Prognose (serverloos) met AutoML
Belangrijk
Deze functie bevindt zich in Public Preview.
In dit artikel leest u hoe u een serverloze voorspellingsexperiment uitvoert met behulp van de gebruikersinterface van Mozaïek AI-modeltraining.
Mozaïek AI-modeltraining - prognose vereenvoudigt het voorspellen van tijdreeksgegevens door automatisch het beste algoritme en de beste hyperparameters te selecteren, allemaal terwijl deze worden uitgevoerd op volledig beheerde rekenresources.
Zie Serverloze prognose versus klassieke rekenprognosesvoor meer informatie over het verschil tussen serverloze prognoses en klassieke rekenprognoses.
Eisen
Trainingsgegevens met een tijdreekskolom, opgeslagen als een Unity Catalog-tabel.
Als voor de werkruimte Secure Egress Gateway (SEG) is ingeschakeld, moet
pypi.orgworden toegevoegd aan de Toegestane domeinen lijst. Zie Netwerkbeleid beheren voor serverloos uitgaand verkeer.
Een prognoseexperiment maken met de gebruikersinterface
Ga naar de landingspagina van Azure Databricks en klik op Experimenten in de zijbalk.
Selecteer in de tegel VoorspellenTraining starten.
Selecteer de trainingsgegevens uit een lijst met Unity Catalog-tabellen waartoe u toegang hebt.
-
tijdkolom: selecteer de kolom met de tijdsperioden voor de tijdreeks. De kolommen moeten van het type
timestampofdatezijn. - Prognosefrequentie: selecteer de tijdseenheid die de frequentie van uw invoergegevens vertegenwoordigt. Bijvoorbeeld minuten, uren, dagen, maanden. Hiermee bepaalt u de granulariteit van uw tijdreeks.
- Horizon voorspellen: Geef op hoeveel eenheden van de geselecteerde frequentie in de toekomst moeten worden voorspeld. Samen met de prognosefrequentie definieert dit zowel de tijdseenheden als het aantal tijdseenheden dat moet worden voorspeld.
Notitie
Als u het auto-ARIMA--algoritme wilt gebruiken, moet de tijdreeks een regelmatige frequentie hebben waarbij het interval tussen twee punten hetzelfde moet zijn gedurende de tijdreeks. AutoML verwerkt ontbrekende tijdstappen door deze waarden in te vullen met de vorige waarde.
-
tijdkolom: selecteer de kolom met de tijdsperioden voor de tijdreeks. De kolommen moeten van het type
Selecteer een doelkolom voor voorspelling die u door het model wilt laten voorspellen.
Geef desgewenst een Unity Catalog-tabel voorspellingsgegevenspad op om de uitvoerprognoses op te slaan.
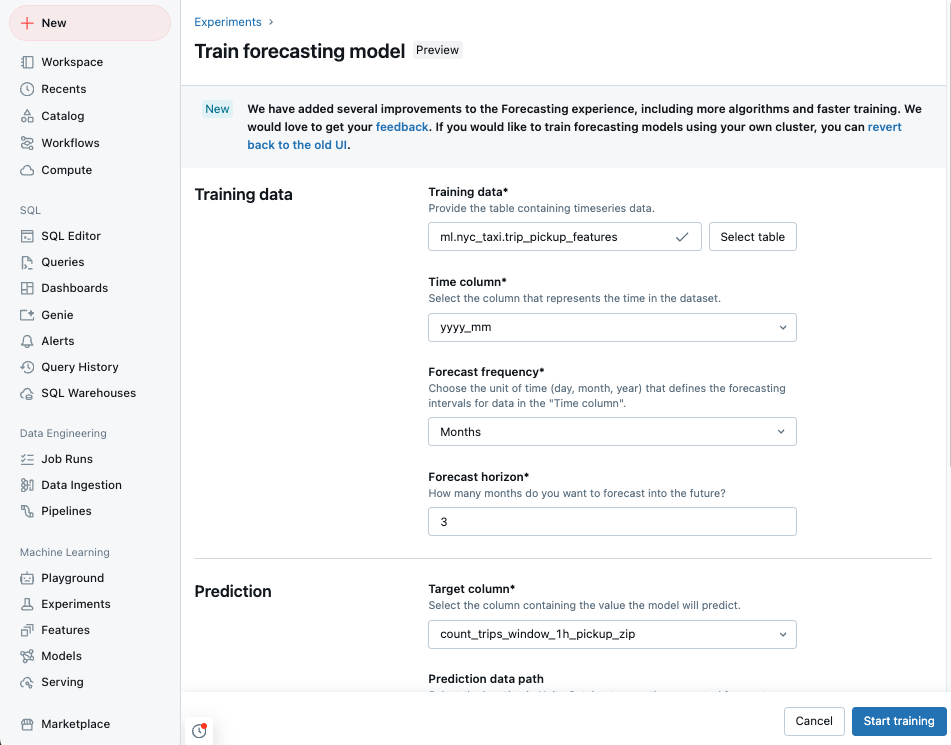
Selecteer een modelregistratie Unity Catalog-locatie en naam.
U kunt desgewenst Geavanceerde opties instellen:
- Naam van experiment: geef een MLflow-experimentnaam op.
- kolommen voor tijdreeks-id's: selecteer voor het voorspellen van meerdere reeksen de kolommen die de afzonderlijke tijdreeksen identificeren. Databricks groepeert de gegevens op deze kolommen als verschillende tijdreeksen en traint een model voor elke reeks afzonderlijk.
- primaire metrische gegevens: kies de primaire metrische waarde die wordt gebruikt om het beste model te evalueren en te selecteren.
- Trainingsframework: kies de frameworks voor AutoML die u wilt verkennen.
- kolom splitsen: selecteer de kolom met aangepaste gegevenssplitsing. Waarden moeten 'train', 'validate' en 'test' zijn.
- Gewichtskolom: specificeer de kolom die moet worden gebruikt voor het toepassen van gewichten op tijdreeksen. Alle monsters voor een bepaalde tijdreeks moeten hetzelfde gewicht hebben. Het gewicht moet binnen het bereik liggen [0, 10000].
- vakantieregio: selecteer de vakantieregio die u wilt gebruiken als covariabelen in modeltraining.
- Timeout: Stel een maximale duur in voor het AutoML-experiment.
Voer het experiment uit en bewaak de resultaten
Als u het AutoML-experiment wilt starten, klikt u op Training starten. Op de trainingspagina voor experimenten kunt u het volgende doen:
- Stop het experiment op elk gewenst moment.
- Runs monitoren.
- Navigeer naar de uitvoeringspagina voor elke uitvoering.
Resultaten weergeven of het beste model gebruiken
Nadat de training is voltooid, worden de voorspellingsresultaten opgeslagen in de opgegeven Delta-tabel en wordt het beste model geregistreerd bij Unity Catalog.
Op de pagina experimenten kiest u uit de volgende stappen:
- Selecteer Voorspellingen weergeven om de tabel met prognoseresultaten weer te geven.
- Selecteer Batch-inferentienotebook om een automatisch gegenereerd notitieboek te openen voor batchinference met behulp van het beste model.
- Selecteer Een service-eindpunt maken om het beste model te implementeren op een eindpunt voor modelbediening.
serverloze prognose versus klassieke rekenprognoses
De volgende tabel bevat een overzicht van de verschillen tussen serverloze voorspellingen en voorspellen met klassieke computertaken.
| Functie | Serverloze prognose | Klassieke rekenprognoses |
|---|---|---|
| Compute-infrastructuur | Azure Databricks beheert de rekenconfiguratie en optimaliseert automatisch voor kosten en prestaties. | Door de gebruiker geconfigureerde rekenkracht |
| Bestuur | Modellen en artefacten die zijn geregistreerd bij Unity Catalog | Door de gebruiker geconfigureerde werkruimtebestandsopslag |
| Algoritmeselectie | statistische modellen plus het neurale netwerkalgoritmen voor deep learning DeepAR- | statistische modellen |
| Integratie van feature store | Niet ondersteund | Ondersteunde |
| Automatisch gegenereerde notebooks | Notebook voor batch-inferentie | Broncode voor alle proefversies |
| Model met één klik voor implementatie | Ondersteund | Niet ondersteund |
| Aangepaste splitsingen trainen/valideren/testen | Ondersteund | Niet ondersteund |
| Aangepaste gewichten voor afzonderlijke tijdreeksen | Ondersteund | Niet ondersteund |