Hiaten tussen Spark-taken
U ziet dus hiaten in uw takentijdlijn, zoals hieronder:
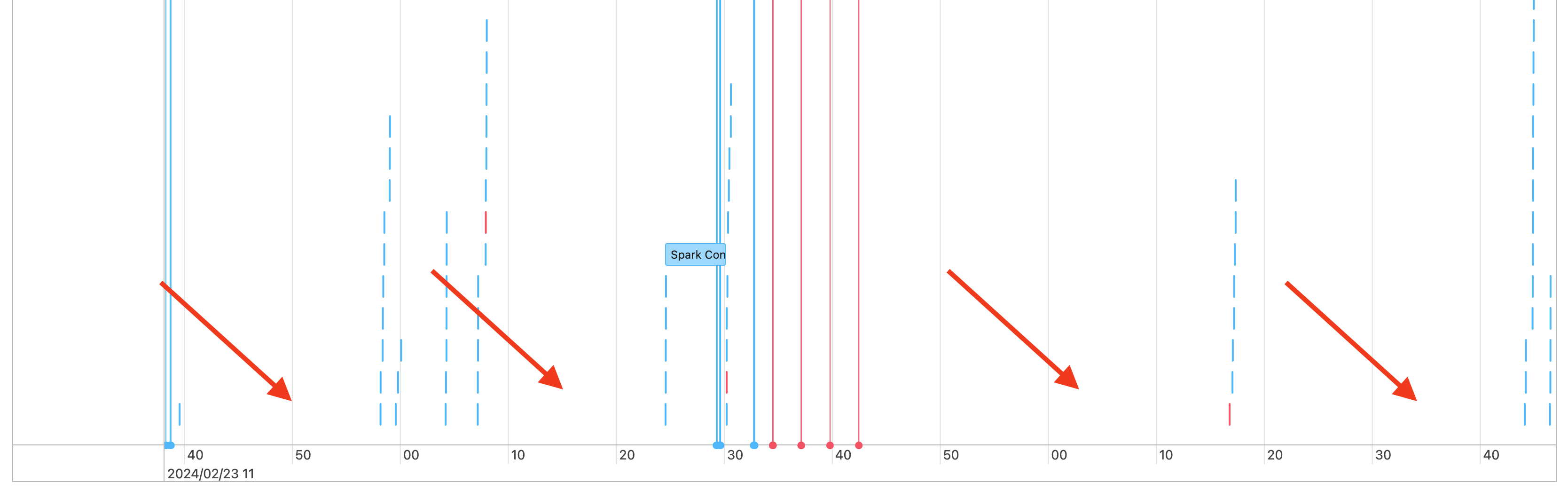
Er zijn een paar redenen waarom dit kan gebeuren. Als de hiaten een groot deel uitmaken van de tijd die aan uw werkbelasting is besteed, moet u nagaan wat deze hiaten veroorzaken en of deze wel of niet worden verwacht. Er kunnen enkele dingen gebeuren tijdens de hiaten:
- Er is geen werk te doen
- Het stuurprogramma compileert een complex uitvoeringsplan
- Uitvoering van niet-Spark-code
- Stuurprogramma is overbelast
- Cluster is defect
Geen werk
Bij veelzijdige rekencapaciteitis het ontbreken van werk bij having de meest waarschijnlijke verklaring voor de hiaten. Omdat het cluster wordt uitgevoerd en gebruikers query's indienen, worden hiaten verwacht. Deze hiaten zijn de tijd tussen het indienen van query's.
Complex uitvoeringsplan
Als u bijvoorbeeld in een lus gebruikt withColumn() , wordt er een zeer duur plan gemaakt om te verwerken. De hiaten kunnen de tijd zijn waarop de bestuurder gewoon het plan bouwt en verwerkt. Als dit het geval is, vereenvoudigt u de code. Gebruik selectExpr() om meerdere withColumn() aanroepen te combineren in één expressie of om de code te converteren naar SQL. U kunt de SQL nog steeds insluiten in uw Python-code, met behulp van Python om de query te bewerken met tekenreeksfuncties. Dit lost dit soort problemen vaak op.
Uitvoering van niet-Spark-code
Spark-code is geschreven in SQL of met behulp van een Spark-API zoals PySpark. Elke uitvoering van code die niet Spark is, wordt weergegeven in de tijdlijn als hiaten. U kunt bijvoorbeeld een lus in Python hebben die systeemeigen Python-functies aanroept. Deze code wordt niet uitgevoerd in Spark en kan worden weergegeven als een hiaat in de tijdlijn. Als u niet zeker weet of spark wordt uitgevoerd met uw code, kunt u deze interactief uitvoeren in een notebook. Als de code Spark gebruikt, ziet u Spark-taken onder de cel:

U kunt ook de vervolgkeuzelijst Spark-taken onder de cel uitvouwen om te zien of de taken actief worden uitgevoerd (als Spark nu niet actief is). Als u Spark niet gebruikt, ziet u de Spark-taken niet in de cel of ziet u dat er geen spark actief is. Als u de code niet interactief kunt uitvoeren, kunt u proberen u aan te melden bij uw code en te kijken of u de hiaten met secties van uw code op tijdstempel kunt vergelijken, maar dat kan lastig zijn.
Als u hiaten in uw tijdlijn ziet die worden veroorzaakt door het uitvoeren van niet-Spark-code, betekent dit dat uw werknemers allemaal inactief zijn en waarschijnlijk geld verspillen tijdens de hiaten. Misschien is dit opzettelijk en onvermijdelijk, maar als u deze code kunt schrijven om Spark te gebruiken, zult u het cluster volledig gebruiken. Begin met deze zelfstudie voor meer informatie over het werken met Spark.
Stuurprogramma is overbelast
Als u wilt bepalen of uw stuurprogramma overbelast is, moet u de metrische gegevens van het cluster bekijken.
Als uw cluster zich op DBR 13.0 of hoger bevindt, klikt u op Metrische gegevens zoals gemarkeerd in deze schermafbeelding:
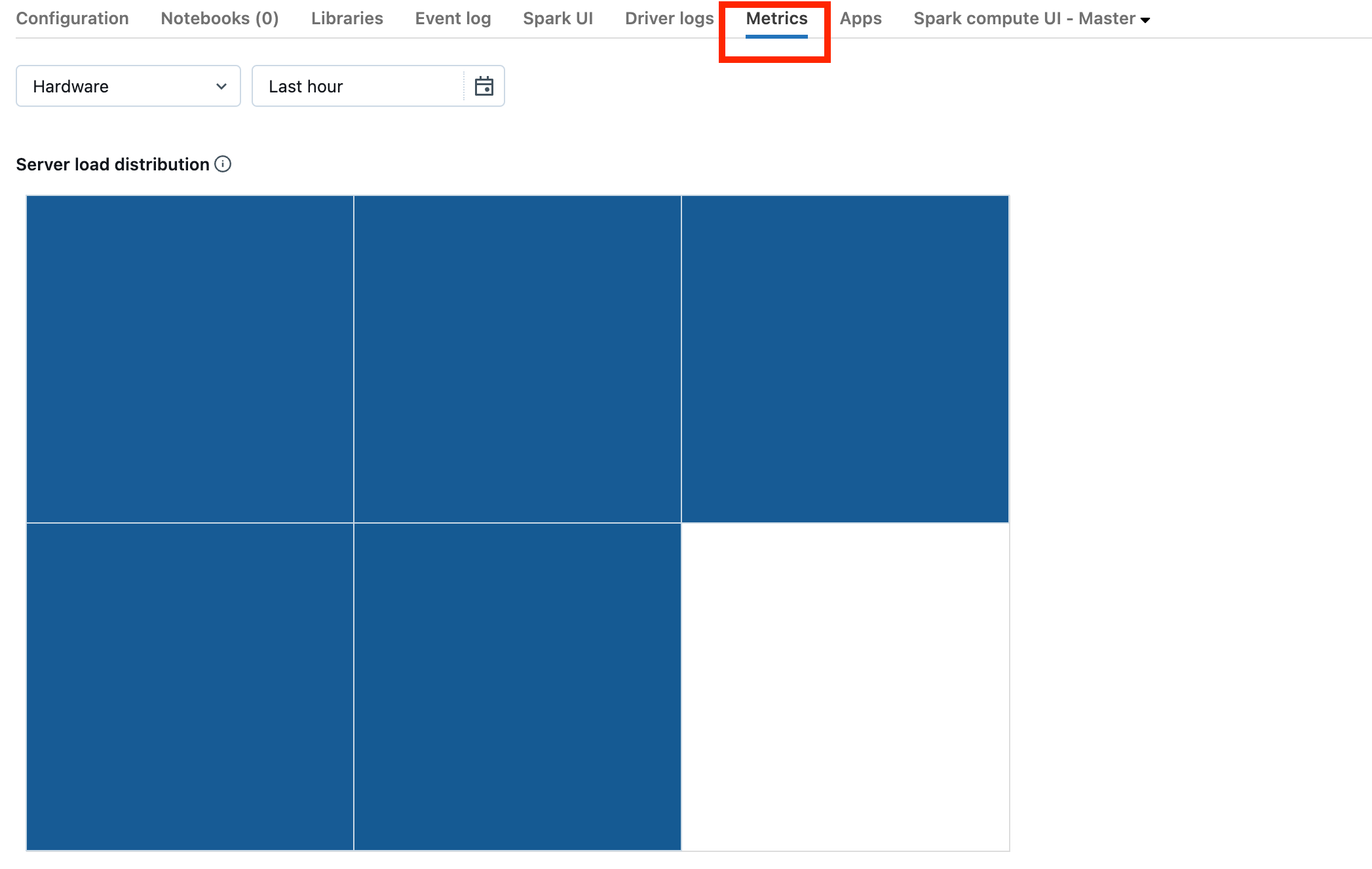
Let op de visualisatie serverbelastingsdistributie. U moet kijken of het stuurprogramma zwaar is geladen. Deze visualisatie heeft een kleurblok voor elke machine in het cluster. Rood betekent zwaar geladen en blauw betekent helemaal niet geladen.
In de vorige schermopname ziet u een inactief cluster. Als het stuurprogramma overbelast is, ziet het er ongeveer als volgt uit:
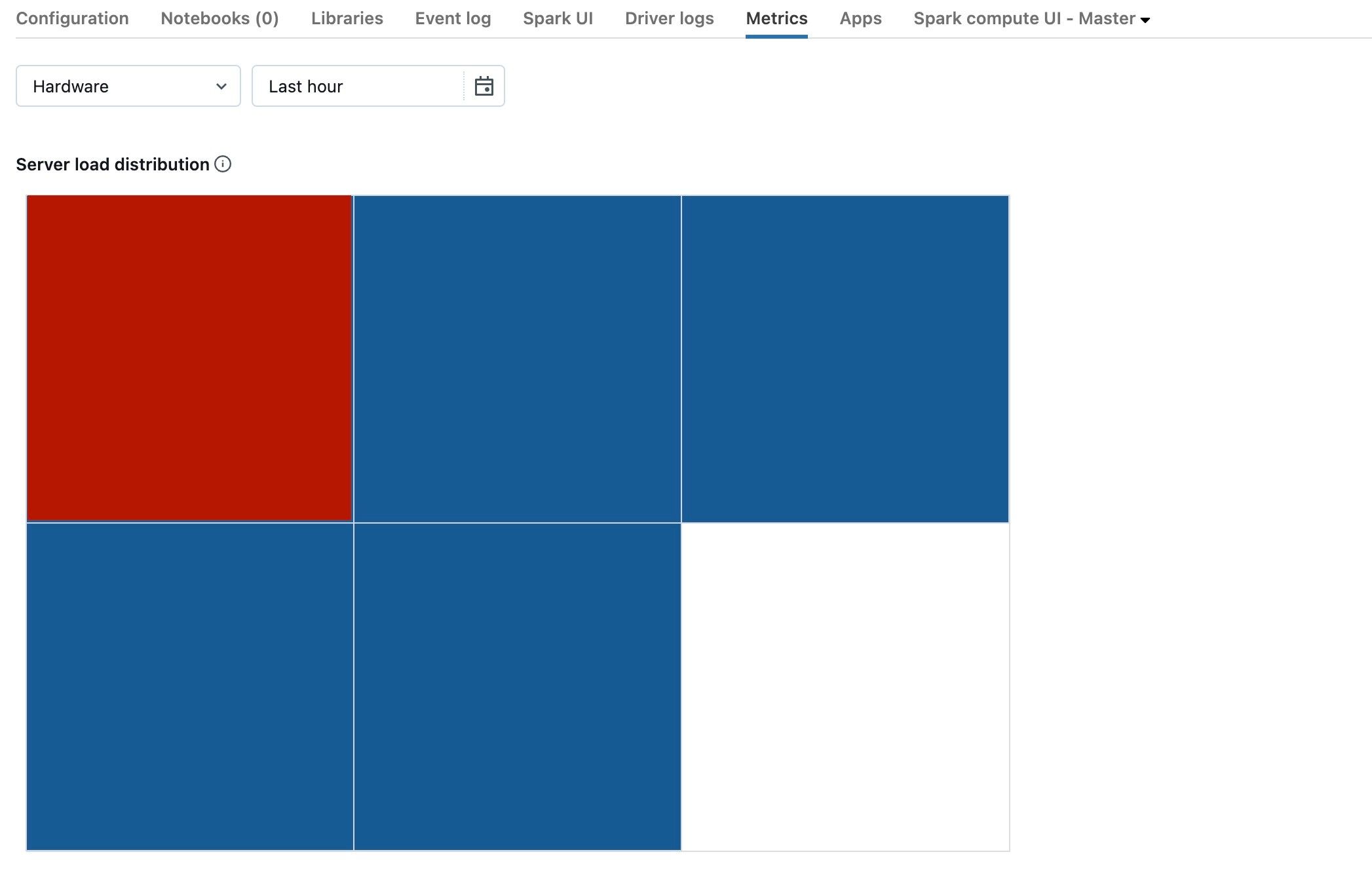
We kunnen zien dat één vierkant rood is, terwijl de andere blauw zijn. Beweeg uw muis over het rode vierkant om ervoor te zorgen dat het rode blok uw stuurprogramma vertegenwoordigt.
Zie Spark-stuurprogramma overbelast om een overbelast stuurprogramma op te lossen.
Cluster is defect
Storingsclusters zijn zeldzaam, maar als dit het geval is, kan het lastig zijn om te bepalen wat er is gebeurd. Mogelijk wilt u het cluster opnieuw opstarten om te zien of dit het probleem oplost. U kunt ook de logboeken bekijken om te zien of er iets verdachts is. Het tabblad Gebeurtenislogboek en de tabbladen stuurprogrammalogboeken , gemarkeerd in de onderstaande schermafbeelding, zijn de plaatsen om te kijken:
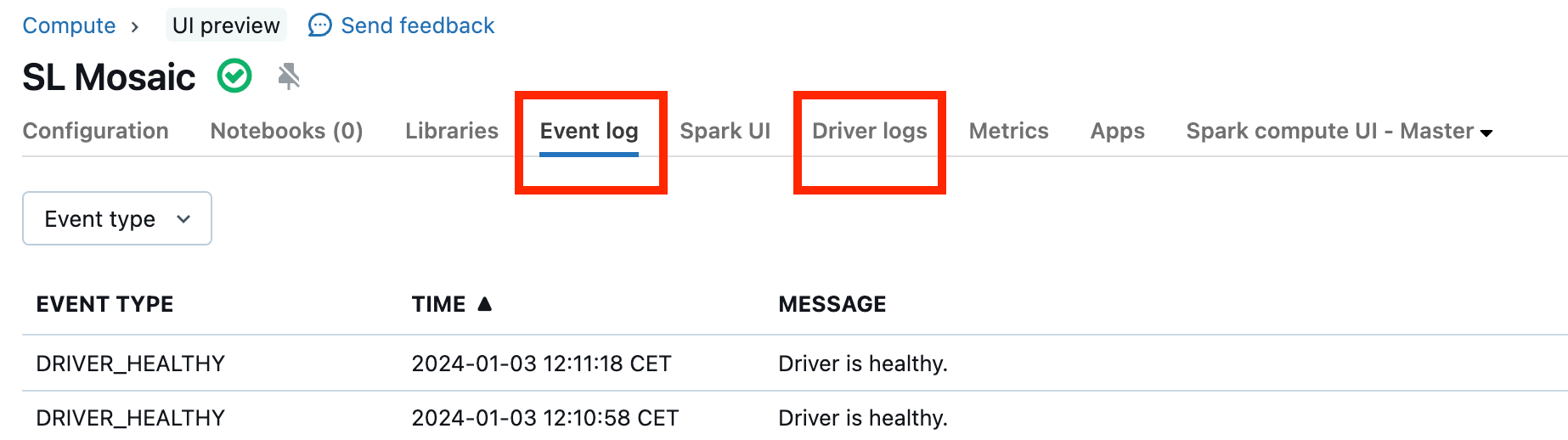
Mogelijk wilt u de levering van clusterlogboeken inschakelen om toegang te krijgen tot de logboeken van de werknemers. U kunt ook het logboekniveau wijzigen, maar mogelijk moet u contact opnemen met uw Databricks-accountteam voor hulp.