Uw Azure Databricks-taak uitvoeren met serverloze rekenkracht voor werkstromen
Met serverloze berekening voor werkstromen kunt u uw Azure Databricks-taak uitvoeren zonder infrastructuur te configureren en te implementeren. Met serverloze berekeningen richt u zich op het implementeren van uw pijplijnen voor gegevensverwerking en analyse, en Azure Databricks beheert efficiënt rekenresources, waaronder het optimaliseren en schalen van rekenkracht voor uw workloads. Automatisch schalen en Photon worden automatisch ingeschakeld voor de rekenresources die uw taak uitvoeren.
Serverloze berekening voor werkstromen optimaliseert automatisch en continu infrastructuur, zoals instantietypen, geheugen en verwerkingsengines, om de beste prestaties te garanderen op basis van de specifieke verwerkingsvereisten van uw workloads.
Databricks werkt de Databricks Runtime-versie automatisch bij om verbeteringen en upgrades naar het platform te ondersteunen en tegelijkertijd de stabiliteit van uw Azure Databricks-taken te garanderen. Zie de releaseopmerkingen voor serverloze berekeningen voor werkstromen om de huidige Databricks Runtime-versie te bekijken die wordt gebruikt door serverloze berekeningen.
Omdat de machtiging voor het maken van clusters niet is vereist, kunnen alle werkruimtegebruikers serverloze berekeningen gebruiken om hun werkstromen uit te voeren.
In dit artikel wordt beschreven hoe u de gebruikersinterface van Azure Databricks-taken gebruikt om taken te maken en uit te voeren die gebruikmaken van serverloze berekeningen. U kunt ook het maken en uitvoeren van taken automatiseren die gebruikmaken van serverloze berekeningen met de Jobs-API, Databricks Asset Bundles en de Databricks SDK voor Python.
- Zie Taken in de REST API-verwijzing voor meer informatie over het gebruik van de Taken-API om taken te maken en uit te voeren die gebruikmaken van serverloze berekeningen.
- Zie Een taak ontwikkelen in Azure Databricks met behulp van Databricks Asset Bundles voor meer informatie over het gebruik van Databricks Asset Bundles om taken te maken en uit te voeren die gebruikmaken van serverloze berekeningen.
- Zie De Databricks SDK voor Python voor meer informatie over het gebruik van de Databricks SDK voor Python om taken te maken en uit te voeren die gebruikmaken van serverloze berekeningen.
Vereisten
Voor uw Azure Databricks-werkruimte moet Unity Catalog zijn ingeschakeld.
Omdat serverloze berekeningen voor werkstromen gebruikmaken van de modus voor gedeelde toegang, moeten uw workloads deze toegangsmodus ondersteunen.
Uw Databricks-werkruimte moet zich in een ondersteunde regio bevinden. Zie Functies met beperkte regionale beschikbaarheid.
Voor uw Azure Databricks-account moet serverloze rekenkracht zijn ingeschakeld. Zie Serverloze berekening inschakelen.
Een taak maken met serverloze rekenkracht
Notitie
Omdat serverloze berekeningen voor werkstromen ervoor zorgen dat er voldoende resources worden ingericht om uw workloads uit te voeren, kan het zijn dat u een verhoogde opstarttijd ondervindt bij het uitvoeren van een Azure Databricks-taak waarvoor grote hoeveelheden geheugen is vereist of veel taken bevat.
Serverloze rekenkracht wordt ondersteund met de taaktypen notebook, Python-script, dbt en Python-wiel. Serverloze berekeningen worden standaard geselecteerd als het rekentype wanneer u een nieuwe taak maakt en een van deze ondersteunde taaktypen toevoegt.
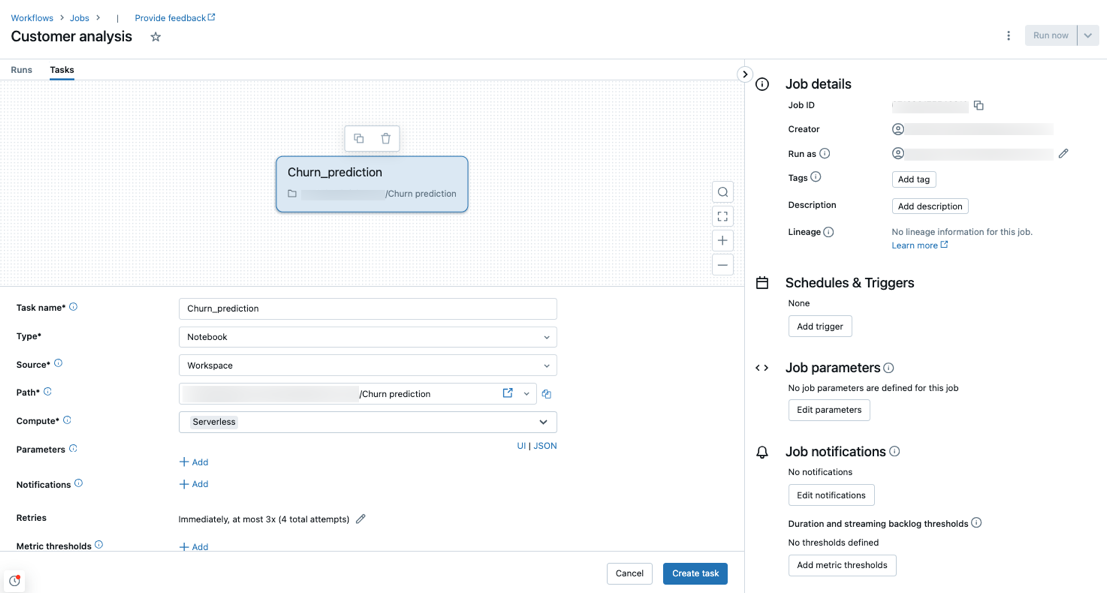
Databricks raadt aan serverloze berekeningen te gebruiken voor alle taaktaken. U kunt ook verschillende rekentypen opgeven voor taken in een taak, wat mogelijk vereist is als een taaktype niet wordt ondersteund door serverloze berekeningen voor werkstromen.
Als u uitgaande netwerkverbindingen voor uw taken wilt beheren, raadpleegt u Wat is serverloos uitgaand verkeer?
Een bestaande taak configureren voor het gebruik van serverloze berekeningen
U kunt een bestaande taak overschakelen naar serverloze berekeningen voor ondersteunde taaktypen wanneer u de taak bewerkt. Ga als volgende te werk om over te schakelen naar serverloze berekeningen:
- Klik in het Taakdetails zijpaneel op Wisselen onder Compute, klik op Nieuw, voer instellingen in of werk deze bij, en klik op Bijwerken.
- Klik op
 omlaag in de vervolgkeuzelijst Compute en selecteer Serverloze.
omlaag in de vervolgkeuzelijst Compute en selecteer Serverloze.

Een notebook plannen met serverloze berekeningen
Naast het gebruik van de gebruikersinterface taken om een taak te maken en te plannen met serverloze berekeningen, kunt u een taak maken en uitvoeren die serverloze berekening rechtstreeks vanuit een Databricks-notebook gebruikt. Zie Geplande notebooktaken maken en beheren.
Selecteer een budgetbeleid voor uw serverloze gebruik
Belangrijk
Deze functie is beschikbaar als openbare preview.
Met budgetbeleid kan uw organisatie aangepaste tags toepassen op serverloos gebruik voor gedetailleerde factureringstoewijzing.
Als uw werkruimte budgetbeleid gebruikt om serverloos gebruik toe te wijzen, kunt u het budgetbeleid van uw taak selecteren met behulp van de instelling Budgetbeleid in de gebruikersinterface voor taakdetails. Als u slechts aan één budgetbeleid bent toegewezen, wordt het beleid automatisch geselecteerd voor uw nieuwe taken.
Notitie
Nadat u een budgetbeleid hebt toegewezen, worden uw bestaande taken niet automatisch gelabeld met uw beleid. U moet bestaande taken handmatig bijwerken als u een beleid aan deze taken wilt koppelen.
Zie Serverloos gebruik van kenmerken met budgetbeleid voor meer informatie over budgetbeleidsregels.
Spark-configuratieparameters instellen
Als u de configuratie van Spark op serverloze berekeningen wilt automatiseren, staat Databricks alleen specifieke Spark-configuratieparameters in. Zie Ondersteunde Spark-configuratieparametersvoor de lijst met toegestane parameters.
U kunt alleen Spark-configuratieparameters instellen op sessieniveau. Om dit te doen, stelt u ze in een notebook in en voegt u het notebook toe aan een taak die is opgenomen in dezelfde opdracht die gebruikmaakt van de parameters. Zie Apache Spark-configuratie-eigenschappen ophalen en instellen in een notebook.
Omgevingen en afhankelijkheden configureren
Hoge geheugen configureren voor notebooktaken
Belangrijk
Deze functie is beschikbaar als openbare preview.
U kunt notebooktaken configureren om een hogere geheugengrootte te gebruiken. Configureer hiervoor de instelling Memory in het zijpaneel Environment van het notitieblok. Zie Hoog geheugen configureren voor uw serverloze workloads.
Hoog geheugen is alleen beschikbaar voor notebooktaaktypen.
Automatische optimalisatie van serverloze berekeningen configureren om nieuwe pogingen niet toe te staan
Serverloze berekening voor automatische optimalisatie van werkstromen optimaliseert automatisch de berekening die wordt gebruikt om uw taken uit te voeren en mislukte taken opnieuw uit te voeren. Automatische optimalisatie is standaard ingeschakeld en Databricks raadt aan deze ingeschakeld te laten om ervoor te zorgen dat kritieke workloads minstens één keer worden uitgevoerd. Als u echter workloads hebt die maximaal één keer moeten worden uitgevoerd, bijvoorbeeld taken die niet idempotent zijn, kunt u automatische optimalisatie uitschakelen bij het toevoegen of bewerken van een taak:
-
Klik naast Nieuwe pogingen op Toevoegen (of
 als er al een beleid voor opnieuw proberen bestaat).
als er al een beleid voor opnieuw proberen bestaat). - Schakel in het dialoogvenster Beleid voor opnieuw proberen het selectievakje Serverloze automatische optimalisatie inschakelen uit (mogelijk extra nieuwe pogingen) uit.
- Klik op Bevestigen.
- Als u een taak toevoegt, klikt u op Taak maken. Als u een taak bewerkt, klikt u op Taak opslaan.
De kosten van taken bewaken die gebruikmaken van serverloze berekeningen voor werkstromen
U kunt de kosten bewaken van taken die gebruikmaken van serverloze berekeningen voor werkstromen door een query uit te voeren op de factureerbare gebruikssysteemtabel. Deze tabel is bijgewerkt met kenmerken van gebruikers en werkbelastingen van serverloze kosten. Zie verwijzing naar de tabel voor factureerbaar gebruikssysteem .
Zie de pagina Met werkstromen prijzen voor informatie over huidige prijzen en eventuele promoties.
Querydetails voor taakuitvoeringen weergeven
U kunt gedetailleerde runtime-informatie voor uw Spark-instructies bekijken, zoals metrische gegevens en queryplannen.
Voer de volgende stappen uit om toegang te krijgen tot querydetails vanuit de gebruikersinterface van taken:
Klik op
 Werkstromen in de zijbalk.
Werkstromen in de zijbalk.Klik op de naam van de taak die u wilt weergeven.
Klik op de specifieke uitvoering die u wilt weergeven.
Klik op Tijdlijn om de uitvoering als tijdlijn weer te geven, opgesplitst in afzonderlijke taken.
Klik op de pijl naast de taaknaam om query-instructies en de bijbehorende runtimes weer te geven.
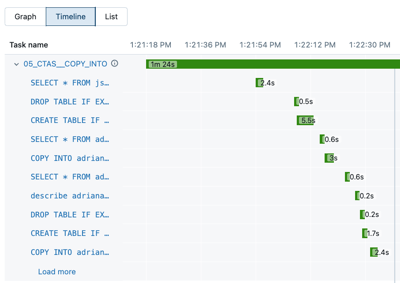
Klik op een instructie om het deelvenster met querydetails te openen. Zie Querydetails weergeven voor meer informatie over de informatie die beschikbaar is in dit deelvenster.
De querygeschiedenis voor een taak weergeven:
- Klik in de sectie Compute van het deelvenster Taakuitvoering op Querygeschiedenis.
- U wordt omgeleid naar de querygeschiedenis, vooraf gefilterd op basis van de taakuitvoerings-id van de taak waarin u zich bevindt.
Zie Access-querygeschiedenis voor Delta Live Tables-pijplijnen en Querygeschiedenisvoor meer informatie over het gebruik van querygeschiedenis.
Beperkingen
Zie Beperkingen van serverloze rekenkracht in de opmerkingen bij de release van serverloze rekenkracht voor een lijst met serverloze rekenkracht voor werkstromen.