HorovodRunner: gedistribueerd Deep Learning met Horovod
Belangrijk
Horovod en HorovodRunner zijn nu afgeschaft. Releases na 15.4 LTS ML hebben dit pakket niet vooraf geïnstalleerd. Voor gedistribueerde deep learning raadt Databricks aan om TorchDistributor te gebruiken voor gedistribueerde training met PyTorch of de tf.distribute.Strategy API voor gedistribueerde training met TensorFlow.
Meer informatie over het uitvoeren van gedistribueerde training van machine learning-modellen met horovodRunner om Horovod-trainingstaken te starten als Spark-taken in Azure Databricks.
Wat is HorovodRunner?
HorovodRunner is een algemene API voor het uitvoeren van gedistribueerde Deep Learning-workloads in Azure Databricks met behulp van het Horovod-framework . Door Horovod te integreren met de barrièremodus van Spark, kan Azure Databricks een hogere stabiliteit bieden voor langlopende deep learning-trainingstaken in Spark. HorovodRunner gebruikt een Python-methode die deep learning-trainingscode bevat met Horovod hooks. HorovodRunner kiest de methode op het stuurprogramma en distribueert deze naar Spark-werkrollen. Een Horovod MPI-taak wordt ingesloten als een Spark-taak met behulp van de uitvoeringsmodus voor barrières. De eerste uitvoerder verzamelt de IP-adressen van alle taakuitvoerders met behulp BarrierTaskContext van en activeert een Horovod-taak met behulp van mpirun. Elk Python MPI-proces laadt het gekozen gebruikersprogramma, ontserialiseerd het en voert het uit.
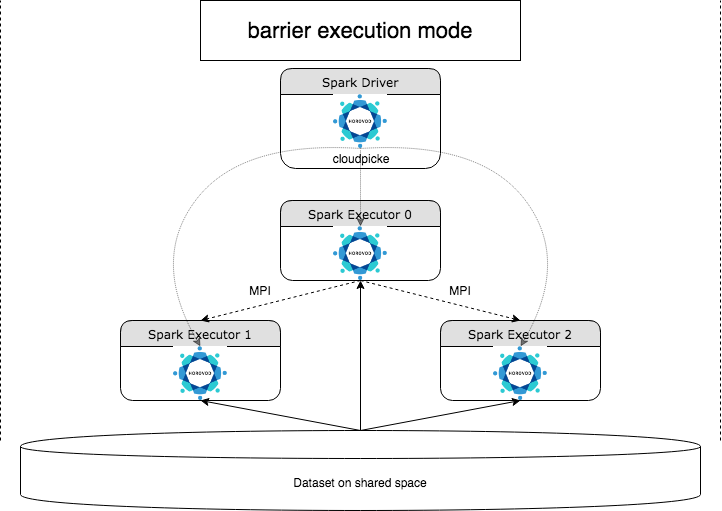
Gedistribueerde training met HorovodRunner
Met HorovodRunner kunt u Horovod-trainingstaken starten als Spark-taken. De HorovodRunner-API ondersteunt de methoden die worden weergegeven in de table. Zie de documentatie voor de HorovodRunner-API voor meer informatie.
| Methode en handtekening | Beschrijving |
|---|---|
init(self, np) |
Maak een exemplaar van HorovodRunner. |
run(self, main, **kwargs) |
Voer een Horovod-trainingstaak uit die aanroept main(**kwargs). De belangrijkste functie en de trefwoordargumenten worden geserialiseerd met behulp van cloudpickle en gedistribueerd naar clustermedewerkers. |
De algemene benadering voor het ontwikkelen van een gedistribueerd trainingsprogramma met horovodRunner is:
- Maak een
HorovodRunnerexemplaar dat is geïnitialiseerd met het aantal knooppunten. - Definieer een Horovod-trainingsmethode volgens de methoden die worden beschreven in Het gebruik van Horovod, en zorg ervoor dat u eventuele importinstructies in de methode toevoegt.
- Geef de trainingsmethode door aan het
HorovodRunnerexemplaar.
Voorbeeld:
hr = HorovodRunner(np=2)
def train():
import tensorflow as tf
hvd.init()
hr.run(train)
Als u HorovodRunner alleen wilt uitvoeren op het stuurprogramma met n subprocessen, gebruikt u hr = HorovodRunner(np=-n). Als er bijvoorbeeld 4 GPU's op het stuurprogrammaknooppunt staan, kunt u maximaal nkiezen4. Zie de documentatie van de np voor meer informatie over de parameter. Zie de Handleiding voor Horovod-gebruik voor meer informatie over het vastmaken van één GPU per subproces.
Een veelvoorkomende fout is dat TensorFlow-objecten niet kunnen worden gevonden of geselecteerd. Dit gebeurt wanneer de importinstructies van de bibliotheek niet worden gedistribueerd naar andere uitvoerders. Als u dit probleem wilt voorkomen, moet u alle importinstructies (bijvoorbeeld import tensorflow as tf)opnemen boven aan de Horovod-trainingsmethode en in alle andere door de gebruiker gedefinieerde functies die worden aangeroepen in de Horovod-trainingsmethode.
Horovod-training opnemen met Horovod Timeline
Horovod heeft de mogelijkheid om de tijdlijn van de activiteit vast te leggen, genaamd Horovod Timeline.
Belangrijk
Horovod Timeline heeft een aanzienlijke invloed op de prestaties. De doorvoer in Het begin3 kan met ~40% afnemen wanneer Horovod Timeline is ingeschakeld. Gebruik HorovodRunner-taken niet om Horovod Timeline te versnellen.
U kunt de Horovod-tijdlijn niet bekijken terwijl de training wordt uitgevoerd.
Als u een Horovod-tijdlijn wilt opnemen, set u de omgevingsvariabele HOROVOD_TIMELINE op de locatie where u het tijdlijnbestand wilt opslaan. Databricks raadt aan een locatie in gedeelde opslag te gebruiken, zodat het tijdlijnbestand eenvoudig kan worden opgehaald. U kunt bijvoorbeeld LOKALE DBFS-bestands-API's gebruiken, zoals wordt weergegeven:
timeline_dir = "/dbfs/ml/horovod-timeline/%s" % uuid.uuid4()
os.makedirs(timeline_dir)
os.environ['HOROVOD_TIMELINE'] = timeline_dir + "/horovod_timeline.json"
hr = HorovodRunner(np=4)
hr.run(run_training_horovod, params=params)
Voeg vervolgens tijdlijnspecifieke code toe aan het begin en einde van de trainingsfunctie. Het volgende voorbeeldnotebook bevat voorbeeldcode die u als tijdelijke oplossing kunt gebruiken om de voortgang van de training weer te geven.
Voorbeeldnotitieblok voor Horovod-tijdlijn
Als u het tijdlijnbestand wilt downloaden, gebruikt u de Databricks CLI en gebruikt u vervolgens de faciliteit van chrome://tracing de Chrome-browser om het te bekijken. Voorbeeld:
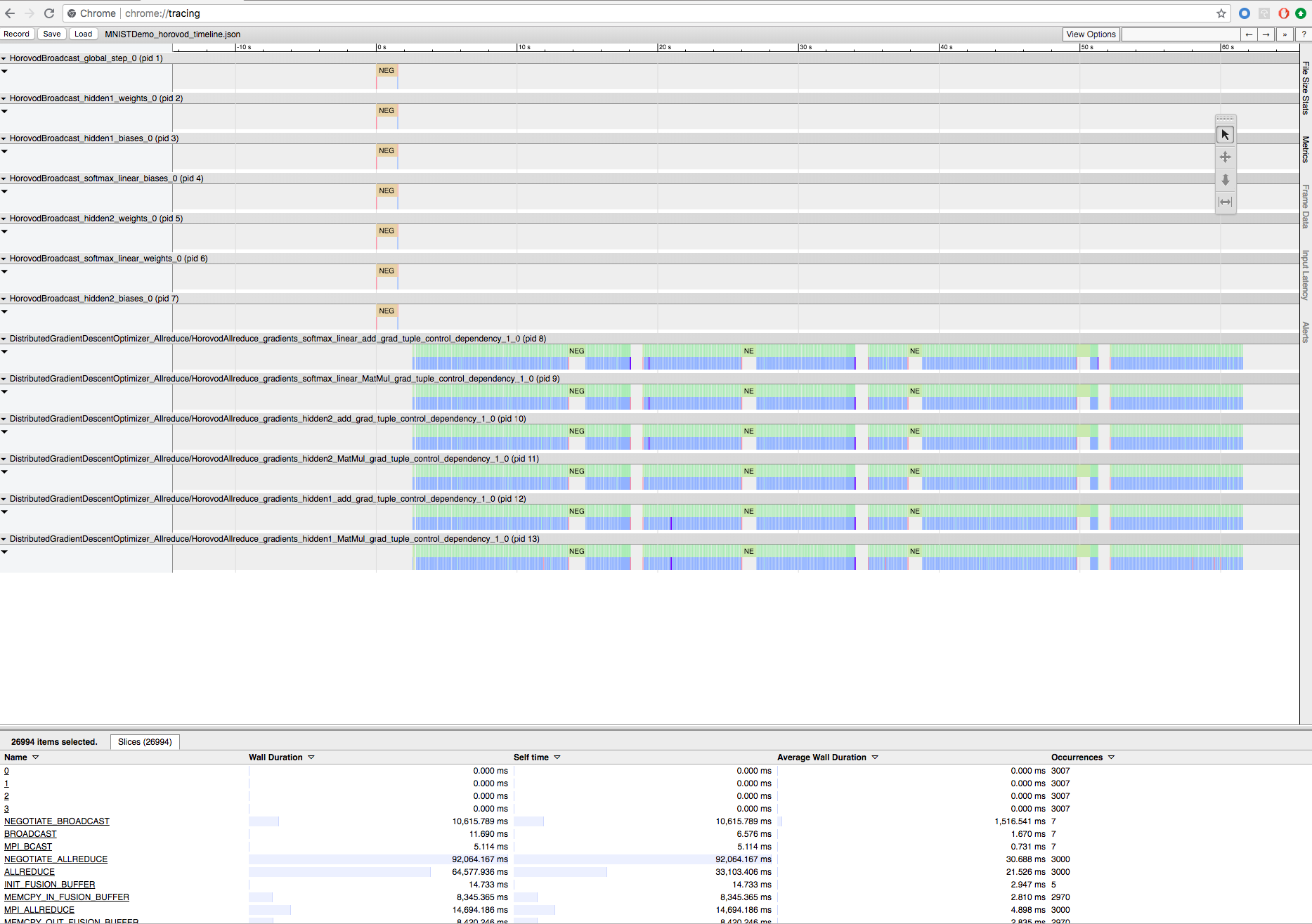
Ontwikkelwerkstroom
Dit zijn de algemene stappen voor het migreren van deep learning-code voor één knooppunt naar gedistribueerde training. De voorbeelden: Migreren naar gedistribueerde deep learning met HorovodRunner in deze sectie illustreren deze stappen.
- Code voor één knooppunt voorbereiden: de code van één knooppunt voorbereiden en testen met TensorFlow, Keras of PyTorch.
-
Migreren naar Horovod: volg de instructies van horovod-gebruik om de code te migreren met Horovod en test deze op het stuurprogramma:
- Toevoegen
hvd.init()om Horovod te initialiseren. - Maak een server-GPU vast om door dit proces te worden gebruikt met behulp van
config.gpu_options.visible_device_list. Met de typische installatie van één GPU per proces kan dit zijn van set naar lokale rang. In dat geval wordt het eerste proces op de server toegewezen aan de eerste GPU, het tweede proces wordt de tweede GPU toegewezen, enzovoort. - Neem een shard van de gegevensset op. Deze gegevenssetoperator is erg handig bij het uitvoeren van gedistribueerde training, omdat elke werknemer een unieke subset kan lezen.
- Schaal de leersnelheid op basis van het aantal werknemers. De effectieve batchgrootte in synchrone gedistribueerde training wordt geschaald op basis van het aantal werkrollen. Het verhogen van de leersnelheid compenseert de toegenomen batchgrootte.
- Wrap the optimizer in
hvd.DistributedOptimizer. De gedistribueerde optimizer delegeert de berekening van kleurovergangen naar de oorspronkelijke optimizer, gemiddelden met allreduce of allgather en past vervolgens de gemiddelde kleurovergangen toe. - Voeg toe
hvd.BroadcastGlobalVariablesHook(0)aan het uitzenden van initiële variabelestatussen van rang 0 tot alle andere processen. Dit is nodig om een consistente initialisatie van alle werknemers te garanderen wanneer de training wordt gestart met willekeurige gewichten of hersteld vanaf een controlepunt. Als u deze niet gebruiktMonitoredTrainingSession, kunt u dehvd.broadcast_global_variablesbewerking ook uitvoeren nadat globale variabelen zijn geïnitialiseerd. - Wijzig uw code om controlepunten alleen op werkrol 0 op te slaan om te voorkomen dat andere werknemers deze beschadigen.
- Toevoegen
- Migreren naar HorovodRunner: HorovodRunner voert de Horovod-trainingstaak uit door een Python-functie aan te roepen. U moet de hoofdtrainingsprocedure verpakken in één Python-functie. Vervolgens kunt u HorovodRunner testen in de lokale modus en gedistribueerde modus.
Update de Deep Learning-bibliotheken
Als u TensorFlow, Keras of PyTorch upgradet of downgradet, moet u Horovod opnieuw installeren zodat deze wordt gecompileerd op basis van de zojuist geïnstalleerde bibliotheek. Als u bijvoorbeeld TensorFlow wilt upgraden, raadt Databricks aan het init-script te gebruiken vanuit de Installatie-instructies van TensorFlow en de volgende TensorFlow-specifieke Horovod-installatiecode toe te voegen aan het einde ervan. Zie de installatie-instructies voor Horovod voor het werken met verschillende combinaties, zoals het upgraden of downgraden van PyTorch en andere bibliotheken.
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt update
# Using the same compiler that TensorFlow was built to compile Horovod
apt install g++-7 -y
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60
HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_CUDA_HOME=/usr/local/cuda pip install horovod==0.18.1 --force-reinstall --no-deps --no-cache-dir
Voorbeelden: Migreren naar gedistribueerd deep learning met HorovodRunner
De volgende voorbeelden, op basis van de MNIST-gegevensset , laten zien hoe u een deep learning-programma met één knooppunt migreert naar gedistribueerde deep learning met HorovodRunner.
- Deep Learning met Behulp van TensorFlow met HorovodRunner voor MNIST
- PyTorch met één knooppunt aanpassen aan gedistribueerde deep learning
Beperkingen
- Wanneer u met werkruimtebestanden werkt, zal HorovodRunner niet functioneren als
npgroter is dan set en de notebook importeert vanuit andere relatieve bestanden. Overweeg om horovod.spark te gebruiken in plaats vanHorovodRunner. - Als u fouten ondervindt,
WARNING: Open MPI accepted a TCP connection from what appears to be a another Open MPI process but cannot find a corresponding process entry for that peergeeft dit een probleem aan met netwerkcommunicatie tussen knooppunten in uw cluster. Als u deze fout wilt oplossen, voegt u het volgende codefragment toe aan uw trainingscode om de primaire netwerkinterface te gebruiken.
import os
os.environ["OMPI_MCA_btl_tcp_if_include"]="eth0"
os.environ["NCCL_SOCKET_IFNAME"]="eth0"