gebruik een bestaande. Locatie Geef de locatie van de resourcegroep op. Clusternaam Voer een naam in voor het HBase-cluster. Gebruikersnaam en wachtwoord voor aanmelding bij cluster De standaardaanmeldingsnaam is admin.SSH-gebruikersnaam en SSH-wachtwoord De standaardgebruikersnaam is sshuser.Andere parameters zijn optioneel.
Elk cluster is afhankelijk van een Azure Storage-account. Nadat u een cluster hebt verwijderd, blijven de gegevens in het opslagaccount. De naam van het standaardopslagaccount voor het cluster is de naam waaraan 'store' is toegevoegd. Deze is vastgelegd in de sectie met sjabloonvariabelen.
Selecteer Ik ga akkoord met de bovenstaande voorwaarden en selecteer vervolgens Kopen. Het duurt ongeveer 20 minuten om een cluster te maken.
Nadat een HBase-cluster is verwijderd, kunt u een ander HBase-cluster maken met behulp van dezelfde standaard-blobcontainer. Het nieuwe cluster haalt de HBase-tabellen op die u hebt gemaakt in het oorspronkelijke cluster. Om inconsistenties te voorkomen, wordt u aangeraden de HBase-tabellen uit te schakelen voordat u het cluster verwijdert.
Tabellen maken en gegevens invoegen
U kunt SSH gebruiken om verbinding te maken met HBase-clusters en vervolgens Apache HBase Shell gebruiken om HBase-tabellen te maken, gegevens in te voegen, en gegevens te doorzoeken.
Voor de meeste mensen worden de gegevens weergegeven in een tabelindeling:

In HBase (een implementatie van Cloud BigTable) zien dezelfde gegevens er als volgt uit:

De HBase-shell gebruiken
Gebruik de opdracht
sshom verbinding te maken met uw HBase-cluster. Bewerk de volgende opdracht door de naam van uw cluster te vervangenCLUSTERNAMEen voer vervolgens de opdracht in:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netGebruik de opdracht
hbase shellom de interactieve HBase-shell te starten. Voer de volgende opdracht in uw SSH-verbinding in:hbase shellGebruik
createde opdracht om een HBase-tabel met twee kolomfamilies te maken. De tabel- en kolomnamen zijn hoofdlettergevoelig. Voer de volgende opdracht in:create 'Contacts', 'Personal', 'Office'Gebruik de opdracht
listom alle tabellen in HBase weer te geven. Voer de volgende opdracht in:listGebruik de opdracht
putom in een opgegeven rij in een bepaalde tabel waarden in te voegen voor een opgegeven kolom. Voer de volgende opdrachten in:put 'Contacts', '1000', 'Personal:Name', 'John Dole' put 'Contacts', '1000', 'Personal:Phone', '1-425-000-0001' put 'Contacts', '1000', 'Office:Phone', '1-425-000-0002' put 'Contacts', '1000', 'Office:Address', '1111 San Gabriel Dr.'Gebruik de opdracht
scanom deContacts-tabelgegevens te scannen en te retourneren. Voer de volgende opdracht in:scan 'Contacts'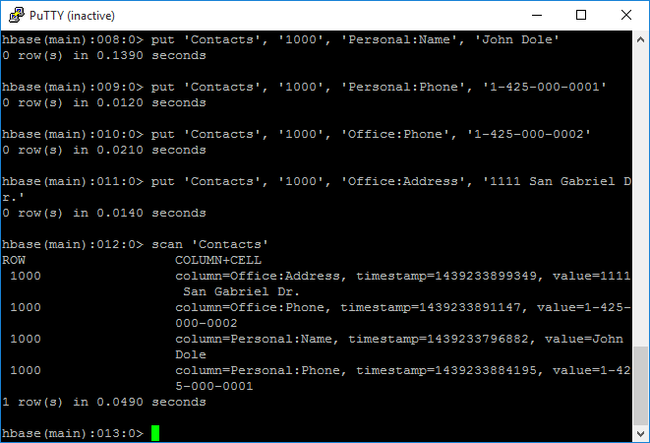
Gebruik de opdracht
getom de inhoud van een rij op te halen. Voer de volgende opdracht in:get 'Contacts', '1000'U ziet soortgelijke resultaten als bij de opdracht
scan, omdat er maar één rij is.Zie Inleiding tot het Apache HBase-schemaontwerp voor meer informatie over het HBase-tabelschema. Raadpleeg de Snelzoekgids voor Apache HBase voor meer HBase-opdrachten.
Gebruik de opdracht
exitom de interactieve HBase-shell te stoppen. Voer de volgende opdracht in:exit
Gegevens bulksgewijs laden in de HBase-tabel met contacten
U kunt in HBase verschillende methoden gebruiken om gegevens in tabellen te laden. Zie Bulk loading (Bulkgsgewijs laden) voor meer informatie.
Een voorbeeld van een gegevensbestand is te vinden in een openbare Blob-container, wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt. De inhoud van het gegevensbestand is:
8396 Calvin Raji 230-555-0191 230-555-0191 5415 San Gabriel Dr.
16600 Karen Wu 646-555-0113 230-555-0192 9265 La Paz
4324 Karl Xie 508-555-0163 230-555-0193 4912 La Vuelta
16891 Jonn Jackson 674-555-0110 230-555-0194 40 Ellis St.
3273 Miguel Miller 397-555-0155 230-555-0195 6696 Anchor Drive
3588 Osa Agbonile 592-555-0152 230-555-0196 1873 Lion Circle
10272 Julia Lee 870-555-0110 230-555-0197 3148 Rose Street
4868 Jose Hayes 599-555-0171 230-555-0198 793 Crawford Street
4761 Caleb Alexander 670-555-0141 230-555-0199 4775 Kentucky Dr.
16443 Terry Chander 998-555-0171 230-555-0200 771 Northridge Drive
U kunt een tekstbestand maken en het bestand desgewenst uploaden naar uw eigen opslagaccount. Zie Gegevens voor Apache Hadoop-taken in HDInsight uploaden voor instructies.
In deze procedure wordt gebruikgemaakt van de HBase-tabel Contacts die u in de laatste procedure hebt gemaakt.
Voer vanuit uw open SSH-verbinding de volgende opdracht uit om het gegevensbestand te transformeren naar StoreFiles en op te slaan naar een relatief pad dat is opgegeven door
Dimporttsv.bulk.output.hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Phone,Office:Phone,Office:Address" -Dimporttsv.bulk.output="/example/data/storeDataFileOutput" Contacts wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txtVoer de volgende opdracht uit om de gegevens uit
/example/data/storeDataFileOutputnaar de HBase-tabel te uploaden:hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/storeDataFileOutput ContactsU kunt de HBase-shell openen en de opdracht
scangebruiken om de tabelinhoud weer te geven.
Query’s uitvoeren op Apache HBase met Apache Hive
Met Apache Hive kunt u een query uitvoeren op de gegevens in HBase-tabellen. In dit gedeelte maakt u een Hive-tabel die is toegewezen aan de HBase-tabel en deze gebruikt om een query voor de gegevens in uw HBase-tabel uit te voeren.
Gebruik vanuit uw open SSH-verbinding de volgende opdracht om Beeline te starten:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n adminZie voor meer informatie over Beeline Hive gebruiken met Hadoop in HDInsight met Beeline.
Voer het volgende HiveQL-script uit om een Hive-tabel te maken die is toegewezen aan de HBase-tabel. Zorg ervoor dat u met de HBase-shell de voorbeeldtabel hebt gemaakt waarnaar eerder in dit artikel is verwezen voordat u deze instructie uitvoert.
CREATE EXTERNAL TABLE hbasecontacts(rowkey STRING, name STRING, homephone STRING, officephone STRING, officeaddress STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Phone,Office:Phone,Office:Address') TBLPROPERTIES ('hbase.table.name' = 'Contacts');Voer het volgende HiveQL-script uit om een query uit te voeren voor de gegevens in de HBase-tabel:
SELECT count(rowkey) AS rk_count FROM hbasecontacts;Gebruik
!exitom Beeline af te sluiten.Gebruik
exitom uw SSH-verbinding af te sluiten.
Afzonderlijke Hive- en Hbase-clusters
De Hive-query voor toegang tot HBase-gegevens hoeft niet te worden uitgevoerd vanuit het HBase-cluster. Elk cluster dat deel uitmaakt van Hive (inclusief Spark, Hadoop, HBase of Interactive Query) kan worden gebruikt voor het opvragen van HBase-gegevens, mits de volgende stappen worden uitgevoerd:
- Beide clusters moeten aan hetzelfde virtuele netwerk en subnet zijn gekoppeld
- Kopieer
/usr/hdp/$(hdp-select --version)/hbase/conf/hbase-site.xmlvan de hoofdknooppunten van het HBase-cluster naar de Hoofdknooppunten van het Hive-cluster en werkknooppunten.
Beveiligde clusters
HBase-gegevens kunnen ook worden opgevraagd uit Hive met behulp van HBase met ESP:
- Bij het volgen van een patroon met meerdere clusters moet op beide clusters ESP zijn ingeschakeld.
- Als u wilt dat Hive query's kan uitvoeren op HBase-gegevens, moet u ervoor zorgen dat de
hive-gebruiker machtigingen krijgt voor toegang tot de HBase-gegevens via de Hbase Apache Ranger-invoeg toepassing - Wanneer u afzonderlijke clusters met ESP gebruikt, moet de inhoud van de hoofdknooppunten van
/etc/hostshet HBase-cluster worden toegevoegd aan/etc/hostsde Hoofdknooppunten en werkknooppunten van het Hive-cluster.
Notitie
Nadat u clusters hebt geschaald, moet /etc/hosts opnieuw worden toegevoegd
De HBase REST API gebruiken via Curl
De HBase REST API wordt beveiligd via basisverificatie. U moet aanvragen altijd uitvoeren via een beveiligde HTTP-verbinding (HTTPS). Zo zorgt u ervoor dat uw referenties veilig worden verzonden naar de server.
Als u de HBase REST API in het HDInsight-cluster wilt inschakelen, voegt u het volgende aangepaste opstartscript toe aan de sectie Scriptactie . U kunt het opstartscript toevoegen tijdens het maken van het cluster of nadat het cluster is gemaakt. Selecteer Regioservers bij Knooppunttype om ervoor te zorgen dat het script alleen op HBase-regioservers wordt uitgevoerd. Script start de HBase REST-proxy op 8090-poort op regioservers.
#! /bin/bash THIS_MACHINE=`hostname` if [[ $THIS_MACHINE != wn* ]] then printf 'Script to be executed only on worker nodes' exit 0 fi RESULT=`pgrep -f RESTServer` if [[ -z $RESULT ]] then echo "Applying mitigation; starting REST Server" sudo python /usr/lib/python2.7/dist-packages/hdinsight_hbrest/HbaseRestAgent.py else echo "REST server already running" exit 0 fiStel voor het gemak de omgevingsvariabele in. Bewerk de volgende opdrachten door het aanmeldingswachtwoord voor het cluster te vervangen
MYPASSWORD. VervangMYCLUSTERNAMEdoor de naam van uw HBase-cluster. Voer daarna de opdrachten in.export PASSWORD='MYPASSWORD' export CLUSTER_NAME=MYCLUSTERNAMEGebruik de volgende opdracht om een lijst met bestaande HBase-tabellen weer te geven:
curl -u admin:$PASSWORD \ -G https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Gebruik de volgende opdracht om een nieuwe HBase-tabel met twee kolomfamilies te maken:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/schema" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"@name\":\"Contact1\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Office\"}]}" \ -vHet schema wordt geleverd in de JSON-indeling.
Gebruik de volgende opdracht om enkele gegevens in te voegen:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/false-row-key" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"Row\":[{\"key\":\"MTAwMA==\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"Sm9obiBEb2xl\"}]}]}" \ -vCodeer de waarden die in de schakeloptie -d zijn opgegeven met Base64. In het voorbeeld:
MTAwMA==: 1000
UGVyc29uYWw6TmFtZQ==: Persoonlijk: Naam
Sm9obiBEb2xl: Joep Davids
false-row-key maakt het mogelijk om meerdere waarden (in batch) in te voegen.
Gebruik de volgende opdracht om een rij te verkrijgen:
curl -u admin:$PASSWORD \ GET "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/1000" \ -H "Accept: application/json" \ -v
Notitie
Scannen via het clustereindpunt wordt nog niet ondersteund.
Zie Apache HBase Reference Guide (Snelzoekgids voor Apache HBase) voor meer informatie over HBase REST.
Notitie
Thrift wordt niet ondersteund door HBase in HDInsight.
Wanneer u Curl of andere REST-communicatie met WebHCat gebruikt, moet u de aanvragen verifiëren door de gebruikersnaam en het wachtwoord op te geven voor de HDInsight-clusterbeheerder. U moet ook de clusternaam gebruiken als onderdeel van de URI (Uniform Resource Identifier) die wordt gebruikt om de aanvragen naar de server te verzenden:
curl -u <UserName>:<Password> \
-G https://<ClusterName>.azurehdinsight.net/templeton/v1/status
Het antwoord dat u ontvangt, is vergelijkbaar met het volgende antwoord:
{"status":"ok","version":"v1"}
De clusterstatus controleren
HBase in HDInsight wordt geleverd met een webgebruikersinterface voor het bewaken van clusters. Met de webgebruikersinterface kunt u statistieken of informatie over regio's aanvragen.
De HBase-hoofdinterface openen
Meld u aan bij de Ambari-webgebruikersinterface op
https://CLUSTERNAME.azurehdinsight.net, waarbijCLUSTERNAMEde naam van uw HBase-cluster is.Selecteer HBase in het menu links.
Selecteer Snelkoppelingen boven aan de pagina, wijs de actieve Zookeeper-knooppuntkoppeling aan en selecteer vervolgens HBase Master UI. De interface wordt in een nieuw browsertabblad geopend:
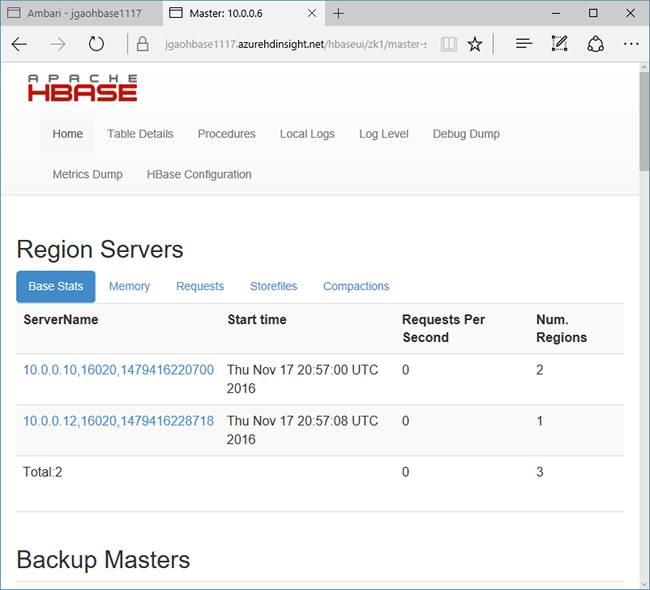
De HBase-hoofdinterface bevat de volgende onderdelen:
- regioservers
- back-upmasters
- tabellen
- taken
- softwarekenmerken
Clusterrecreatie
Nadat een HBase-cluster is verwijderd, kunt u een ander HBase-cluster maken met behulp van dezelfde standaard-blobcontainer. Het nieuwe cluster haalt de HBase-tabellen op die u hebt gemaakt in het oorspronkelijke cluster. Om inconsistenties te voorkomen, raden we u echter aan de HBase-tabellen uit te schakelen voordat u het cluster verwijdert.
U kunt de HBase-opdracht disable 'Contacts' gebruiken.
Resources opschonen
Als u deze toepassing verder niet meer gebruikt, verwijdert u het HBase-cluster dat u hebt gemaakt, via de volgende stappen:
- Meld u aan bij het Azure-portaal.
- Typ HDInsight in het Zoekvak bovenaan.
- Selecteer onder Services de optie HDInsight-clusters.
- Klik in de lijst met HDInsight-clusters die wordt weergegeven, op de ... naast het cluster dat u voor deze zelfstudie hebt gemaakt.
- Klik op Verwijderen. Klik op Ja.
Volgende stappen
In deze zelfstudie hebt u geleerd hoe u een Apache HBase-cluster maakt. En hoe u tabellen maakt en gegevens in deze tabellen weergeeft vanuit de HBase-shell. U hebt ook geleerd hoe u een Hive-query op gegevens in HBase-tabellen uitvoert. En hoe u de HBase C# REST API gebruikt om een HBase-tabel te maken en gegevens op te halen uit de tabel. Raadpleeg voor meer informatie: