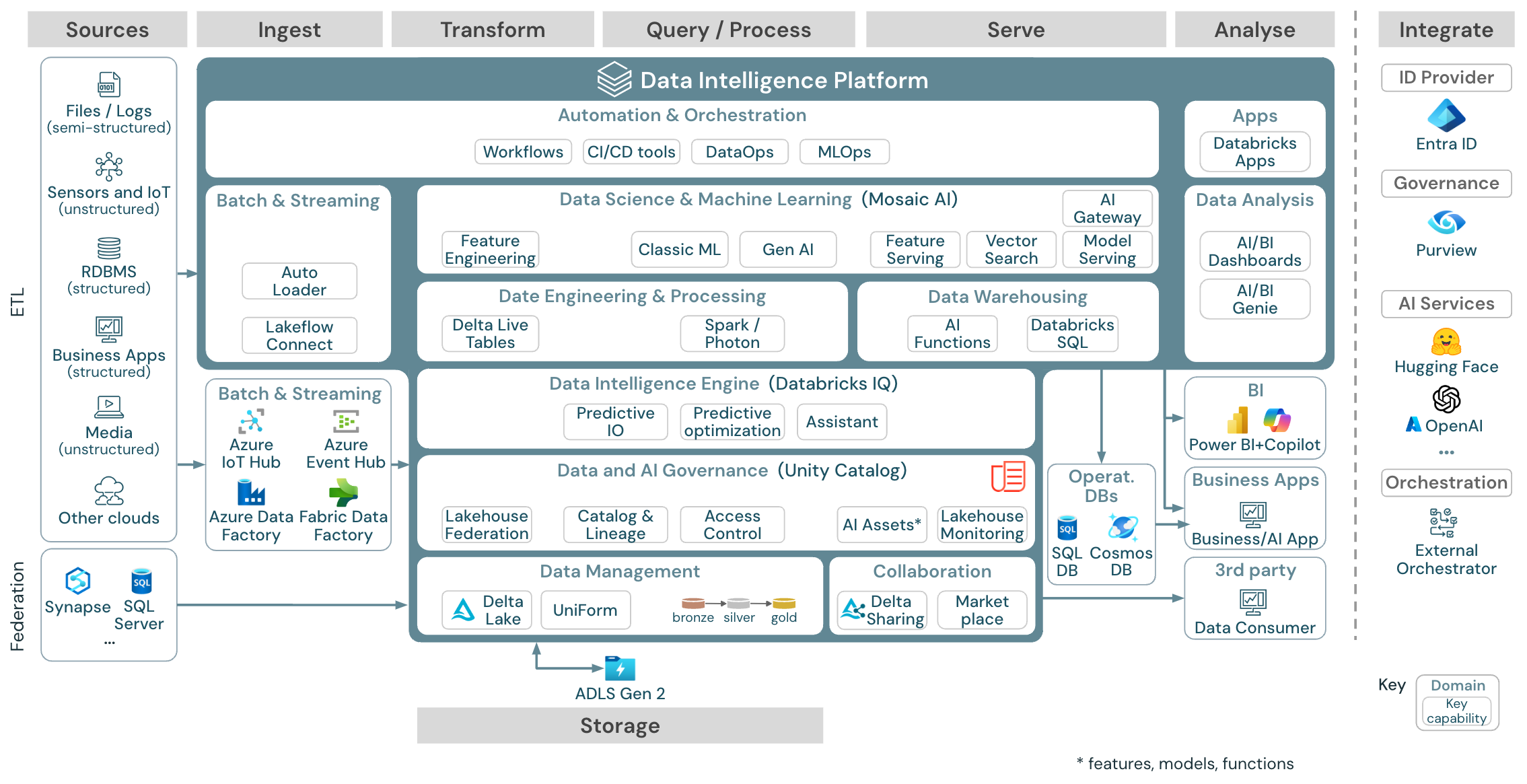
Lakehouse-referentiearchitecturen (download)
In dit artikel worden architectuurrichtlijnen voor lakehouse beschreven in termen van gegevensbron, opname, transformatie, query's en verwerking, het leveren, analyseren en opslaan.
Elke referentiearchitectuur heeft een downloadbare PDF-indeling van 11 x 17 (A3).
Hoewel het Lakehouse op Databricks een open platform is dat kan worden geïntegreerd met een groot ecosysteem van partnerhulpprogramma's, richten de referentiearchitecturen zich alleen op Azure-services en databricks lakehouse. De weergegeven cloudproviderservices zijn geselecteerd om de concepten te illustreren en zijn niet volledig.
Downloaden: Referentiearchitectuur voor de Azure Databricks Lakehouse-
De Azure-referentiearchitectuur toont de volgende Azure-specifieke services voor opname, opslag, service en analyse:
- Azure Synapse en SQL Server als bronsystemen voor Lakehouse Federation
- Azure IoT Hub en Azure Event Hubs voor streamingopname
- Azure Data Factory voor batchopname
- Azure Data Lake Storage Gen 2 (ADLS) als objectopslag
- Azure SQL DB en Azure Cosmos DB als operationele databases
- Azure Purview als de bedrijfscatalogus waarnaar UC schema- en herkomstgegevens exporteert
- Power BI als BI-tool
Organisatie van de referentiearchitecturen
De referentiearchitectuur is gestructureerd langs de zwembanen Bron, Opnemen, Transformeren, Query/Process, Dienen, Analyseen Opslag:
Bron
De architectuur maakt onderscheid tussen semi-gestructureerde en ongestructureerde gegevens (sensoren en IoT, media, bestanden/logboeken) en gestructureerde gegevens (RDBMS, bedrijfstoepassingen). SQL-bronnen (RDBMS) kunnen ook zonder ETL worden geïntegreerd in het lakehouse en in de Unity Catalog via de lakehouse-federatie. Daarnaast kunnen gegevens worden geladen van andere cloudproviders.
Invoer
Gegevens kunnen via batch of streaming in het lakehouse worden opgenomen:
- Databricks Lakeflow Connect biedt ingebouwde connectors voor opname vanuit bedrijfstoepassingen en -databases. De resulterende opnamepijplijn wordt beheerd door Unity Catalog en wordt mogelijk gemaakt door serverloze berekeningen en DLT.
- Bestanden die in de cloudopslag worden geleverd, kunnen rechtstreeks worden geladen met behulp van het Databricks Auto Loader.
- Voor batchopname van gegevens uit bedrijfstoepassingen in Delta Lake vertrouwt de Databricks Lakehouse op partner-opnamehulpmiddelen met specifieke adapters voor deze recordsystemen.
- Streaminggebeurtenissen kunnen rechtstreeks vanuit gebeurtenisstreamingsystemen, zoals Kafka, worden opgenomen met behulp van Databricks Structured Streaming. Streamingbronnen kunnen sensoren, IoT of processen voor veranderingsgegevens vastleggen zijn.
Storage
Gegevens worden doorgaans opgeslagen in het cloudopslagsysteem waar de ETL-pijplijnen gebruikmaken van de medal queue-architectuur om gegevens op een gecureerde manier op te slaan als Delta-bestanden/-tabellen.
Transformeer en Query / proces
Databricks Lakehouse gebruikt de engines Apache Spark en Photon voor alle transformaties en query's.
DLT (DLT) is een declaratief framework voor het vereenvoudigen en optimaliseren van betrouwbare, onderhoudbare en testbare pijplijnen voor gegevensverwerking.
Het Databricks Data Intelligence Platform, mogelijk gemaakt door Apache Spark en Photon, ondersteunt beide typen workloads: SQL-query's via SQL-magazijnen en SQL-, Python- en Scala-workloads via werkruimteclusters.
Voor data science (ML Modeling en Gen AI) biedt het Databricks AI- en Machine Learning-platform gespecialiseerde ML-runtimes voor AutoML en voor het coderen van ML-taken. Alle data science- en MLOps-werkstromen worden het beste ondersteund door MLflow.
Serveren
Voor DWH- en BI-gebruikssituaties biedt het Databricks LakehouseDatabricks SQL, het datawarehouse dat wordt mogelijk gemaakt door SQL-warehouses en serverloze SQL-warehouses.
Voor machine learning is modelbediening een schaalbare, realtime, op ondernemingsniveau modelbedieningsmogelijkheid die wordt gehost in het Databricks-controleplan. Mosaic AI Gateway is databricks-oplossing voor het beheren en bewaken van toegang tot ondersteunde generatieve AI-modellen en hun bijbehorende model voor eindpunten.
Operationele databases: externe systemen, zoals operationele databases, kunnen worden gebruikt voor het opslaan en leveren van eindproducten aan gebruikerstoepassingen.
Samenwerking: zakelijke partners krijgen veilige toegang tot de gegevens die ze nodig hebben via Delta Sharing-. Op basis van Delta Sharing is Databricks Marketplace een open forum voor het uitwisselen van gegevensproducten.
Analyse
De laatste zakelijke toepassingen bevinden zich in deze zwembaan. Voorbeelden zijn aangepaste clients zoals AI-toepassingen die zijn verbonden met Mosaic AI Model Serving voor realtime deductie of toepassingen die toegang hebben tot gegevens die vanuit lakehouse naar een operationele database worden gepusht.
Voor BI-use cases gebruiken analisten doorgaans BI-hulpprogramma's voor toegang tot het datawarehouse. SQL-ontwikkelaars kunnen bovendien de Databricks SQL Editor (niet weergegeven in het diagram) gebruiken voor query's en dashboarding.
Het Data Intelligence Platform biedt ook dashboards voor het bouwen van gegevensvisualisaties en het delen van inzichten.
integreren
- Het Databricks-platform kan worden geïntegreerd met standaardidentiteitsproviders voor gebruikersbeheer en eenmalige aanmelding (SSO).
Externe AI-services zoals OpenAI, LangChain of HuggingFace kunnen rechtstreeks vanuit het Databricks Intelligence Platform worden gebruikt.
Externe orkestratoren kunnen de uitgebreide REST API- of specifieke connectors voor externe orkestratietools zoals Apache Airflow-gebruiken.
Unity Catalog wordt gebruikt voor alle data- en AI-governance in het Databricks Intelligence Platform en kan andere databases integreren in de governance via Lakehouse Federation.
Daarnaast kan Unity Catalog worden geïntegreerd in andere bedrijfscatalogussen, bijvoorbeeld Purview. Neem contact op met de leverancier van de bedrijfscatalogus voor meer informatie.
Algemene mogelijkheden voor alle workloads
Daarnaast wordt databricks lakehouse geleverd met beheermogelijkheden die ondersteuning bieden voor alle workloads:
Gegevens en AI-governance
Het centrale data- en AI-governancesysteem in het Databricks Data Intelligence Platform is Unity Catalog. Unity Catalog biedt één locatie voor het beheren van beleidsregels voor gegevenstoegang die van toepassing zijn op alle werkruimten en ondersteunt alle assets die zijn gemaakt of gebruikt in lakehouse, zoals tabellen, volumes, functies (functiearchief) en modellen (modelregister). Unity Catalog kan ook worden gebruikt om runtimegegevensherkomst vast te leggen voor query's die worden uitgevoerd op Databricks.
Met Databricks Lakehouse Monitoring heeft u de mogelijkheid om de gegevenskwaliteit van alle tabellen in uw account te bewaken. Het kan ook de prestaties van machine learning-modellen en eindpunten voor modelverdiening bijhouden.
Voor waarneembaarheid zijn systeemtabellen een door Databricks gehoste analytische opslag van de operationele gegevens van uw account. Systeemtabellen kunnen worden gebruikt voor historische waarneembaarheid in uw account.
Data intelligence engine
Met het Databricks Data Intelligence Platform kan uw hele organisatie gegevens en AI gebruiken. Het wordt mogelijk gemaakt door DatabricksIQ en combineert generatieve AI met de eenwordingsvoordelen van een lakehouse om inzicht te hebben in de unieke semantiek van uw gegevens.
De Databricks Assistant is beschikbaar in Databricks-notebooks, SQL-editor en bestandseditor als contextbewuste AI-assistent voor ontwikkelaars.
Automation & Orchestration
Databricks-taken organiseren pijplijnen voor gegevensverwerking, machine learning en analyse op het Databricks Data Intelligence Platform. DLT- kunt u betrouwbare en onderhoudbare ETL-pijplijnen bouwen met declaratieve syntaxis. Het platform ondersteunt ook CI/CD- en MLOps-
Use cases op hoog niveau voor het Data Intelligence Platform in Azure
Databricks Lakeflow Connect biedt ingebouwde connectors voor opname vanuit bedrijfstoepassingen en -databases. De resulterende opnamepijplijn wordt beheerd door Unity Catalog en wordt mogelijk gemaakt door serverloze berekeningen en DLT. Lakeflow Connect maakt gebruik van efficiënte incrementele lees- en schrijfbewerkingen om gegevensopname sneller, schaalbaar en rendabeler te maken, terwijl uw gegevens vers blijven voor downstreamverbruik.
Use case: Invoer met Lakeflow Connect:

Downloaden: Batch ETL-referentiearchitectuur voor Azure Databricks.
Gebruiksscenario: Batch ETL
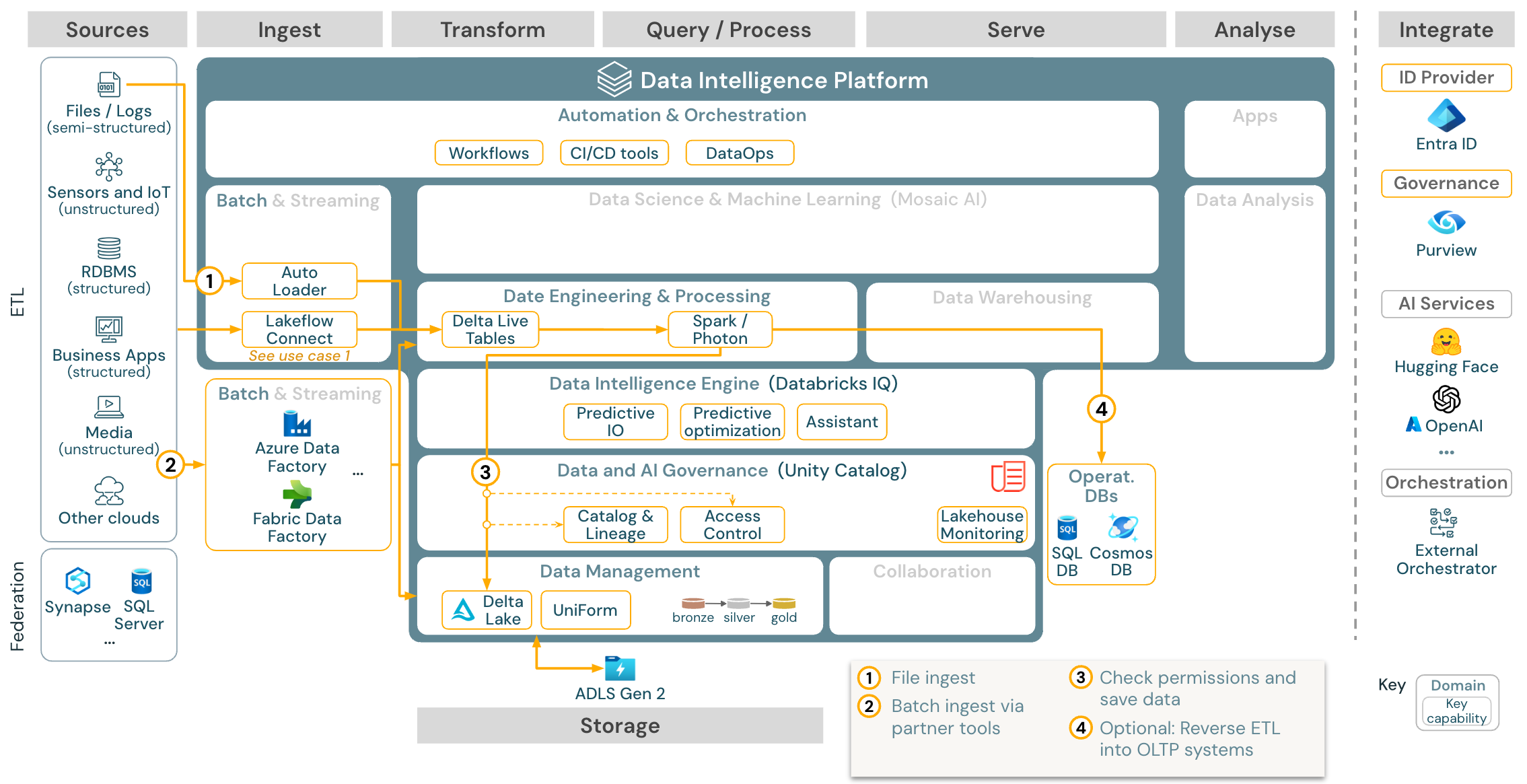
Downloaden: Batch ETL-referentiearchitectuur voor Azure Databricks
Ingesttools gebruiken bronspecifieke adapters om gegevens uit de bron te lezen en slaan deze vervolgens op in de cloudopslag, van waaruit Auto Loader het kan lezen, of roepen Databricks rechtstreeks aan (bijvoorbeeld met partneringesttools die zijn geïntegreerd in het Databricks Lakehouse). Als u de gegevens wilt laden, voert de Databricks ETL en de verwerkingsengine , via DLT, de query's uit. Werkstromen voor enkelvoudige of meervoudige taken kunnen worden ingevoerd door Databricks Jobs en beheerd via Unity Catalog (toegangscontrole, audit, herkomst, enzovoort). Als operationele systemen met lage latentie toegang nodig hebben tot specifieke gouden tabellen, kunnen ze worden geëxporteerd naar een operationele database, zoals een RDBMS- of sleutelwaardearchief aan het einde van de ETL-pijplijn.
Toepassingsgeval: Streaming en bijgehouden gegevenswijziging (CDC)
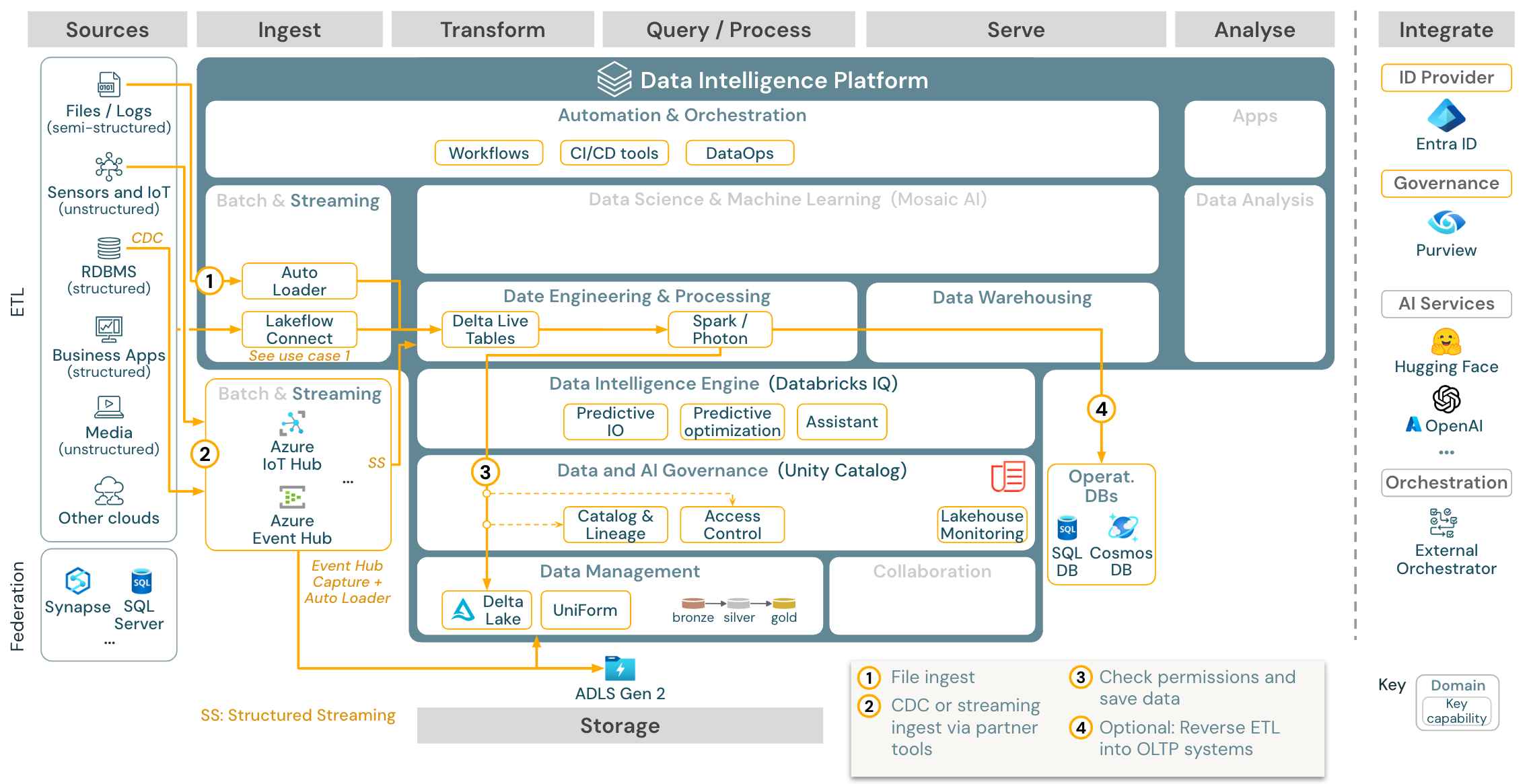
Downloaden: Gestructureerde Spark-streamingarchitectuur voor Azure Databricks
De Databricks ETL-engine maakt gebruik van Spark Structured Streaming om te lezen uit gebeurteniswachtrijen, zoals Apache Kafka of Azure Event Hub. De downstreamstappen volgen de benadering van de bovenstaande Batch-use-case.
Cdc (Real-time change data capture) gebruikt doorgaans een gebeurteniswachtrij om de geëxtraheerde gebeurtenissen op te slaan. Vanaf daar volgt het gebruiksscenario het streaminggebruiksscenario.
Als CDC wordt uitgevoerd in batch waarbij de geëxtraheerde records eerst worden opgeslagen in cloudopslag, kan Databricks Autoloader ze lezen en volgt de use-case Batch ETL.
Gebruikssituatie: Machine learning en AI
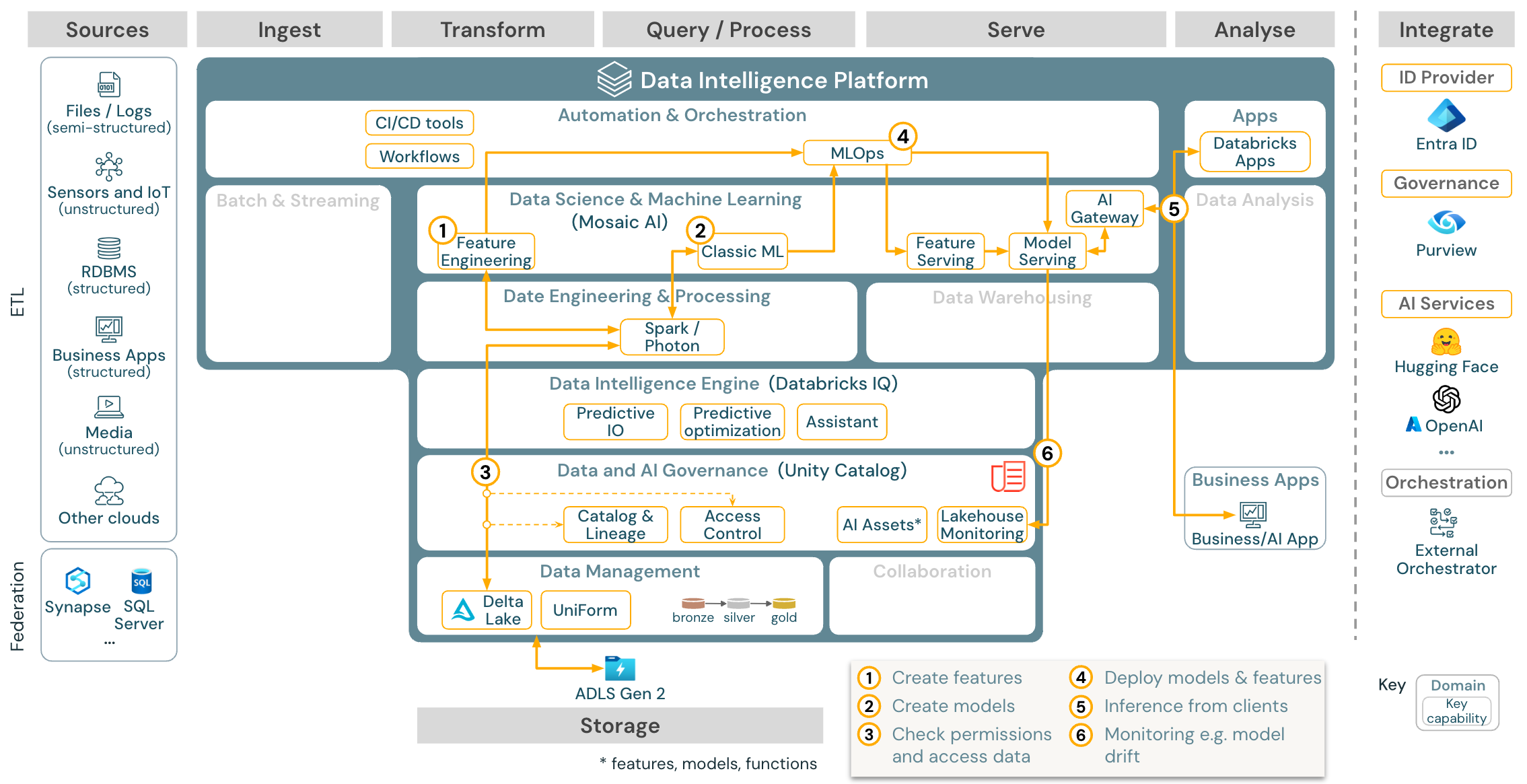
Downloaden: Machine learning- en AI-referentiearchitectuur voor Azure Databricks
Voor machine learning biedt het Databricks Data Intelligence Platform Mozaïek AI, dat wordt geleverd met geavanceerde machine- en deep learning-bibliotheken. Het biedt mogelijkheden zoals Feature Store en modelregister (beide geïntegreerd in Unity Catalog), functies met weinig code met AutoML en MLflow-integratie in de levenscyclus van data science.
Alle gegevenswetenschapgerelateerde assets (tabellen, functies en modellen) worden beheerd door Unity Catalog en gegevenswetenschappers kunnen Databricks-taken gebruiken om hun taken te organiseren.
Voor het implementeren van modellen op een schaalbare en zakelijke manier, gebruik de MLOps-functionaliteiten om de modellen te publiceren via modellering dienstverlening.
Gebruiksgeval: Generatieve AI-agenttoepassingen
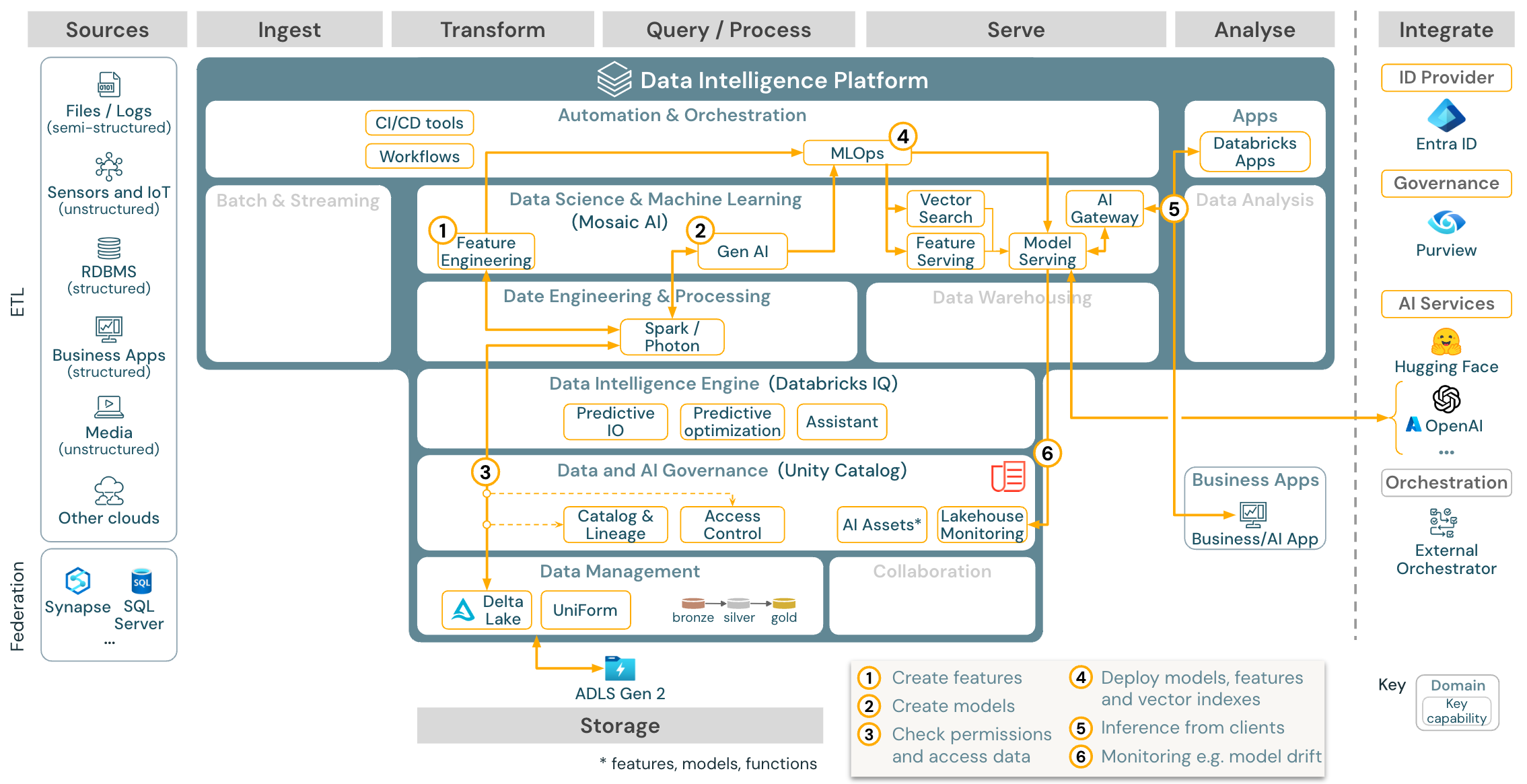
Downloaden: Referentiearchitectuur voor Gen AI-toepassingen voor Azure Databricks-
Voor generatieve AI-toepassingen wordt Mosaic AI geleverd met geavanceerde bibliotheken en specifieke generatieve AI-mogelijkheden, van prompt engineering tot het verfijnen van bestaande modellen en pre-training vanaf nul. In de bovenstaande architectuur ziet u een voorbeeld van hoe de vectorzoekfunctie kan worden geïntegreerd om een generatieve AI-toepassing te maken door gebruik te maken van RAG (ophalen-verrijkte generatie).
Voor het implementeren van modellen op een schaalbare en bedrijfsniveau manier, gebruikt u de MLOps-mogelijkheden om de modellen te publiceren in een modellendienst.
Use-case: BI- en SQL-analyses
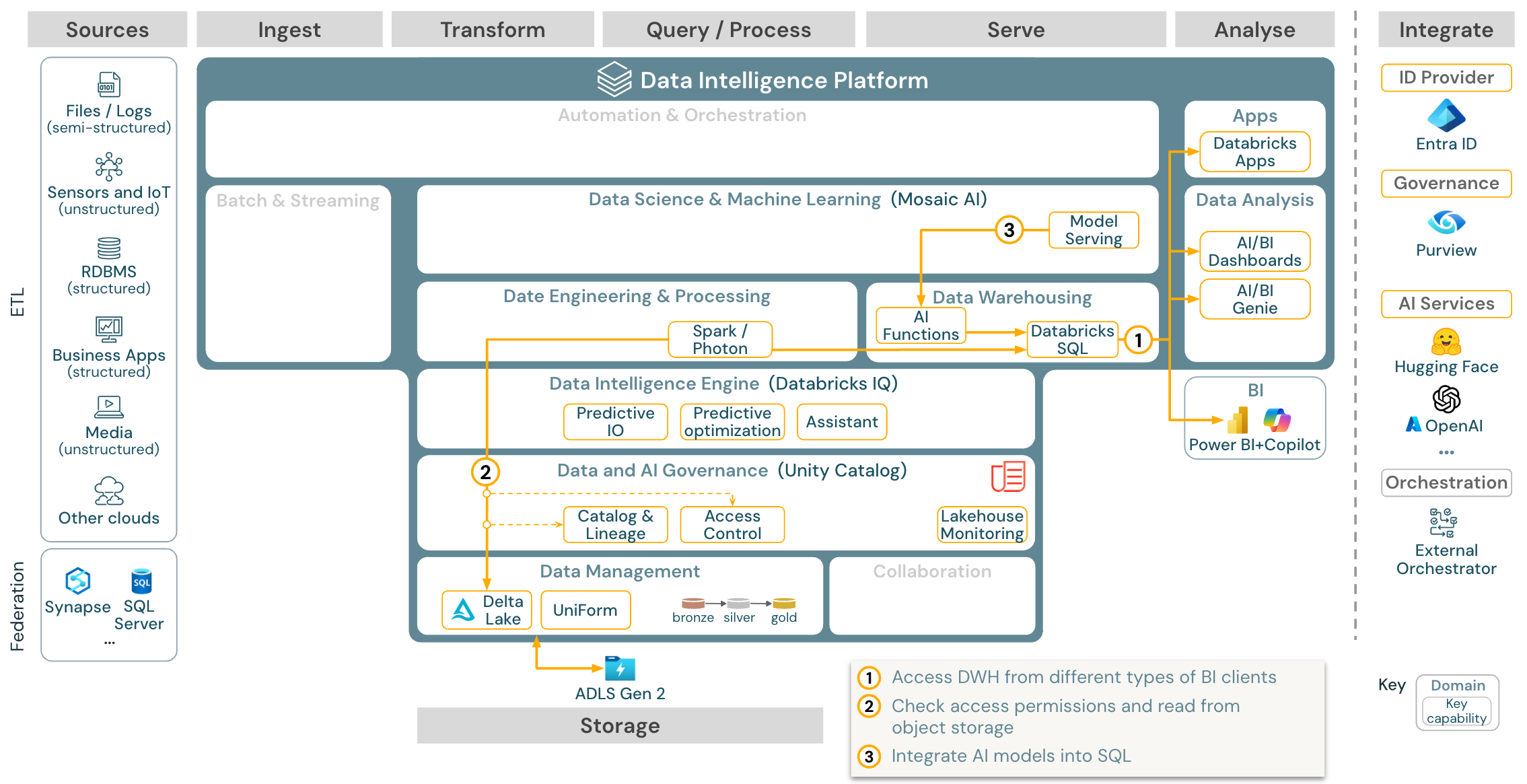
Download: Referentie-architectuur voor BI- en SQL-analyse voor Azure Databricks
Voor BI-use cases kunnen bedrijfsanalisten dashboards, de Databricks SQL-editor of specifieke BI-hulpprogramma's zoals Tableau of Power BI gebruiken. In alle gevallen is de engine Databricks SQL (serverloos of niet-serverloos) en worden gegevensdetectie, verkenning en toegangsbeheer geleverd door Unity Catalog.
Gebruikssituatie: Lakehouse-federatie
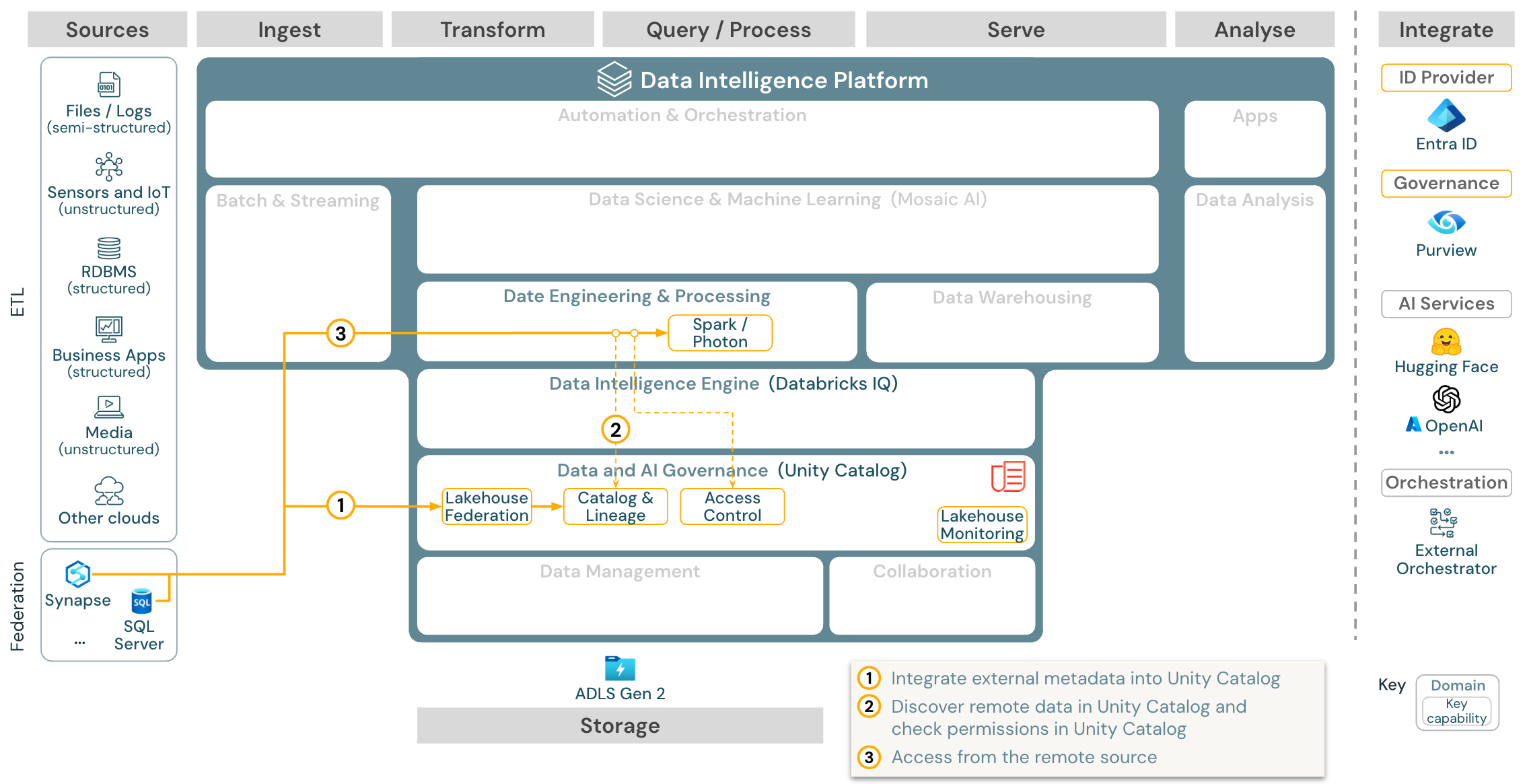
Download: de Lakehouse Federatie naslagarchitectuur voor Azure Databricks
Met Lakehouse-federatie kunnen sql-databases voor externe gegevens (zoals MySQL, Postgres, SQL Server of Azure Synapse) worden geïntegreerd met Databricks.
Alle workloads (AI, DWH en BI) kunnen hiervan profiteren zonder dat de data eerst naar objectopslag hoeft te worden getransformeerd. De externe broncatalogus wordt toegewezen aan de Unity-catalogus en gedetailleerd toegangsbeheer kan worden toegepast op toegang via het Databricks-platform.
Gebruiksscenario: Zakelijke gegevensdeling
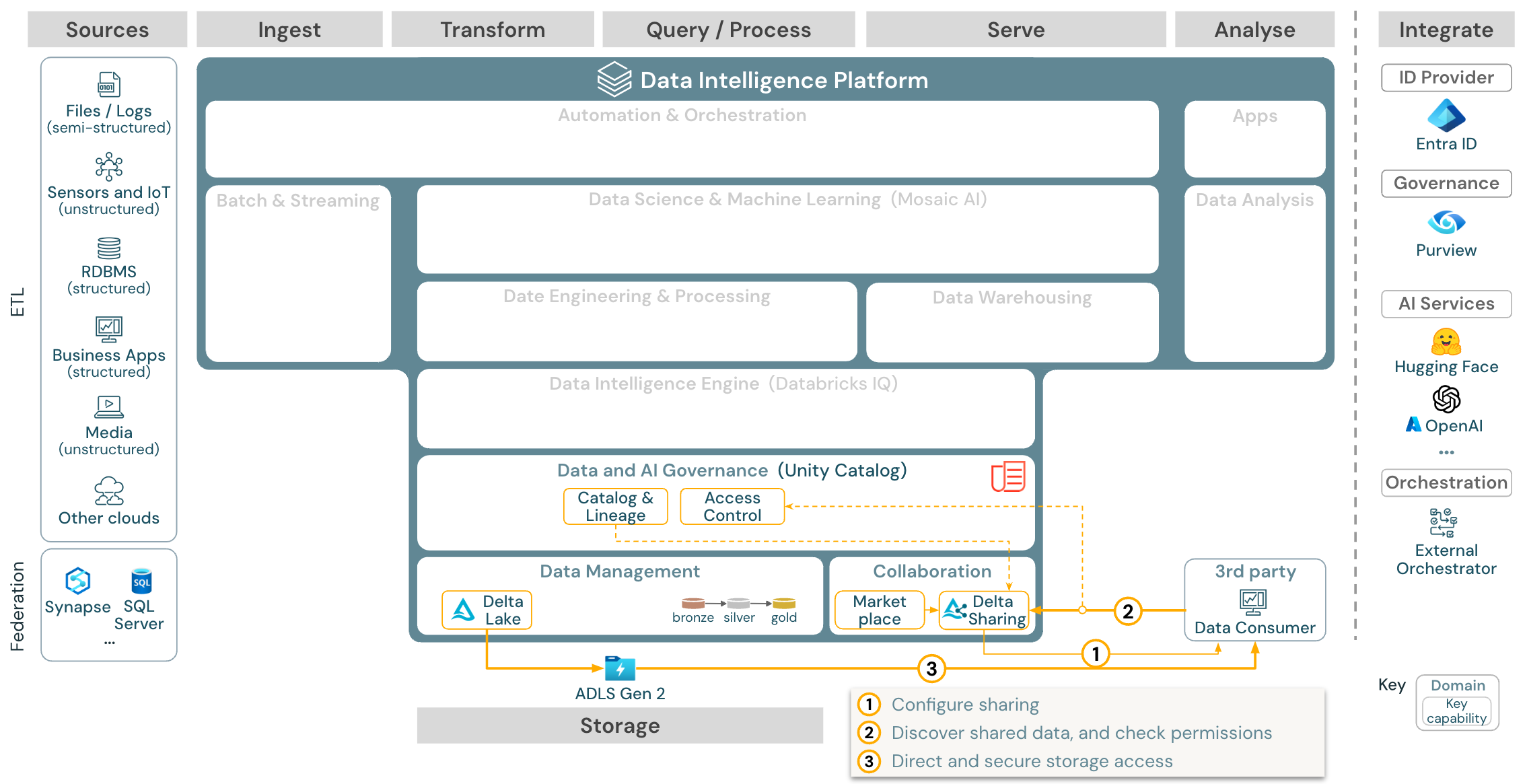
Downloaden: Referentiearchitectuur voor het delen van ondernemingsgegevens voor Azure Databricks
Gegevens delen op bedrijfsniveau wordt geleverd door Delta Sharing. Het biedt directe toegang tot gegevens in het objectarchief dat wordt beveiligd door Unity Catalog en Databricks Marketplace is een open forum voor het uitwisselen van gegevensproducten.