Juli 2019
Deze functies en verbeteringen in het Azure Databricks-platform zijn uitgebracht in juli 2019.
Notitie
Releases worden gefaseerd. Uw Azure Databricks-account kan pas een week na de eerste releasedatum worden bijgewerkt.
Binnenkort beschikbaar: Databricks 6.0 biedt geen ondersteuning voor Python 2
In afwachting van de komende levensduur van Python 2, aangekondigd voor 2020, wordt Python 2 niet ondersteund in Databricks Runtime 6.0. Eerdere versies van Databricks Runtime blijven Python 2 ondersteunen. We verwachten dat Databricks Runtime 6.0 later in 2019 wordt uitgebracht.
Databricks Runtime-versie vooraf laden op inactieve instanties van groep
30 juli - 6 aug 2019: versie 2.103
U kunt nu de clusterlanceringen met poolsteun versnellen door een Databricks Runtime-versie te selecteren die moet worden geladen op niet-actieve exemplaren in de pool. Het veld in de poolgebruikersinterface heet vooraf geladen Spark-versie.

Aangepaste clustertags en groeptags werken beter samen
30 juli - 6 aug 2019: versie 2.103
Eerder deze maand introduceerde Azure Databricks pools, een set niet-actieve exemplaren waarmee u clusters snel kunt instellen. In de oorspronkelijke release hebben clusters met poolsteun de standaard- en aangepaste tags overgenomen van de poolconfiguratie en kunt u deze tags niet wijzigen op clusterniveau. U kunt nu aangepaste tags configureren die specifiek zijn voor een cluster met poolsteun en dat cluster past alle aangepaste tags toe, ongeacht of deze zijn overgenomen van de pool of specifiek aan dat cluster zijn toegewezen. U kunt geen clusterspecifieke aangepaste tag toevoegen met dezelfde sleutelnaam als een aangepaste tag die is overgenomen van een pool (u kunt dus geen aangepaste tag overschrijven die wordt overgenomen van de pool). Zie Pooltags voor meer informatie.
MLflow 1.1 biedt een aantal gebruikersinterface- en API-verbeteringen
30 juli - 6 aug 2019: versie 2.103
MLflow 1.1 introduceert verschillende nieuwe functies om de gebruikersinterface en API-bruikbaarheid te verbeteren:
Met de overzichtsgebruikersinterface voor uitvoeringen kunt u nu door meerdere pagina's met uitvoeringen bladeren als het aantal uitvoeringen groter is dan 100. Klik na de 100e uitvoering op de knop Meer laden om de volgende 100 uitvoeringen te laden.
De gebruikersinterface voor vergelijken voert nu een parallelle coördinatenplot uit. Met de plot kunt u relaties tussen een n-dimensionale set parameters en metrische gegevens observeren. nl-NL: Hiermee worden alle runs gevisualiseerd als lijnen die zijn gecodeerd met kleuren op basis van de metriekwaarde (bijvoorbeeld nauwkeurigheid) en worden de parameterwaarden weergegeven die elke uitvoering aannam.
U kunt nu tags toevoegen en bewerken vanuit de gebruikersinterface voor het uitvoeren van een overzicht en tags weergeven in de zoekweergave voor experimenten.
Met de nieuwe MLflowContext-API kunt u uitvoeringen maken en registreren op een manier die vergelijkbaar is met de Python-API. Deze API contrasteert met de bestaande API op laag niveau
MlflowClient, waarmee de REST API's eenvoudig worden verpakt.U kunt nu tags uit MLflow-uitvoeringen verwijderen met behulp van de DeleteTag-API.
Zie het blogbericht MLflow 1.1 voor meer informatie. Zie de MLflow Changelogvoor de volledige lijst met functies en oplossingen.
Pandas-DataFrame wordt weergegeven zoals in Jupyter
30 juli - 6 aug 2019: versie 2.103
Wanneer u nu een Pandas DataFrame aanroept, wordt het op dezelfde manier weergegeven als in Jupyter.
Nieuwe regio’s
30 juli 2019
Azure Databricks is nu beschikbaar in de volgende extra regio's:
- Korea - centraal
- Zuid-Afrika - noord
Bijgewerkte verbindingslimiet voor metastore
16 juli - 23 juli 2019: versie 2.102
Nieuwe Azure Databricks-werkruimten in eastus, eastus2, centralus, westus2, westeurope, northeurope hebben een hogere metastore-verbindingslimiet van 250. Bestaande werkruimten blijven de huidige metastore gebruiken zonder onderbreking en blijven een verbindingslimiet van 100 hebben.
Machtigingen instellen voor pools (openbare preview)
16 juli - 23 juli 2019: versie 2.102
De gebruikersinterface van de pool ondersteunt nu het instellen van machtigingen voor wie pools kan beheren en wie clusters aan pools kan koppelen.
Zie Groepsmachtigingen voor meer informatie.
Databricks Runtime 5.5 voor machine learning
15 juli 2019
Databricks Runtime 5.5 ML is gebaseerd op Databricks Runtime 5.5 LTS (EoS). Het bevat veel populaire machine learning-bibliotheken, waaronder TensorFlow, PyTorch, Keras en XGBoost, en biedt gedistribueerde TensorFlow-training met horovod.
Deze release bevat de volgende nieuwe functies en verbeteringen:
- Het Python-pakket MLflow 1.0 toegevoegd
- Bijgewerkte machine learning-bibliotheken
- TensorFlow bijgewerkt van 1.12.0 naar 1.13.1
- PyTorch bijgewerkt van 0.4.1 naar 1.1.0
- scikit-learn bijgewerkt van 0.19.1 naar 0.20.3
- Bewerking met één knooppunt voor HorovodRunner
Zie Databricks Runtime 5.5 LTS voor ML (EoS) voor meer informatie.
Databricks Runtime 5.5
15 juli 2019
Databricks Runtime 5.5 is nu beschikbaar. Databricks Runtime 5.5 bevat Apache Spark 2.4.3, bijgewerkte Python-, R-, Java- en Scala-bibliotheken, en de volgende nieuwe functies:
- Delta Lake op Azure Databricks Auto Optimize GA
- Delta Lake in Azure Databricks heeft de prestaties van de aggregatiequery min, max en count verbeterd
- Snellere pijplijnen voor modeldeductie met verbeterde binaire bestandsgegevensbron en scalaire iterator pandas UDF (openbare preview)
- Geheimen-API in R-notebooks
Zie Databricks Runtime 5.5 LTS (EoS) voor meer informatie.
Een groep instanties stand-by houden voor snelle clusterstart (openbare preview)
9 juli - 11, 2019: versie 2.101
Azure Databricks biedt nu ondersteuning voor het koppelen van een cluster aan een vooraf gedefinieerde pool met niet-actieve exemplaren om de begintijd van het cluster te verminderen. Wanneer het is gekoppeld aan een pool, wijst een cluster het stuurprogramma en de werkknooppunten van de pool toe. Als de pool onvoldoende niet-actieve resources heeft om tegemoet te komen aan de aanvraag van het cluster, wordt de pool uitgebreid door nieuwe exemplaren van de cloudprovider toe te wijzen. Wanneer een gekoppeld cluster wordt beëindigd, worden de gebruikte exemplaren geretourneerd naar de pool en kunnen ze opnieuw worden gebruikt door een ander cluster.
Azure Databricks brengt geen DBU's in rekening terwijl instanties inactief zijn in de pool. Facturering van exemplaarproviders is van toepassing. Zie prijzen.
Zie de naslaginformatie voor de poolconfiguratie voor meer informatie.
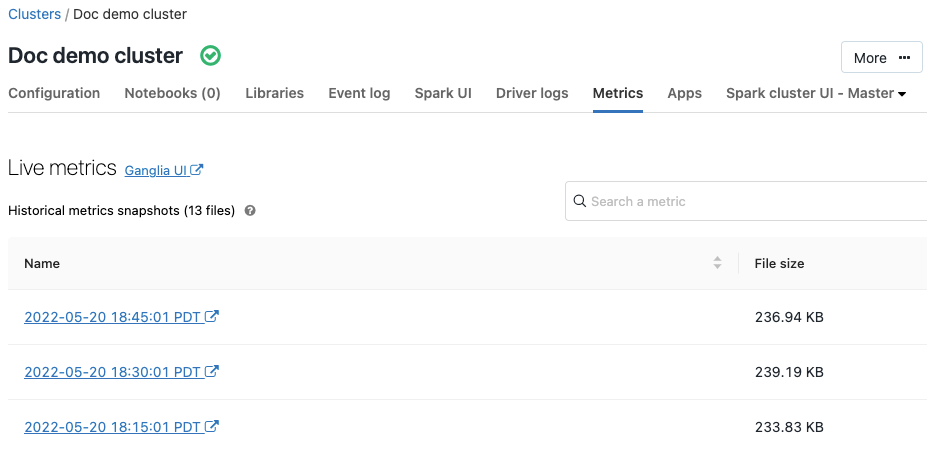
Metrische Ganglia-gegevens
9 juli - 11, 2019: versie 2.101
Ganglia is een schaalbaar gedistribueerd bewakingssysteem dat nu beschikbaar is op Azure Databricks-clusters. Metrische ganglia-gegevens helpen u bij het bewaken van de prestaties en status van het cluster. U kunt metrische gegevens van Ganglia openen via de pagina met clusterdetails:
Globale reekskleur
9 juli - 11, 2019: versie 2.101
U kunt nu opgeven dat de kleuren van een reeks consistent moeten zijn in alle grafieken in uw notitieblok. Zie Kleurconsistentie in grafieken.