Wat betekenen tokens per secondebereik in ingerichte doorvoer?
In dit artikel wordt beschreven hoe en waarom Databricks tokens per seconde meet voor workloads met ingerichte doorvoer voor de Foundation Model-API's.
Prestaties voor grote taalmodellen (LLM's) worden vaak gemeten in termen van tokens per seconde. Bij het configureren van productiemodel voor eindpunten is het belangrijk om rekening te houden met het aantal aanvragen dat uw toepassing naar het eindpunt verzendt. Dit helpt u te begrijpen of uw eindpunt moet worden geconfigureerd om te worden geschaald, zodat de latentie niet wordt beïnvloed.
Bij het configureren van de uitschaalbereiken voor eindpunten die zijn geïmplementeerd met ingerichte doorvoer, heeft Databricks het gemakkelijker gevonden om te redeneren over de invoer in uw systeem met behulp van tokens.
Wat zijn tokens?
LLM's lezen en generate tekst in termen van wat een token wordt genoemd. Tokens kunnen woorden of subwoorden zijn en de exacte regels voor het splitsen van tekst in tokens variëren van model tot model. U kunt bijvoorbeeld onlinehulpprogramma's gebruiken om te zien hoe Tokenizer van Llama woorden converteert naar tokens.
In het volgende diagram ziet u een voorbeeld van hoe de Llama-tokenizer tekst opbreekt:

Waarom de LLM-prestaties meten in termen van tokens per seconde?
Traditioneel worden service-eindpunten geconfigureerd op basis van het aantal gelijktijdige aanvragen per seconde (RPS). Een LLM-inferentieverzoek neemt echter een verschillende tijd in beslag, afhankelijk van het aantal tokens dat wordt doorgegeven en het aantal dat wordt gegenereerd, wat ongelijk verdeeld kan zijn over verzoeken. Daarom vereist het bepalen hoeveel schaalvergroting uw eindpunt nodig heeft, echt het meten van de schaal van het eindpunt in termen van de inhoud van uw verzoek - tokens.
Verschillende use cases hebben verschillende verhoudingen tussen invoer- en uitvoertoken:
- verschillende lengten van invoercontexten: hoewel sommige aanvragen mogelijk slechts enkele invoertokens bevatten, bijvoorbeeld een korte vraag, kunnen andere honderden of zelfs duizenden tokens omvatten, zoals een lang document voor samenvatting. Deze variabiliteit maakt het configureren van een service-eindpunt alleen op basis van RPS lastig, omdat het niet rekening houdt met de verschillende verwerkingsvereisten van de verschillende aanvragen.
- verschillende lengten van uitvoer, afhankelijk van gebruiksvoorbeelden: verschillende gebruiksvoorbeelden voor LLM's kunnen leiden tot zeer verschillende uitvoertokenlengten. Het genereren van uitvoertokens is het meest tijdrovende deel van LLM-deductie, zodat dit de doorvoer aanzienlijk kan beïnvloeden. Samenvatting omvat bijvoorbeeld kortere, pithier antwoorden, maar het genereren van tekst, zoals het schrijven van artikelen of productbeschrijvingen, kan veel langere antwoorden generate.
Hoe select ik de tokens per secondebereik voor mijn eindpunt?
De geconfigureerde doorvoercapaciteit voor serverende eindpunten wordt uitgedrukt in een bereik van tokens per seconde dat u naar het eindpunt kunt verzenden. Het eindpunt wordt omhoog en omlaag geschaald om de belasting van uw productietoepassing af te handelen. Er worden kosten per uur in rekening gebracht op basis van het bereik van tokens per seconde waarnaar uw eindpunt is geschaald.
De beste manier om te weten welke tokens per seconde bereik op uw geconfigureerde doorvoereindpunt voor uw gebruiksscenario werken, is door een belastingstest uit te voeren met een representatieve dataset. Zie Voer uw eigen benchmark van LLM-eindpunt uit.
Er zijn twee belangrijke factoren om rekening mee te houden:
- Hoe Databricks de prestaties in tokens per seconde van de LLM meet.
- Hoe automatisch schalen werkt.
Hoe Databricks de prestaties van tokens per seconde meet bij de LLM.
Databricks beoordeelt eindpunten aan de hand van een workload die samenvattingstaken kenmerkt die gebruikelijk zijn voor use cases voor door retrieval versterkte generatie. De workload bestaat met name uit:
- 2048 invoertokens
- 256 uitvoertokens
De tokenbereiken die worden weergegeven combineren doorvoer van invoer- en uitvoertoken en standaard optimize voor het verdelen van doorvoer en latentie.
Databricks-benchmarks tonen aan dat gebruikers dat aantal tokens per seconde gelijktijdig naar de eindpunt kunnen verzenden, met een batchgrootte van 1 per aanvraag. Hiermee simuleert u meerdere aanvragen die tegelijkertijd het eindpunt bereiken, wat nauwkeuriger aangeeft hoe u het eindpunt daadwerkelijk in productie zou gebruiken.
- Als een ingerichte doorvoer voor een eindpunt bijvoorbeeld een set snelheid van 2304 tokens per seconde heeft (2048 + 256), duurt één aanvraag met een invoer van 2048 tokens en een verwachte uitvoer van 256 tokens ongeveer één seconde om uit te voeren.
- Als de snelheid tussen set en 5600 ligt, kunt u één aanvraag verwachten waarbij het aantal invoer- en uitvoertokens, zoals hierboven vermeld, ongeveer 0,5 seconden in beslag neemt. Dit betekent dat het eindpunt in staat is om twee vergelijkbare aanvragen in ongeveer één seconde te verwerken.
Als uw workload verschilt van het bovenstaande, kunt u verwachten dat de latentie varieert met betrekking tot de vermelde ingerichte doorvoersnelheid. Zoals eerder vermeld, is het genereren van meer uitvoertokens tijdrovender dan het opnemen van meer invoertokens. Als u batchdeductie uitvoert en de hoeveelheid tijd wilt schatten die nodig is om te voltooien, kunt u het gemiddelde aantal invoer- en uitvoertokens berekenen en vergelijken met de bovenstaande Databricks-benchmarkworkload.
- Als u bijvoorbeeld 1000 rijen hebt, met een gemiddelde invoertokentelling van 3000 en een gemiddeld aantal uitvoertokens van 500 en een ingerichte doorvoer van 3500 tokens per seconde, kan het langer duren dan 1000 seconden (één seconde per rij), omdat uw gemiddelde tokenaantallen groter dan de Databricks-benchmark.
- Als u 1000 rijen hebt, een gemiddelde invoer van 1500 tokens, een gemiddelde uitvoer van 100 tokens en een ingerichte doorvoer van 1600 tokens per seconde, kan het minder dan 1000 seconden in totaal (één seconde per rij) duren omdat uw gemiddelde tokenaantal minder is dan de Databricks-benchmark.
Als u een schatting wilt maken van de ideale geprovisioneerde doorvoer die nodig is om uw batchinference-workload af te ronden, kunt u het notebook in de Batch LLM-inference uitvoeren met behulp van ai_query gebruiken.
Hoe automatisch schalen werkt
ModelService biedt een snel automatisch schalend systeem waarmee de onderliggende rekenkracht wordt geschaald om te voldoen aan de tokens per seconde vraag van uw toepassing. Databricks schaalt voorzien doorvoer op in segmenten van tokens per seconde, dus er worden alleen extra eenheden van voorzien doorvoer in rekening gebracht wanneer u ze gebruikt.
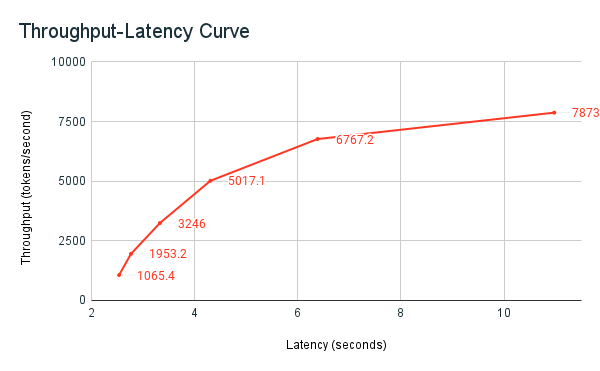
In de volgende grafiek met doorvoerlatentie ziet u een getest ingerichte doorvoereindpunt met een toenemend aantal parallelle aanvragen. Het eerste punt vertegenwoordigt 1 aanvraag, de tweede, 2 parallelle aanvragen, het derde, 4 parallelle aanvragen, enzovoort. Naarmate het aantal aanvragen toeneemt en op zijn beurt de vraag naar tokens per seconde, ziet u dat de voorziening van de doorvoer ook toeneemt. Deze toename geeft aan dat automatisch schalen de beschikbare rekenkracht verhoogt. U kunt echter mogelijk zien dat de doorvoer begint af te vlakken, waardoor een limit van ~8000 tokens per seconde wordt bereikt doordat er meer parallelle aanvragen worden gedaan. De totale latentie neemt toe naarmate meer aanvragen in de wachtrij moeten wachten voordat ze worden verwerkt, omdat de toegewezen rekenkracht tegelijkertijd wordt gebruikt.
Notitie
U kunt de doorvoer consistent houden door scale-to-zero uit te schakelen en een minimale doorvoer op het servereindpunt te configureren. Als u dit doet, hoeft u niet te wachten totdat het eindpunt omhoog wordt geschaald.
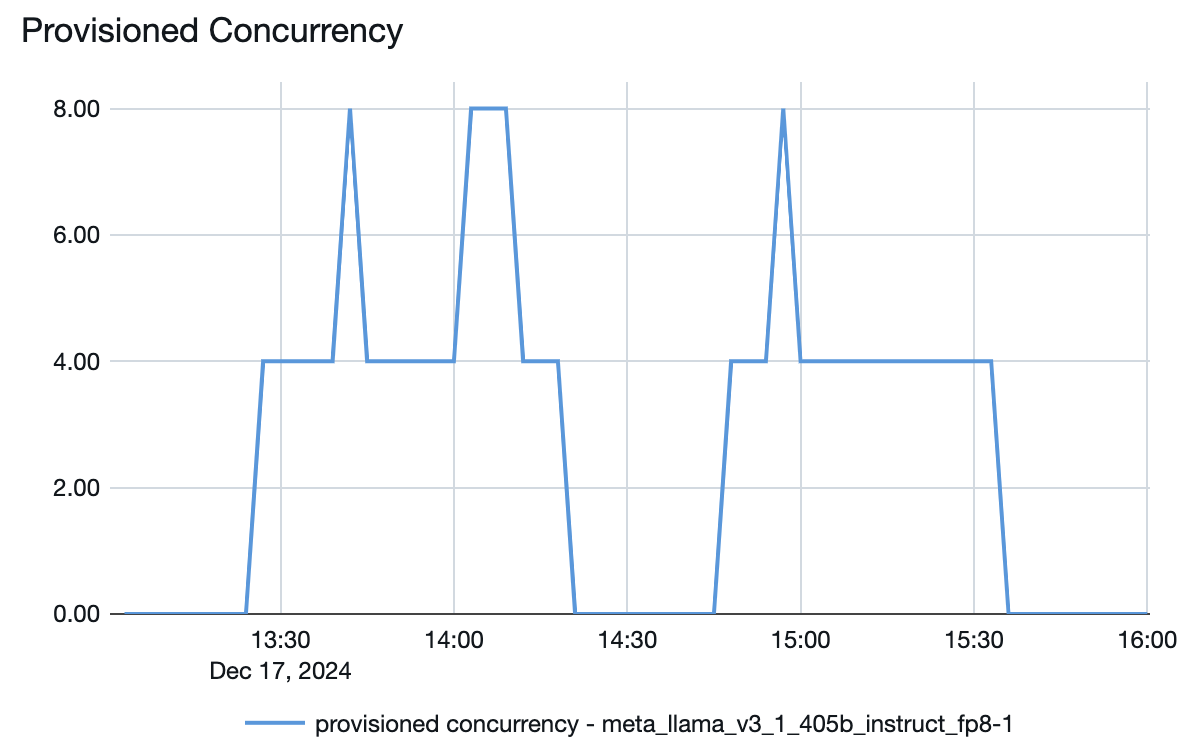
U kunt ook zien vanuit het model dat eindpunten bedient, hoe resources omhoog of omlaag worden uitgesplitst, afhankelijk van de vraag:
afbeelding van gpu-gebruik