Prognose met AutoML (klassieke berekening)
Gebruik AutoML om automatisch het beste prognose-algoritme en de hyperparameterconfiguratie te vinden om waarden te voorspellen op basis van tijdreeksgegevens.
Tijdreeksprognoses zijn alleen beschikbaar voor Databricks Runtime 10.0 ML of hoger.
Prognoseexperiment instellen met de gebruikersinterface
U kunt een prognoseprobleem instellen met behulp van de AutoML-gebruikersinterface met de volgende stappen:
- Selecteer in de zijbalk Experimenten.
- Selecteer op de kaart Prognose maken de optie Start met trainen.
De prognosegebruikersinterface wordt standaard ingesteld op serverloze prognose . Als u toegang wilt krijgen tot prognoses met uw eigen rekenproces, selecteert u teruggaan naar de oude ervaring.
Het AutoML-experiment configureren
De pagina AutoML-experiment configureren wordt weergegeven. Op deze pagina configureert u het AutoML-proces, waarbij u de gegevensset, het probleemtype, de doel- of labelkolom opgeeft om te voorspellen, de metriek die wordt gebruikt om de experimentuitvoeringen te evalueren en te scoren, en de stopcondities.
Selecteer in het veld Compute een cluster met Databricks Runtime 10.0 ML of hoger.
Klik onder Gegevensset op Bladeren. Navigeer naar de tabel die u wilt gebruiken en klik op Selecteer. Het tabelschema wordt weergegeven.
Klik in het veld Voorspellingsdoel . Er wordt een vervolgkeuzemenu weergegeven met de kolommen die in het schema worden weergegeven. Selecteer de kolom die u wilt voorspellen in het model.
Klik in het veld in de kolom Tijd. Er verschijnt een vervolgkeuzelijst met de kolommen van de dataset die van het type
timestampofdatezijn. Selecteer de kolom met de tijdsperioden voor de tijdreeks.Selecteer de kolommen die de afzonderlijke tijdreeksen identificeren uit de tijdreeks-id's dropdownlijst voor het voorspellen van meerdere reeksen. AutoML groepeerde de gegevens op deze kolommen als verschillende tijdreeksen en traint een model voor elke reeks afzonderlijk. Als u dit veld leeg laat, gaat AutoML ervan uit dat de gegevensset één tijdreeks bevat.
Geef in de velden Prognose-horizon en -frequentie het aantal perioden in de toekomst op waarvoor AutoML voorspelde waarden moet berekenen. Voer in het linkervak het gehele aantal perioden in dat moet worden voorspeld. Selecteer de eenheden in het rechtervak.
Notitie
Als u Auto-ARIMA wilt gebruiken, moet de tijdreeks een normale frequentie hebben waarbij het interval tussen twee punten hetzelfde moet zijn gedurende de tijdreeks. De frequentie moet overeenkomen met de frequentie-eenheid die is opgegeven in de API-aanroep of in de AutoML-gebruikersinterface. AutoML verwerkt ontbrekende tijdstappen door deze waarden in te vullen met de vorige waarde.
In Databricks Runtime 11.3 LTS ML en hoger kunt u voorspellingsresultaten opslaan. Geef hiervoor een database op in het veld Uitvoerdatabase . Klik op Bladeren en selecteer een database in het dialoogvenster. AutoML schrijft de voorspellingsresultaten naar een tabel in deze database.
In het veld Experimentnaam wordt de standaardnaam weergegeven. Als u deze wilt wijzigen, typt u de nieuwe naam in het veld.
U kunt ook het volgende doen:
- Geef aanvullende configuratieopties op.
- Gebruik bestaande functietabellen in Feature Store om de oorspronkelijke invoergegevenssette verbeteren.
Geavanceerde configuraties
Open het gedeelte Geavanceerde configuratie (optioneel) om toegang te krijgen tot deze parameters.
- De metrische evaluatiewaarde is de primaire metriek die wordt gebruikt om de uitvoeringen te beoordelen.
- In Databricks Runtime 10.4 LTS ML en hoger kunt u trainingsframeworks uitsluiten van overweging. AutoML traint standaard modellen met behulp van frameworks die worden vermeld onder AutoML-algoritmen.
- U kunt de stopvoorwaarden bewerken. Standaardcondities voor stoppen zijn:
- Voor het voorspellen van experimenten stopt u na 120 minuten.
- Stop in Databricks Runtime 10.4 LTS ML en hieronder voor classificatie- en regressieexperimenten na 60 minuten of na het voltooien van 200 proefversies, afhankelijk van wat het eerst gebeurt. Voor Databricks Runtime 11.0 ML en hoger wordt het aantal experimenten niet gebruikt als stopvoorwaarde.
- In Databricks Runtime 10.4 LTS ML en hoger, voor classificatie- en regressieexperimenten, omvat AutoML vroege stop; het stopt met het trainen en afstemmen van modellen als de metrische validatiegegevens niet meer worden verbeterd.
- In Databricks Runtime 10.4 LTS ML en hoger kunt u een
time columnselecteren om de gegevens te splitsen voor training, validatie en testen in chronologische volgorde (alleen van toepassing op classificatie en regressie). - Databricks raadt aan het veld Gegevensmap niet in te vullen. Hierdoor wordt het standaardgedrag geactiveerd voor het veilig opslaan van de gegevensset als een MLflow-artefact. Een DBFS-pad kan worden opgegeven, maar in dit geval neemt de gegevensset de toegangsmachtigingen van het AutoML-experiment niet over.
Voer het experiment uit en bewaak de resultaten
Klik op AutoML starten om het AutoML-experiment te starten. Het experiment wordt uitgevoerd en de AutoML-trainingspagina wordt weergegeven. Als u de uitvoeringstabel wilt vernieuwen, klikt u op  .
.
Voortgang van experiment weergeven
Op deze pagina kunt u het volgende doen:
- Stop het experiment op elk gewenst moment.
- Open het notebook voor gegevensverkenning.
- Uitvoeringen bewaken.
- Navigeer naar de uitvoeringspagina voor elke uitvoering.
Met Databricks Runtime 10.1 ML en hoger geeft AutoML waarschuwingen weer voor mogelijke problemen met de gegevensset, zoals niet-ondersteunde kolomtypen of kolommen met hoge kardinaliteit.
Notitie
Databricks doet het beste om potentiële fouten of problemen aan te geven. Dit is echter mogelijk niet uitgebreid en legt mogelijk de problemen of fouten die u zoekt niet vast.
Als u waarschuwingen voor de gegevensset wilt zien, klikt u op het tabblad Waarschuwingen op de trainingspagina of op de experimentpagina nadat het experiment is voltooid.
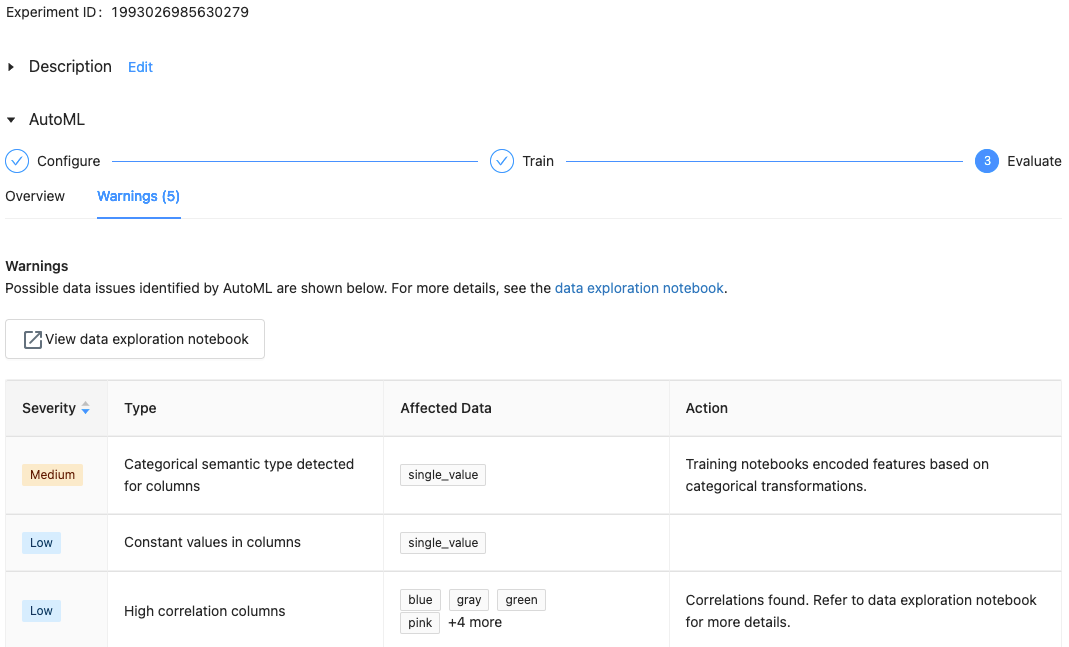
Resultaten weergeven
Wanneer het experiment is voltooid, kunt u het volgende doen:
- Registreer en implementeer een van de modellen met MLflow.
- Selecteer Notitieblok weergeven voor het beste model om het notitieblok te controleren en te bewerken waarmee het beste model is gemaakt.
- Selecteer Notebook voor gegevensverkenning weergeven om het notitieblok voor gegevensverkenning te openen.
- Zoek, filter en sorteer de runs in de runstabel.
- Zie de details voor elke uitvoering:
- Het gegenereerde notebook met broncode voor een proefuitvoering vindt u door te klikken op de MLflow-uitvoering. Het notebook wordt opgeslagen in de sectie Artefacten van de uitvoeringspagina. U kunt dit notitieblok downloaden en importeren in de werkruimte als het downloaden van artefacten is ingeschakeld door uw werkruimtebeheerders.
- Als u de uitvoeringsresultaten wilt weergeven, klikt u in de kolom Modellen of de Starttijd kolom. De uitvoeringspagina wordt weergegeven met informatie over de proefversie (zoals parameters, metrische gegevens en tags) en artefacten die door de uitvoering zijn gemaakt, inclusief het model. Deze pagina bevat ook codefragmenten die u kunt gebruiken om voorspellingen te doen met het model.
Als u later wilt terugkeren naar dit AutoML-experiment, zoekt u het in de tabel op de pagina Experimenten. De resultaten van elk AutoML-experiment, inclusief de notebooks voor gegevensverkenning en training, worden opgeslagen in een databricks_automl map in de basismap van de gebruiker die het experiment heeft uitgevoerd.
Een model registreren en implementeren
U kunt uw model registreren en implementeren met de AutoML-gebruikersinterface:
- Selecteer de koppeling in de kolom Modellen om het model te registreren. Wanneer een uitvoering is voltooid, is de bovenste rij het beste model (op basis van de primaire metriek).
- Selecteer de knoppen
 om het model te registreren in Modelregister.
om het model te registreren in Modelregister. - Selecteer
 modellen in de zijbalk om naar het modelregister te navigeren.
modellen in de zijbalk om naar het modelregister te navigeren. - Selecteer de naam van uw model in de modeltabel.
- Op de geregistreerde modelpagina kunt u het model bedienen met Model Serving.
Geen module met de naam pandas.core.indexes.numeriek
Bij het leveren van een model dat is gebouwd met behulp van AutoML met Model Serving, krijgt u mogelijk de foutmelding: No module named 'pandas.core.indexes.numeric.
Dit komt door een incompatibele pandas versie tussen AutoML en het model voor eindpuntomgeving. U kunt deze fout oplossen door het add-pandas-dependency.py script uit te voeren. Het script bewerkt het requirements.txt en conda.yaml voor het vastgelegde model om de juiste pandas afhankelijkheidsversie op te nemen: pandas==1.5.3
- Wijzig het script om de
run_idvan de MLflow-run op te nemen waarin uw model is gelogd. - Het model opnieuw registreren bij het MLflow-modelregister.
- Probeer de nieuwe versie van het MLflow-model te leveren.