Uw eigen LLM-eindpuntbenchmarking uitvoeren
Dit artikel bevat een door Databricks aanbevolen notebookvoorbeeld voor het benchmarken van een LLM-eindpunt. Het bevat ook een korte inleiding tot hoe Databricks LLM-deductie uitvoert en latentie en doorvoer berekent als metrische gegevens over eindpuntprestaties.
LLM-inferentie op Databricks meet tokens per seconde voor de geconfigureerde doorvoermodus voor Foundation Model-API's. Zie Wat betekenen tokens per seconde-bereik in ingerichte doorvoer?.
Benchmark-voorbeeldnotitieblok
U kunt het volgende notebook importeren in uw Databricks-omgeving en de naam van uw LLM-eindpunt opgeven om een loadtest uit te voeren.
Een LLM-eindpunt benchmarken
inleiding tot LLM-inferentie
LLM's voeren deductie uit in een proces in twee stappen:
- Vulvooraf in, worden de tokens in de invoerprompt where parallel verwerkt.
- decodering van, wordt where tekst één token tegelijk gegenereerd op een automatische regressieve manier. Elk gegenereerd token wordt aan de invoer toegevoegd en teruggegeven aan het model om het volgende token te generate. Genereren stopt wanneer de LLM een speciaal stoptoken uitvoert of wanneer aan een door de gebruiker gedefinieerde voorwaarde wordt voldaan.
De meeste productietoepassingen hebben een latentiebudget en Databricks raadt u aan om de doorvoer te maximaliseren op basis van dat latentiebudget.
- Het aantal invoertokens heeft een aanzienlijke invloed op het vereiste geheugen voor het verwerken van aanvragen.
- Het aantal uitvoertokens overheerst de totale reactielatentie.
Databricks verdeelt LLM-deductie in de volgende submetrieken:
- Tijd voor het eerste token (TTFT): Dit is hoe snel gebruikers de uitvoer van het model zien nadat ze hun query hebben ingevoerd. Lage wachttijden voor een reactie zijn essentieel in realtime interacties, maar minder belangrijk in offlineworkloads. Deze metrische waarde wordt bepaald door de tijd die nodig is om de prompt te verwerken en vervolgens generate het eerste uitvoertoken.
- Tijd per uitvoertoken (TPOT): Tijd om een uitvoertoken te generate voor elke gebruiker die een query op het systeem uitvoert. Deze metrische waarde komt overeen met de manier waarop elke gebruiker de 'snelheid' van het model waarneemt. Een TPOT van 100 milliseconden per token is bijvoorbeeld 10 tokens per seconde of ~450 woorden per minuut, wat sneller is dan een typische persoon kan lezen.
Op basis van deze metrische gegevens kan de totale latentie en doorvoer als volgt worden gedefinieerd:
- latentie = TTFT + (TPOT) * (het aantal tokens dat moet worden gegenereerd)
- doorvoer = aantal uitvoertokens per seconde voor alle gelijktijdigheidsaanvragen
Op Databricks kunnen LLM-eindpunten worden opgeschaald om aan te sluiten bij de belasting van verkeer afkomstig van clients met meerdere gelijktijdige aanvragen. Er is een afweging tussen latentie en doorvoer. Op LLM-eindpunten kunnen gelijktijdige aanvragen tegelijkertijd worden verwerkt. Bij lage gelijktijdige aanvraagbelastingen is latentie het laagst mogelijk. Als u echter de belasting van de aanvraag verhoogt, kan de latentie stijgen, maar de doorvoer neemt waarschijnlijk ook toe. Dit komt doordat twee aanvragen van tokens per seconde in minder dan twee keer zoveel tijd kunnen worden verwerkt.
Daarom is het beheren van het aantal parallelle aanvragen in uw systeem de kern van het verdelen van latentie met doorvoer. Als u een use-case met lage latentie hebt, wilt u minder gelijktijdige aanvragen naar het eindpunt verzenden om de latentie laag te houden. Als u een use-case voor hoge doorvoer hebt, wilt u het eindpunt overbelasten met veel gelijktijdigheidsaanvragen, omdat een hogere doorvoer het waard is, zelfs ten koste van latentie.
- Gebruiksvoorbeelden voor hoge doorvoer kunnen batchdeducties en andere niet-gebruikersgerichte taken bevatten.
- Gebruiksscenario's met lage latentie kunnen realtime-toepassingen bevatten waarvoor onmiddellijke reacties nodig zijn.
Databricks benchmarking-omgeving
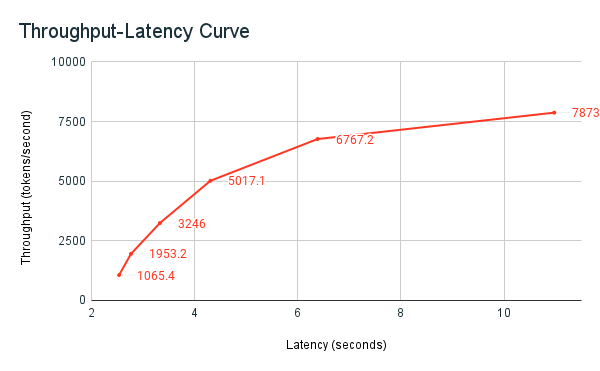
De eerder gedeelde voorbeeldnotebook voor benchmarking is het Databricks-benchmarking-harnas. Het notebook geeft de totale latentie weer voor alle aanvragen en metrische doorvoergegevens en plot de doorvoer versus latentiecurve voor verschillende aantallen parallelle aanvragen. De strategie voor het automatisch schalen van Databricks-eindpunten vindt een balans tussen latentie en doorvoer. In het notebook ziet u dat latentie en doorvoer toenemen naarmate meer gelijktijdige gebruikers query's uitvoeren op het eindpunt.
U begint echter ook te zien dat naarmate het aantal parallelle aanvragen toeneemt, de doorvoer een plateau bereikt, met een limit van ongeveer 8000 tokens per seconde. Dit plateau treedt op omdat de voorziene doorvoer voor het eindpunt het aantal werknemers en parallelle aanvragen die kunnen worden uitgevoerd, beperkt. Naarmate er meer aanvragen worden gedaan dan wat het eindpunt tegelijkertijd kan verwerken, blijft de totale latentie toenemen naarmate er extra aanvragen in de wachtrij wachten.
Meer informatie over de Databricks-filosofie over LLM-prestatiebenchmarking wordt beschreven in de LLM Inference Performance Engineering: Best Practices blog.