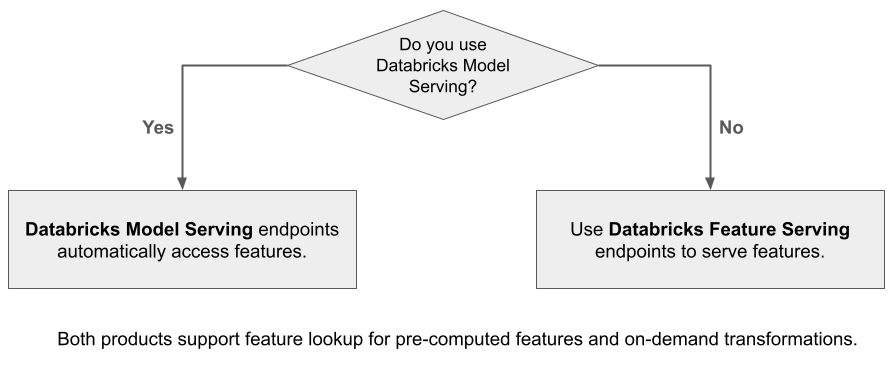
Wat is databricks-functie?
Databricks Feature Serving maakt gegevens beschikbaar in het Databricks-platform voor modellen of toepassingen die buiten Azure Databricks zijn geïmplementeerd. Functie voor eindpunten automatisch schalen om aan te passen aan realtime verkeer en een service met hoge beschikbaarheid en lage latentie te bieden voor het leveren van functies. Op deze pagina wordt beschreven hoe u Feature Serving instelt en gebruikt. Zie Een functie implementeren en er query's op uitvoeren voor een eindpunt voor een stapsgewijze zelfstudie.
Wanneer u Mosaic AI Model Serving gebruikt om een model te leveren dat is gebouwd met behulp van functies van Databricks, zoekt het model automatisch functies op en transformeert deze voor deductieaanvragen. Met Databricks Feature Serving kunt u gestructureerde gegevens leveren voor het ophalen van augmented generation-toepassingen (RAG), evenals functies die vereist zijn voor andere toepassingen, zoals modellen die buiten Databricks worden geleverd of een andere toepassing waarvoor functies zijn vereist op basis van gegevens in Unity Catalog.
Waarom functie serveren gebruiken?
Databricks Feature Serving biedt één interface die vooraf gerealiseerde en on-demand functies bedient. Het bevat ook de volgende voordelen:
- Eenvoud. Databricks verwerkt de infrastructuur. Met één API-aanroep maakt Databricks een productieklare serviceomgeving.
- Hoge beschikbaarheid en schaalbaarheid. Functie voor het leveren van eindpunten wordt automatisch omhoog en omlaag geschaald om het volume van het verwerken van aanvragen aan te passen.
- Beveiliging. Eindpunten worden geïmplementeerd in een beveiligde netwerkgrens en gebruiken toegewezen rekenkracht die eindigt wanneer het eindpunt wordt verwijderd of geschaald naar nul.
Eisen
- Databricks Runtime 14.2 ML of hoger.
- Voor het gebruik van de Python-API is voor Feature Serving versie 0.1.2 of hoger vereist
databricks-feature-engineering. Deze is ingebouwd in Databricks Runtime 14.2 ML. Voor eerdere Versies van Databricks Runtime ML moet u de vereiste versie handmatig installeren met behulp van%pip install databricks-feature-engineering>=0.1.2. Als u een Databricks-notebook gebruikt, moet u de Python-kernel opnieuw starten door deze opdracht uit te voeren in een nieuwe cel:dbutils.library.restartPython(). - Als u de Databricks SDK wilt gebruiken, is voor Feature Serving versie 0.18.0 of hoger vereist
databricks-sdk. Als u de vereiste versie handmatig wilt installeren, gebruikt u%pip install databricks-sdk>=0.18.0. Als u een Databricks-notebook gebruikt, moet u de Python-kernel opnieuw starten door deze opdracht uit te voeren in een nieuwe cel:dbutils.library.restartPython().
Databricks Feature Serving biedt een gebruikersinterface en verschillende programmatische opties voor het maken, bijwerken, opvragen en verwijderen van eindpunten. Dit artikel bevat instructies voor elk van de volgende opties:
- Databricks-gebruikersinterface
- REST-API
- Python-API
- Databricks SDK
Als u de REST API of MLflow Deployments SDK wilt gebruiken, moet u een Databricks API-token hebben.
Belangrijk
Als best practice voor beveiliging voor productiescenario's raadt Databricks u aan om OAuth-tokens voor machine-naar-machine te gebruiken voor verificatie tijdens de productie.
Voor testen en ontwikkelen raadt Databricks aan om een persoonlijk toegangstoken te gebruiken dat hoort bij service-principals in plaats van werkruimtegebruikers. Zie Tokens voor een service-principal beheren om tokens voor service-principals te maken.
Verificatie voor functiebediening
Zie Verificatietoegang tot Azure Databricks-resources voor meer informatie over verificatie.
Maak een FeatureSpec
Een FeatureSpec is een door de gebruiker gedefinieerde set functies en functies. U kunt functies en functies combineren in een FeatureSpec. FeatureSpecs worden opgeslagen in en beheerd door Unity Catalog en worden weergegeven in Catalog Explorer.
De tabellen die in een FeatureSpec tabel zijn opgegeven, moeten worden gepubliceerd naar een onlinetabel of een onlinewinkel van derden. Zie Onlinetabellen gebruiken voor realtime-functies of online winkels van derden.
U moet het databricks-feature-engineering pakket gebruiken om een FeatureSpec.
from databricks.feature_engineering import (
FeatureFunction,
FeatureLookup,
FeatureEngineeringClient,
)
fe = FeatureEngineeringClient()
features = [
# Lookup column `average_yearly_spend` and `country` from a table in UC by the input `user_id`.
FeatureLookup(
table_name="main.default.customer_profile",
lookup_key="user_id",
feature_names=["average_yearly_spend", "country"]
),
# Calculate a new feature called `spending_gap` - the difference between `ytd_spend` and `average_yearly_spend`.
FeatureFunction(
udf_name="main.default.difference",
output_name="spending_gap",
# Bind the function parameter with input from other features or from request.
# The function calculates a - b.
input_bindings={"a": "ytd_spend", "b": "average_yearly_spend"},
),
]
# Create a `FeatureSpec` with the features defined above.
# The `FeatureSpec` can be accessed in Unity Catalog as a function.
fe.create_feature_spec(
name="main.default.customer_features",
features=features,
)
Een eindpunt maken
Het FeatureSpec eindpunt wordt gedefinieerd. Zie Aangepast model maken voor eindpunten, de Python-API-documentatie of de Databricks SDK-documentatie voor meer informatie.
Notitie
Voor workloads die latentiegevoelig zijn of hoge query's per seconde vereisen, biedt Model Serving routeoptimalisatie voor aangepaste eindpunten voor het leveren van modellen. Zie Routeoptimalisatie configureren voor het leveren van eindpunten.
REST-API
curl -X POST -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints \
-H 'Content-Type: application/json' \
-d '"name": "customer-features",
"config": {
"served_entities": [
{
"entity_name": "main.default.customer_features",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
]
}'
Databricks SDK - Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
workspace = WorkspaceClient()
# Create endpoint
workspace.serving_endpoints.create(
name="my-serving-endpoint",
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
Python-API
from databricks.feature_engineering.entities.feature_serving_endpoint import (
ServedEntity,
EndpointCoreConfig,
)
fe.create_feature_serving_endpoint(
name="customer-features",
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name="main.default.customer_features",
workload_size="Small",
scale_to_zero_enabled=True,
instance_profile_arn=None,
)
)
)
Als u het eindpunt wilt zien, klikt u op Serveren in de linkerzijbalk van de Databricks-gebruikersinterface. Wanneer de status Gereed is, is het eindpunt klaar om te reageren op query's. Zie Mosaic AI Model Serving voor meer informatie over Mosaic AI Model Serving.
Een eindpunt ophalen
U kunt de Databricks SDK of de Python-API gebruiken om de metagegevens en status van een eindpunt op te halen.
Databricks SDK - Python
endpoint = workspace.serving_endpoints.get(name="customer-features")
# print(endpoint)
Python-API
endpoint = fe.get_feature_serving_endpoint(name="customer-features")
# print(endpoint)
Het schema van een eindpunt ophalen
U kunt de REST API gebruiken om het schema van een eindpunt op te halen. Zie Een model ophalen voor eindpuntschema voor meer informatie over het eindpuntschema.
ACCESS_TOKEN=<token>
ENDPOINT_NAME=<endpoint name>
curl "https://example.databricks.com/api/2.0/serving-endpoints/$ENDPOINT_NAME/openapi" -H "Authorization: Bearer $ACCESS_TOKEN" -H "Content-Type: application/json"
Een query uitvoeren op een eindpunt
U kunt de REST API, de MLflow Deployments SDK of de gebruikersinterface van de server gebruiken om een query uit te voeren op een eindpunt.
De volgende code laat zien hoe u referenties instelt en de client maakt wanneer u de MLflow Deployments SDK gebruikt.
# Set up credentials
export DATABRICKS_HOST=...
export DATABRICKS_TOKEN=...
# Set up the client
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Notitie
Als best practice voor beveiliging, wanneer u zich verifieert met geautomatiseerde hulpprogramma's, systemen, scripts en apps, raadt Databricks u aan om persoonlijke toegangstokens te gebruiken die behoren tot service-principals in plaats van werkruimtegebruikers. Zie Tokens voor een service-principal beheren om tokens voor service-principals te maken.
Een query uitvoeren op een eindpunt met behulp van API's
Deze sectie bevat voorbeelden van het uitvoeren van query's op een eindpunt met behulp van de REST API of de MLflow Deployments SDK.
REST-API
curl -X POST -u token:$DATABRICKS_API_TOKEN $ENDPOINT_INVOCATION_URL \
-H 'Content-Type: application/json' \
-d '{"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]}'
MLflow Deployments SDK
Belangrijk
In het volgende voorbeeld wordt de predict() API van de MLflow Deployments SDK gebruikt. Deze API is experimenteel en de API-definitie kan veranderen.
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint="test-feature-endpoint",
inputs={
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280},
]
},
)
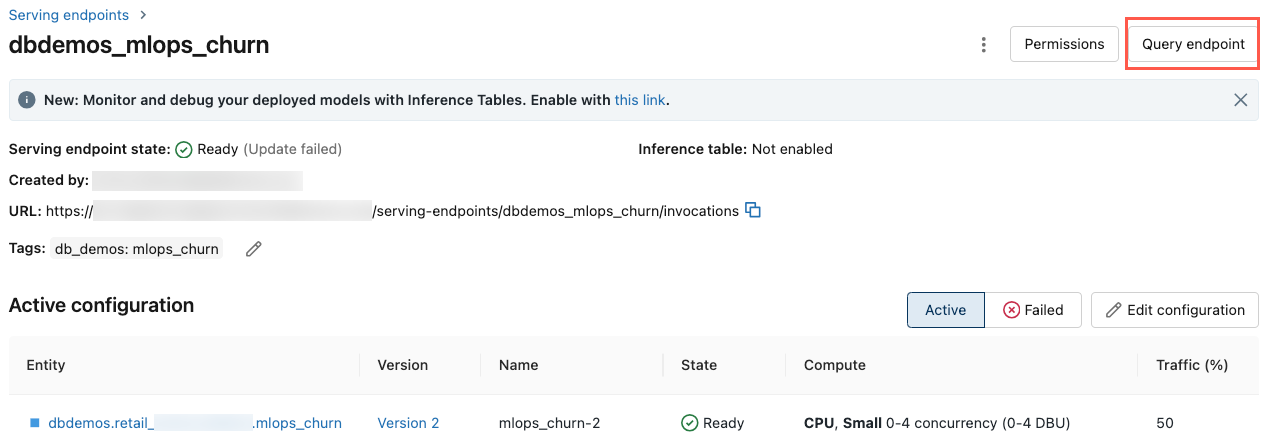
Een eindpunt opvragen met behulp van de gebruikersinterface
U kunt rechtstreeks vanuit de gebruikersinterface van de server een query uitvoeren op een eindpunt voor een server. De gebruikersinterface bevat gegenereerde codevoorbeelden die u kunt gebruiken om een query uit te voeren op het eindpunt.
Klik in de linkerzijbalk van de Azure Databricks-werkruimte op Serveren.
Klik op het eindpunt waarop u een query wilt uitvoeren.
Klik in de rechterbovenhoek van het scherm op Query-eindpunt.
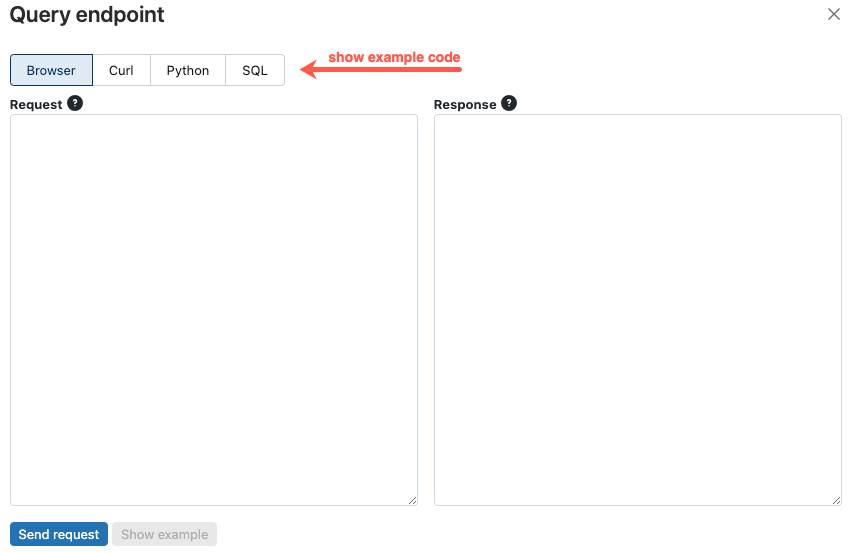
Typ in het vak Aanvraag de hoofdtekst van de aanvraag in JSON-indeling.
Klik op Aanvraag verzenden.
// Example of a request body.
{
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]
}
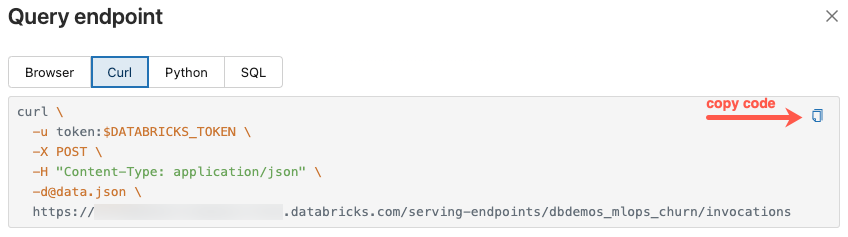
Het dialoogvenster Query-eindpunt bevat gegenereerde voorbeeldcode in curl, Python en SQL. Klik op de tabbladen om de voorbeeldcode weer te geven en te kopiëren.
Als u de code wilt kopiëren, klikt u op het kopieerpictogram in de rechterbovenhoek van het tekstvak.
Een eindpunt bijwerken
U kunt een eindpunt bijwerken met behulp van de REST API, de Databricks SDK of de gebruikersinterface van de server.
Een eindpunt bijwerken met behulp van API's
REST-API
curl -X PUT -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>/config \
-H 'Content-Type: application/json' \
-d '"served_entities": [
{
"name": "customer-features",
"entity_name": "main.default.customer_features_new",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
]'
Databricks SDK - Python
workspace.serving_endpoints.update_config(
name="my-serving-endpoint",
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
Een eindpunt bijwerken met behulp van de gebruikersinterface
Volg deze stappen om de gebruikersinterface van de server te gebruiken:
- Klik in de linkerzijbalk van de Azure Databricks-werkruimte op Serveren.
- Klik in de tabel op de naam van het eindpunt dat u wilt bijwerken. Het eindpuntscherm wordt weergegeven.
- Klik in de rechterbovenhoek van het scherm op Eindpunt bewerken.
- Bewerk de eindpuntinstellingen indien nodig in het dialoogvenster Voor het verwerken van eindpunten bewerken.
- Klik op Bijwerken om uw wijzigingen op te slaan.

Een eindpunt verwijderen
Waarschuwing
Deze actie kan niet ongedaan worden genomen.
U kunt een eindpunt verwijderen met behulp van de REST API, de Databricks SDK, de Python-API of de gebruikersinterface van de server.
Een eindpunt verwijderen met behulp van API's
REST-API
curl -X DELETE -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>
Databricks SDK - Python
workspace.serving_endpoints.delete(name="customer-features")
Python-API
fe.delete_feature_serving_endpoint(name="customer-features")
Een eindpunt verwijderen met behulp van de gebruikersinterface
Volg deze stappen om een eindpunt te verwijderen met behulp van de gebruikersinterface van De server:
- Klik in de linkerzijbalk van de Azure Databricks-werkruimte op Serveren.
- Klik in de tabel op de naam van het eindpunt dat u wilt verwijderen. Het eindpuntscherm wordt weergegeven.
- Klik in de rechterbovenhoek van het scherm ophetmenu
 en selecteer Verwijderen.
en selecteer Verwijderen.

De status van een eindpunt bewaken
Zie Modelkwaliteit en eindpuntstatus bewaken voor informatie over de logboeken en metrische gegevens die beschikbaar zijn voor functie-eindpunten.
Toegangsbeheer
Zie Machtigingen beheren voor uw model voor eindpunten voor het leveren van functies voor informatie over machtigingen voor functie-eindpunten.
Voorbeeld van notebook
In dit notebook ziet u hoe u de Databricks SDK gebruikt om een eindpunt voor functieverdeling te maken met behulp van Databricks Online Tables.