Wat is een Data Lakehouse?
Een Data Lakehouse is een databeheersysteem dat de voordelen van data lakes en datawarehouses combineert. In dit artikel wordt het architectuurpatroon van Lakehouse beschreven en wat u ermee kunt doen in Azure Databricks.
Waarvoor wordt data lakehouse gebruikt?
Een Data Lakehouse biedt schaalbare opslag- en verwerkingsmogelijkheden voor moderne organisaties die geïsoleerde systemen willen vermijden voor het verwerken van verschillende workloads, zoals machine learning (ML) en business intelligence (BI). Een Data Lakehouse kan helpen om één bron van waarheid tot stand te brengen, redundante kosten te elimineren en ervoor te zorgen dat gegevens vers zijn.
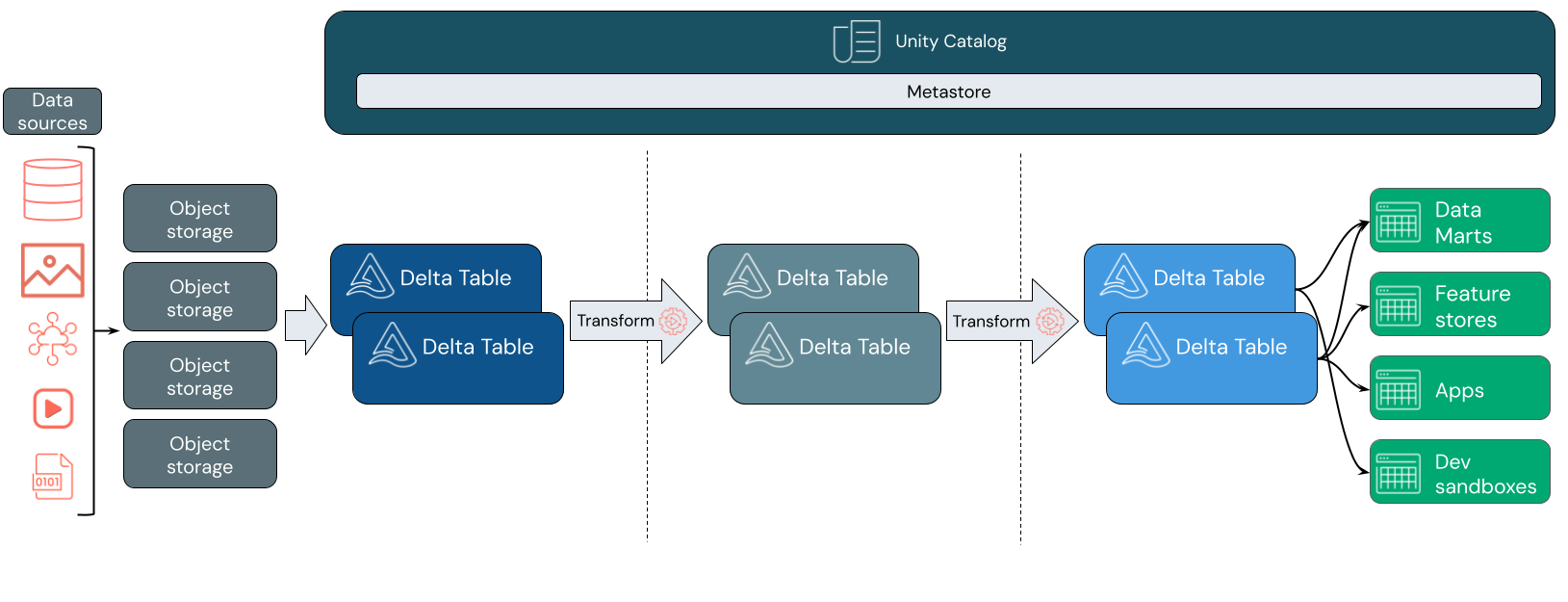
Data Lakehouses maken vaak gebruik van een gegevensontwerppatroon dat gegevens stapsgewijs verbetert, verrijkt en verfijnt tijdens het doorlopen van lagen van fasering en transformatie. Elke laag van het lakehouse kan een of meer lagen bevatten. Dit patroon wordt vaak aangeduid als een medaillonarchitectuur. Zie voor meer informatie Wat is de medallion lakehouse-architectuur?
Hoe werkt databricks lakehouse?
Databricks is gebouwd op Apache Spark. Apache Spark maakt een zeer schaalbare engine mogelijk die wordt uitgevoerd op rekenresources die zijn losgekoppeld van de opslag. Zie Apache Spark in Azure Databricks voor meer informatie
Databricks lakehouse maakt gebruik van twee extra belangrijke technologieën:
- Delta Lake: een geoptimaliseerde opslaglaag die ACID-transacties ondersteunt en schema-handhaving.
- Unity Catalog: een uniforme, verfijnde governanceoplossing voor gegevens en AI.
Gegevensopname
Bij de opnamelaag komen batch- of streaminggegevens uit verschillende bronnen en in verschillende indelingen binnen. Deze eerste logische laag biedt een plaats waar die gegevens in hun onbewerkte formaat terechtkomen. Wanneer u deze bestanden converteert naar Delta tables, kunt u de schema afdwingingsmogelijkheden van Delta Lake gebruiken om te controleren op ontbrekende of onverwachte gegevens. U kunt Unity Catalog gebruiken om tables te registreren op basis van uw gegevensbeheermodel en de vereiste grenzen voor gegevensisolatie. Met Unity Catalog kunt u de herkomst van uw gegevens bijhouden terwijl deze wordt getransformeerd en verfijnd, en kunt u een geïntegreerd governancemodel toepassen om gevoelige gegevens privé en veilig te houden.
Gegevensverwerking, curatie en integratie
Zodra dit is geverifieerd, kunt u beginnen met het cureren en verfijnen van uw gegevens. Gegevenswetenschappers en machine learning-beoefenaars werken vaak met gegevens in deze fase om te beginnen met het combineren of maken van nieuwe functies en het voltooien van gegevensopschoning. Zodra uw gegevens grondig zijn opgeschoond, kunnen deze worden geïntegreerd en gereorganiseerd in tables ontworpen om te voldoen aan uw specifieke bedrijfsbehoeften.
Een schema-on-write-benadering, gecombineerd met delta-schema evolutiemogelijkheden, betekent dat u aanpassingen in deze laag kunt maken zonder dat u per se having om de logica stroomafwaarts, die gegevens aan uw eindgebruikers levert, te herschrijven.
Gegevensservering
De laatste laag levert schone, verrijkte gegevens aan eindgebruikers. De laatste tables moet zijn ontworpen om gegevens te leveren voor al uw gebruiksscenario's. Een geïntegreerd governancemodel betekent dat u gegevensherkomst kunt bijhouden naar uw enige bron van waarheid. Met gegevensindelingen, geoptimaliseerd voor verschillende taken, hebben eindgebruikers toegang tot gegevens voor machine learning-toepassingen, data engineering en business intelligence en rapportage.
Zie Wat is Delta Lake? voor meer informatie over Delta Lake. Zie Wat is Unity Catalog? voor meer informatie over Unity Catalog.
Mogelijkheden van een Databricks Lakehouse
Een lakehouse gebouwd op Databricks elimineert de huidige noodzaak van data lakes en data warehouses voor moderne databedrijven. Enkele belangrijke taken die u kunt uitvoeren, zijn:
- realtime gegevensverwerking: streaminggegevens in realtime verwerken voor onmiddellijke analyse en actie.
- Gegevensintegratie: Uw gegevens samenvoegen in één systeem om samenwerking mogelijk te maken en één bron van waarheid voor uw organisatie tot stand te brengen.
- Schema evolutie: Gegevens schema wijzigen om zich aan te passen aan veranderende bedrijfsbehoeften zonder bestaande gegevenspijplijnen te verstoren.
- gegevenstransformaties: Apache Spark en Delta Lake gebruiken, zorgt voor snelheid, schaalbaarheid en betrouwbaarheid voor uw gegevens.
- Gegevensanalyse en -rapportage: Voer complexe analytische queries uit met een engine geoptimaliseerd voor datawarehousingtaken.
- Machine learning en AI: Geavanceerde analysetechnieken toepassen op al uw gegevens. Gebruik ML om uw gegevens te verrijken en andere workloads te ondersteunen.
- gegevensversiebeheer en herkomst: Versiegeschiedenis voor gegevenssets onderhouden en herkomst bijhouden om de herkomst en traceerbaarheid van gegevens te garanderen.
- Gegevensbeheer: Gebruik één geïntegreerd systeem om de toegang tot uw gegevens te beheren en controles uit te voeren.
- gegevens delen: Samenwerking vergemakkelijken door het delen van gecureerde gegevenssets, rapporten en inzichten in teams mogelijk te maken.
- Operationele analyses: Houd toezicht op metingen van gegevenskwaliteit, modelkwaliteit en drift door machine learning toe te passen op de bewakingsgegevens van lakehouse.
Lakehouse vs Data Lake vs Data Warehouse
Datawarehouses hebben ongeveer 30 jaar Business Intelligence (BI) beslissingen mogelijk gemaakt, having zijn ontwikkeld als een set van ontwerprichtlijnen voor systemen die de stroom van gegevens controleren. Datamagazijnen voor ondernemingen voeren optimize query's uit voor BI-rapporten, maar het kan enkele minuten of zelfs uren duren voordat resultaten generate. Datawarehouses zijn ontworpen voor gegevens die waarschijnlijk niet met een hoge frequentie kunnen worden gewijzigd, om conflicten tussen gelijktijdig uitgevoerde query's te voorkomen. Veel datawarehouses zijn afhankelijk van eigen indelingen, die vaak limit ondersteuning voor machine learning. Datawarehousing in Azure Databricks maakt gebruik van de mogelijkheden van een Databricks Lakehouse en Databricks SQL. Voor meer informatie, zie Wat is datawarehousing in Azure Databricks?.
Aangedreven door technologische ontwikkelingen in gegevensopslag en gedreven door exponentiële toename van de typen en het volume van gegevens, zijn data lakes in de afgelopen tien jaar in wijdverspreid gebruik gekomen. Data lakes slaan gegevens goedkoop en efficiënt op. Data lakes worden vaak gedefinieerd als tegenstelling van datawarehouses: een datawarehouse levert schone, gestructureerde gegevens voor BI-analyses, terwijl een data lake gegevens van elke soort permanent en voordelig opslaat in elk formaat. Veel organisaties gebruiken data lakes voor data science en machine learning, maar niet voor BI-rapportage vanwege de niet-gevalideerde aard.
Data Lakehouse combineert de voordelen van data lakes en datawarehouses en biedt:
- Open, directe toegang tot gegevens die zijn opgeslagen in standaardgegevensindelingen.
- Indexeringsprotocollen die zijn geoptimaliseerd voor machine learning en gegevenswetenschap.
- Lage querylatentie en hoge betrouwbaarheid voor BI en geavanceerde analyses.
Door een geoptimaliseerde metagegevenslaag te combineren met gevalideerde gegevens die zijn opgeslagen in standaardindelingen in cloudobjectopslag, kunnen gegevenswetenschappers en ML-ingenieurs modellen ontwikkelen op basis van dezelfde data-driven BI-rapporten.
Volgende stap
Zie Inleiding tot de goed ontworpen data lakehouse- voor meer informatie over de principes en best practices voor het implementeren en gebruiken van een lakehouse met Databricks