Delta Lake configureren voor het beheren van de bestandsgrootte
Notitie
De aanbevelingen in dit artikel zijn niet van toepassing op beheerde tabellen van Unity Catalog. Databricks raadt aan beheerde tabellen van Unity Catalog te gebruiken met standaardinstellingen voor alle nieuwe Delta-tabellen.
In Databricks Runtime 13.3 en hoger raadt Databricks aan om clustering te gebruiken voor de indeling van deltatabellen. Zie Liquid Clustering gebruiken voor Delta-tabellen.
Databricks raadt aan voorspellende optimalisatie te gebruiken om automatisch uit te voeren OPTIMIZE en VACUUM voor Delta-tabellen. Zie Voorspellende optimalisatie voor beheerde tabellen van Unity Catalog.
In Databricks Runtime 10.4 LTS en hoger zijn automatisch comprimeren en geoptimaliseerde schrijfbewerkingen altijd ingeschakeld voor MERGE, UPDATEen DELETE bewerkingen. U kunt deze functionaliteit niet uitschakelen.
Delta Lake biedt opties voor het handmatig of automatisch configureren van de doelbestandsgrootte voor schrijfbewerkingen en voor OPTIMIZE bewerkingen. Azure Databricks tunest automatisch veel van deze instellingen en maakt functies mogelijk die de tabelprestaties automatisch verbeteren door te zoeken naar bestanden met de juiste grootte.
Voor beheerde tabellen in Unity Catalog worden de meeste van deze configuraties automatisch door Databricks uitgevoerd als u een SQL-warehouse of Databricks Runtime 11.3 LTS of hoger gebruikt.
Als u een workload bijwerkt vanuit Databricks Runtime 10.4 LTS of lager, raadpleeg dan Upgraden naar automatische compressie op de achtergrond.
Wanneer uitvoeren OPTIMIZE
Automatische compressie en geoptimaliseerde schrijfbewerkingen verminderen elk kleine bestandsproblemen, maar zijn geen volledige vervanging voor OPTIMIZE. Met name voor tabellen die groter zijn dan 1 TB, raadt Databricks aan om OPTIMIZE volgens een rooster uit te voeren om bestanden verder samen te voegen. Azure Databricks voert niet automatisch ZORDER uit op tabellen, dus moet u OPTIMIZE samen met ZORDER uitvoeren om verbeterd gegevens overslaan mogelijk te maken. Zie Gegevens overslaan voor Delta Lake.
Wat is auto-optimalisatie op Azure Databricks?
De term automatisch optimaliseren wordt soms gebruikt om de functionaliteit te beschrijven die wordt beheerd door de instellingen delta.autoOptimize.autoCompact en delta.autoOptimize.optimizeWrite. Deze term is buiten gebruik gesteld ten gunste van het afzonderlijk beschrijven van elke instelling. Zie Automatische compressie voor Delta Lake in Azure Databricks en geoptimaliseerde schrijfbewerkingen voor Delta Lake in Azure Databricks.
Automatische compressie voor Delta Lake in Azure Databricks
Automatische compressie combineert kleine bestanden in Delta-tabelpartities om problemen met kleine bestanden automatisch te verminderen. Automatische compressie vindt plaats nadat een schrijfbewerking naar een tabel is geslaagd en synchroon wordt uitgevoerd op het cluster dat de schrijfbewerking heeft uitgevoerd. Met automatisch comprimeren worden alleen bestanden gecomprimeerd die nog niet eerder zijn gecomprimeerd.
U kunt de grootte van het uitvoerbestand beheren door de Spark-configuratiespark.databricks.delta.autoCompact.maxFileSizein te stellen. Databricks raadt aan om automatisch afstemmen te gebruiken op basis van workload- of tabelgrootte. Zie De bestandsgrootte van Autotune op basis van de workload en de grootte van het Autotune-bestand op basis van de tabelgrootte.
Automatische compressie wordt alleen geactiveerd voor partities of tabellen met ten minste een bepaald aantal kleine bestanden. U kunt desgewenst het minimale aantal bestanden wijzigen dat nodig is om automatische compressie te activeren door de instelling in te stellen spark.databricks.delta.autoCompact.minNumFiles.
Automatische compressie kan worden ingeschakeld op tabel- of sessieniveau met behulp van de volgende instellingen:
- Tabeleigenschap:
delta.autoOptimize.autoCompact - SparkSession-instelling:
spark.databricks.delta.autoCompact.enabled
Deze instellingen accepteren de volgende opties:
| Opties | Gedrag |
|---|---|
auto (aanbevolen) |
Optimaliseert bestandsdoelgrootte terwijl andere automatisch afstemmingsfunctionaliteit gerespecteerd wordt. Vereist Databricks Runtime 10.4 LTS of hoger. |
legacy |
Alias voor true. Vereist Databricks Runtime 10.4 LTS of hoger. |
true |
Gebruik 128 MB als doelbestandsgrootte. Geen dynamische afmetingen. |
false |
Hiermee schakelt u automatische compressie uit. Kan worden ingesteld op sessieniveau om automatische compressie te overschrijven voor alle Delta-tabellen die in de workload zijn gewijzigd. |
Belangrijk
In Databricks Runtime 9.1 LTS kan automatische compressie ervoor zorgen dat andere taken mislukken met een transactieconflict wanneer andere schrijvers gelijktijdig bewerkingen zoals DELETE, MERGE, UPDATE, of OPTIMIZE uitvoeren. Dit is geen probleem in Databricks Runtime 10.4 LTS en hoger.
Geoptimaliseerde schrijfbewerkingen voor Delta Lake in Azure Databricks
Geoptimaliseerde schrijfbewerkingen verbeteren de bestandsgrootte wanneer gegevens worden geschreven en profiteren van latere leesbewerkingen in de tabel.
Geoptimaliseerde schrijfbewerkingen zijn het meest effectief voor gepartitioneerde tabellen, omdat ze het aantal kleine bestanden verminderen dat naar elke partitie wordt geschreven. Het schrijven van minder grote bestanden is efficiënter dan het schrijven van veel kleine bestanden, maar u ziet mogelijk nog steeds een toename van de schrijflatentie omdat de gegevens in willekeurige volgorde worden geschoven voordat ze worden geschreven.
In de volgende afbeelding ziet u hoe geoptimaliseerde schrijfbewerkingen werken:
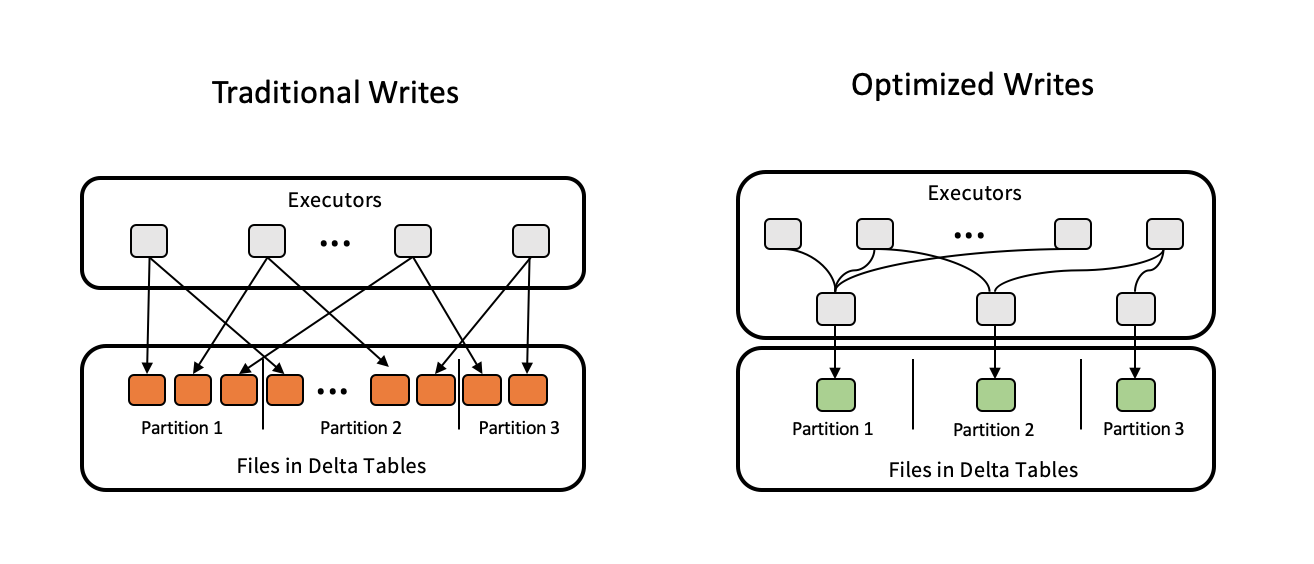
Notitie
Mogelijk hebt u code die wordt uitgevoerd coalesce(n) of repartition(n) net voordat u uw gegevens opschrijft om het aantal geschreven bestanden te bepalen. Met geoptimaliseerde schrijfbewerkingen hoeft u dit patroon niet meer te gebruiken.
Geoptimaliseerde schrijfbewerkingen zijn standaard ingeschakeld voor de volgende bewerkingen in Databricks Runtime 9.1 LTS en hoger:
MERGE-
UPDATEmet subquery's -
DELETEmet subquery's
Geoptimaliseerde schrijfbewerkingen worden ook ingeschakeld voor CTAS instructies en INSERT bewerkingen bij het gebruik van SQL Warehouses. In Databricks Runtime 13.3 LTS en hoger hebben alle Delta-tabellen die zijn geregistreerd in Unity Catalog geoptimaliseerde schrijfbewerkingen ingeschakeld voor CTAS instructies en INSERT bewerkingen voor gepartitioneerde tabellen.
Geoptimaliseerde schrijfbewerkingen kunnen worden ingeschakeld op tabel- of sessieniveau met behulp van de volgende instellingen:
- Tabelinstelling:
delta.autoOptimize.optimizeWrite - SparkSession-instelling:
spark.databricks.delta.optimizeWrite.enabled
Deze instellingen accepteren de volgende opties:
| Opties | Gedrag |
|---|---|
true |
Gebruik 128 MB als doelbestandsgrootte. |
false |
Hiermee schakelt u geoptimaliseerde schrijfbewerkingen uit. Kan worden ingesteld op sessieniveau om automatische compressie te overschrijven voor alle Delta-tabellen die in de workload zijn gewijzigd. |
Een doelbestandsgrootte instellen
Als u de grootte van bestanden in uw Delta-tabel wilt afstemmen, stelt u de tabeleigenschapdelta.targetFileSize in op de gewenste grootte. Als deze eigenschap is ingesteld, doen alle optimalisatiebewerkingen voor gegevensindelingen een best-inspanning om bestanden van de opgegeven grootte te genereren. Voorbeelden hier zijn optimalisatie of Z-order, automatische compressie en geoptimaliseerde schrijfbewerkingen.
Notitie
Wanneer u beheerde tabellen in Unity Catalog en SQL Warehouses of Databricks Runtime 11.3 LTS en hoger gebruikt, respecteren alleen OPTIMIZE opdrachten de targetFileSize instelling.
| Tabeleigenschap |
|---|
|
delta.targetFileSize Type: Grootte in bytes of hogere eenheden. De grootte van het doelbestand. Bijvoorbeeld 104857600 (bytes) of 100mb.Standaardwaarde: Geen |
Voor bestaande tabellen kunt u eigenschappen instellen en ongedaan maken met behulp van de SQL-opdracht ALTER TABLESET TBL PROPERTIES. U kunt deze eigenschappen ook automatisch instellen wanneer u nieuwe tabellen maakt met behulp van Spark-sessieconfiguraties. Zie de naslaginformatie over eigenschappen van deltatabellen voor meer informatie.
Bestandsgrootte automatisch afstemmen op basis van workload
Databricks raadt aan om de tabeleigenschap delta.tuneFileSizesForRewrites in te true stellen voor alle tabellen waarop veel MERGE of DML-bewerkingen betrekking hebben, ongeacht Databricks Runtime, Unity Catalog of andere optimalisaties. Als dit is ingesteld true, wordt de grootte van het doelbestand voor de tabel ingesteld op een veel lagere drempelwaarde, waardoor schrijfintensieve bewerkingen worden versneld.
Als dit niet expliciet is ingesteld, detecteert Azure Databricks automatisch of 9 van de laatste tien vorige bewerkingen in een Delta-tabel bewerkingen waren MERGE en stelt deze tabeleigenschap in op true. U moet deze eigenschap expliciet instellen op false om dit gedrag te voorkomen.
| Tabeleigenschap |
|---|
|
delta.tuneFileSizesForRewrites Typ: BooleanOf u de bestandsgrootten wilt afstemmen voor optimalisatie van de gegevensindeling. Standaardwaarde: Geen |
Voor bestaande tabellen kunt u eigenschappen instellen en ongedaan maken met behulp van de SQL-opdracht ALTER TABLESET TBL PROPERTIES. U kunt deze eigenschappen ook automatisch instellen wanneer u nieuwe tabellen maakt met behulp van Spark-sessieconfiguraties. Zie de naslaginformatie over eigenschappen van deltatabellen voor meer informatie.
Bestandsgrootte automatisch afstemmen op basis van tabelgrootte
Om de noodzaak van handmatig afstemmen te minimaliseren, wordt door Azure Databricks automatisch de bestandsgrootte van Delta-tabellen afstemmen op basis van de grootte van de tabel. Azure Databricks gebruikt kleinere bestandsgrootten voor kleinere tabellen en grotere bestandsgrootten voor grotere tabellen, zodat het aantal bestanden in de tabel niet te groot wordt. In Azure Databricks worden tabellen die u op een specifieke doelgrootte hebt afgestemd of die gebaseerd zijn op een workload met frequente herschrijvingen, niet automatisch afgestemd.
De grootte van het doelbestand is gebaseerd op de huidige grootte van de Delta-tabel. Voor tabellen kleiner dan 2,56 TB is de automatisch afgestemde doelbestandsgrootte 256 MB. Voor tabellen met een grootte tussen 2,56 TB en 10 TB groeit de doelgrootte lineair van 256 MB tot 1 GB. Voor tabellen groter dan 10 TB is de doelbestandsgrootte 1 GB.
Notitie
Wanneer de grootte van het doelbestand voor een tabel groeit, worden bestaande bestanden niet opnieuw geoptimaliseerd in grotere bestanden met de OPTIMIZE opdracht. Een grote tabel kan daarom altijd een aantal bestanden hebben die kleiner zijn dan de doelgrootte. Als u deze kleinere bestanden ook in grotere bestanden wilt optimaliseren, kunt u een vaste doelbestandsgrootte voor de tabel configureren met behulp van de delta.targetFileSize tabeleigenschap.
Wanneer een tabel incrementeel wordt geschreven, liggen de bestandsgrootten van het doel en het aantal bestanden dicht bij de volgende getallen, op basis van de tabelgrootte. Het aantal bestanden in deze tabel is slechts een voorbeeld. De werkelijke resultaten verschillen, afhankelijk van veel factoren.
| Tabelgrootte | Grootte van doelbestand | Geschat aantal bestanden in tabel |
|---|---|---|
| 10 GB | 256 MB | 40 |
| 1 TB | 256 MB | 4096 |
| 2,56 TB | 256 MB | 10240 |
| 3 TB | 307 MB | 12108 |
| 5 TB | 512 MB | 17339 |
| 7 TB | 716 MB | 20784 |
| 10 TB | 1 GB | 24437 |
| 20 TB | 1 GB | 34437 |
| 50 TB | 1 GB | 64437 |
| 100 TB | 1 GB | 114437 |
Beperk het aantal rijen dat in een gegevensbestand wordt geschreven.
Soms kunnen tabellen met smalle gegevens een fout tegenkomen waarbij het aantal rijen in een bepaald gegevensbestand de ondersteuningslimieten van de Parquet-indeling overschrijdt. Om deze fout te voorkomen, kunt u de configuratie spark.sql.files.maxRecordsPerFile van de SQL-sessie gebruiken om het maximum aantal records op te geven dat naar één bestand voor een Delta Lake-tabel moet worden geschreven. Het opgeven van een waarde van nul of een negatieve waarde vertegenwoordigt geen limiet.
In Databricks Runtime 11.3 LTS en hoger kunt u ook de optie maxRecordsPerFile DataFrameWriter gebruiken wanneer u de DataFrame-API's gebruikt om naar een Delta Lake-tabel te schrijven. Wanneer maxRecordsPerFile is opgegeven, wordt de waarde van de configuratie spark.sql.files.maxRecordsPerFile van de SQL-sessie genegeerd.
Notitie
Databricks raadt het gebruik van deze optie niet aan, tenzij het nodig is om de bovengenoemde fout te voorkomen. Deze instelling is mogelijk nog steeds nodig voor sommige beheerde tabellen van Unity Catalog met zeer smalle gegevens.
Upgraden naar automatische compressie op de achtergrond
Automatische compressie op de achtergrond is beschikbaar voor beheerde Unity Catalog-tabellen in Databricks Runtime 11.3 LTS en hoger. Wanneer u een verouderde workload of tabel migreert, gaat u als volgt te werk:
- Verwijder de Spark-configuratie
spark.databricks.delta.autoCompact.enableduit de configuratie-instellingen van het cluster of notebook. - Voer voor elke tabel uit
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)om verouderde instellingen voor automatische compressie te verwijderen.
Nadat u deze verouderde configuraties hebt verwijderd, ziet u dat automatische compressie op de achtergrond automatisch wordt geactiveerd voor alle beheerde tabellen van Unity Catalog.